
Comme je l’ai expliqué dans les derniers articles, l’architecture de données est un composant central de toute stratégie de données. Il n’est donc pas surprenant que le choix de la bonne architecture de données soit une priorité absolue pour de nombreuses organisations.
Les architectures de données peuvent être classifiées selon la vélocité des données. Les deux architectures basées sur la vélocité les plus populaires sont Lambda et Kappa. Les architectures de données peuvent également être classifiées selon leur mode opérationnel ou topologie. Le Data Fabric, le Data Hub et le Data Mesh sont les trois principales architectures que nous aborderons dans cette classification.
Dans cet article, je plongerai en profondeur dans les caractéristiques clés de ces architectures et fournirai une comparaison pour vous aider à décider laquelle correspond le mieux à vos besoins métier. Que vous soyez data scientist, ingénieur ou chef d’entreprise, ce guide vous apportera des informations précieuses sur les avantages et les inconvénients de chaque architecture et vous aidera à prendre une décision éclairée sur laquelle choisir.
Qu’est-ce que l’architecture de données ?
L’architecture de données fait partie de l’architecture d’entreprise, dont elle hérite les principales propriétés : les processus, la stratégie, la gestion du changement et l’évaluation des compromis. Selon TOGAF, l’architecture de données est : « Une description de la structure et de l’interaction des principaux types et sources de données de l’entreprise, des actifs de données logiques, des actifs de données physiques et des ressources de gestion des données. »
Le DAMA DMBOOK définit l’architecture de données comme le processus « d’identification des besoins en données de l’entreprise (quelle que soit leur structure) et de conception et de maintenance des plans directeurs pour répondre à ces besoins. Utiliser ces plans directeurs pour guider l’intégration des données, contrôler les actifs de données et aligner les investissements en données sur la stratégie métier. »
En tenant compte des deux définitions précédentes, nous pouvons définir l’architecture de données comme la conception du plan directeur pour les actifs de données organisationnelles, en cartographiant les processus et les outils pour soutenir la prise de décision de l’organisation.
Qu’est-ce qui fait une « bonne » architecture de données ?
On reconnaît ce qui est « bon » lorsqu’on voit le pire. Une mauvaise architecture de données est fortement couplée, rigide, trop centralisée et utilise les mauvais outils pour le travail, freinant le développement et la gestion du changement. Une bonne architecture de données doit principalement répondre aux exigences métier avec un ensemble d’éléments de construction largement réutilisables, tout en préservant des meilleures pratiques (principes) bien définies et en faisant les compromis appropriés. Nous nous inspirons pour les principes d’une « bonne » architecture de données de plusieurs sources, notamment le AWS Well-Architected Framework. Il comprend six piliers :
- Excellence opérationnelle : les processus opérationnels qui maintiennent un système en production.
- Sécurité : la protection des applications et des données contre les menaces.
- Fiabilité : la capacité d’un système à se remettre des pannes et à continuer à fonctionner.
- Efficacité des performances : la capacité d’un système à s’adapter aux changements de charge.
- Optimisation des coûts : la gestion des coûts pour maximiser la valeur livrée.
- Durabilité : la minimisation des impacts environnementaux liés à l’exécution des charges de travail du système.
Dans les prochains articles, nous évaluerons les outils, solutions et architectures de données au regard de cet ensemble de principes.
Parce que l’architecture de données est une discipline abstraite, il est utile de raisonner par catégories d’architecture. La section suivante présente des exemples et des types d’architectures de données célèbres aujourd’hui. Nous les avons classifiés de deux manières différentes : par vélocité des données et par topologie. Bien que cet ensemble d’exemples ne soit pas exhaustif, l’intention est de vous exposer à certains des patterns d’architecture de données les plus courants et de donner un aperçu de l’analyse des compromis nécessaire lors de la conception d’une bonne architecture pour votre cas d’usage.
Architectures de données basées sur la vélocité
La vélocité des données désigne la rapidité avec laquelle les données sont générées et peuvent être traitées pour produire des insights exploitables. Selon la vélocité des données qu’elles traitent, les architectures de données peuvent être classifiées en deux catégories : Lambda et Kappa.
Dans ce chapitre, je décris les deux architectures plus en détail : leurs différences, les technologies que nous pouvons utiliser pour les réaliser, et les points de basculement qui nous amèneront à décider d’utiliser l’une ou l’autre.
1 - Architecture de données Lambda
Le terme « Lambda » est dérivé du calcul lambda (λ) qui décrit une fonction s’exécutant dans le calcul distribué sur plusieurs nœuds en parallèle. L’architecture de données Lambda a été conçue pour fournir un système évolutif, tolérant aux pannes et flexible pour traiter de grandes quantités de données, permettant l’accès aux méthodes de traitement par lots (batch) et de traitement en flux (stream) de manière hybride. Elle a été développée en 2011 par Nathan Marz, le créateur d’Apache Storm, pour résoudre les défis du traitement de données en temps réel à grande échelle.
L’architecture Lambda est une architecture idéale lorsque vous avez une grande variété de charges de travail et de vélocités. Elle peut gérer de grands volumes de données et fournir des résultats de requêtes à faible latence, ce qui la rend adaptée aux applications d’analyse en temps réel comme les tableaux de bord et les rapports. De plus, cette architecture est utile pour le traitement par lots (par ex., le nettoyage, la transformation ou l’agrégation de données), pour les tâches de traitement en flux (par ex., la gestion d’événements, le développement de modèles de machine learning, la détection d’anomalies ou la prévention des fraudes), et pour la construction de référentiels centralisés connus sous le nom de « data lakes » pour stocker des informations structurées/non structurées.
La caractéristique critique de l’architecture Lambda est qu’elle utilise deux systèmes de traitement séparés pour gérer différents types de charges de travail. Le premier est un système de traitement par lots, qui traite les données en grands lots et stocke les résultats dans un store de données centralisé (par ex., un data warehouse ou un data lake). Le deuxième système est un système de traitement en flux, qui traite les données en temps réel au fur et à mesure de leur arrivée et stocke les résultats dans un store de données distribué.
L’architecture Lambda résout le problème du calcul de fonctions arbitraires : évaluer la fonction de traitement de données pour toute entrée donnée (en différé ou en temps réel). De plus, elle fournit une tolérance aux pannes en garantissant que les résultats de l’un ou l’autre système peuvent être utilisés comme entrée dans l’autre en cas de défaillance ou d’indisponibilité. L’efficacité de cette architecture se manifeste sous la forme d’un débit élevé, d’une faible latence et d’applications quasi-temps réel.
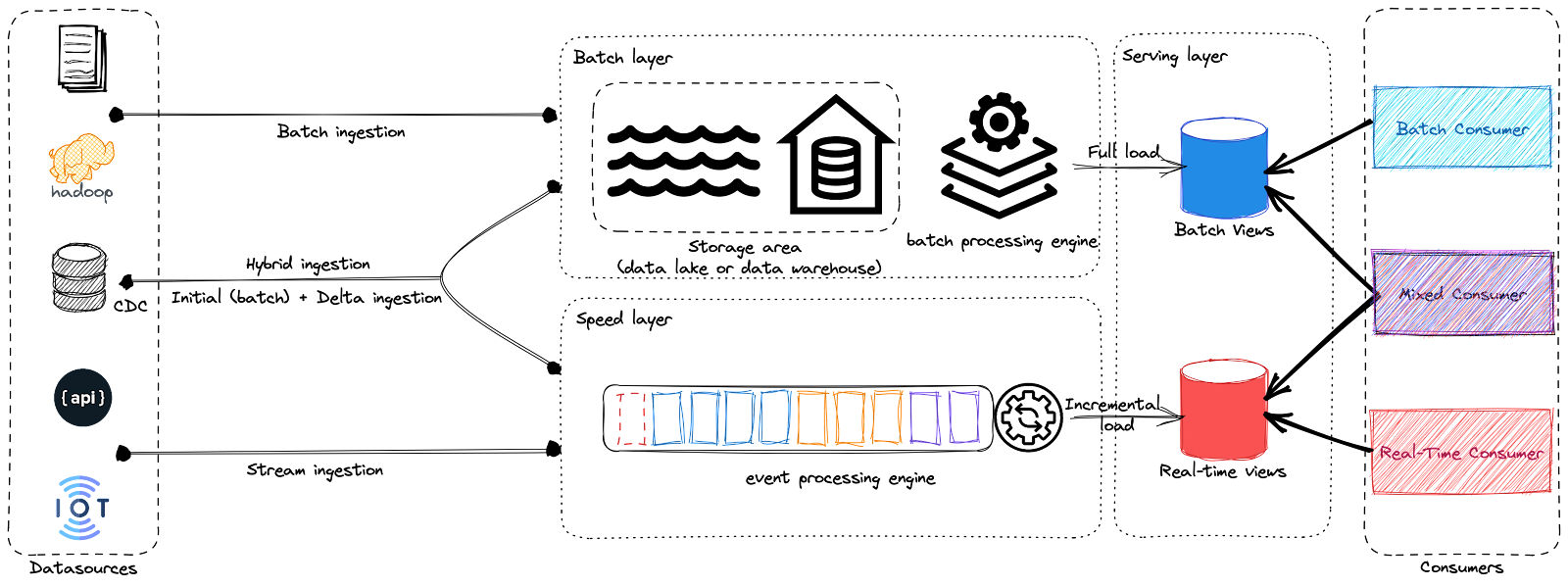
Dans le diagramme ci-dessus, vous pouvez voir les composants principaux de l’architecture Lambda. Elle comprend la couche d’ingestion, la couche batch, la couche de vitesse (ou couche stream) et la couche de service.
- Couche Batch : la couche de traitement par lots est conçue pour gérer de grands volumes de données historiques et stocker les résultats dans un store de données centralisé, tel qu’un data warehouse ou un système de fichiers distribué. Cette couche utilise des frameworks comme Hadoop ou Spark pour un traitement efficace de l’information, lui permettant de fournir une vue globale de toutes les données disponibles.
- Couche de vitesse (Speed Layer) : la couche de vitesse est conçue pour gérer les flux de données à haute vélocité et fournir des vues de données actualisées en utilisant des moteurs de traitement d’événements, tels qu’Apache Flink ou Apache Storm. Cette couche traite les données en temps réel entrant et stocke les résultats dans un store de données distribué tel qu’une file de messages ou une base de données NoSQL.
- Couche de service (Serving Layer) : la couche de service de l’architecture Lambda est essentielle pour offrir aux utilisateurs un accès cohérent et fluide aux données, quel que soit le système de traitement sous-jacent. De plus, elle joue un rôle important en activant les applications en temps réel comme les tableaux de bord et les analyses qui nécessitent un accès rapide aux informations actuelles.
Bien que les architectures Lambda offrent de nombreux avantages, tels que la scalabilité, la tolérance aux pannes et la flexibilité pour gérer une large gamme de charges de travail de traitement de données (lots et flux), elles comportent également des inconvénients que les organisations doivent considérer avant de décider de les utiliser ou non. En fait, l’architecture Lambda est un système complexe qui utilise plusieurs stacks technologiques pour traiter et stocker les données. De plus, la logique sous-jacente est dupliquée dans les couches Batch et Speed pour chaque étape. Il peut être difficile à configurer et à maintenir, surtout pour les organisations disposant de ressources limitées. De plus, cette duplication a un coût : les incohérences de données, car bien qu’ayant la même logique, l’implémentation est différente d’une couche à l’autre. Ainsi, la probabilité d’erreurs/bugs est définitivement plus élevée, et vous pouvez obtenir des résultats différents des couches batch et speed.
2 - Architecture de données Kappa
En 2014, alors qu’il travaillait encore chez LinkedIn, Jay Kreps a lancé une discussion dans laquelle il a souligné certains inconvénients de l’architecture Lambda. Cette discussion a conduit la communauté big data vers une autre alternative utilisant moins de ressources de code.
L’idée principale derrière cela est qu’une seule stack technologique peut être utilisée pour le traitement de données en temps réel et par lots. Cette architecture a été appelée Kappa. L’architecture Kappa tire son nom de la lettre grecque « Kappa » (ϰ), utilisée en mathématiques pour représenter une « boucle » ou un « cycle ». Le nom reflète l’accent mis par l’architecture sur le traitement ou le retraitement continu des données plutôt qu’une approche basée sur les lots. En son cœur, elle repose sur une architecture de streaming : les données entrantes sont d’abord stockées dans un journal de streaming d’événements, puis traitées en continu par un moteur de traitement en flux, comme Kafka, soit en temps réel soit ingérées dans n’importe quelle autre base de données analytique ou application métier en utilisant divers paradigmes de communication tels que le temps réel, le quasi-temps réel, le batch, le micro-batch et la requête-réponse.
L’architecture Kappa est conçue pour fournir un système évolutif, tolérant aux pannes et flexible pour traiter de grandes quantités de données en temps réel. L’architecture Kappa est considérée comme une alternative plus simple à l’architecture Lambda car elle utilise une seule stack technologique pour gérer les charges de travail en temps réel et historiques, en traitant tout comme des flux. La principale motivation derrière la création de l’architecture Kappa était d’éviter la maintenance de deux bases de code séparées (pipelines) pour les couches batch et speed. Cela lui permet de fournir un pipeline de traitement de données plus rationalisé et simplifié tout en offrant un accès rapide et fiable aux résultats des requêtes.

L’exigence la plus importante pour Kappa était le retraitement des données, rendant visibles les effets des changements de données sur les résultats. Par conséquent, l’architecture Kappa ne comprend que deux couches : la couche stream et la couche de service.
Dans l’architecture Kappa, il n’y a qu’une seule couche de traitement : la couche de traitement en flux. Cette couche est responsable de la collecte, du traitement et du stockage des données en streaming en direct. Cette approche élimine le besoin de systèmes de traitement par lots en utilisant un moteur de traitement en flux avancé tel qu’Apache Flink, Apache Storm, Apache Kafka ou Apache Kinesis pour gérer de grands volumes de flux de données et fournir un accès rapide et fiable aux résultats des requêtes. La couche de traitement en flux est divisée en deux composants : le composant d’ingestion, qui collecte les données de diverses sources, et le composant de traitement, qui traite ces données entrantes en temps réel.
- Composant d’ingestion : cette couche collecte les données entrantes de diverses sources, telles que les journaux, les transactions de bases de données, les capteurs et les API. Les données sont ingérées en temps réel et stockées dans un store de données distribué, tel qu’une file de messages ou une base de données NoSQL.
- Composant de traitement : le composant de traitement de l’architecture Kappa est responsable de la gestion des flux de données à fort volume et de la fourniture d’un accès rapide et fiable aux résultats des requêtes. Il utilise des moteurs de traitement d’événements, tels qu’Apache Flink ou Apache Storm, pour traiter les données entrantes en temps réel et les données historiques provenant d’une zone de stockage avant de les stocker dans un store de données distribué.
De nos jours, les données en temps réel l’emportent sur les données lentes. C’est vrai pour presque chaque cas d’usage. Néanmoins, l’architecture Kappa ne peut pas être considérée comme un substitut à l’architecture Lambda. Au contraire, elle doit être vue comme une alternative à utiliser dans les circonstances où la performance active de la couche batch n’est pas nécessaire pour atteindre le niveau de qualité de service standard.
Bien que les architectures Kappa offrent les promesses de scalabilité, de tolérance aux pannes et de gestion rationalisée (plus simple à configurer et à maintenir par rapport à Lambda), elles présentent également des inconvénients que les organisations doivent considérer attentivement. L’architecture Kappa est théoriquement plus simple que Lambda, mais peut rester techniquement complexe pour les entreprises peu familières avec les frameworks de traitement en flux. Cependant, le principal inconvénient de Kappa, de mon point de vue, est le coût de l’infrastructure lors de la mise à l’échelle de la plateforme de streaming d’événements. Stocker de grands volumes de données dans une plateforme de streaming d’événements peut être coûteux et soulever d’autres problèmes de scalabilité, notamment lors du traitement de téraoctets ou de pétaoctets. De plus, la différence entre le temps d’événement et le temps de traitement peut entraîner des données arrivant en retard, ce qui peut représenter un grand défi pour une architecture Kappa : besoin de watermarking, gestion des états, retraitement, backfill…
3 - Modèle Dataflow
Lambda et Kappa ont émergé comme des tentatives pour surmonter les lacunes de l’écosystème Hadoop dans les années 2010 en essayant d’intégrer des outils complexes qui n’étaient pas intrinsèquement compatibles. Cependant, les deux approches ont eu du mal à résoudre le défi fondamental consistant à réconcilier les données batch et streaming. Malgré cela, Lambda et Kappa ont fourni une inspiration et une base pour des avancées supplémentaires dans la quête d’une solution plus unifiée.
Unifier plusieurs chemins de code est l’un des défis les plus importants lors de la gestion du traitement par lots et en flux. Même avec la couche de mise en file d’attente et de stockage unifiée de l’architecture Kappa, les ingénieurs sont toujours confrontés au défi d’utiliser différents outils pour collecter des statistiques en temps réel et exécuter des tâches d’agrégation par lots. Aujourd’hui, les ingénieurs travaillent à relever ce défi de différentes manières. Par exemple, Google a réalisé des progrès significatifs en développant le modèle Dataflow et le framework Apache Beam, qui implémente ce modèle.
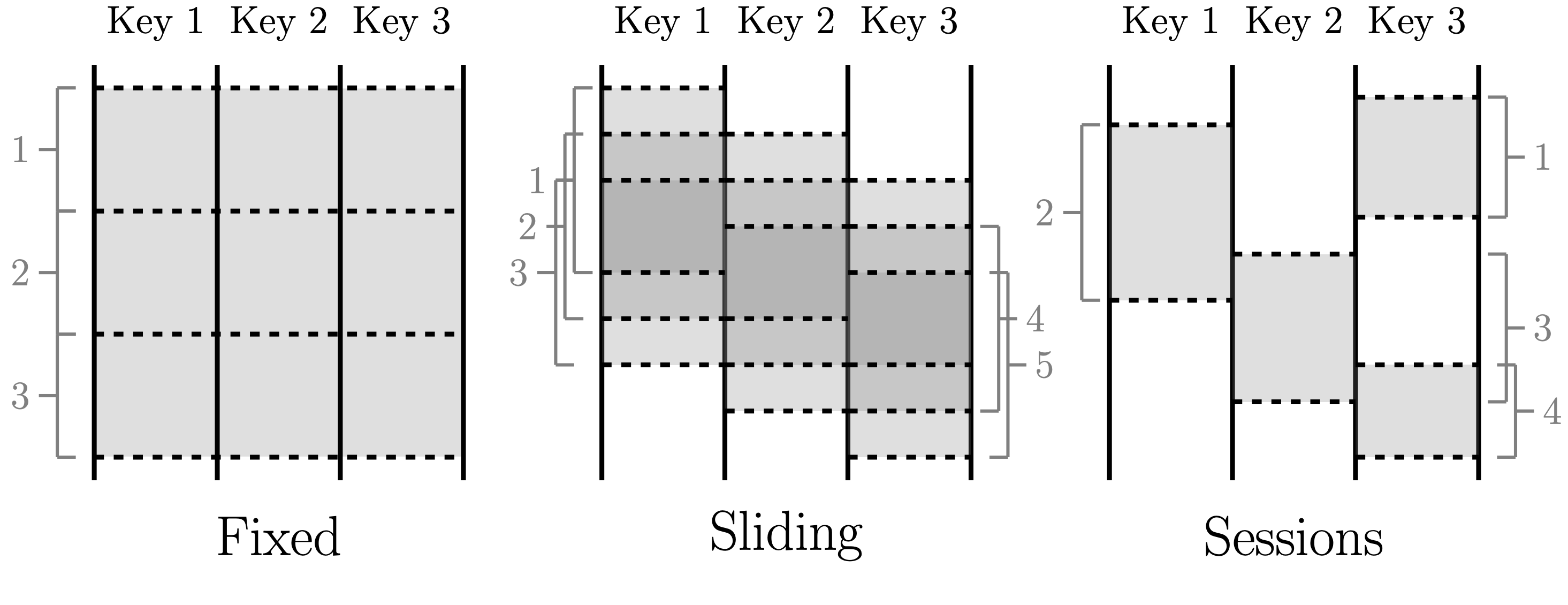 Patterns de fenêtrage.
Patterns de fenêtrage.
Le concept fondamental du modèle Dataflow est de traiter toutes les données comme des événements et d’effectuer des agrégations sur différents types de fenêtres. Les flux d’événements en temps réel sont des données non bornées, tandis que les lots de données sont des flux d’événements bornés qui ont des fenêtres naturelles. Les ingénieurs peuvent choisir parmi différentes fenêtres, telles que glissantes ou à basculement, pour l’agrégation en temps réel. Le modèle Dataflow permet au traitement en temps réel et par lots de se produire dans le même système, en utilisant du code presque identique. L’idée du « batch comme cas particulier du streaming » est devenue de plus en plus répandue, avec des frameworks comme Flink et Spark adoptant des approches similaires.
4 - Architecture pour l’IoT
L’Internet des Objets (IoT) est un réseau d’appareils physiques, de véhicules, d’appareils électroménagers et d’autres objets (alias « choses ») intégrés avec des capteurs, des logiciels et une connectivité qui leur permet de collecter et d’échanger des données. Ces appareils peuvent être n’importe quoi, des appareils électroménagers intelligents aux machines industrielles en passant par les dispositifs médicaux, et ils sont tous connectés à Internet. Les données collectées par les appareils IoT peuvent être utilisées à diverses fins, telles que la surveillance et le contrôle à distance des appareils, l’optimisation des processus, l’amélioration de l’efficacité et de la productivité, et la création de nouveaux services et modèles d’affaires. Les données IoT sont générées par des appareils qui collectent périodiquement ou en continu des données de l’environnement environnant et les transmettent à une destination. Les appareils IoT sont souvent à faible consommation d’énergie et opèrent dans des environnements à faibles ressources/faible bande passante.
Bien que le concept d’appareils IoT remonte à plusieurs décennies, l’adoption massive des smartphones a créé une immense armée d’appareils IoT presque du jour au lendemain. Depuis lors, diverses nouvelles catégories d’appareils IoT ont émergé, notamment les thermostats intelligents, les systèmes de divertissement automobile, les téléviseurs intelligents et les enceintes connectées. L’IoT peut potentiellement révolutionner de nombreux secteurs, notamment la santé, la fabrication, le transport et l’énergie. Il est passé d’un concept futuriste à un domaine important de l’ingénierie des données. On s’attend à ce qu’il devienne l’une des principales façons dont les données sont générées et consommées.
Les architectures pour l’IoT sont des architectures orientées événements qui englobent la capacité de créer, mettre à jour et déplacer de manière asynchrone des événements à travers diverses parties du parcours de données. Ce workflow implique trois domaines principaux : la production d’événements, le routage et la consommation. Un événement doit être produit et acheminé vers quelque chose qui le consomme sans dépendances fortement couplées entre le producteur, le routeur d’événements et le consommateur.
Un producteur d’événements est un appareil dans cette architecture, qui n’est pas utile à moins que vous ne puissiez récupérer ses données. Ainsi, une passerelle IoT est un composant critique qui collecte et achemine de manière sécurisée les données des appareils vers les destinations appropriées sur Internet. À partir de là, les événements et les mesures peuvent s’écouler dans une architecture d’ingestion d’événements avec tous les défis qu’elle apporte, par exemple, les données arrivant en retard, les disparités de structure et de schema des données, la corruption des données et les interruptions de connexion.

Ensuite, les exigences de stockage pour un système IoT varieront considérablement selon les exigences de latence des appareils IoT. Par exemple, si des capteurs distants collectent des données scientifiques qui seront analysées ultérieurement, un stockage d’objets par lots peut être suffisant. Inversement, si un backend système analyse en permanence des données dans une solution de surveillance à domicile ou d’automatisation, des réponses quasi-temps réel peuvent être nécessaires. Une file de messages ou une base de données de séries temporelles serait plus appropriée dans de tels cas. Les supports de stockage en mémoire sont préférables pour une faible latence.
Tout comme l’architecture Kappa, la couche de service est une vue en temps réel permettant aux utilisateurs d’accéder de manière cohérente et fluide aux données IoT. Elle joue un rôle important en activant les applications en temps réel comme les tableaux de bord et les analyses qui nécessitent un accès rapide aux informations actuelles.
Architectures de données basées sur la topologie
Le débat entre les architectes de données s’est concentré sur les mérites des ontologies de données existantes. Alors que les architectures de données peuvent être regroupées en fonction de la vélocité des données, comme nous l’avons vu avec Lambda et Kappa, une autre façon de les classer est le modèle opérationnel ou la topologie des données, qui est agnostique à la technologie. Rappelons que trois types de modèles opérationnels peuvent exister dans n’importe quelle organisation (Data 101 - partie 2) : centralisé, décentralisé et hybride.
Dans ce chapitre, je décris trois architectures de données basées sur la topologie plus en détail : le data fabric, le data mesh et le data hub.
1 - Architectures de données centralisées : le Data Hub
Un data hub est une architecture permettant de gérer les données de manière centralisée. Il peut être décrit comme un échange de données avec un flux de données sans friction en son cœur. Il agit comme un référentiel central d’informations avec des connexions à d’autres systèmes et clients, permettant le partage de données entre eux. Les points d’accès interagissent avec le Data Hub en lui fournissant des données ou en en recevant, et le hub fournit un point de médiation et de gestion, rendant visible la façon dont les données circulent dans l’entreprise. Une architecture de data hub facilite cet échange en connectant les producteurs et les consommateurs de données. Le travail fondateur derrière l’architecture de data hub était un article de recherche Gartner publié en 2017. Dans cet article, Gartner a suggéré une architecture technologiquement neutre pour connecter les producteurs et les consommateurs de données, plus avantageuse que les alternatives point à point. Des recherches ultérieures ont développé davantage ce concept, aboutissant à la définition actuelle des attributs d’un data hub.
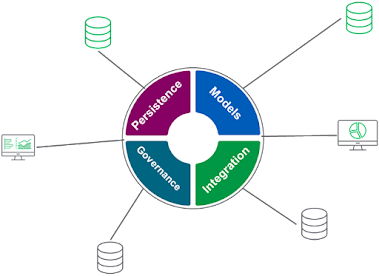
 Attributs du data hub.
Attributs du data hub.
Le hub est structuré et consommé selon les modèles définis par ses utilisateurs. Des politiques de gouvernance sont établies pour garantir la confidentialité des données, le contrôle d’accès, la sécurité, la rétention et la suppression sécurisée des informations. Des stratégies d’intégration telles que les API ou les processus ETL peuvent être utilisées pour travailler avec les données stockées dans le hub. La persistance définit quel type de base de données doit être utilisé pour stocker ces données (par ex., les bases de données relationnelles). La mise en œuvre d’une architecture de Data Hub facilite :
- La consolidation et la rationalisation des données les plus couramment utilisées en un point central,
- L’établissement d’un système de contrôle des données efficace pour améliorer la qualité des données,
- La garantie de la traçabilité sur les flux et l’offre d’une surveillance statistique de l’activité de l’entreprise,
- L’amélioration de la connaissance des données échangées,
- La construction progressive du modèle de données de l’entreprise.
 Data hub.
Data hub.
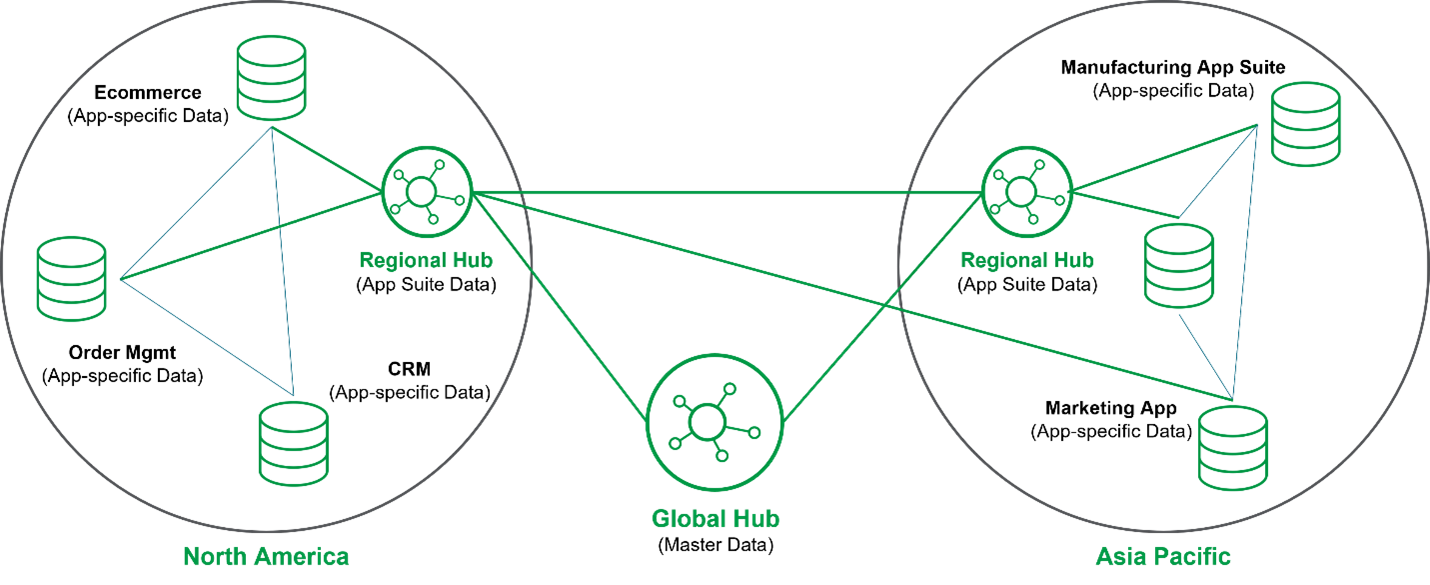
Gartner a proposé que des data hubs spécialisés et dédiés pourraient être utilisés à diverses fins. Celles-ci comprenaient des data hubs analytiques utilisés pour collecter et partager des informations pour les processus analytiques en aval ; des data hubs applicatifs utilisés comme contexte de domaine pour des applications ou des suites spécifiques ; des data hubs d’intégration conçus pour faciliter le partage de données via différents styles d’intégration ; des data hubs de données maîtres axés sur la distribution des données maîtres dans les systèmes opérationnels et les procédures de l’entreprise ; et enfin des data hubs de données de référence ayant des objectifs similaires mais limités en portée aux données de « référence » (par ex., les codes couramment utilisés).
La centralisation des données mise en œuvre dans les data hubs garantit que les données sont gérées depuis une source centrale, mais est conçue pour rendre les données accessibles depuis de nombreux points différents. Elle sert à minimiser les silos de données, à favoriser la collaboration et à fournir une visibilité sur les tendances émergentes et les impacts dans toute l’entreprise. Une vue centralisée des données aide à aligner la stratégie de données avec la stratégie métier en fournissant une vue à 360° des tendances, des insights et des prédictions afin que tout le monde dans l’organisation puisse aller dans la même direction.
Le défi de la centralisation des données est que les processus peuvent être lents sans accélérateurs ou une sorte de stratégie en libre-service. En conséquence, les demandes prennent de plus en plus de temps. L’entreprise ne peut pas avancer assez vite, et les opportunités d’améliorer l’expérience client et d’augmenter les revenus sont perdues simplement parce qu’elles ne peuvent pas être saisies rapidement.
Pour ces raisons, Gartner a récemment mis à jour le concept de data hub pour permettre aux organisations de faire fonctionner plusieurs hubs de manière interconnectée. De cette façon, le data hub pourrait tirer parti de la centralisation des données et exploiter la décentralisation en remettant plus de responsabilités et de pouvoir aux lignes métier.
L’utilisation la plus courante des data hubs est le data warehouse. Un data warehouse est un data hub central utilisé pour le reporting et l’analyse. Les données dans un data warehouse sont généralement très formatées et structurées pour les cas d’usage analytiques. En conséquence, c’est l’une des architectures de données les plus anciennes et les plus établies. En 1989, Bill Inmon a créé la notion de data warehouse, qu’il a décrit comme « une collection de données orientée sujet, intégrée, non volatile et variable dans le temps, en appui aux décisions de la direction. » Bien que les aspects techniques du data warehouse aient considérablement évolué, nous estimons que cette définition originale conserve toute sa valeur aujourd’hui.
Traditionnellement, un data warehouse extrait des données des systèmes applicatifs via ETL. La phase d’extraction tire les données des systèmes sources. Enfin, la phase de transformation nettoie et standardise les données, les organisant et imposant une logique métier sous une forme très modélisée. Nous publierons un article de blog dédié à la modélisation des données.
Une variante de l’ETL est l’ELT. Avec le mode ELT dans les architectures de data warehouse, les données sont déplacées plus ou moins directement des systèmes de production vers une zone de staging dans le data warehouse. Le staging dans ce contexte indique que les données sont sous forme brute. Plutôt que d’utiliser un système externe, les transformations sont gérées directement dans le data warehouse. Les données sont traitées par lots, et les résultats transformés sont écrits dans des tables et des vues pour l’analyse.

À l’ère du big data, le data lake est apparu comme une autre architecture centralisée largement utilisée. L’idée était de créer un référentiel central où tous les types de données structurées et non structurées pourraient être stockés sans contraintes structurelles strictes. Le data lake était destiné à habiliter les entreprises en fournissant un approvisionnement illimité de données. La version initiale du data lake, connue sous le nom de « data lake 1.0 », a débuté avec des systèmes distribués comme Hadoop (HDFS). À mesure que le cloud gagnait en popularité, ces data lakes ont migré vers le stockage d’objets dans le cloud, avec des coûts de stockage extrêmement bas et une capacité de stockage quasi illimitée. Plutôt que de s’appuyer sur un data warehouse monolithique où le stockage et le calcul sont étroitement couplés, le data lake stocke une immense quantité de données de n’importe quelle taille et type.
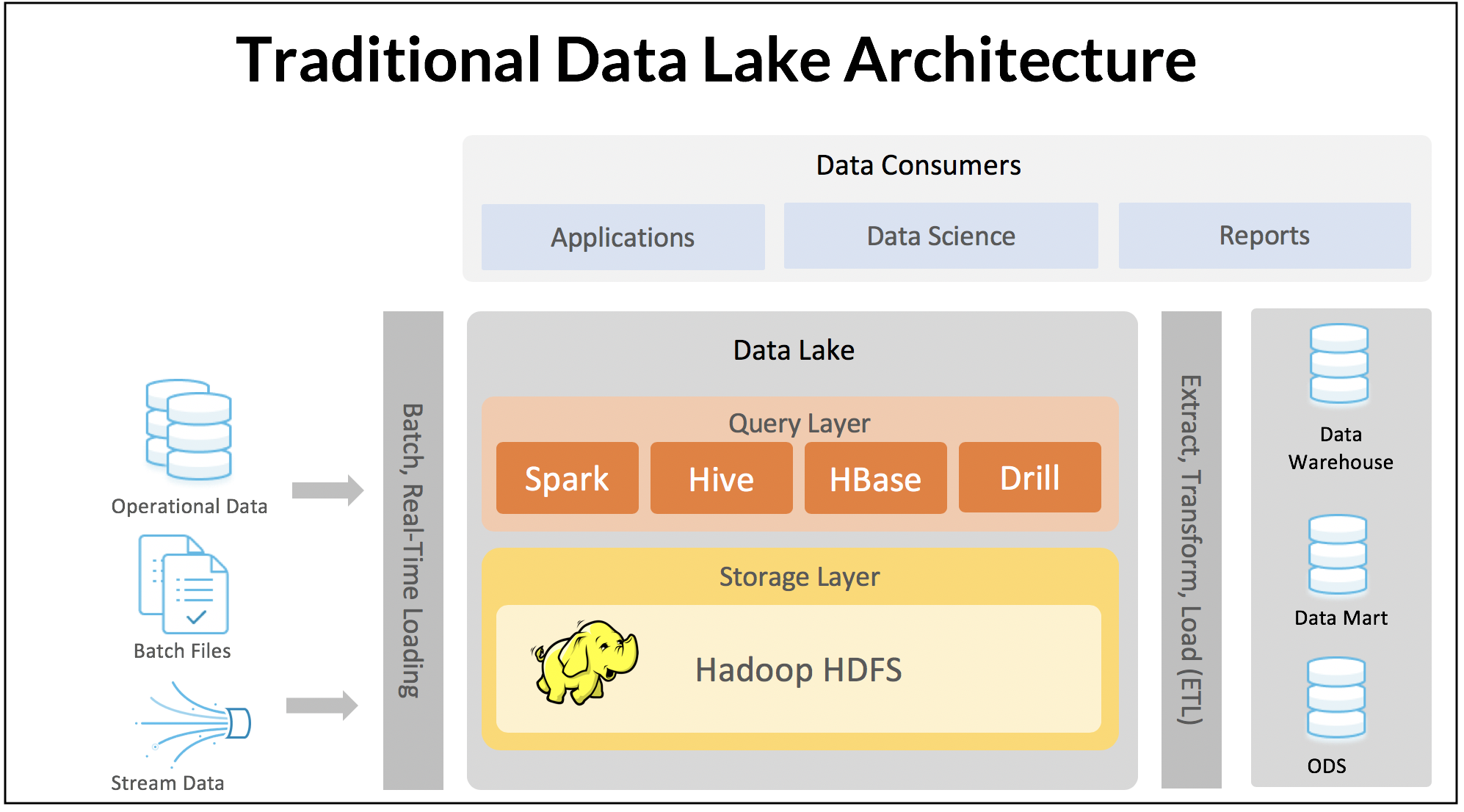 Data Lake 1.0.
Data Lake 1.0.
Malgré le battage médiatique et les bénéfices potentiels, la première génération de data lakes (data lake 1.0) présentait plusieurs inconvénients significatifs. Le data lake s’est essentiellement transformé en décharge de données, créant des termes tels que « data swamp » et « dark data », car de nombreux projets de données n’ont pas tenu leurs promesses initiales. La gestion des données est devenue de plus en plus difficile à mesure que le volume de données augmentait de façon exponentielle, et les outils de gestion des schémas, de catalogage des données et de découverte faisaient défaut. De plus, le concept original de data lake était essentiellement en écriture seule, créant d’énormes maux de tête avec l’arrivée de réglementations telles que le RGPD qui exigeaient la suppression ciblée d’enregistrements d’utilisateurs. Le traitement des données était également un défi majeur, avec des transformations de données relativement basiques, telles que les jointures, nécessitant l’implémentation de tâches MapReduce complexes.
Divers acteurs ont cherché à améliorer le concept pour réaliser pleinement sa promesse, en réponse aux limitations des data lakes de première génération. Par exemple, Databricks a introduit la notion de data lakehouse. Le lakehouse intègre les contrôles, la gestion des données et les structures de données que l’on trouve dans un data warehouse tout en hébergeant les données dans un stockage d’objets et en prenant en charge une variété de moteurs de requête et de transformation. En particulier, le data lakehouse prend en charge les transactions atomicité, cohérence, isolation et durabilité (ACID). C’est une rupture significative par rapport au data lake original, où vous versiez simplement des données et ne les mettiez jamais à jour ni ne les supprimiez. Le terme data lakehouse suggère une convergence entre les data lakes et les data warehouses.
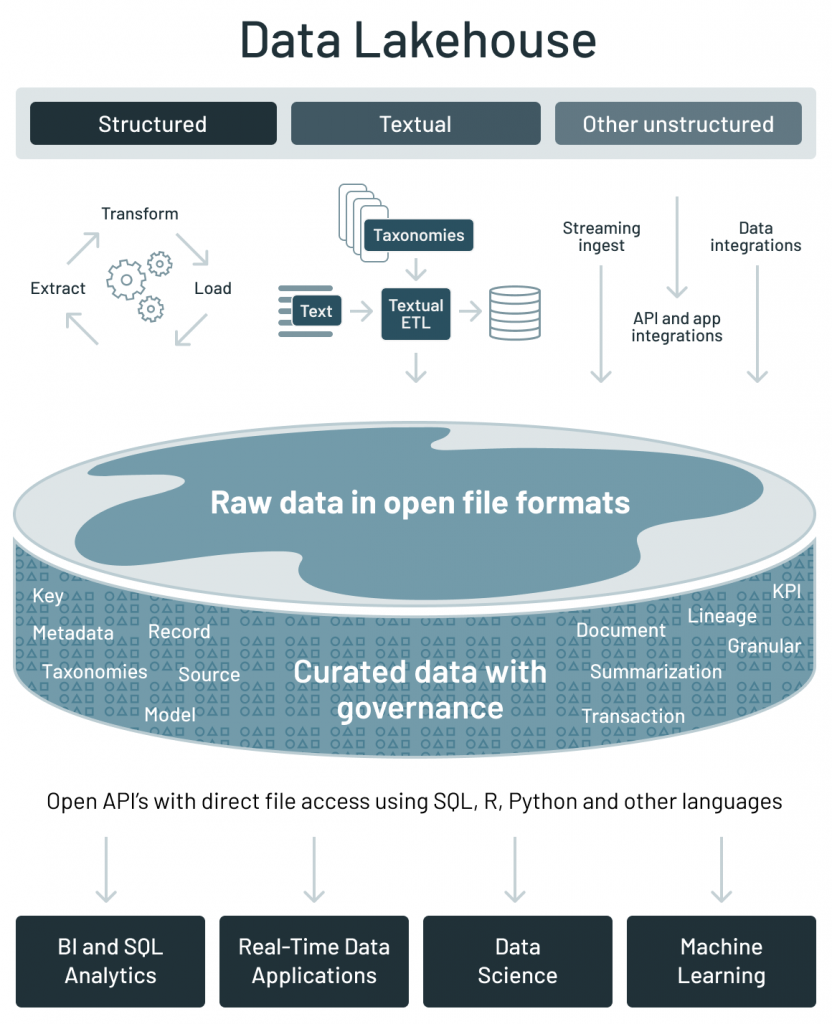 Data Lake + Data Warehouse = Data Lakehouse.
Data Lake + Data Warehouse = Data Lakehouse.
2 - Architectures de données décentralisées : le Data Fabric
La décentralisation des données est une approche de gestion des données qui élimine le besoin d’un référentiel central en distribuant le stockage, le nettoyage, l’optimisation, la production et la consommation des données dans différents départements organisationnels. Cela aide à réduire la complexité lors du traitement de grandes quantités de données et des problèmes tels que les changements de schema, les temps d’arrêt, les mises à niveau et la compatibilité ascendante.
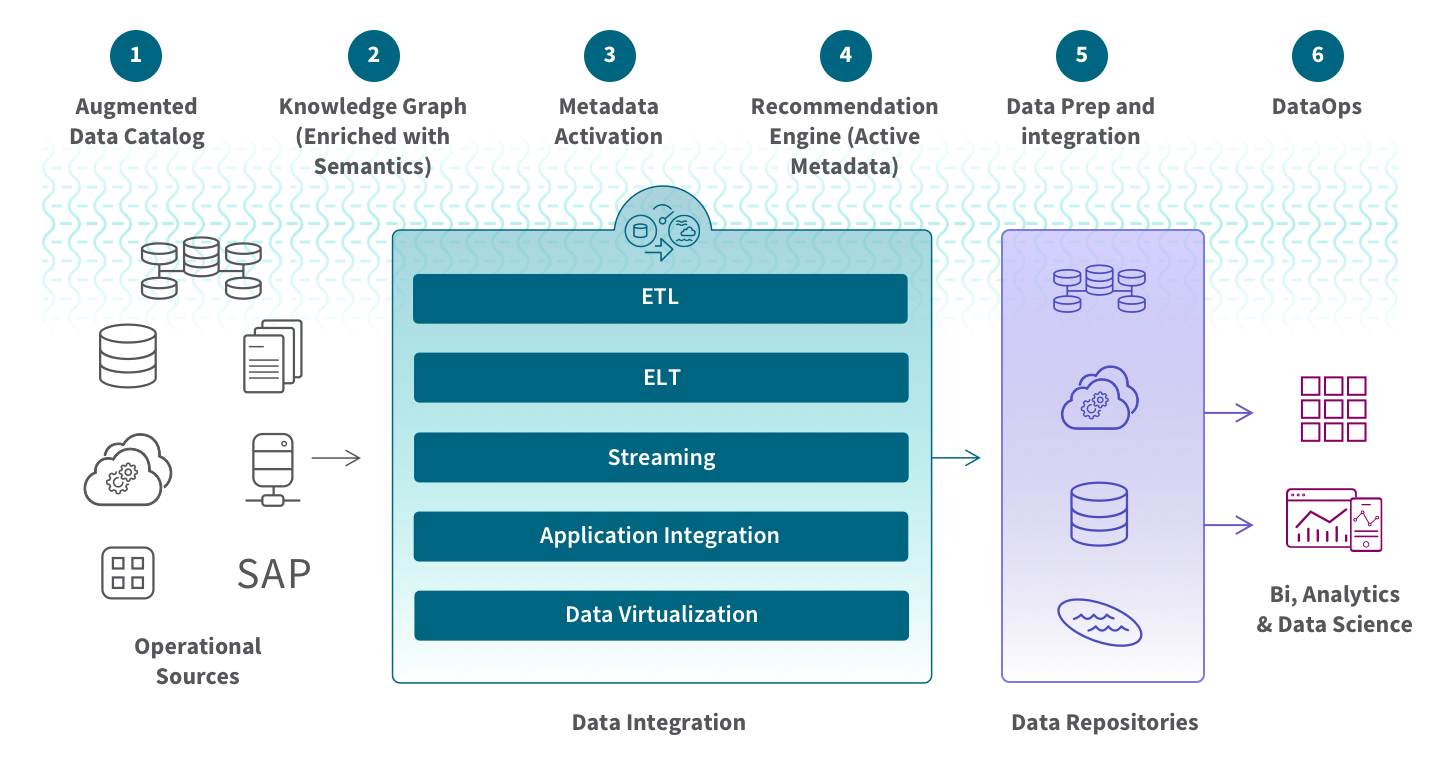
Le data fabric a d’abord été créé comme un environnement de données distribué qui permet l’ingestion, la transformation, la gestion, le stockage et l’accès aux données depuis divers référentiels pour des cas d’usage tels que les outils de business intelligence (BI) ou les applications opérationnelles. Il fournit une couche interconnectée semblable à une toile pour intégrer les processus liés aux données en tirant parti d’une analyse continue sur les actifs de métadonnées actuels et inférés. Il utilise des techniques avancées telles que la gestion active des métadonnées, les graphes de connaissances sémantiques et des capacités d’apprentissage automatique intégrées/AutoML pour maximiser l’efficacité.
Ce concept a d’abord été introduit fin 2016 par Noel Yuhanna de Forrester Research dans sa publication « Forrester Wave: Big Data Fabric ». Son article décrivait une approche orientée technologie combinant des sources de données disparates en une plateforme unifiée utilisant Hadoop et Apache Spark pour le traitement. L’objectif est d’augmenter l’agilité en créant une couche sémantique automatisée qui accélère la livraison des insights tout en minimisant la complexité avec des pipelines rationalisés pour l’ingestion, l’intégration et la curation.
Au fil des années, Noel a développé davantage son concept de Big Data Fabric. Sa vision actuelle est de fournir des solutions répondant à divers besoins métier, tels que la création d’une vue globale des clients, l’intelligence client et les analyses liées à l’Internet des Objets. Le data fabric comprend des composants tels que l’IA/ML, le catalogue de données, la transformation des données, la préparation des données, la modélisation des données et la découverte des données. Il fournit également des capacités de gouvernance et de modélisation qui permettent une gestion complète des données de bout en bout.
Gartner a également adopté le terme « data fabric » et l’a défini de manière similaire : ils le décrivent comme une conception émergente de gestion et d’intégration des données qui permet des pipelines, des services et des sémantiques d’intégration de données flexibles, réutilisables et améliorés pour prendre en charge divers cas d’usage opérationnels ou analytiques sur plusieurs plateformes de déploiement. Les data fabrics combinent différentes techniques d’intégration de données tout en utilisant des métadonnées actives, des graphes de connaissances, des sémantiques et le machine learning (ML) pour améliorer leur processus de conception. Ils définissent cinq attributs internes comme parties du data fabric :
 Attributs du data fabric.
Attributs du data fabric.
Dans un fabric, les métadonnées actives contiennent des catalogues d’éléments de données passifs tels que les schémas, les types de champs, les valeurs de données et les relations du graphe de connaissances. Le graphe de connaissances stocke et visualise les relations complexes entre plusieurs entités de données. Il maintient des ontologies de données pour aider les utilisateurs non techniques à interpréter les données.
Le data fabric exploite les capacités d’IA et de machine learning pour assister et améliorer automatiquement les activités de gestion des données. Cette architecture doit également offrir des capacités d’intégration pour ingérer dynamiquement des données disparates dans le fabric où elles sont stockées, analysées et accessibles. De plus, l’orchestration automatisée des données prend en charge une variété de cas d’usage de données et d’analyse dans l’ensemble de l’entreprise. Elle permet aux utilisateurs d’appliquer les principes DataOps tout au long du processus pour des pipelines de données agiles, fiables et reproductibles.
Le data fabric est une architecture agnostique à la technologie. Cependant, sa mise en œuvre vous permet de faire évoluer vos opérations Big Data pour les processus batch et le streaming en temps réel, en fournissant des capacités cohérentes sur le cloud, le multi-cloud hybride, les déploiements sur site et les appareils edge. Il simplifie le flux d’informations entre différents environnements afin qu’un ensemble complet de données actualisées soit disponible pour les applications analytiques ou les processus métier. De plus, il réduit le temps et les coûts en offrant des composants et des connecteurs préconfigurés, éliminant le besoin de coder manuellement chaque connexion.
3 - Architectures de données décentralisées : le Data Mesh
Le data mesh a été introduit en 2019 par Zhamak Dehghani. Dans son article de blog, elle a soutenu qu’une architecture décentralisée était nécessaire en raison des lacunes des data warehouses et des data lakes centralisés.
Un data mesh est un framework qui permet aux domaines métier de posséder et d’exploiter leurs données spécifiques au domaine sans avoir besoin d’un intermédiaire centralisé. Il s’inspire des principes du calcul distribué, où les composants logiciels sont partagés entre plusieurs ordinateurs fonctionnant ensemble comme un système. De cette manière, la propriété des données est répartie entre différents domaines métier, chacun étant responsable de la création de ses propres produits. De plus, il permet une contextualisation plus facile des informations collectées pour générer des insights plus profonds tout en facilitant simultanément la collaboration entre les propriétaires de domaines pour créer des solutions adaptées selon des besoins spécifiques.
Dans un article ultérieur, Zhamak a révisé sa position en proposant quatre principes qui forment ce nouveau paradigme.
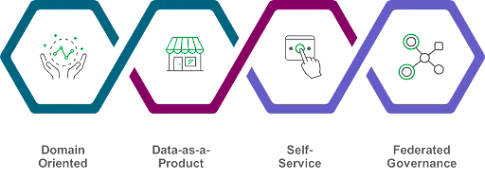 Principes du data mesh.
Principes du data mesh.
- Orienté domaine : le data mesh est basé sur la décentralisation et la distribution de la responsabilité des données analytiques, de leurs métadonnées et du calcul nécessaire pour les servir aux personnes les plus proches des données. Cela permet un changement continu et une scalabilité dans l’écosystème de données d’une organisation. Pour ce faire, le Data Mesh décompose les composants le long des unités organisationnelles ou des domaines métier qui localisent les changements ou l’évolution dans ce contexte délimité. Ce faisant, la propriété de ces composants peut être distribuée aux parties prenantes proches des données.

- La donnée comme produit : l’un des problèmes avec les architectures de données analytiques existantes est qu’il peut être difficile et coûteux de découvrir, comprendre, faire confiance et utiliser des données de qualité. Si elle n’est pas traitée correctement, ce problème ne fera qu’empirer à mesure que davantage d’équipes fournissent des données (domaines) de manière décentralisée, ce qui enfreindrait le premier principe. Pour relever ces défis liés à la qualité des données et aux silos, un data mesh doit traiter les données analytiques fournies par les domaines comme un produit et les consommateurs de ce produit comme des clients. Le produit deviendra la nouvelle unité d’architecture qui doit être construite, déployée et maintenue comme un quantum unique. Il garantit que les consommateurs de données peuvent facilement découvrir, comprendre et utiliser en toute sécurité des données de haute qualité dans de nombreux domaines.

- Infrastructure de données en libre-service : la plateforme d’infrastructure permet aux équipes de domaine de créer et de consommer de manière autonome des produits de données sans se soucier de la complexité sous-jacente de la construction, de l’exécution et de la maintenance de solutions sécurisées et interopérables.
Une infrastructure en libre-service doit fournir une expérience rationalisée permettant aux propriétaires de domaines de données de se concentrer sur leurs objectifs principaux plutôt que de s’inquiéter des détails techniques. Les capacités de la plateforme en libre-service se répartissent en plusieurs catégories ou plans :
- Plan de provisionnement d’infrastructure qui prend en charge le provisionnement de l’infrastructure sous-jacente nécessaire pour exécuter les composants d’un produit de données et le mesh de produits.
- Plan d’expérience développeur de produit est l’interface principale qu’un développeur de produit de données utilise. Il simplifie et abstrait une grande partie des complexités associées au soutien de leur workflow, fournissant un niveau d’abstraction plus élevé et plus facile à utiliser que ce qui est disponible via le Plan de provisionnement.
- Plan de supervision du mesh fournit un moyen de gérer et de superviser l’ensemble du mesh de produits de données, permettant un contrôle global sur tous les produits connectés. Cela inclut des fonctionnalités telles que la surveillance de la qualité, des performances, l’évaluation des protocoles de sécurité, la fourniture de mécanismes de contrôle d’accès, etc. Avoir ces capacités au niveau du mesh plutôt qu’au niveau des produits individuels permet une plus grande flexibilité dans la gestion de grands réseaux de produits de données interconnectés.
- Gouvernance fédérée : la mise en œuvre du data mesh nécessite un modèle de gouvernance qui prend en charge la décentralisation et la souveraineté des domaines, l’interopérabilité via une topologie dynamique et l’exécution automatisée des décisions par la plateforme. L’intégration des normes de gouvernance globales et d’interopérabilité dans l’écosystème du mesh permet aux consommateurs de données de tirer profit de la combinaison et de la comparaison de différents produits de données au sein du même système.
Le data mesh combine ces principes en un système unifié, décentralisé et distribué, où les propriétaires de produits de données ont accès à une infrastructure partagée en libre-service pour le développement de pipelines partageant des données de manière ouverte mais gouvernée. Cela leur permet de développer des produits rapidement sans sacrifier la gouvernance ou le contrôle sur les actifs de données de leur domaine.

Le data mesh diffère de l’approche traditionnelle consistant à gérer les pipelines et les données comme des entités séparées avec une infrastructure de stockage partagée. Au lieu de cela, il considère tous les composants (c’est-à-dire les pipelines, les données et l’infrastructure de stockage) à la granularité d’un contexte délimité au sein d’un domaine donné pour créer un produit intégré. Cela permet une plus grande flexibilité en termes de scalabilité et de personnalisation tout en offrant une meilleure visibilité sur la façon dont les différentes parties interagissent.
Résumé
Le marché des données est souvent perçu comme stagnant et mature, mais la discussion actuelle sur l’architecture de données prouve que c’est une affirmation erronée.
Les types de données augmentent en nombre, les patterns d’utilisation ont considérablement évolué, et un regain d’attention a été porté à la construction de pipelines avec les architectures Lambda et Kappa sous la forme de data hubs ou de fabrics. Qu’ils soient regroupés par vélocité ou par le type de topologie qu’ils fournissent, les architectures de données ne sont pas orthogonales. Les architectures et paradigmes de données présentés dans cet article peuvent être utilisés côte à côte, utilisés alternativement lorsqu’il est nécessaire d’alterner entre eux. De plus, bien sûr, ils peuvent être mélangés dans des architectures comme le data mesh, dans lesquelles chaque produit de données est un artefact autonome. On peut imaginer qu’une architecture Lambda est implémentée dans certains produits de données et des architectures Kappa dans d’autres.
Malgré tous ces changements, il est clair que le débat sur la meilleure façon de structurer notre approche de la gestion des données est loin d’être terminé. Nous ne faisons que commencer !
Références
- Akidau T. et al., The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Proceedings of the VLDB Endowment, vol. 8 (2015), pp. 1792-1803.
- Reis, J. and Housley M. Fundamentals of data engineering: Plan and build robust data systems. O’Reilly Media (2022).
- “Lambda vs. Kappa Architecture. A Guide to Choosing the Right Data Processing Architecture for Your Needs”, Dorota Owczarek.
- “A brief introduction to two data processing architectures: Lambda and Kappa for Big Data”, Iman Samizadeh, Ph.D.
- “What Is Lambda Architecture?”, Hazelcast Glosary.
- “What Is the Kappa Architecture?”, Hazelcast Glosary.
- “Kappa Architecture is Mainstream Replacing Lambda”, Kai Waehner.
- “Data processing architectures – Lambda and Kappa”, Julien Forgeat.
- “Why the Data Hub Architecture?”, Stambia Solutions.
- “Data Hub, Fabric or Mesh? Part 1 of 2”, Clive Bearman.
- “Data Hub, Fabric or Mesh? Part 2 of 2”, Clive Bearman.
- “What Is Data Fabric?”, Qlik.
- “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh”, Zhamak Dehghani (Martin Fowler Blog).
- “Data Mesh Principles and Logical Architecture”, Zhamak Dehghani (Martin Fowler Blog).