
Dans le paysage commercial compétitif d’aujourd’hui, la satisfaction client est cruciale pour maintenir une entreprise prospère. Les entreprises s’efforcent de répondre et de dépasser les attentes des clients en comprenant leurs besoins et leurs préférences.
Les enquêtes de satisfaction client ont longtemps été l’approche standard pour recueillir des feedbacks. Généralement administrées après une interaction ou une transaction avec un client, ces enquêtes visent à collecter des informations sur les perceptions, les expériences et la satisfaction globale des clients. Les organisations ont compté sur ces enquêtes pour identifier les domaines d’amélioration et évaluer la fidélité des clients. Cependant, elles souffrent de quelques limitations :
Premièrement, ces enquêtes ont souvent un délai important entre les interactions avec les clients et les réponses aux enquêtes. Ce retard entrave l’immédiateté du feedback, empêchant toute action rapide sur les problèmes soulevés. Ces enquêtes peuvent également être influencées par un biais de réponse, où les clients peuvent fournir des réponses inexactes ou incomplètes en raison de problèmes de mémoire ou d’un biais de désirabilité sociale. Cela peut conduire à des données biaisées et à une compréhension incomplète du sentiment des clients.
Enfin, de nombreux clients choisissent de ne pas participer aux enquêtes, ce qui entraîne de faibles taux de réponse. Cela peut limiter la représentativité des données collectées, conduisant potentiellement à des conclusions biaisées.
Les avancées technologiques, en particulier dans l’analyse des sentiments, ont ouvert de nouvelles voies pour surveiller la satisfaction client en quasi temps réel. Cet article explore les avantages de l’analyse des sentiments pour remplacer les enquêtes de satisfaction client, permettant aux entreprises d’obtenir des insights opportuns et d’améliorer les expériences clients. Pour cela, j’ai associé la haute vélocité de Redis et les capacités avancées de Google Cloud pour implémenter un système de surveillance de la satisfaction client en temps réel.
Qu’est-ce que l’analyse des sentiments ?
L’analyse des sentiments est un sous-ensemble du traitement du langage naturel (NLP) qui relève de la catégorie de la classification de texte. En utilisant des algorithmes d’apprentissage automatique, l’analyse des sentiments catégorise automatiquement les données textuelles en sentiments positifs, négatifs ou neutres. L’objectif ultime de l’analyse des sentiments est de déchiffrer les humeurs sous-jacentes des interactions (émotions et sentiments). C’est également connu sous le nom d’analyse d’opinion (Opinion Mining).
Les analyses de sentiments et d’émotions permettent aux entreprises d’analyser et de comprendre l’humeur générale derrière les feedbacks des clients. Cet outil puissant permet aux entreprises d’extraire des informations précieuses de divers points de contact clients, tels que les publications sur les réseaux sociaux, les avis en ligne, les interactions du support client, les centres d’appels, et plus encore.
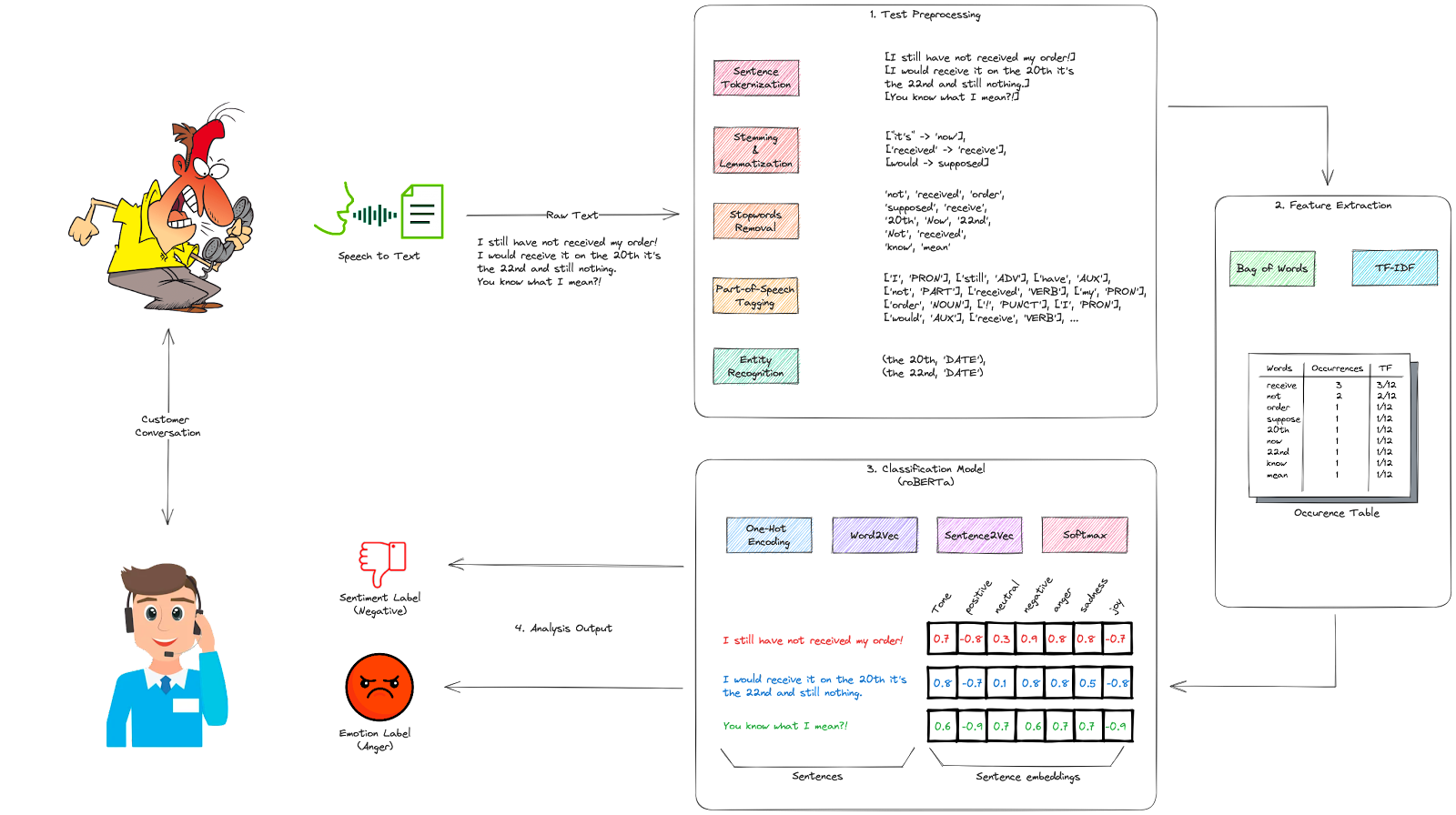
Le processus d’analyse des sentiments comprend plusieurs étapes :
1. Pré-traitement du texte : la première étape consiste à nettoyer et pré-traiter les données textuelles. Cette étape comprend :
- Tokenisation : le texte est divisé en unités individuelles appelées tokens. Ces tokens peuvent être des mots, des phrases ou même des caractères individuels, selon le niveau d’analyse souhaité.
- Racinisation (Stemming) : réduction des mots à leur forme racine ou base, connue sous le nom de radical. Le radical n’est peut-être pas toujours un mot valide, mais il représente la signification fondamentale du mot sans tenir compte des variations grammaticales ou des affixes. La racinisation vise à normaliser les mots afin que les mots liés ayant des significations similaires soient traités comme le même mot. Par exemple, la racinisation du mot « Caring » retournerait le mot « Car ».
- Lemmatisation : réduction des mots à leur forme de base ou canonique, connue sous le nom de lemme. Le lemme représente la forme du dictionnaire ou la forme racine d’un mot. La lemmatisation prend en compte les variations morphologiques des mots et applique des règles linguistiques pour les transformer en leur forme de base. La lemmatisation du mot « Caring » retournerait le mot « Care » au lieu de « Car » avec la racinisation.
- Suppression des mots vides (Stopword removal) : le processus de suppression des éléments inutiles tels que la ponctuation, les mots vides (mots courants comme « et », « le », etc.) et les caractères spéciaux. De plus, le texte peut être converti en minuscules pour la cohérence.
- Étiquetage des parties du discours (POS tagging) : le processus qui attribue des étiquettes grammaticales aux mots dans un texte donné, indiquant leurs parties du discours respectives. Les parties du discours comprennent les noms, les verbes, les adjectifs, les adverbes, les pronoms, les prépositions, les conjonctions, et plus encore.
- Reconnaissance d’entités : également connue sous le nom de Reconnaissance d’entités nommées (NER), c’est une tâche cruciale qui implique l’identification et la classification des entités nommées dans un texte. Les entités nommées sont des informations spécifiques qui peuvent être catégorisées en classes prédéfinies telles que les noms de personnes, les lieux, les organisations, les dates, et plus encore.
2. Extraction de features : pour analyser le sentiment, des features pertinentes doivent être extraites du texte. Cela peut inclure l’identification de mots ou de phrases importants, l’étiquetage des parties du discours, le calcul des occurrences de mots (sacs de mots) et de la fréquence (TF-IDF), et l’extraction de n-grammes (séquences continues de mots) qui fournissent un contexte supplémentaire.
3. Classification des sentiments : les features extraites sont ensuite utilisées pour classer le sentiment du texte. Les algorithmes d’apprentissage automatique sont entraînés sur des jeux de données étiquetés où des annotateurs humains attribuent des étiquettes de sentiment (positif, négatif ou neutre) au texte. De plus, certains autres algorithmes peuvent attribuer des étiquettes d’émotion (heureux, triste, en colère…) à ce texte. Diverses techniques d’apprentissage automatique telles que Naïve Bayes, Support Vector Machines (SVM) ou des modèles de deep learning comme les Réseaux de Neurones Récurrents (RNN) ou les Transformers sont couramment employées.
4. Sortie de l’analyse : une fois le modèle entraîné, il peut être utilisé pour analyser de nouvelles données textuelles. La sortie est généralement une étiquette de sentiment/émotion (positif, négatif, neutre, joie, tristesse, colère…) et un score associé au texte analysé. Le score indique la confiance dans l’étiquette. Ainsi, les scores les plus élevés sont toujours associés aux sentiments/émotions prédominants du texte…
Avantages des analyses de sentiments et d’émotions en temps réel
Examinons l’importance des analyses de sentiments et d’émotions et comment les organisations peuvent en bénéficier.
Imaginez que vous ayez lancé une plateforme d’e-commerce vendant une large gamme d’articles. Vous avez conclu des partenariats avec des sociétés de transport de colis comme DHL et UPS pour livrer vos produits. Et, bien sûr, parce que les clients continuent d’apprécier le « contact humain », en particulier lorsqu’ils cherchent de l’aide, vous avez un petit centre d’appels qui reçoit des centaines/milliers d’appels quotidiens de vos clients.
Alors que les clients affluent sur votre site web, vous réalisez la nécessité de vous assurer que chaque colis est livré à temps comme prévu. C’est un différentiateur crucial que vous avez par rapport à vos concurrents. L’idée est de maintenir une satisfaction client élevée et d’agir rapidement lorsqu’un problème survient. Vous ne pouvez pas vous permettre d’attendre plusieurs jours pour obtenir le feedback du client à partir d’enquêtes post-commande. Lorsqu’un problème se produit (par exemple, perte d’un colis), vous devez capturer le feedback du client pendant qu’il appelle votre centre d’appels. Cela permet à votre entreprise de réagir rapidement, d’escalader vers vos partenaires et de trouver une solution acceptable pour vos clients. C’est là qu’intervient l’analyse des sentiments.

Pour simplifier le processus, lorsque votre centre d’appels reçoit les appels d’un client, la conversation est transcrite, et des analyses de sentiments et d’émotions lui sont appliquées. Quelques tableaux de bord de surveillance permettent aux opérateurs du centre d’appels de jauger et d’évaluer la satisfaction du client. Ainsi, ils peuvent adapter leurs réponses et faire de leur mieux pour trouver une solution acceptable.
Cela permet également de recueillir quelques statistiques en temps réel telles que la satisfaction globale de tous les appels entrants, les percentiles des sentiments négatifs/positifs, et les scores de satisfaction moyens entre les fractions basses et élevées de feedback.
Système de surveillance de la satisfaction avec Redis & GCP
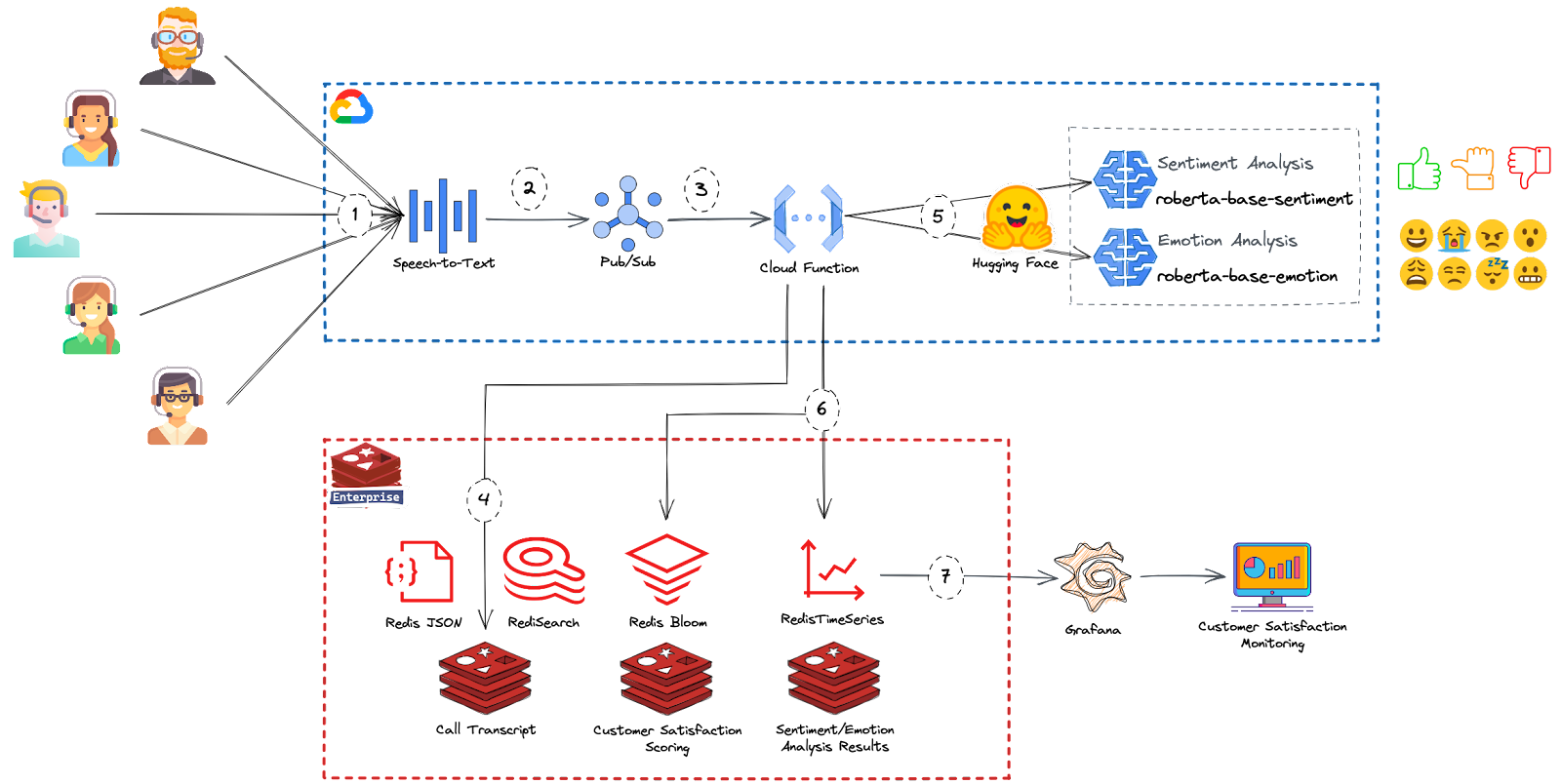
Redis Enterprise joue trois fonctions dans une solution de surveillance de la satisfaction. Premièrement, il est utilisé comme base de données primaire multi-modèle qui stocke et indexe les documents JSON (transcription des appels), utilise les structures de données t-digest et Top-k pour effectuer des calculs statistiques tels que la distribution des échantillons, les percentiles et le scoring de satisfaction, et enfin, comme feature store en ligne opéré par des algorithmes d’apprentissage automatique sur Google Cloud. Un seul cluster Redis peut servir toutes ces fonctions. Il n’est pas nécessaire d’avoir des clusters séparés.
Une Cloud Function consomme la transcription d’appel reçue par PubSub, infère les scores de satisfaction, effectue des calculs statistiques et charge tous les résultats dans les bases de données Redis.
Le diagramme suivant représente l’architecture de solution implémentée avec Redis Enterprise et GCP.
En pré-requis, vous devez choisir comment effectuer l’analyse du taux de satisfaction. Vous pouvez utiliser un analyseur basé sur des règles comme VADER (Valence Aware Dictionary and sEntiment Reasoner). Cette approche consiste à créer un ensemble de règles ou de modèles prédéfinis qui déterminent le sentiment d’un texte. Ces règles peuvent être basées sur des mots-clés, des modèles linguistiques ou des lexiques de sentiments (dictionnaires de mots et leurs sentiments associés). Cependant, cette approche nécessite des mises à jour régulières et une validation humaine pour que les règles fournissent des résultats précis.
Lorsqu’il s’agit d’algorithmes d’apprentissage automatique, il existe plusieurs approches et techniques pour effectuer l’analyse des sentiments. Les algorithmes d’apprentissage automatique peuvent être entraînés à classer le sentiment des données textuelles sur la base d’exemples étiquetés. Les algorithmes courants utilisés pour l’analyse des sentiments comprennent Naïve Bayes, Support Vector Machines (SVM), Random Forests, Réseaux de Neurones Récurrents (RNN), Réseaux de Neurones Convolutifs (CNN) et Transformers.
Les modèles basés sur les Transformers représentent une avancée de pointe dans les techniques de traitement du langage naturel (NLP). Dans cet article, nous avons utilisé deux modèles Transformer de Hugging Face, tous deux basés sur le modèle roBERTa-base, entraîné sur ~58M tweets, et affiné pour la reconnaissance des sentiments et des émotions.
1. Le flux de données commence avec les opérateurs du centre d’appels invoquant l’API Google Cloud Speech-To-Text pour la transcription des conversations.
2. Google Cloud PubSub est utilisé pour capturer les transcriptions de conversations en temps réel. Cloud PubSub est un service entièrement géré pour le traitement de données d’événements à n’importe quelle échelle.
3. Cloud Functions est une solution de calcul serverless pour les développeurs permettant de créer des fonctions autonomes qui répondent aux événements Cloud sans avoir besoin de gérer un serveur ou un environnement d’exécution. Dans notre solution, la Cloud Function est déclenchée par PubSub pour lire les données entrantes et effectuer les actions suivantes :
4. Persister le contenu de la conversation dans RedisJSON pour permettre l’indexation et l’interrogation de la transcription à faible latence.
5. Pour calculer la satisfaction client, la cloud function appelle les points d’accès des modèles Transformer de Hugging Face pour attribuer des scores de sentiment et d’émotion aux phrases entrantes.
def perform_inference(data_payload):
print("** perform_inference - START")
output = {}
sentiment_labels=["negative","neutral","positive"]
emotion_labels=["anger","joy","optimism","sadness"]
output["sentiment_analysis"] = get_analysis(data_payload, "sentiment", sentiment_labels)
output["emotion_analysis"] = get_analysis(data_payload, "emotion", emotion_labels)
print("** perform_inference - END")
return output
- Analyses de sentiment / émotion :
def get_analysis(data, task, labels):
MODEL = f"cardiffnlp/twitter-roberta-base-{task}"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
tokenizer.save_pretrained("/tmp")
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
model.save_pretrained("/tmp")
encoded_input = tokenizer(data, return_tensors='pt')
output = model(**encoded_input)
scores = output[0][0].detach().numpy()
scores = softmax(scores)
ranking = np.argsort(scores)
ranking = ranking[::-1]
output = []
for i in range(scores.shape[0]):
l = labels[ranking[i]]
s = scores[ranking[i]]
output.insert(i, {'label_index' : int(ranking[i]),'label' : l, 'score' : np.round(float(s), 4)})
return output
6. La Cloud Function persiste ensuite les résultats de l’analyse de satisfaction dans Redis Enterprise. La fonction utilise RedisBloom pour calculer statistiquement les sentiments et les émotions et stocke les résultats dans une base de données de séries temporelles pour des visualisations de données ultérieures à l’aide de Grafana.
def persist_conversation_score(customer_id,satisfaction_score):
print("** persist_conversation_score - START")
now = datetime.datetime.now() # current date and time
trans_date_trans_time = now.strftime("%Y/%m/%d-%H:%M:%S")
key = "customer-satisfaction:" + customer_id
data = {}
data['end_time'] = trans_date_trans_time
data['score'] = satisfaction_score
# Merging the conversation end time and overall score
redis_client.json().merge(key, Path.root_path(), data)
# Adding the satisfaction Score to the t-digest structure
redis_client.tdigest().add("satisfaction-tdigest", [float(satisfaction_score)])
print("** persist_conversation_score - END")
Ci-dessous se trouve le tableau de bord Grafana qui affiche les scores de satisfaction client en temps réel pour les appels entrants. Le tableau de bord affiche le score de satisfaction global et les sentiments/émotions actuels de toute conversation entrante. De plus, d’autres graphiques sont utilisés pour visualiser les changements des scores de satisfaction dans le temps et pour comparer différents sentiments et émotions (côté bas). Le code source de cette solution est disponible dans le dépôt Github suivant.

De plus, vous pouvez mesurer la tendance centrale en utilisant Redis Bloom. Parfois, vous voudrez peut-être connaître la valeur en dessous de laquelle se trouve un certain pourcentage de satisfaction client. Par exemple, vous voudrez peut-être trouver le 75e percentile (troisième quartile), qui représente le taux de satisfaction le plus bas qui est inférieur ou égal à 75%, et la fraction de ce percentile par rapport aux scores globaux.
Selon cet article, « Le t-digest est un algorithme en ligne pour construire de petits croquis de données qui peuvent être utilisés pour approximer les statistiques basées sur le rang avec une haute précision, en particulier près des queues. Ce nouveau type de croquis est robuste par rapport aux distributions asymétriques, aux échantillons répétés et aux jeux de données ordonnés. Les croquis calculés séparément peuvent être combinés avec peu ou pas de perte de précision ».
Dans l’exemple ci-dessous, le t-digest contient les 17 observations suivantes représentant les taux de satisfaction collectés à partir de 17 appels clients : 32%, 64,5%, 98%, 82%, 33%, 18,5%, 32%, 19%, 21%, 56%, 61,3%, 61%, 61%, 60%, 53%, 32%, 45% et 46%. Comme vous pouvez le voir, cette distribution est asymétrique à gauche. Pour cette raison, nous pouvons utiliser la structure de données t-digest de Redis Bloom qui retourne, pour chaque valeur d’entrée, une estimation de la fraction d’observations inférieures à un taux de satisfaction donné.
$ TDIGEST.CDF satisfaction-tdigest 0.75
1) "0.88235294117647056"
Ainsi, le calcul des fractions de quantile en utilisant un t-digest indique que 88,2% des clients ont un taux de satisfaction inférieur à 75%. En d’autres termes, seulement 11,8% des clients dépassent un taux de satisfaction de 75%, ce qui représente un faible niveau de satisfaction.

Résumé
Les enquêtes de satisfaction client ont longtemps été la base pour évaluer le sentiment des clients, mais leurs limitations sont devenues évidentes dans l’environnement commercial rapide d’aujourd’hui. Les analyses de sentiments et d’émotions émergent comme des outils puissants qui permettent aux entreprises de surveiller la satisfaction client en temps réel, remplaçant les enquêtes post-vente. En exploitant les avantages de l’analyse des sentiments, les organisations peuvent obtenir des insights immédiats, traiter proactivement les problèmes, personnaliser les expériences et optimiser l’allocation des ressources. Alors que les entreprises continuent de donner la priorité à la satisfaction client, l’analyse des sentiments en temps réel s’avère être un atout inestimable pour rester compétitif et répondre aux attentes évolutives des clients.
Dans cet article, nous avons exploré comment Redis Enterprise et les services Google Cloud ont contribué à implémenter une plateforme de surveillance de la satisfaction client en temps réel. La haute vélocité de Redis, en plus des structures de données probabilistes Bloom, fournit aux entreprises un accès instantané aux feedbacks clients. En surveillant les sentiments des clients en temps réel, les entreprises peuvent rapidement identifier les expériences positives et négatives. Cela leur permet de répondre rapidement, de traiter les préoccupations et de capitaliser sur les feedbacks positifs pour amplifier la satisfaction client.
Références
- t-digest: a new probabilistic data structure in Redis Stack, Blog Redis
- The t-digest: Efficient estimates of distributions, Ted Dunning, Software Impacts (Elsevier), Volume 7, 2021
- How to perform sentiment analysis on earnings call of companies, Towards Data Science
- Sentiment Analysis in Python, Hugging Face