
Les systèmes mainframe constituent depuis longtemps l’épine dorsale de l’informatique d’entreprise, reconnus pour leur fiabilité, leur scalabilité et leur puissance de traitement inégalée. Alors que les entreprises s’efforcent de moderniser leurs infrastructures informatiques, comprendre les fondamentaux de l’architecture des bases de données mainframe devient crucial.
Dans le précédent article de cette série, nous avons mis en lumière l’héritage durable des systèmes mainframe et leur rôle central dans l’informatique d’entreprise. Nous avons expliqué pourquoi les mainframes ont perduré si longtemps et pourquoi il est essentiel de les moderniser vers une alternative distribuée et cloud-native.
Cet article plonge dans l’univers complexe du stockage de données mainframe, en explorant les composants architecturaux des bases de données mainframe traditionnelles. Nous examinerons leurs forces et leurs limites, tout en évaluant les défis de performance, de scalabilité et d’exploitation. Nous illustrerons également ces concepts par des exemples concrets, mettant en lumière les divers cas d’usage et secteurs qui s’appuient sur les bases de données mainframe.
Stockage : différents niveaux d’abstraction
« Le stockage signifie des choses différentes selon les utilisateurs. Quand on parle de stockage, certains pensent à la façon dont les données sont physiquement stockées ; d’autres se concentrent sur le matériau brut qui supporte les systèmes de stockage, tandis que d’autres encore pensent au système ou à la technologie de stockage pertinents pour leur cas d’usage. Tous ces niveaux sont des attributs importants du stockage, mais ils se concentrent sur différents niveaux d’abstraction. »
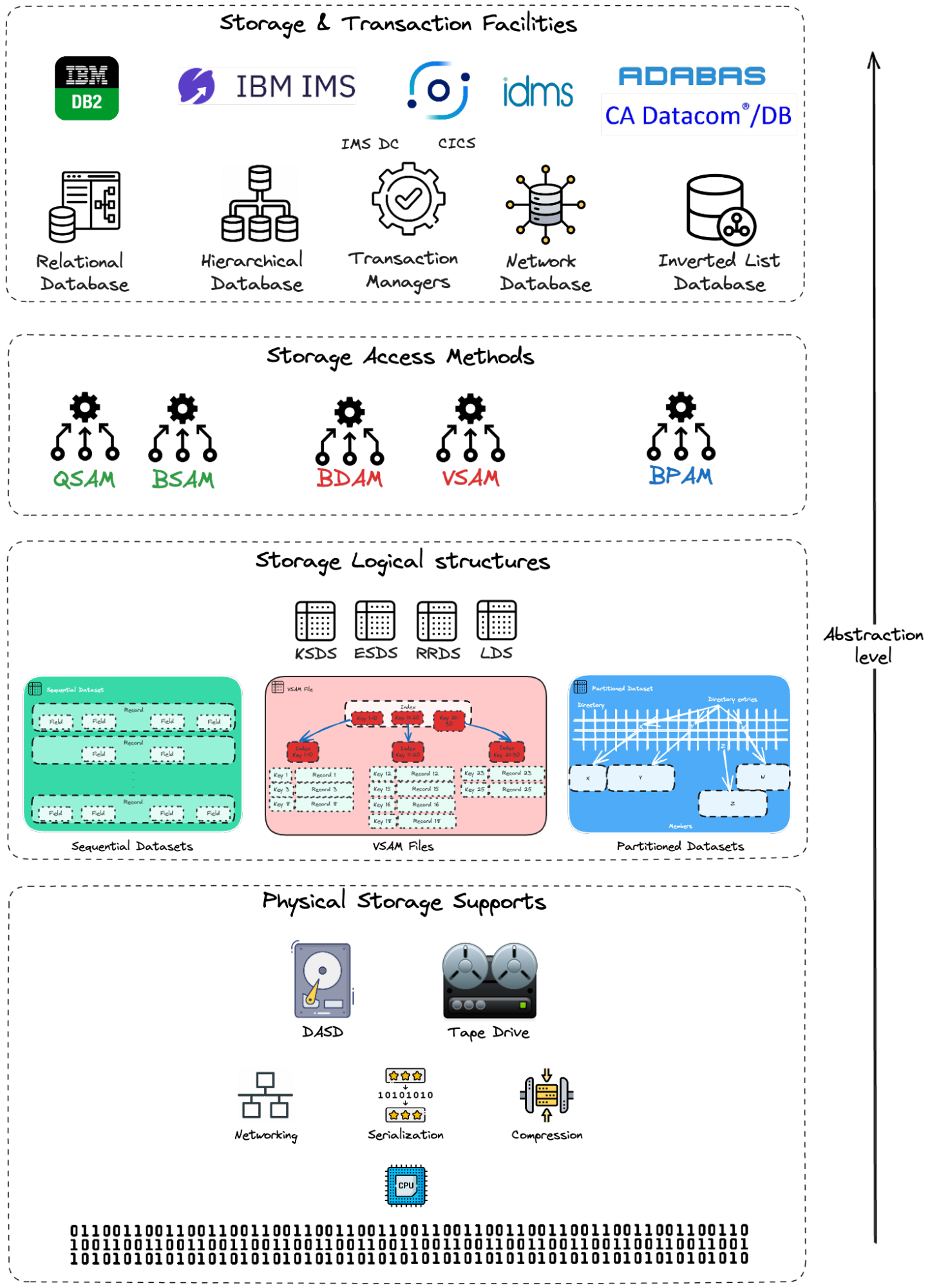
Diagramme des niveaux d’abstraction du stockage mainframe
Le stockage est omniprésent, ce qui rend facile d’en négliger l’importance. Par exemple, de nombreux ingénieurs logiciels et données utilisent le stockage quotidiennement, mais peuvent ne pas connaître son fonctionnement ni les compromis associés aux différents supports de stockage.
Par exemple, les systèmes mainframe prennent en charge de nombreux appareils différents pour le stockage de données. Les disques ou les bandes sont les plus fréquemment utilisés pour le stockage de données à long terme. Qu’est-ce qu’un disque dur ? Un disque dur comprend une pile de disques circulaires recouverts d’un matériau magnétique pour le stockage des données. Chaque disque présente un trou central pour le montage sur un axe, lui permettant de tourner rapidement. La surface de chaque disque est divisée en pistes, et chaque piste est encore subdivisée en cylindres. Un disque dur utilise un actionneur pour déplacer une tête de lecture/écriture vers un secteur spécifique afin d’accéder aux données. Ce processus est guidé par l’adresse mémoire de chaque secteur, garantissant une récupération précise des données.
Dans l’univers mainframe, les disques durs sont appelés Direct Access Storage Devices (DASD), prononcé « Dazz-Dee ». Par exemple, lorsque vous travaillez sur un système PC classique, l’unité granulaire la plus fine du disque dur est appelée un « fichier ». Le fichier représente une longue chaîne d’octets, souvent délimitée pour indiquer le début et la fin de certains types de données au système d’exploitation.
Mais le mainframe adopte une approche différente. Le système d’exploitation mainframe gère les données à l’aide de datasets. Que sont les datasets ? Le terme dataset désigne un fichier contenant un ou plusieurs enregistrements. Un enregistrement est l’unité de base d’information utilisée par un programme s’exécutant sur des mainframes.
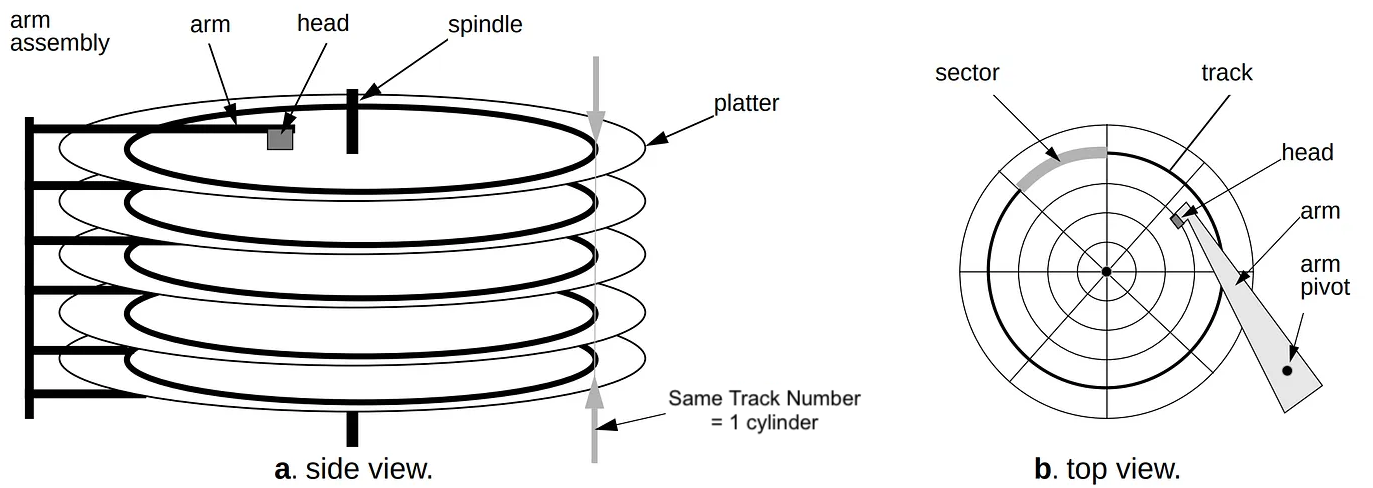
Diagramme du Direct Access Storage Device
Un enregistrement est un nombre fixe d’octets contenant des données. Souvent, un enregistrement regroupe des informations liées traitées comme une unité, telles qu’un élément dans une base de données ou des données personnelles. Le terme champ désigne une portion spécifique d’un enregistrement utilisée pour une catégorie de données particulière, comme le nom ou le département d’un employé.
Les enregistrements dans un dataset peuvent être organisés de différentes manières, selon la façon dont nous prévoyons d’accéder aux informations. Par exemple, si vous écrivez un programme applicatif qui traite des données du personnel, votre programme peut définir un format d’enregistrement pour ces données.
Un dataset peut être organisé dans le mainframe de nombreuses façons différentes. Parmi les types les plus couramment utilisés, on trouve :
-
Les Sequential Data Sets (SDS) ou ensembles de données séquentiels, qui consistent en des enregistrements stockés consécutivement. Par exemple, le système doit parcourir les neuf premiers éléments pour accéder au dixième élément du dataset. Les éléments de données qui doivent tous être utilisés en séquence, comme la liste alphabétique des noms dans un registre de classe, sont mieux stockés dans un dataset séquentiel.
-
Les Partitioned Data Sets (PDS) ou ensembles de données partitionnés, qui se composent d’un répertoire et de membres. Le répertoire contient l’adresse de chaque membre et permet ainsi aux programmes ou au système d’exploitation d’accéder directement à chaque membre. Chaque membre, cependant, est composé d’enregistrements stockés séquentiellement. Les datasets partitionnés sont souvent appelés bibliothèques. Les programmes sont stockés en tant que membres de datasets partitionnés. En général, le système d’exploitation charge les membres d’un PDS en mémoire séquentiellement, mais il peut accéder directement aux membres lors de la sélection d’un programme pour son exécution.
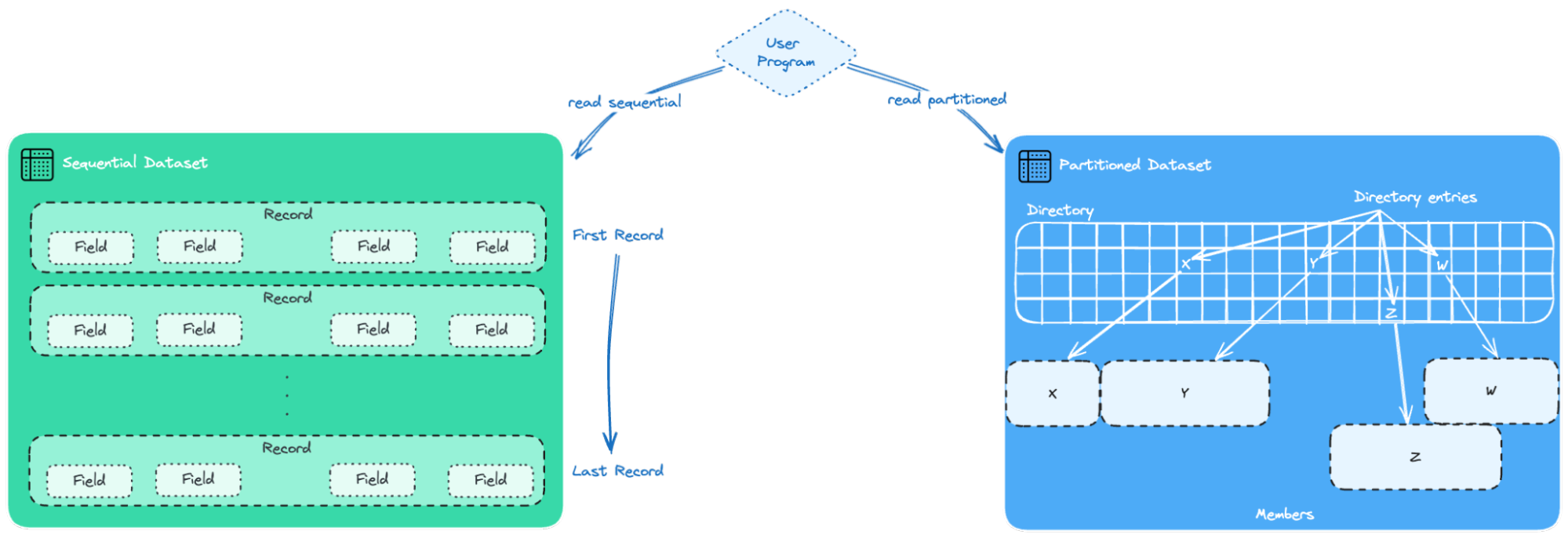
Dataset séquentiel et dataset partitionné
Dans IBM z/OS®, vous pouvez gérer les mises à jour successives de données associées via les generation data groups (GDGs). Chaque dataset dans un GDG est un generation dataset (GDS), et ces ensembles sont organisés chronologiquement. Les GDGs peuvent être composés de datasets ayant des attributs et des organisations similaires ou différents. S’ils sont identiques, ils peuvent être récupérés ensemble. Les GDGs offrent plusieurs avantages, notamment :
- un nom de référence commun
- un ordonnancement chronologique automatique
- une suppression automatique des générations obsolètes
Les datasets GDG ont des noms absolus et relatifs indiquant leur ancienneté, avec des entrées de base allouées dans un catalogue pour l’organisation.
Bien que certains datasets puissent être stockés séquentiellement, les DASDs peuvent gérer l’accès direct. Un DASD se connecte au mainframe via des baies, en utilisant la mise en cache pour améliorer la vitesse et des contrôleurs pour gérer le traitement et le partage système.
Pour localiser rapidement un dataset spécifique, le mainframe utilise un système de catalogue et un VTOC (volume table of contents) qui suivent ses emplacements. En pratique, presque tous les datasets sur disque sont catalogués. L’un des effets secondaires est que tous les datasets (catalogués) doivent avoir des noms uniques.
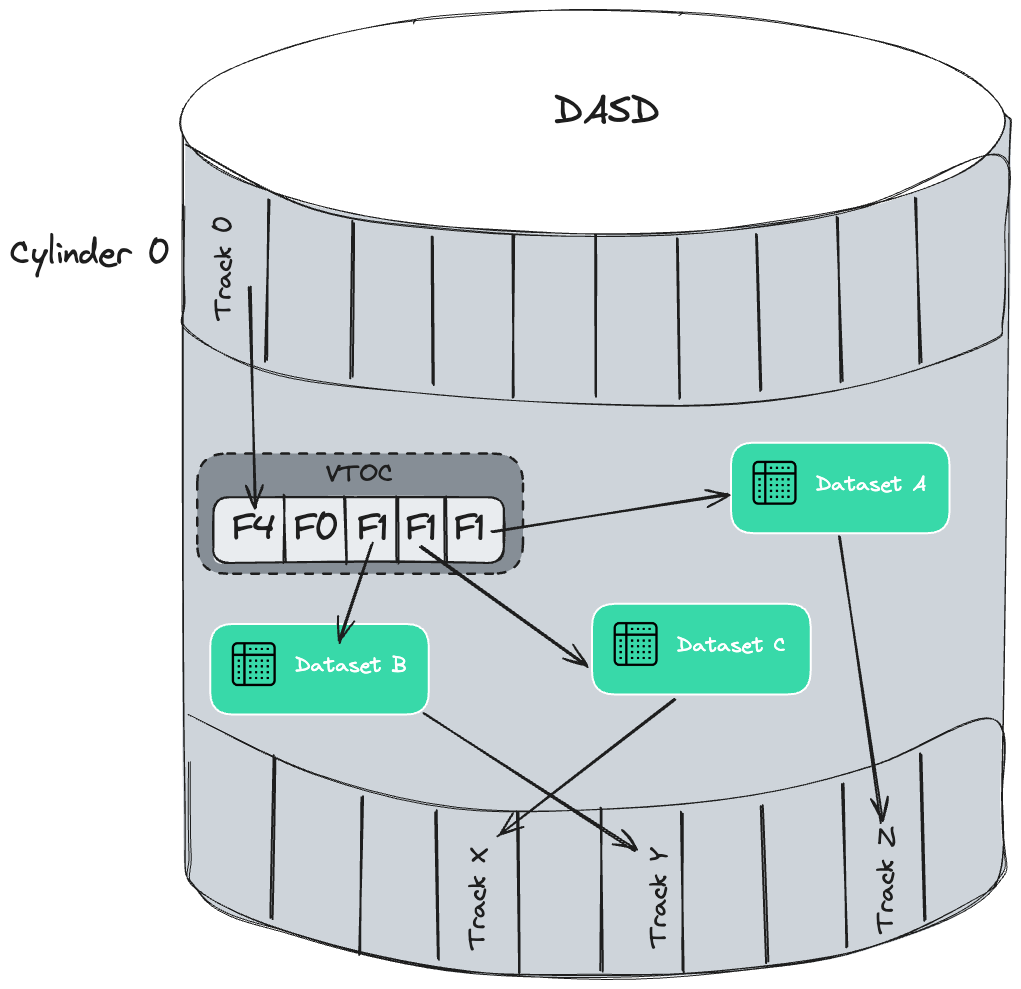
Diagramme du Volume Table of Contents (VTOC)
Une méthode d’accès définit la technique utilisée pour stocker et récupérer des données. Les méthodes d’accès ont leurs propres structures de dataset pour organiser les données, des programmes (ou macros) fournis par le système pour décrire les datasets, et des programmes utilitaires pour traiter les datasets.
Les méthodes d’accès couramment utilisées incluent :
-
QSAM (Queued Sequential Access Method) est une méthode d’accès très utilisée. QSAM arrange les enregistrements séquentiellement dans l’ordre dans lequel ils sont saisis pour former des datasets séquentiels, et anticipe le besoin d’enregistrements en fonction de leur ordre. Le système organise les enregistrements avec d’autres enregistrements. Pour améliorer les performances, QSAM lit ces enregistrements en mémoire avant qu’ils ne soient demandés, une technique connue sous le nom d’« accès en file d’attente ».
-
BSAM (Basic Sequential Access Method) est utilisé pour les cas exceptionnels. BSAM arrange les enregistrements séquentiellement dans l’ordre dans lequel ils sont saisis.
-
BDAM Qu’est-ce que BDAM ? (Basic Direct Access Method) arrange les enregistrements dans n’importe quelle séquence indiquée par votre programme et récupère les enregistrements par adresse réelle ou relative. Si vous ne connaissez pas l’emplacement exact d’un enregistrement, vous pouvez spécifier un point dans le dataset à partir duquel commencer la recherche. Les datasets organisés de cette manière sont appelés « datasets directs ».
-
BPAM (Basic Partitioned Access Method) arrange les enregistrements en tant que membres d’un Partitioned Data Set (PDS) ou d’un Partitioned Data Set Extended (PDSE) sur DASD. Vous pouvez utiliser BPAM pour visualiser un répertoire UNIX et ses fichiers de manière similaire à un PDS.
-
VSAM (Virtual Sequential Access Method) combine un dataset et une méthode d’accès. Il arrange les enregistrements par clé d’index, par numéro d’enregistrement relatif ou par adressage d’octets relatif. VSAM est utilisé pour le traitement DASD direct ou séquentiel d’enregistrements à longueur fixe et variable. Les données organisées par VSAM sont cataloguées pour une récupération facile.
Les méthodes d’accès sont identifiées principalement par l’organisation du dataset. Par exemple, les Sequential Data Sets (SDS) sont accessibles à l’aide de BSAM ou QSAM avec des datasets séquentiels.
Cependant, une méthode d’accès associée à une structure de dataset peut être utilisée pour traiter un dataset structuré différemment. Par exemple, un dataset séquentiel créé avec BSAM peut être traité en utilisant BDAM et vice versa. Un autre exemple est celui des fichiers UNIX, que vous pouvez traiter avec BSAM, QSAM, BPAM ou VSAM.
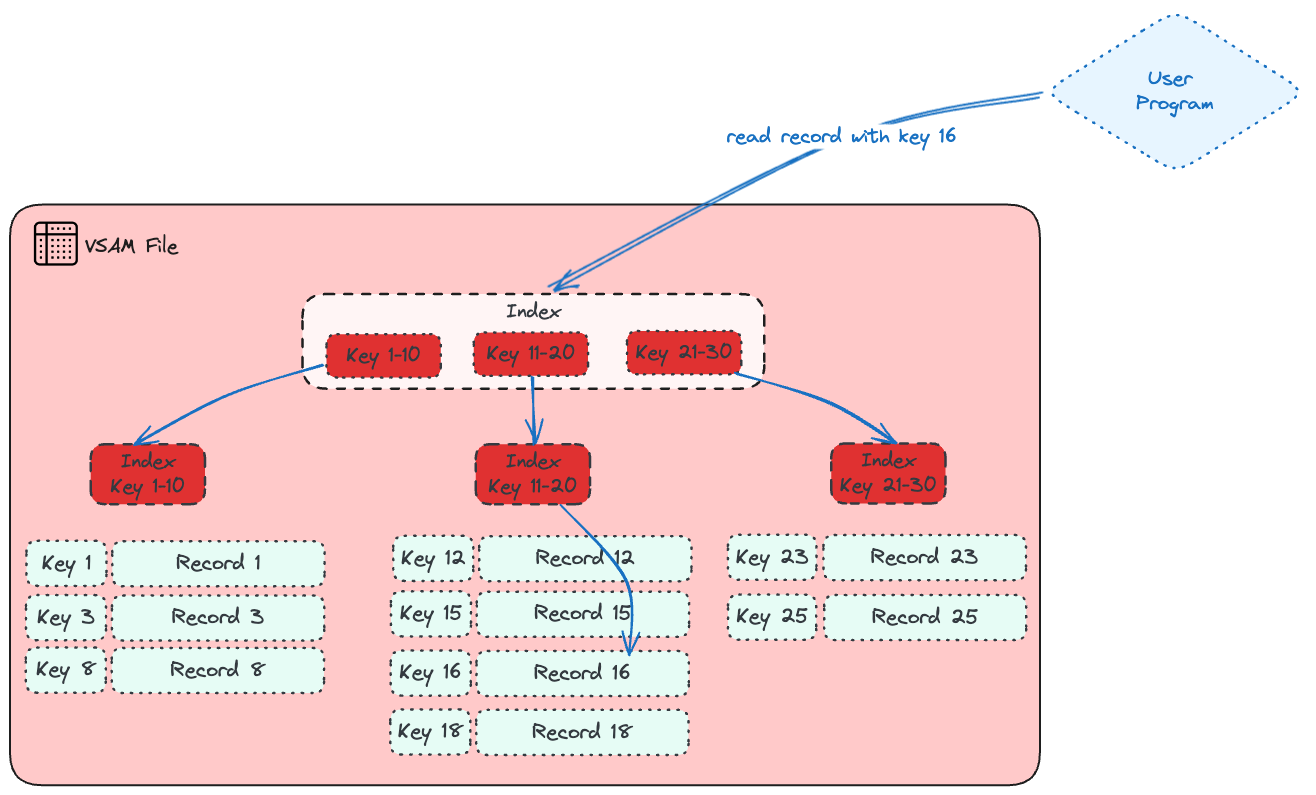
Diagramme explicatif de VSAM
Vous pouvez utiliser VSAM pour organiser les enregistrements en quatre types de datasets : à clé séquentielle, à entrée séquentielle, linéaire ou à enregistrement relatif. La principale différence entre ces types de datasets réside dans la façon dont leurs enregistrements sont stockés et accessibles. Les datasets VSAM sont brièvement décrits comme suit :
-
Key Sequence Data Set (KSDS) : Ce type est l’utilisation la plus courante de VSAM. Chaque enregistrement possède un ou plusieurs champs clés, et un enregistrement peut être récupéré (ou inséré) par valeur de clé. Vous pouvez accéder aux enregistrements de manière aléatoire et utiliser des enregistrements de longueur variable. KSDS est trié par un champ clé, ce qui rend le traitement plus efficace. C’est pourquoi les bases de données hiérarchiques comme IMS utilisent les KSDSs.
-
Entry Sequence Data Set (ESDS) : Cette forme de VSAM conserve les enregistrements dans l’ordre séquentiel. Les enregistrements sont identifiés par une adresse physique, et le stockage est basé sur l’ordre dans lequel ils sont insérés dans le dataset. Cependant, la suppression n’est pas autorisée et, comme il n’y a pas d’index, des enregistrements dupliqués peuvent exister. ESDS est courant dans IMS, DB2 et z/OS UNIX.
-
Relative Record Data Set (RRDS) : Ce format VSAM permet la récupération des enregistrements par numéro. Il partage de nombreuses fonctions avec ESDS. Cependant, une différence significative est que les enregistrements sont accessibles en utilisant le Relative Record Number (RRN), basé sur l’emplacement du premier enregistrement. Il offre un accès aléatoire et suppose que le programme applicatif peut dériver les numéros d’enregistrement souhaités. Notez que les enregistrements sont de longueur fixe et que la suppression est autorisée.
-
Linear Data Set (LDS) : Ce type est en fait un dataset de flux d’octets. IBM Db2 et plusieurs fonctions système mainframe utilisent intensivement ce format, mais les programmes applicatifs l’utilisent rarement.
Plusieurs méthodes supplémentaires d’accès aux données dans VSAM ne sont pas listées ici. La plupart des applications utilisent VSAM pour les données indexées.
Cependant, VSAM présente quelques inconvénients, notamment :
-
Vous ne pouvez utiliser VSAM que sur un disque DASD, pas sur des lecteurs de bandes. Mais les lecteurs de bandes ne sont de toute façon plus beaucoup utilisés.
-
Une autre limitation est qu’un VSAM peut avoir des besoins de stockage plus importants en raison de la surcharge nécessaire pour ses fonctions.
-
Enfin, le dataset VSAM est propriétaire, ce qui signifie qu’il n’est pas lisible par d’autres méthodes d’accès. Par exemple, vous ne pouvez pas le visualiser à l’aide d’Interactive System Productivity Facility (ISPF) sans utiliser un logiciel spécial.
Traitement par lots vs traitement transactionnel en ligne
Qu’est-ce que le traitement par lots ? Le traitement par lots sur un ordinateur mainframe consiste à traiter de grandes quantités de données en groupes, ou lots, sans nécessiter d’interaction avec l’utilisateur. Cette méthode est fréquemment utilisée pour exécuter des tâches répétitives telles que les sauvegardes, le filtrage et le tri, plus efficacement que si elles étaient exécutées sur des transactions individuelles.
Aux débuts des mainframes, le traitement par lots s’est imposé comme l’approche prédominante de traitement des données. Par exemple, une pratique courante consistait à accumuler des données sur une période spécifique, comme les heures ouvrables, puis à les traiter pendant les heures creuses, généralement la nuit lorsque l’activité était minimale. Un autre scénario typique était le traitement de la paie, où les données étaient recueillies pendant des semaines et traitées à la fin de la période.
Le traitement par lots, réputé pour son efficacité économique dans la gestion de grands volumes de données, reste une pratique répandue dans les environnements mainframe. Cependant, certaines activités comme les paiements par carte de crédit ou la gestion des stocks en distribution doivent être traitées en temps réel. Ce type de traitement a donné naissance à ce que l’on connaît aujourd’hui sous le nom de traitement transactionnel en ligne (OLTP).
Caractéristiques des transactions
Qu’est-ce que l’OLTP ? Il s’agit d’une classe d’applications logicielles capables de prendre en charge des programmes orientés transactions. L’OLTP est utilisé par les organisations qui ont besoin de moyens efficaces pour stocker et gérer de vastes quantités de données en quasi-temps réel, tout en prenant en charge de nombreux utilisateurs simultanés et types de transactions.
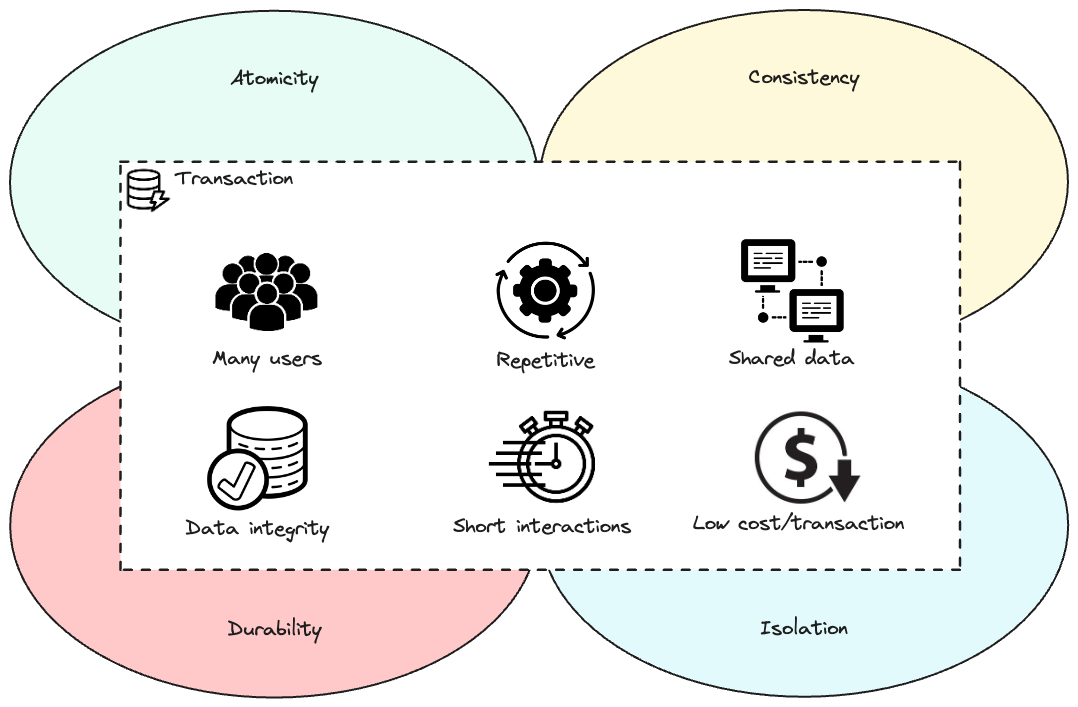
Dans un système OLTP, l’utilisateur effectuera une transaction commerciale complète à travers de courtes interactions, avec un temps de réponse immédiat requis pour chaque interaction (en dessous de la milliseconde dans certains cas). Ces applications sont critiques pour l’entreprise ; par conséquent, la disponibilité continue, les hautes performances, la protection et l’intégrité des données sont des prérequis.
Dans un système transactionnel, les transactions doivent respecter quatre exigences fondamentales connues collectivement par l’acronyme A-C-I-D ou ACID. CockroachDB, par exemple, est une base de données conforme aux principes ACID. ACID dans les bases de données signifie :
- Atomicité. Les processus effectués par la transaction sont réalisés en totalité ou pas du tout.
- Cohérence. La transaction ne doit fonctionner qu’avec des informations cohérentes.
- Isolation. Les processus provenant de deux transactions ou plus doivent être isolés les uns des autres.
- Durabilité. Les modifications apportées par la transaction doivent être permanentes.
Les systèmes OLTP ont joué un rôle déterminant dans la croissance économique en réduisant la dépendance aux dossiers papier. Dans les sections suivantes, nous présenterons quelques systèmes de traitement des transactions, y compris des systèmes de traitement par lots et en ligne, qui ont été et sont encore utilisés dans des milliers des plus grandes entreprises mondiales.
Customer Information Control System (CICS)
Aux débuts, CICS, parfois prononcé « KICKS », était fourni avec le matériel IBM, donnant lieu au premier exemple de logiciel open source. CICS signifie « Customer Information Control System ». Il s’agit d’un sous-système de traitement transactionnel à usage général pour le système d’exploitation z/OS. CICS fournit des services pour exécuter une application en ligne à la demande, comme de nombreux autres utilisateurs qui soumettent des demandes pour exécuter les mêmes applications en utilisant les mêmes fichiers et programmes.
Les applications CICS sont traditionnellement exécutées en soumettant une demande de transaction. L’exécution de la transaction consiste à exécuter un ou plusieurs programmes applicatifs qui mettent en œuvre la fonction requise. Dans la documentation CICS, vous pouvez trouver des programmes applicatifs CICS parfois simplement appelés « programmes », et parfois le terme « transaction » est utilisé pour désigner le traitement effectué par les programmes applicatifs.
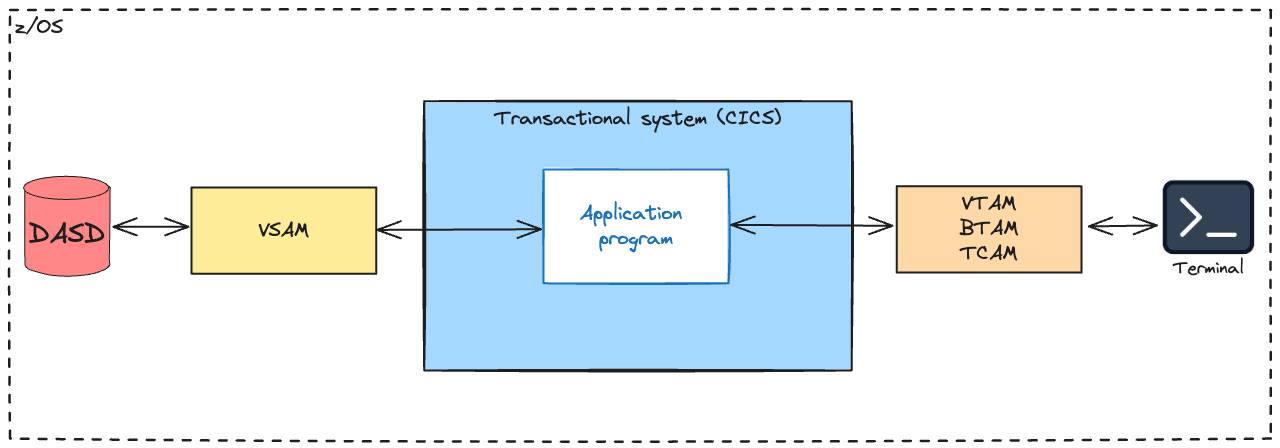
Diagramme du Customer Information Control System (CICS)
Dans l’environnement z/OS, une installation mainframe CICS comprend une ou plusieurs « régions » réparties sur une ou plusieurs images du système z/OS. Bien qu’il traite des transactions interactives, chaque région CICS est généralement démarrée comme un travail par lots. Chaque région CICS comprend une tâche principale sur laquelle chaque transaction s’exécute, bien que certains services, tels que l’accès aux données IBM Db2, utilisent d’autres tâches.
Au sein d’une région, les transactions sont multitâchées de manière coopérative : elles sont supposées se comporter correctement et céder le CPU plutôt que d’attendre. Les services CICS gèrent cela automatiquement. CICS prend facilement en charge des milliers de transactions par seconde (TPS) sur les serveurs IBM Z, ce qui en fait un pilier de l’informatique d’entreprise.
Chaque « tâche » ou transaction CICS unique se voit allouer sa propre mémoire dynamique au démarrage. Les demandes ultérieures de mémoire supplémentaire sont gérées par un appel au « programme de contrôle du stockage » (faisant partie du noyau CICS), qui est analogue à un système d’exploitation traditionnel : il gère le partage des ressources, l’intégrité des données et la priorisation de l’exécution, avec une réponse rapide. CICS autorise les utilisateurs, alloue des ressources (stockage et cycles), et transmet les requêtes de base de données des applications au gestionnaire de base de données approprié (tel que DB2).
À l’origine, CICS était utilisé pour traiter les entrées de terminaux. Cependant, la technologie a évolué pour intégrer des appareils et des interfaces. Par exemple, CICS fonctionne de manière transparente avec les smartphones, les services web, etc. La plateforme est unique dans le monde technologique par son échelle, sa vitesse et ses capacités.
Les principaux utilisateurs de CICS sont les entreprises du Fortune 500 qui s’appuient sur un traitement transactionnel en ligne rapide comme cœur critique de leur activité. Les utilisateurs de CICS comprennent des compagnies d’assurance, des sociétés de télécommunications, des gouvernements, des compagnies aériennes, l’industrie hôtelière, des banques, des maisons de courtage et des sociétés de traitement des cartes de crédit.
Ce benchmark évalue le traitement back-end pour un scénario d’application de vente au détail impliquant des achats depuis un catalogue en ligne. Lors d’une promotion commerciale, le distributeur doit être capable de gérer un très grand volume de requêtes simultanément tout au long de la journée. Le catalogue de vente au détail est conservé dans une table de données partagée gérée par CICS, sauvegardée par un fichier KSDS (key-sequenced dataset) du Virtual Storage Access Method (VSAM).
La conclusion du benchmark explique que CICS peut exécuter jusqu’à 227 000 TPS CICS avec 26 CPU (LPAR en z13). Il démontre comment le CICS Transaction Server peut évoluer pour gérer des charges de travail à des taux de transactions très élevés, tout en maintenant la fiabilité et l’efficacité exigées par les entreprises.
Information Management System (IMS)
L’Information Management System (IMS) d’IBM a été développé au milieu des années 1960 pour répondre au besoin du programme spatial Apollo d’une gestion efficace de la comptabilité pour la construction de modules spatiaux, impliquant plus de deux millions de pièces. Le système a été commercialisé avec le slogan « Le monde en dépend », une affirmation qui s’est avérée vraie au-delà du marketing technologique habituel. IMS est rapidement devenu un standard d’entreprise et reste encore très utilisé par les sociétés du Fortune 500 aujourd’hui, traitant plus de 50 milliards de transactions quotidiennement.
Le système de gestion de base de données (SGBD) IMS a introduit l’idée que le code applicatif devrait être séparé des données. Avant IMS, une application mainframe fusionnait le code et les données en un seul bloc. Mais cela s’est avéré difficile à gérer, notamment en raison des données dupliquées et de la nécessité de réutilisabilité. Une innovation clé d’IMS consistait à séparer ces deux parties. IMS contrôle l’accès et la récupération des données. Les programmes applicatifs peuvent toujours accéder aux données et les parcourir en utilisant l’interface d’appel standard DL/I.
Les principaux composants d’IMS
Cette séparation a établi un nouveau paradigme pour la programmation applicative. Le code applicatif pouvait désormais se concentrer sur la manipulation des données sans les complications et la surcharge associées à leur accès et à leur récupération. Ce paradigme a pratiquement éliminé le besoin de copies redondantes des données. Plusieurs applications pouvaient accéder et mettre à jour une seule instance de données, fournissant ainsi des données actuelles pour chaque application. L’accès en ligne aux données est également devenu plus simple car le code applicatif était séparé du contrôle des données.
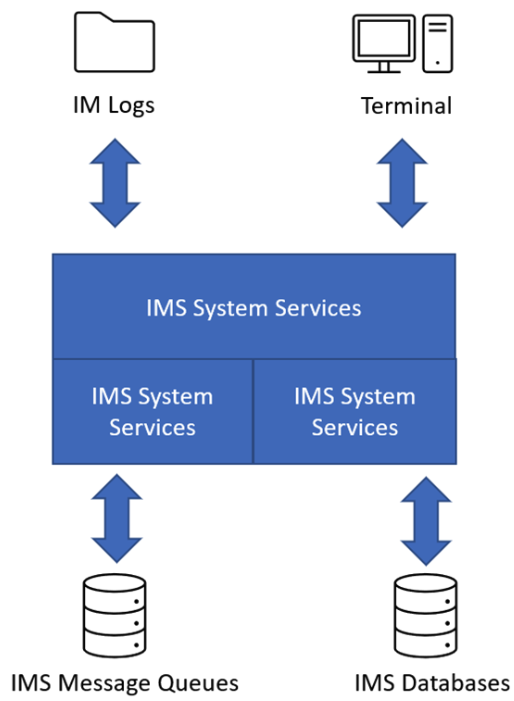
Le gestionnaire de base de données IMS gère les fonctions de base de données fondamentales, telles que le stockage et la récupération des informations. Le gestionnaire de transactions IMS est un système en ligne qui traite de grandes quantités de données transactionnelles en provenance des terminaux et des appareils. Cela est géré à l’aide d’un système basé sur des files d’attente.
Le gestionnaire de base de données IMS est un système de base de données hiérarchique qui organise les données en différents niveaux, du général au spécifique. Il gère les opérations de base de données essentielles telles que le stockage et la récupération des informations.
Par exemple, la structure ressemblerait à la figure ci-dessous si vous souhaitez concevoir une base de données hiérarchique pour les départements d’une entreprise :
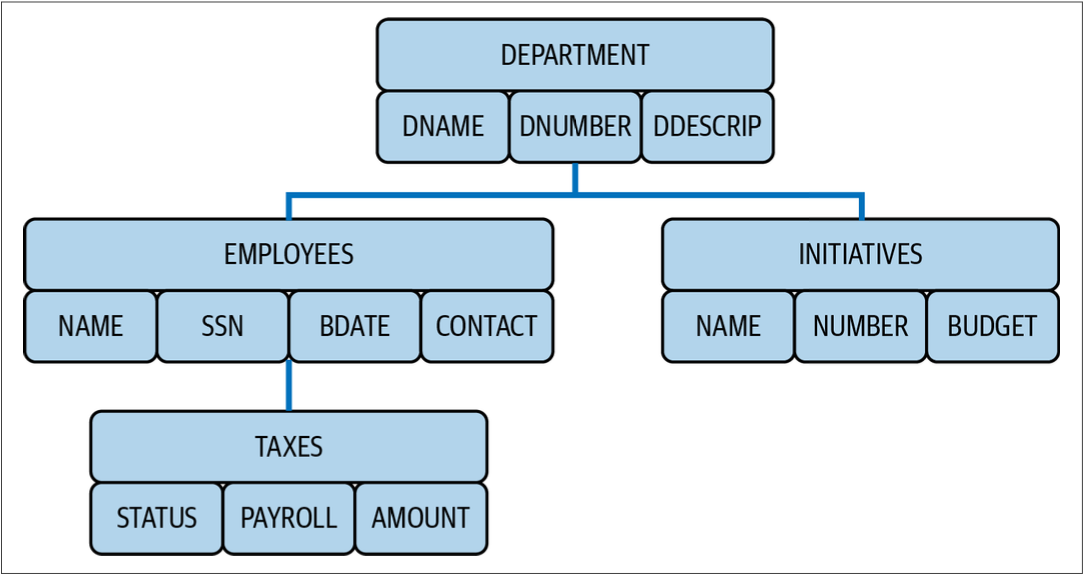
Un modèle IMS
Vous vous demandez peut-être pourquoi vous devriez utiliser une base de données hiérarchique. IMS est l’une des rares bases de données capables d’exécuter plus de 117 000 transactions de mise à jour par seconde. Cette vitesse exceptionnelle est principalement due à la nature inhérente des bases de données hiérarchiques, où les relations sont prédéfinies au sein de la hiérarchie, éliminant le besoin d’un traitement supplémentaire pour établir ces connexions.
IMS bénéficie également de certains avantages intégrés au mainframe, tels qu’un long historique de fiabilité, de sécurité, de scalabilité, et une utilisation moindre de l’espace disque et de la puissance CPU. IMS présente un coût par transaction relativement faible.
En revanche, le premier inconvénient évident d’IMS est que les bases de données hiérarchiques peuvent être compliquées à mettre en place, notamment pour les schémas de données comportant plusieurs niveaux de profondeur. Une autre limitation est qu’il est difficile d’apporter des modifications après la création de la structure initiale, car cela nécessite un remappage des relations, ce qui peut être chronophage.
Integrated Database Management System (IDMS)
IDMS, ou Integrated Database Management System, est un SGBD pour mainframes développé par Cullinet, qui a ensuite été acquis par Computer Associates (connu sous le nom de CA Technologies). IDMS est principalement utilisé pour gérer des applications à grande échelle et haute performance nécessitant des capacités robustes de gestion et de traitement des données.
L’une des fonctionnalités avancées d’IDMS était son Integrated Data Dictionary (IDD) intégré. L’IDD était principalement conçu pour maintenir les définitions de base de données et était lui-même une base de données IDMS. Les administrateurs de bases de données (DBA) et autres utilisateurs interagissaient avec l’IDD en utilisant le Data Dictionary Definition Language (DDDL). De plus, l’IDD était utilisé pour stocker les définitions et le code d’autres produits de la famille IDMS, tels qu’ADS/Online et IDMS-DC. L’extensibilité de l’IDD était l’un de ses aspects les plus puissants, permettant aux utilisateurs de créer des définitions pour pratiquement tout. Certaines entreprises l’ont même utilisé pour développer de la documentation interne.
Contrairement aux bases de données relationnelles qui utilisent des tables, IDMS utilise la structure de réseau CODASYL. Les principaux concepts de structuration dans ce modèle sont les enregistrements et les ensembles. Les enregistrements suivent essentiellement le modèle COBOL, composés de champs de différents types, ce qui permet des structures internes complexes telles que des éléments répétitifs et des groupes répétitifs.
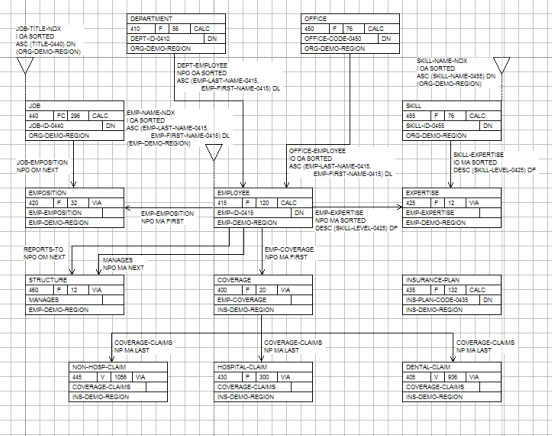
Un modèle IDMS
Le concept de structuration le plus distinctif du modèle Codasyl est l’ensemble. Les ensembles représentent les relations un-à-plusieurs entre enregistrements : un propriétaire et plusieurs membres. Cela permet de gérer efficacement des relations de données complexes grâce aux ensembles et aux types d’enregistrements, offrant des capacités rapides de récupération et de mise à jour des données.
IDMS est conçu pour des performances élevées en traitement transactionnel, ce qui le rend adapté aux applications critiques dans les secteurs bancaire, des assurances et gouvernemental. Ces performances sont dues à la façon dont les données sont stockées dans IDMS. IDMS organise les bases de données en une série de fichiers mappés et préformatés en zones désignées. Ces zones sont ensuite divisées en pages correspondant aux blocs physiques sur le disque, où les enregistrements de base de données sont stockés.
L’administrateur de base de données (DBA) alloue un nombre fixe de pages dans un fichier pour chaque zone et définit quels enregistrements seront stockés dans chaque zone, y compris la façon dont ils seront stockés. IDMS inclut des pages spéciales d’allocation d’espace dans toute la base de données pour suivre l’espace libre disponible sur chaque page. Pour minimiser les exigences d’E/S, l’espace libre est surveillé pour toutes les pages uniquement lorsque l’espace libre pour toute la zone descend en dessous de 30 %.
En revanche, le modèle réseau d’IDMS peut être plus complexe à concevoir et à gérer que les bases de données relationnelles, nécessitant des connaissances et des compétences spécialisées. Apprendre et maîtriser IDMS peut être difficile, particulièrement pour les nouveaux utilisateurs plus familiers avec un SGBDR (SGBDR signifie systèmes de gestion de bases de données relationnelles).
Qu’est-ce qu’un SGBDR ? Il s’agit d’un type de système de gestion de bases de données qui stocke les données dans un format structuré, en utilisant des lignes et des tables, permettant d’identifier et d’accéder aux données par rapport à d’autres données dans la base de données. CockroachDB est un exemple de SGBDR (bien qu’en tant que base de données SQL distribuée, il soit davantage que cela, puisqu’il combine les avantages des SGBDR traditionnels avec la scalabilité des bases de données NoSQL).
Adaptable Database System (ADABAS)
ADABAS (Adaptable Database System) est un système de gestion de bases de données (SGBD) haute performance et haute disponibilité développé par Software AG. Il est conçu pour gérer de grands volumes de transactions et est couramment utilisé dans les environnements mainframe pour les applications critiques.
ADABAS diffère des bases de données relationnelles sur de nombreux aspects. Par exemple, ADABAS stocke de nombreuses relations de données physiquement, réduisant les besoins en ressources CPU par rapport aux bases de données relationnelles qui établissent toutes les relations logiquement à l’exécution.
ADABAS utilise une architecture de liste inversée plutôt qu’un modèle de base de données relationnel traditionnel. Cette structure permet un stockage et une récupération efficaces des données, notamment dans les applications avec des requêtes complexes et de grands ensembles de données. ADABAS est ainsi optimisé pour une récupération rapide des données et un débit élevé de transactions, le rendant adapté aux applications nécessitant des temps de réponse rapides et capables de gérer des millions de transactions par seconde. Il peut gérer de grandes bases de données avec des volumes de données étendus et prendre en charge de nombreux utilisateurs simultanés, ce qui le rend évolutif pour les applications à l’échelle de l’entreprise.
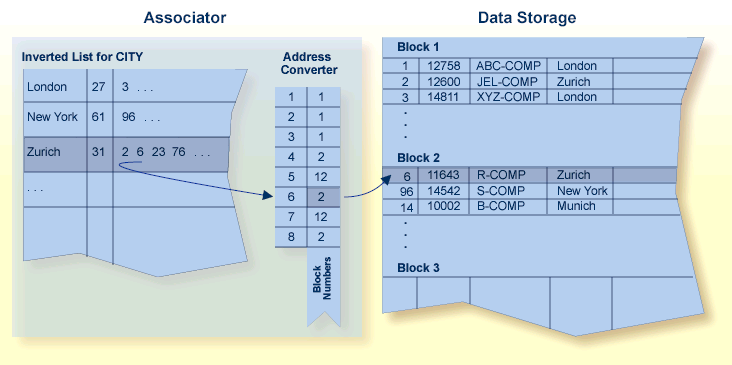
Diagramme de l’Adaptable Database System (ADABAS)
Les hautes performances observées d’ADABAS sont dues à son architecture de stockage sous-jacente. Dans ADABAS, les données sont divisées en blocs, chacun identifié par un numéro de bloc ADABAS relatif de 3 ou 4 octets (RABN), qui identifie l’emplacement physique du bloc par rapport au début du composant. Les blocs de stockage de données contiennent un ou plusieurs enregistrements physiques et une zone de remplissage pour absorber l’expansion des enregistrements dans le bloc.
Un identifiant logique stocké dans les quatre premiers octets de chaque enregistrement physique est la seule information de contrôle stockée dans le bloc de données. Ce numéro de séquence interne, ou ISN, identifie chaque enregistrement de manière unique et ne change jamais. Lors de l’ajout d’un enregistrement, il se voit attribuer un ISN égal au plus grand ISN existant plus un. Lorsqu’un enregistrement est supprimé, son ISN n’est réutilisé que si vous le demandez explicitement à ADABAS. La réutilisation des ISN réduit la surcharge système lors de certaines recherches et est recommandée pour les fichiers avec des enregistrements fréquemment ajoutés et supprimés.
Pour chaque fichier, entre 1 et 90 % (10 % par défaut) de chaque bloc peuvent être alloués comme remplissage en fonction de la quantité et du type de mises à jour attendues. Cet espace réservé permet aux enregistrements de s’agrandir sans migrer vers un autre bloc, minimisant ainsi la surcharge système.
ADABAS sépare les relations de données, la gestion et la récupération des données physiques réelles, stockant les données physiques indépendamment. Ce système offre des techniques d’accès flexibles, permettant des recherches simples et complexes d’être effectuées rapidement et efficacement. L’indépendance des données par rapport au programme minimise le besoin de reprogrammation lorsque la structure de la base de données change.
ADABAS offre des fonctionnalités telles que la réplication des données, la sauvegarde et la récupération, et des mécanismes de basculement pour assurer une haute disponibilité et l’intégrité des données, même en cas de défaillances matérielles ou logicielles. Il inclut une indexation avancée, une compression des données et une gestion dynamique des tampons pour améliorer les performances et l’efficacité.
Bien que traditionnellement utilisé sur les mainframes, ADABAS prend en charge plusieurs plateformes, notamment Linux, UNIX et Windows, offrant une flexibilité dans le déploiement. De nombreuses organisations continuent d’utiliser ADABAS en raison de sa fiabilité et de ses performances dans les systèmes existants. Il est fortement présent dans les secteurs de la finance, du gouvernement et de la santé, où une gestion robuste des données est cruciale.
Datacom/DB
Datacom DB est un système de gestion de bases de données (SGBD) haute performance de niveau entreprise développé au début des années 1970 par Computer Information Management Company. Datacom a été acquis par CA Technologies (anciennement Computer Associates), qui l’a renommé CA Datacom/DB.
Datacom était initialement conçu pour récupérer des données rapidement à partir de fichiers massifs en utilisant des listes inversées. Bien que cette approche ait été très efficace pour la récupération rapide des données, elle aurait pu être plus efficiente pour gérer une maintenance extensive des données. Pour résoudre ce problème, Datacom/DB a adopté la technologie relationnelle, incorporant des capacités uniques basées sur les index qui ont considérablement amélioré la maintenance sans sacrifier la vitesse de récupération. Cette version relationnelle de Datacom est devenue le fondement d’améliorations continues et de premier plan dans l’industrie, maintenant son statut de SGBD rentable et performant pour les mainframes IBM.
Datacom DB est optimisé pour la récupération rapide des données et un débit élevé de transactions, garantissant une gestion efficace du traitement des données à grande échelle. Il peut évoluer pour prendre en charge de vastes bases de données et un grand nombre d’utilisateurs simultanés, le rendant adapté aux applications à l’échelle de l’entreprise. Le système prend en charge les structures de données relationnelles et non relationnelles, offrant une flexibilité dans le stockage et l’accès aux données.
Datacom DB fournit des fonctionnalités robustes d’intégrité des données, de sauvegarde et de récupération, garantissant que les données restent cohérentes et disponibles même en cas de défaillance du système. Il offre des fonctionnalités de sécurité solides pour protéger les données contre les accès non autorisés et assurer la conformité aux exigences réglementaires.
Datacom DB s’intègre bien avec divers langages de programmation et plateformes, offrant un environnement transparent pour le développement d’applications et la gestion des données.
Db2
En 1983, IBM a introduit Db2 pour la plateforme mainframe MVS (Multiple Virtual Storage), représentant une avancée significative sur le marché des bases de données. Au fil des années, il a évolué pour prendre en charge diverses plateformes, notamment Linux, UNIX, Windows, z/OS (mainframe) et iSeries (anciennement AS/400).
Avant cela, les bases de données consistaient principalement en fichiers plats ou utilisaient des modèles tels que des relations hiérarchiques, qui étaient souvent difficiles à modifier.
Db2 stocke les données dans diverses tables liées pour former des relations. Chaque table est bidimensionnelle, composée de colonnes et de lignes. L’intersection d’une colonne et d’une ligne est appelée « valeur » ou « champ », qui peut être alphanumérique, numérique ou null.
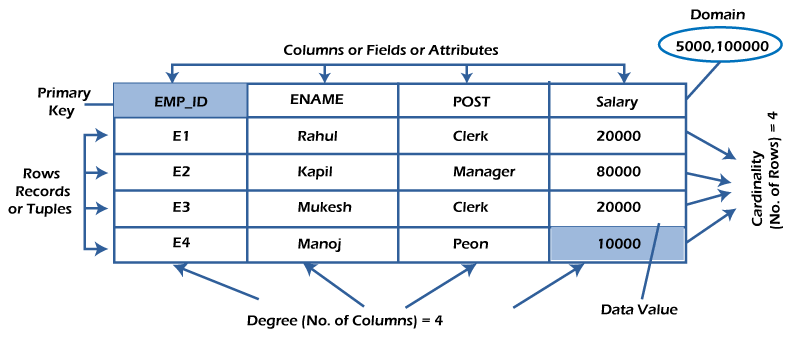
Diagramme Db2
Chaque ligne possède un identifiant unique, la clé primaire, qui facilite la recherche, la mise à jour et la suppression des informations. La clé primaire est automatiquement indexée dans une base de données relationnelle, mais des index supplémentaires peuvent être créés sur d’autres colonnes pour améliorer la vitesse des opérations.
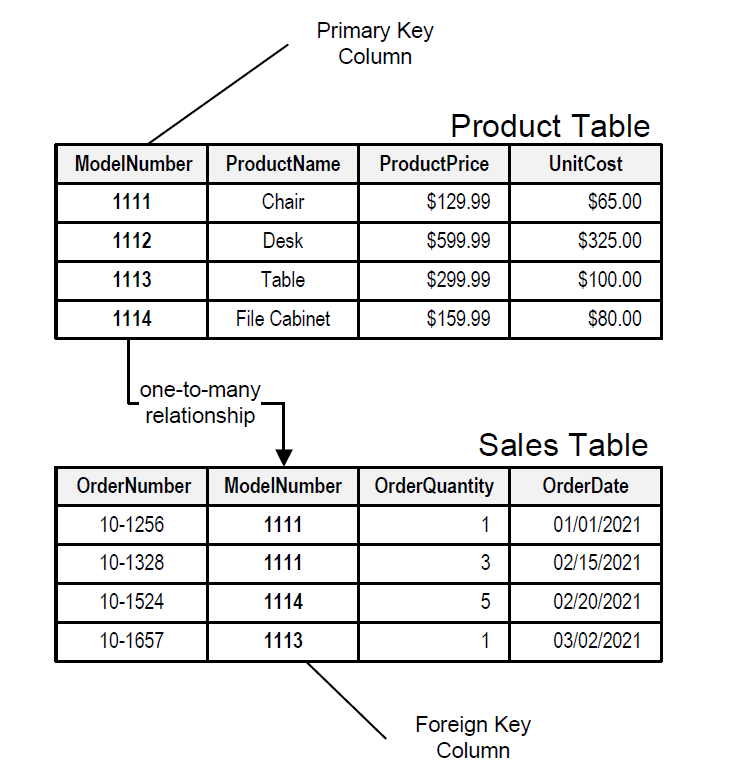
Diagramme de la clé primaire et de la clé étrangère
Les clés primaires permettent la création de relations avec d’autres tables. Une connexion entre les tables est établie à l’aide d’une valeur appelée clé étrangère. Cette connexion se produit lorsqu’une colonne (la clé étrangère) dans une table pointe vers la clé primaire dans une autre table.
L’un des principaux avantages de Db2 est sa polyvalence. Cette base de données prend en charge plusieurs plateformes et modèles de données, la rendant adaptable à divers besoins métier. Elle fonctionne bien avec d’autres produits IBM et des outils tiers, améliorant ses fonctionnalités et sa facilité d’utilisation.
Db2 est optimisé pour de hautes performances et peut gérer des bases de données à grande échelle avec des requêtes complexes et des volumes élevés de transactions. La plateforme est bien connue pour sa robustesse et sa fiabilité, essentielles pour les applications critiques. Elle est conçue pour évoluer efficacement sur plusieurs plateformes et offre également des capacités d’analyse avancées, notamment la prise en charge de l’analyse en base de données et de l’IA pour des insights analytiques améliorés.
Selon cette étude de benchmark, Db2 (à partir de la version 11) offre de nombreuses opportunités de réduction de l’utilisation du CPU dans les charges de travail transactionnelles en ligne simples et dans les requêtes d’analyse en temps réel plus complexes. Les principaux goulots d’étranglement ont été traités pour améliorer la scalabilité des applications insérant simultanément des enregistrements dans les tables Db2. Pour répondre à la demande d’ingestions à haut volume, IBM a introduit un nouvel algorithme d’insertion pour les espaces de table ne nécessitant pas de clustering. Le nouvel algorithme d’insertion et une autre amélioration de la scalabilité dans les écritures de journaux ont permis, lors d’un benchmark interne IBM, d’atteindre 11,7 millions d’insertions par seconde.
Db2 fournit des fonctionnalités de sécurité robustes, notamment le chiffrement, le contrôle d’accès et l’audit, garantissant la protection des données et la conformité réglementaire. Il inclut des fonctionnalités telles que la réplication des données, le clustering et le basculement pour assurer une haute disponibilité et une récupération rapide en cas de défaillances du système.
Bien que Db2 d’IBM soit un système de gestion de bases de données robuste et polyvalent, il présente quelques inconvénients. Le principal est son coût élevé de licence : Db2 peut être coûteux à licencier, notamment pour les grandes entreprises avec une utilisation intensive. Le coût peut constituer un obstacle pour les petites et moyennes entreprises. De plus, le besoin de DBA qualifiés et l’éventuelle exigence de contrats de support IBM peuvent alourdir le coût total de possession.
Bien que Db2 prenne en charge un large éventail de plateformes, l’intégration avec des systèmes et des logiciels non-IBM peut parfois présenter des défis, nécessitant des middlewares supplémentaires ou des solutions personnalisées. Db2 est étroitement intégré avec d’autres produits IBM, entraînant une dépendance vis-à-vis d’un fournisseur unique et rendant difficile le passage à des solutions alternatives sans effort et coût significatifs.
Db2 est largement utilisé dans diverses industries, notamment la finance, la santé, le gouvernement et la distribution, pour les applications de planification des ressources d’entreprise (ERP), de gestion de la relation client (CRM) et de gestion de la chaîne d’approvisionnement (SCM). Les institutions financières utilisent Db2 pour gérer de grands volumes de transactions et assurer l’intégrité des données et les performances dans des applications critiques comme la banque en ligne et le trading boursier.
Db2 est également une solution d’entreposage de données qui offre un stockage efficace, un traitement rapide des requêtes et des capacités analytiques avancées.
Exemples concrets illustrant les divers cas d’usage et industries s’appuyant sur les bases de données mainframe
Les bases de données mainframe jouent un rôle critique dans diverses industries, fournissant des solutions robustes de gestion de données haute performance pour des applications complexes et à grande échelle. Voici quelques exemples concrets illustrant les divers cas d’usage et industries s’appuyant sur les bases de données mainframe :
1. Banque et services financiers
-
Traitement des transactions : De grandes banques comme BNP Paribas, JP Morgan ou State Bank of India utilisent des bases de données mainframe comme Db2 d’IBM ou Datacom DB pour gérer efficacement de vastes quantités de transactions. Ces grandes banques utilisent les systèmes transactionnels présentés précédemment pour traiter des millions de transactions quotidiennes aux distributeurs automatiques, de paiements par carte de crédit et d’activités de banque en ligne.
-
Gestion des informations clients : Les institutions financières s’appuient sur des bases de données mainframe comme IMS ou IDMS pour stocker et récupérer les données clients, garantissant un accès rapide aux informations de compte, à l’historique des transactions et au traitement des prêts.
2. Assurances
-
Gestion des polices : Les compagnies d’assurance utilisent des bases de données mainframe pour gérer les détails des polices, le traitement des sinistres et la souscription. Par exemple, des assureurs comme AXA ou Allianz utilisent IMS ou IDMS pour gérer des millions de dossiers assurés et de sinistres.
-
Analyse des risques et calculs actuariels : Les bases de données mainframe prennent en charge les calculs complexes et l’analyse des données nécessaires à l’évaluation des risques et à la détermination des primes. Les données de risque en ligne sont hébergées dans des fichiers VSAM, et les utilisateurs accèdent généralement à ces applications via des terminaux grâce à des transactions CICS de niveau commande. Des transactions CICS en arrière-plan sont également utilisées pour le traitement par lots, l’analyse des risques et les scores de risque dans l’environnement CICS.
3. Distribution
-
Gestion des stocks : De grands distributeurs comme Walmart et Target utilisent des applications CICS pour gérer les stocks dans des milliers de magasins. Ces systèmes suivent en temps réel les niveaux de stock, les données de ventes et la logistique de la chaîne d’approvisionnement.
-
Programmes de fidélité client : Des distributeurs français comme Auchan ou Carrefour utilisent des bases de données mainframe, notamment Db2 d’IBM, pour stocker et analyser l’historique des achats des clients, permettant des opérations marketing personnalisées et des programmes de récompenses.
4. Secteur public
-
Sécurité sociale : La sécurité sociale française (AMELI) s’appuie sur des bases de données mainframe comme IMS et ADABAS pour gérer les dossiers de millions de bénéficiaires, y compris les paiements, l’éligibilité et les informations personnelles.
-
Traitement fiscal : Des agences comme l’IRS utilisent des applications CICS et Db2 pour traiter les déclarations fiscales, gérer les audits et maintenir des dossiers étendus de manière sécurisée et efficace.
D’autres secteurs utilisent des bases de données mainframe pour gérer et stocker des données d’entreprise critiques. Par exemple, les hôpitaux et les prestataires de soins utilisent des bases de données mainframe pour traiter les dossiers médicaux électroniques (DME), garantissant un accès sécurisé et rapide aux informations des patients. Ces systèmes sont également utilisés dans la recherche médicale pour gérer de grands ensembles de données pour les essais cliniques, la recherche génétique et les études épidémiologiques, soutenant des activités de recherche à forte intensité de données.
Ces systèmes transactionnels sont encore utilisés dans le transport aérien pour gérer les horaires de vols, les réservations et les informations des passagers. Par exemple, le système SABRE d’American Airlines s’appuie sur un ensemble de bases de données mainframe.
De plus, les entreprises manufacturières utilisent des systèmes OLTP mainframe pour traiter les données de production de bout en bout. Cela inclut la gestion de grands volumes de données provenant des lignes de production pour surveiller la qualité et identifier les défauts en temps réel, ainsi que les plannings de production, les niveaux de stocks et la logistique de la chaîne d’approvisionnement.
Cas d’usage des mainframes
Ce ne sont là que quelques exemples soulignant la polyvalence et l’importance critique des bases de données mainframe dans divers secteurs. Leur capacité à gérer de grands volumes de transactions, à garantir l’intégrité des données et à fournir une haute disponibilité les rend indispensables dans le soutien des opérations fondamentales de nombreuses industries.
L’étape suivante : moderniser vers le cloud-native
Les bases de données mainframe continuent de jouer un rôle central dans l’informatique d’entreprise, offrant des performances, une fiabilité et une scalabilité incomparables pour les applications critiques dans diverses industries. Cet article a exploré les aspects fondamentaux du stockage de données mainframe, détaillant les composants architecturaux des bases de données mainframe traditionnelles telles que Db2 d’IBM, IMS et VSAM, ainsi que des systèmes comme ADABAS, IDMS et Datacom/DB. Chaque système de base de données apporte des forces et des défis uniques, depuis les performances de l’IMS hiérarchique jusqu’à la flexibilité relationnelle de Db2.
Les points clés que nous avons abordés ici comprennent :
- les différents niveaux d’abstraction du stockage
- diverses organisations de datasets
- les méthodes d’accès spécifiques qui optimisent la récupération et la gestion des données sur les mainframes
Nous avons également mis en évidence la transition du traitement par lots vers le traitement transactionnel en ligne (OLTP), soulignant la nécessité d’un traitement des données en temps réel dans les environnements métier actuels à rythme rapide.
Des exemples concrets démontrent le rôle critique des bases de données mainframe dans les secteurs bancaire, des assurances, de la distribution, gouvernemental et de la santé. Ces industries s’appuient sur les mainframes pour gérer de grands volumes de transactions, garantir l’intégrité des données et fournir une haute disponibilité, les rendant indispensables aux opérations d’entreprise modernes.
À mesure que les organisations évoluent, la modernisation des systèmes mainframe vers des alternatives cloud-native et distribuées telles que CockroachDB reste un enjeu majeur. Comprendre les subtilités de l’architecture des bases de données mainframe est essentiel pour exploiter pleinement le potentiel des alternatives cloud-native et distribuées afin de naviguer avec succès vers l’avenir de l’informatique d’entreprise.
Références
- Tom Taulli, Modern Mainframe Development, O’Reilly Media, 2022
- Qu’est-ce qu’un dataset ? IBM Docs
- Méthodes d’accès, CIO Wiki
- Introduction à CICS, IBM Docs
- CICS - CodeDocs
- Formation en ligne IBM CICS, Proexcellency
- Histoire d’IMS : les débuts à la NASA, Informit
- IDMS - Wikipedia
- IBM Db2 12 for z/OS Performance Topics, IBM Red Books
- Guide d’utilisation des Partitioned Dataset Extended, IBM Red Books
- Blog Mainframe Concepts and Solutions
- Travailler avec les datasets, Partie 1, Louise Lang (SlidePlayer)
- z/OS Basic Skills, IBM Docs
- Fonctionnement des ressources CICS, IBM Docs
- O. Stevens, “The History of Datacom/DB,” IEEE Annals of the History of Computing, vol. 31, no. 4, pp. 87-91, Oct.-Dec. 2009