
« Data 101 » est une série qui introduit les compétences et les concepts fondamentaux pour aider les personnes à développer leur culture des données. Tout au long de cette série, vous apprendrez à collecter, stocker, traiter, analyser, visualiser et interpréter des données à l’aide de divers outils technologiques et statistiques.
À la fin de cette série, vous aurez acquis les compétences analytiques de base qui sont très précieuses pour les managers. De plus, vous maîtriserez les fondements techniques nécessaires à la construction d’un parcours de données complet : de l’acquisition à la prise de décision. L’enseignement managérial essentiel de tout cet exercice est d’ancrer dans une organisation l’idée que les décisions doivent reposer sur la connaissance, et non sur l’intuition.
Les sujets abordés incluent des concepts statistiques de base tels que les mesures descriptives, les distributions de probabilité, les tests d’hypothèses, les modèles de régression linéaire à des fins de prédiction, et des algorithmes de machine learning tels que les arbres de décision ou les réseaux de neurones pour des tâches de classification. De plus, vous serez initié aux dernières technologies de données, telles que le stockage et le traitement des données, en utilisant des frameworks comme Hadoop, MapReduce et Spark pour traiter efficacement de grands ensembles de données sur des clusters de calcul distribué. À la fin de cette série, vous aurez acquis suffisamment de connaissances sur ces sujets pour les appliquer à vos projets en toute confiance !
Dans ce premier article, j’introduirai le concept de données, la typologie des données, leurs principales caractéristiques et leur impact sur notre mode de vie moderne.
Qu’est-ce que la donnée ?
Les organisations modernes considèrent les données comme leur actif le plus précieux, car elles fournissent des informations sur le comportement des clients, les tendances du marché, les performances des produits et bien d’autres aspects qui aident à prendre des décisions éclairées sur l’allocation des ressources. C’est pourquoi les entreprises investissent souvent dans la collecte ou l’achat de données auprès de sources tierces pour obtenir un avantage concurrentiel.
La donnée est toute information que vous collectez et qui a été organisée et structurée pour en faire un matériau utile à l’analyse. Des données sont collectées chaque fois que vous effectuez un achat, naviguez sur un site web, voyagez, passez un appel téléphonique ou publiez sur un réseau social. Les données peuvent provenir de nombreuses sources, notamment des capteurs, des enquêtes, des expériences, des observations ou des enregistrements existants (données historiques), tels que des transactions financières. Jamais auparavant autant de données sur autant de sujets différents n’ont été collectées et stockées chaque seconde de chaque journée.

La théorie de l’information a poussé le concept de données bien plus loin (Shannon, 1948). La théorie de l’information est un domaine d’étude qui cherche à comprendre la nature et l’origine de l’information, et selon cette étude : tout peut être considéré comme une donnée. Cela inclut les objets physiques et les concepts abstraits tels que les idées ou les émotions. De plus, une donnée est définie comme tout ensemble de symboles qui transmet un sens lorsqu’il est interprété par un récepteur. Par conséquent, tout ce qui possède une forme de représentation symbolique (par exemple, des séquences d’ADN, des mots, des chiffres) pourrait être classifié comme une donnée dans ce contexte.

Types de données
Les données peuvent être classifiées différemment selon la perspective choisie (par valeur, vélocité, structure ou sensibilité…). D’un point de vue purement statistique, les données peuvent appartenir à deux grandes catégories selon leur valeur :
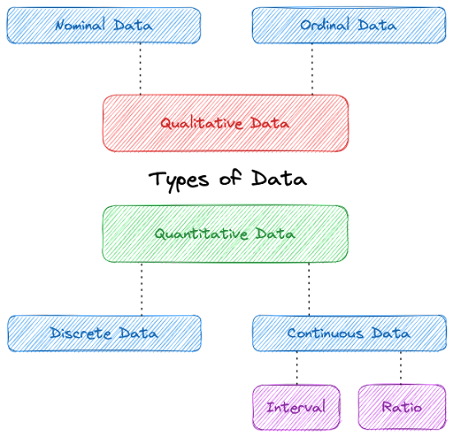
- Données quantitatives (numériques) : toute information pouvant être exprimée, mesurée et comparée à l’aide de valeurs numériques, telles que des entiers ou des nombres réels. Des exemples de données quantitatives incluent la taille, le poids, la longueur, les relevés de température, la taille d’une population, ou des éléments dénombrables comme le nombre d’élèves dans une classe. Ce type de données peut être subdivisé en Discrètes (nombres entiers) ou Continues (décimales).
- Données continues : données quantitatives pouvant être subdivisées de manière significative en niveaux plus fins. Elles peuvent être mesurées sur une échelle ou un continuum. Elles peuvent prendre presque n’importe quelle valeur numérique : toute valeur dans un intervalle fini ou infini (intervalle) ou une valeur qui compare deux nombres ou plus (ratio). En exemples, on trouve la taille, le poids, la température, la vitesse, l’IMC et le temps.
- Données discrètes : composées de valeurs numériques finies et dénombrables. Les valeurs discrètes ne peuvent pas être subdivisées en parties. Les variables discrètes comprennent les comptages (par ex., le nombre d’enfants dans un foyer), le nombre total de produits, ou des indicateurs binaires (oui/non, vrai/faux).
- Données qualitatives (catégorielles) : informations non numériques telles que les opinions, les sentiments, les perceptions et les attitudes. Ces données peuvent répondre à des questions telles que : « Comment cela s’est-il produit ? » ou « Pourquoi cela s’est-il produit ? ». Des exemples de données qualitatives incluent le genre, les classements, les énumérations, etc. Ce type de données peut être subdivisé en Nominales ou Ordinales.
- Données nominales : un type de données catégorielles qui n’a ni valeur numérique ni ordre. Il est composé de noms, d’étiquettes ou de catégories qui classifient et organisent les informations en groupes distincts. Comme exemples, on peut citer le genre (masculin/féminin), la nationalité (marocain/français) et les couleurs (vert/bleu).
- Données ordinales : ce type de données possède un ordre ou un classement associé. Comme exemples : des classements tels que 1er, 2e et 3e ; des notes comme A+, B- et C/D ; et des évaluations de type élevé-moyen-faible.
Sur le plan statistique, les variables qualitatives doivent être transformées en variables indicatrices (dummy variables) avant toute analyse. Par exemple, on pourrait artificiellement attribuer des chiffres à des catégories. Si vos catégories sont des couleurs, on pourrait attribuer le chiffre 1 au rouge et 2 au bleu, mais ces chiffres n’ont aucune signification mathématique. On ne conclurait pas que le bleu vaut deux fois le rouge !
 Types de données
Types de données
Impact des données
Données… Information… Connaissance. Quelle est la différence ? Le modèle DIKW (Rowley, 2007) répond à cette question et à la question sous-jacente : quelle est la finalité des données ?
Le modèle DIKW décrit la relation entre les Données, l’Information, la Connaissance (Knowledge) et la Sagesse (Wisdom). Les données peuvent être considérées comme la matière première d’une prise de décision éclairée, car elles fournissent une base objective pour tirer des conclusions ou prendre des décisions. En analysant de grandes quantités de données de différentes manières, par exemple par le biais d’analyses statistiques ou d’algorithmes de machine learning, on peut découvrir des patterns dans les données qui n’étaient pas évidents auparavant. Ces informations sont ensuite traitées en insights significatifs, formant la base des processus de prise de décision. Enfin, la sagesse intervient lorsque ces insights sont appliqués avec expérience et jugement, permettant de faire un choix éclairé sur la prochaine action à entreprendre (prendre des décisions plus éclairées sur les stratégies et actions futures).

Ainsi, les données créent de la valeur en fournissant des informations et des insights qui peuvent être utilisés pour prendre des décisions éclairées. Les données aident les organisations à identifier des tendances, à mesurer les performances, à optimiser les processus, à améliorer l’expérience client et à stimuler l’innovation. Elles permettent également aux entreprises d’acquérir un avantage concurrentiel sur le marché grâce à de meilleures capacités décisionnelles fondées sur l’analyse des données.
J’ai profondément apprécié la puissance et l’impact des données. Présenter des preuves concrètes sous forme de données, avec des titres comparables, permet vraiment à l’équipe de se sentir à l’aise, dans l’ensemble, avec la façon dont nous prévoyons l’activité.
Tout au long des différentes parties de cette série, vous embarquerez dans ce voyage et apprendrez comment les données se transforment et s’enrichissent, depuis les signaux collectés, les mesures et les faits, vers un modèle d’actions orienté par la décision.
Caractéristiques des données
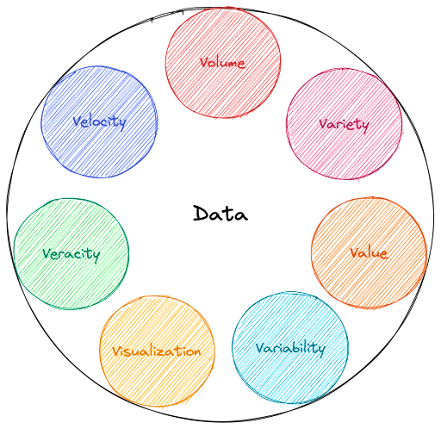
Au début de ce siècle, les données n’étaient étudiées qu’à travers trois caractéristiques, connues sous le nom des trois V des données : Volume, Vélocité et Variété. Au fil du temps, deux autres V (valeur et véracité) ont été ajoutés pour aider les data scientists et les managers à mieux articuler et communiquer les caractéristiques essentielles des données avec lesquelles ils travaillent.
Les cinq principales caractéristiques innées des données sont :
- Volume : la quantité de données qu’une organisation génère et stocke.
- Vélocité : désigne la rapidité avec laquelle les données sont générées, se déplacent et peuvent être traitées pour produire des insights exploitables.
- Variété : désigne la diversité des données. Les organisations peuvent collecter des données provenant de multiples sources, qui peuvent varier en termes de format. Les données collectées peuvent être structurées, semi-structurées ou non structurées.
- Véracité : désigne le niveau de confiance et de fiabilité des données collectées. En termes simples, la qualité et l’exactitude des données. Les données collectées peuvent comporter des lacunes, être inexactes ou ne pas apporter de valeur réelle.
- Valeur : désigne la valeur que les données peuvent apporter, et ce que les organisations peuvent en faire. Cette caractéristique donne directement la signification et le contexte qu’une organisation peut attribuer aux données collectées.
En marketing, les experts métier (SME) ont commencé à utiliser deux caractéristiques supplémentaires qui ne sont pas innées aux données, mais qui peuvent avoir un impact significatif sur les insights générés. Ces deux caractéristiques sont :
- Variabilité : une mesure de la variation des valeurs au sein de chaque variante de données. Ce concept est lié au contexte des données et au sens qui leur est attribué. Dans une organisation, ce sens peut constamment changer, ce qui a un impact significatif sur l’homogénéisation des données. Ce concept diffère de la variété : imaginez un café qui propose six mélanges différents de café (c’est la variété), mais si vous prenez le même mélange chaque jour et qu’il a un goût différent chaque jour, c’est la variabilité.
- Visualisation : la visualisation est essentielle dans le monde actuel. Utiliser des graphiques et des diagrammes pour visualiser de grandes quantités de données complexes est beaucoup plus efficace pour transmettre du sens que les données brutes dans des feuilles de calcul remplies de chiffres et de formules.
 Les 7 V des données
Les 7 V des données
Résumé
- Une donnée est un ensemble d’observations et de faits, matérialisés par des valeurs ou des mesures et organisés pour en faire un matériau utile à l’analyse.
- Les données sont partout et peuvent être qualitatives (descriptives) ou quantitatives (numériques).
- Les données n’ont pas de signification en elles-mêmes ; elles doivent être mises en contexte, interprétées et analysées pour en tirer des insights. Elles doivent également contenir suffisamment d’informations pour que des conclusions significatives puissent être tirées et que des actions puissent être entreprises.
- Les données possèdent différentes caractéristiques. Dans les articles suivants, nous verrons que chaque caractéristique a un impact important sur le parcours des données. Chaque action effectuée sur les données (qu’il s’agisse de la collecte, du stockage, du traitement, de la visualisation ou de l’interprétation) dépend des 7 V des données.
Références
- Claude E. Shannon. “A Mathematical Theory of Communication”. The Bell System Technical Journal, Vol. 27, pp. 379–423, 623–656, July, October, 1948.
- Rowley, Jennifer E.. “The wisdom hierarchy: representations of the DIKW hierarchy.” Journal of Information Science 33 (2007): 163 - 180.
- “The 7 V’s of Big Data”, Matt Moore