
À l’ère du cloud computing, les architectures de bases de données centralisées traditionnelles cèdent de plus en plus la place à des architectures de bases de données distribuées plus flexibles et résilientes. Puisque le cloud est, par définition, un système distribué, l’architecture des bases de données relationnelles traditionnelles entre fréquemment en conflit avec les besoins architecturaux des applications cloud-native modernes : élasticité, passage à l’échelle horizontal et séparation des responsabilités.
La base de données distribuée est apparue comme la réponse à ce conflit, et elle devient mainstream. Les bases de données distribuées, qui stockent et traitent les données sur plusieurs nœuds ou emplacements, offrent une gamme d’avantages qui répondent aux exigences croissantes de scalabilité, de disponibilité et de performance des applications modernes.
Cet article poursuit la construction de la série « Du Mainframe au SQL Distribué » de Cockroach Labs. Nous y explorons les nombreux avantages de l’architecture de bases de données distribuées, en mettant en lumière comment elle améliore les capacités de gestion des données et soutient les besoins dynamiques des entreprises numériques d’aujourd’hui. De la tolérance aux pannes améliorée à la scalabilité transparente et à la localité des données renforcée, nous verrons pourquoi les organisations adoptent les bases de données distribuées pour faire avancer leurs initiatives axées sur les données.
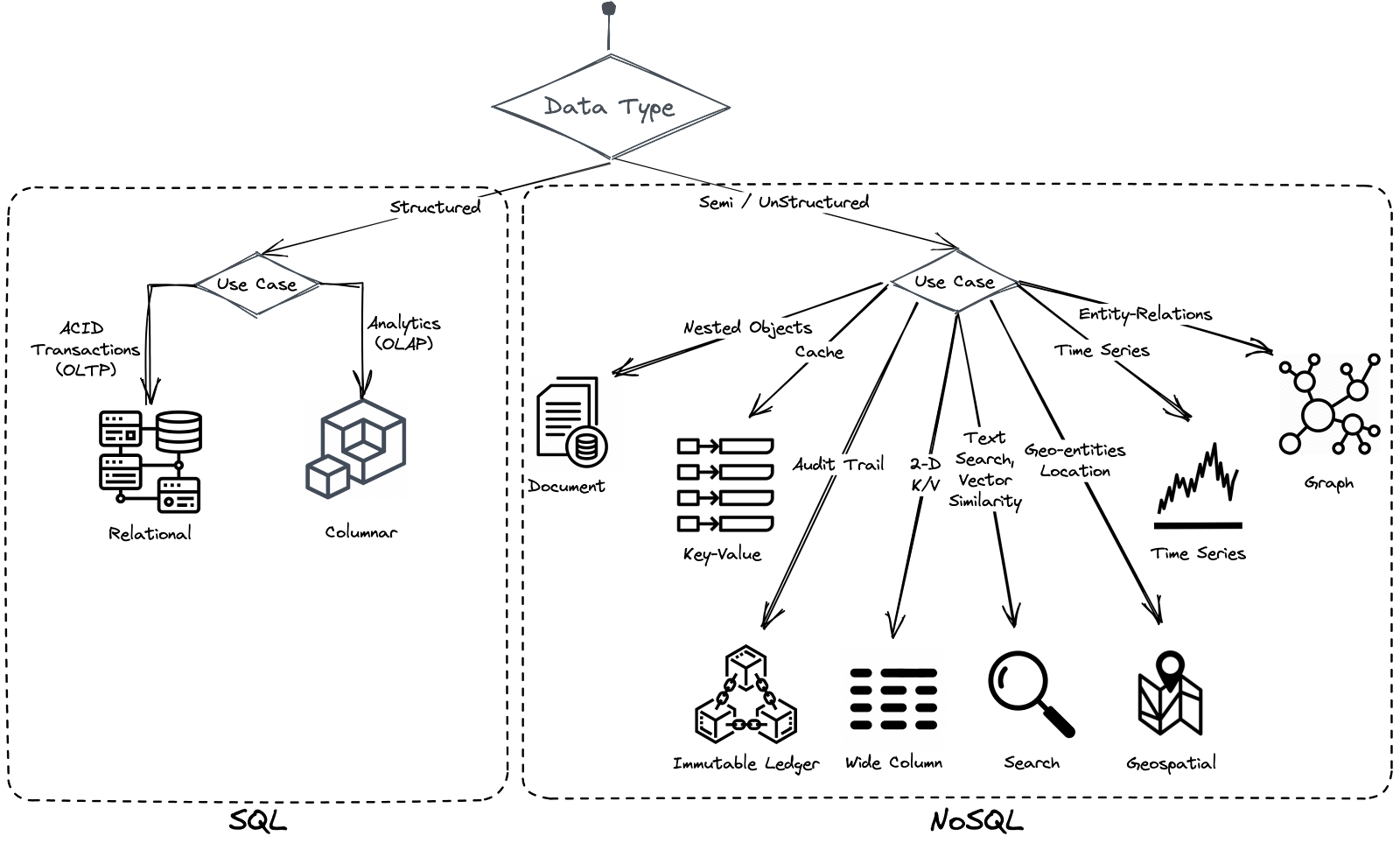
Types de bases de données distribuées
Les bases de données SQL, inventées par Edgar F. Codd, utilisent des tables et des schémas pour stocker et relier les données. Elles sont devenues le standard du stockage de données dans les années 1970 grâce à leur support des garanties transactionnelles ACID (Atomicité, Cohérence, Isolation, Durabilité). Cependant, leur incapacité à évoluer facilement et à fonctionner efficacement dans les environnements cloud a conduit au développement des bases de données NoSQL, qui sont cloud-native, résilientes et évolutives horizontalement.
Les bases de données NoSQL, cependant, sacrifient l’application stricte des schémas et les garanties ACID, ce qui peut compromettre la cohérence des données et leur exactitude dans les charges de travail transactionnelles.
Types de bases de données distribuées
Ces dernières années, les bases de données SQL distribuées, également connues sous le nom de « new SQL », ont émergé pour combiner les avantages du NoSQL (scalabilité cloud-native et résilience) avec les schémas stricts et les garanties ACID des bases de données relationnelles traditionnelles. Ces bases de données ne nécessitent pas de sharding manuel et offrent des garanties ACID, les rendant idéales pour les charges de travail transactionnelles et les applications nécessitant une haute cohérence des données.
Aujourd’hui, les bases de données NoSQL et SQL distribuées sont toutes deux largement utilisées. Les bases de données NoSQL sont préférées pour les charges de travail analytiques et le big data, tandis que les bases de données SQL distribuées sont privilégiées pour les charges de travail transactionnelles et les applications où la cohérence des données est critique.
Principes des bases de données distribuées
Qu’est-ce qu’une base de données distribuée ? Les bases de données distribuées sont devenues un pilier de la gestion des données moderne, offrant des solutions robustes pour les applications à grande échelle et haute performance. Comprendre les principes fondamentaux des architectures de bases de données distribuées est essentiel pour exploiter pleinement leur potentiel. Ces principes définissent les caractéristiques fondamentales et les cadres opérationnels qui rendent les bases de données distribuées puissantes et polyvalentes.
Distribution des données
Les données dans une base de données distribuée sont stockées sur plusieurs emplacements physiques. Ces emplacements peuvent être différents serveurs, centres de données, ou même des régions géographiquement dispersées. Supposons qu’une base de données à instance unique tombe hors ligne (en raison d’une panne de courant, d’une défaillance machine, d’une maintenance planifiée ou autre). Dans ce cas, tous les services applicatifs qui en dépendent seront également hors ligne.
En revanche, les bases de données distribuées gèrent les pannes en divisant les données en morceaux plus petits et gérables (sharding) et en les répliquant sur plusieurs emplacements physiques. Ainsi, si un serveur tombe hors ligne, vos données resteront accessibles sur les autres serveurs.
Les systèmes distribués utilisent des techniques d’équilibrage de charge pour distribuer équitablement les charges de travail sur plusieurs nœuds. Le système peut traiter davantage de requêtes simultanément en évitant qu’un seul nœud ne devienne un goulot d’étranglement. De plus, un équilibrage de charge efficace garantit qu’aucun nœud n’est surchargé, maintenant la stabilité et les performances du système.
Les systèmes distribués permettent également le traitement parallèle, où les tâches sont divisées et traitées simultanément sur plusieurs nœuds. Les grandes tâches peuvent être décomposées en tâches parallèles plus petites, accélérant considérablement les temps de traitement.
Un autre avantage des systèmes distribués est que les données peuvent être stockées plus près de l’endroit où elles sont nécessaires, réduisant la latence et améliorant les temps d’accès. Vous pouvez également ancrer vos données à un emplacement spécifique pour respecter les réglementations de blocage géographique (RGPD, par exemple).
Enfin, les systèmes distribués peuvent isoler les ressources pour différentes tâches ou locataires, améliorant les performances et la sécurité. Différents utilisateurs ou applications peuvent partager la même infrastructure tout en étant isolés les uns des autres, améliorant l’efficacité des ressources (multi-location).
Scalabilité
À mesure que les applications évoluent pour servir plus d’utilisateurs, les besoins en stockage et en calcul de la base de données augmentent avec le temps, et pas toujours à un rythme prévisible.
Essayer de suivre cette croissance avec une base de données à instance unique est difficile. Vous devez soit :
- Payer pour plus de ressources que vous n’en avez besoin afin que votre base de données ait de la « marge de manœuvre » en termes de stockage et de puissance de calcul, ou
- Naviguer dans des mises à niveau matérielles régulières (scalabilité verticale) et des migrations pour s’assurer que l’instance de base de données s’exécute toujours sur une machine capable de gérer la charge actuelle.
Les bases de données distribuées, en revanche, peuvent évoluer horizontalement simplement en ajoutant des instances ou des nœuds supplémentaires. Ainsi, si votre charge de travail fait face à un pic de demande, prévisible ou non, vous pouvez ajouter des nœuds à votre cluster, et votre base de données devrait gérer la charge accrue de manière transparente (scalabilité linéaire).
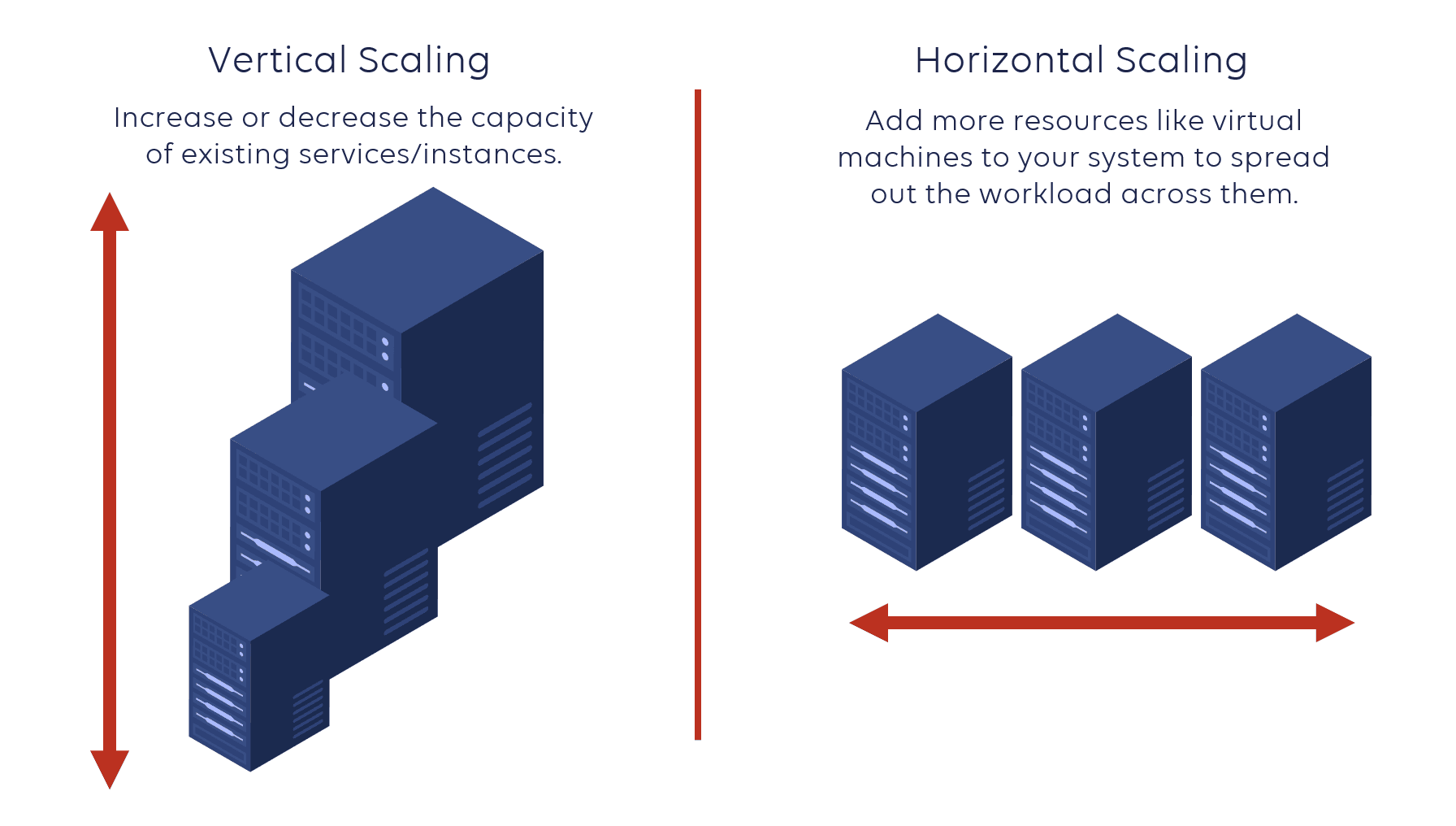
Diagramme de passage à l’échelle vertical vs horizontal
De plus, dans les bases de données distribuées serverless, les nœuds peuvent être ajoutés ou retirés dynamiquement en fonction de la demande. Les ressources ne sont provisionnées que lorsque nécessaire, réduisant le gaspillage et optimisant les coûts. Le système peut gérer les pics soudains de trafic sans compromettre les performances ou la disponibilité. Ainsi, votre base de données n’est ni sous-provisionnée ni sur-provisionnée, ce qui optimise le TCO de votre infrastructure.
Transparence
Les bases de données distribuées visent à présenter une vue unifiée des données à l’utilisateur final, quel que soit l’endroit où les données sont physiquement stockées. Vous pouvez étendre votre cluster sur plusieurs pays et/ou continents. Cependant, les données sont toujours exposées de manière transparente aux utilisateurs finaux sans aucune indication sur leur emplacement de stockage (transparence de localisation).
Dans les bases de données distribuées comme CockroachDB, le système masque les complexités de la réplication des données (sharding de l’espace de clés en ranges et distribution des ranges) à l’utilisateur. Les utilisateurs finaux n’ont pas besoin de connaître l’emplacement physique des données car le système les expose comme une seule base de données logique avec un point d’entrée unique (transparence de réplication).
De plus, le système reste disponible pendant les pannes et se remet en état par la suite. Par exemple, si un nœud tombe hors ligne (en raison d’une panne de courant, d’une défaillance machine, ou autre), le cluster continue sans interruption. Le cluster tentera même de se réparer en répliquant à nouveau les données manquantes sur d’autres nœuds. Ainsi, les utilisateurs finaux travaillent toujours sans interruption dans toutes les conditions (transparence aux pannes).
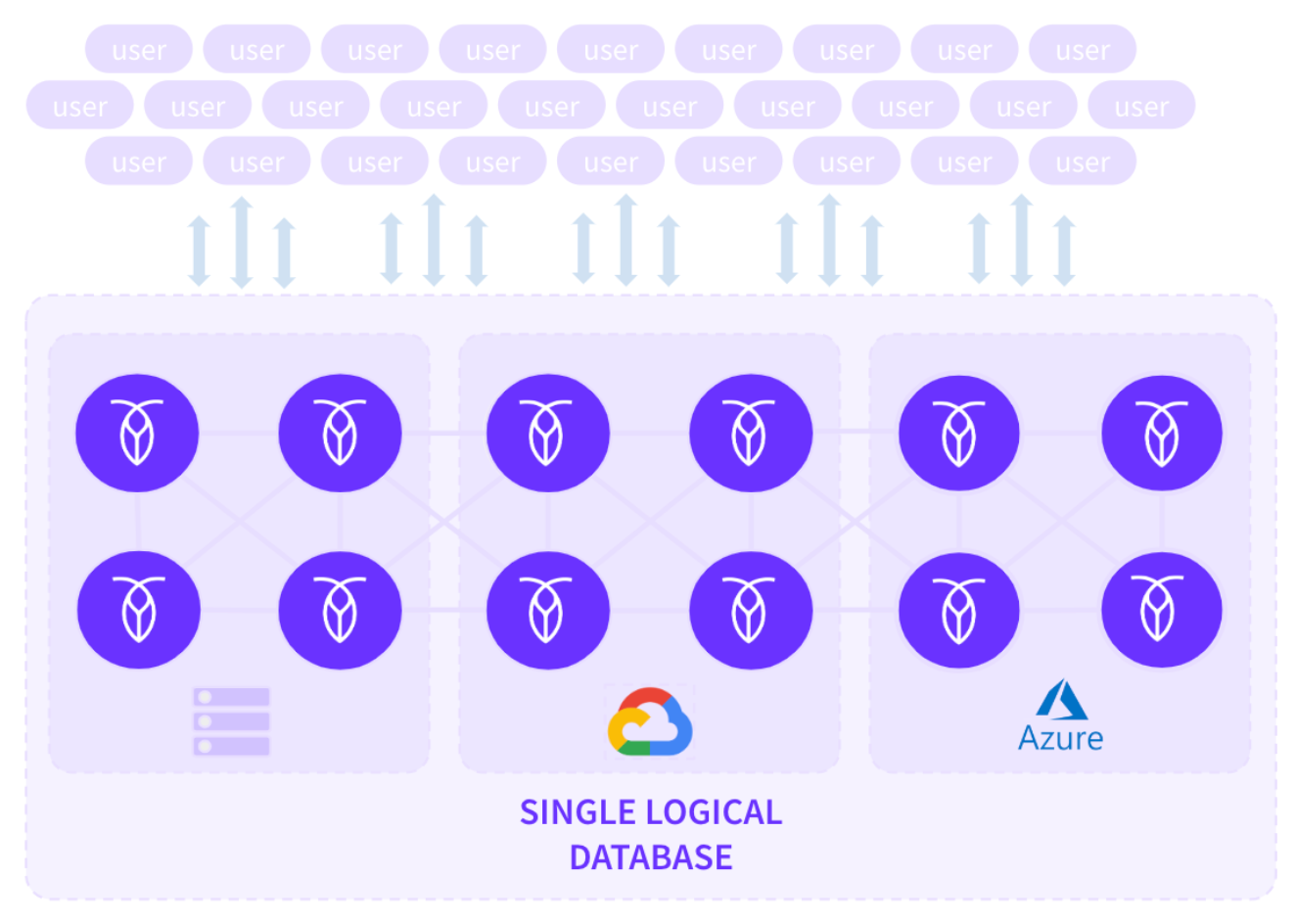
Base de données logique unique sur des nœuds distribués
Fiabilité et disponibilité
La réplication des données et les mécanismes de tolérance aux pannes permettent d’atteindre fiabilité et haute disponibilité. Les bases de données distribuées offrent intrinsèquement des mécanismes avancés de tolérance aux pannes et de résilience, les rendant idéales pour maintenir une haute disponibilité et une reprise après sinistre robuste.
La réplication des données est une stratégie fondamentale dans les bases de données distribuées pour assurer la disponibilité et la durabilité des données. Les données sont écrites sur plusieurs nœuds simultanément, et toutes les copies doivent être mises à jour avant qu’une transaction soit considérée comme complète. Cela assure une forte cohérence et garantit un basculement immédiat avec une perte de données minimale.
Les bases de données distribuées emploient la redondance et le basculement automatique pour maintenir la continuité de service. Plusieurs copies des données sont maintenues sur différents nœuds. Si un nœud tombe en panne, le système réachemine automatiquement les requêtes du nœud défaillant vers un nœud sain qui peut servir les données, assurant une haute disponibilité.
De cette façon, les bases de données distribuées peuvent détecter et récupérer automatiquement des pannes. Le système surveille en permanence la santé et les performances des nœuds. Ainsi, il peut automatiquement isoler et réparer les nœuds défaillants, restaurant les opérations normales.
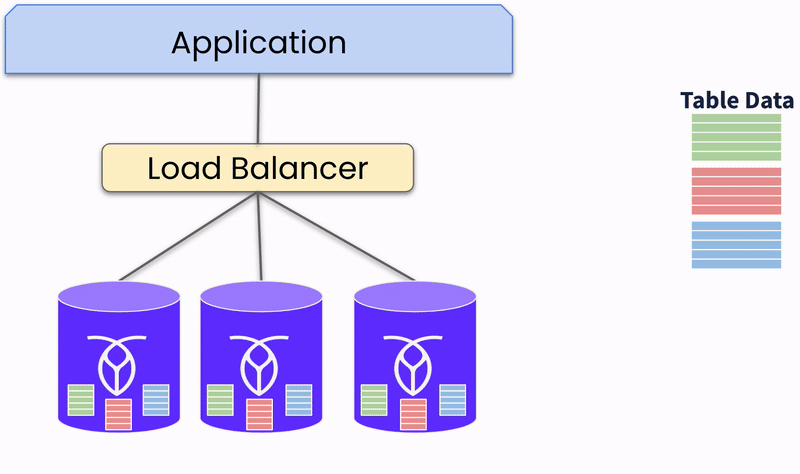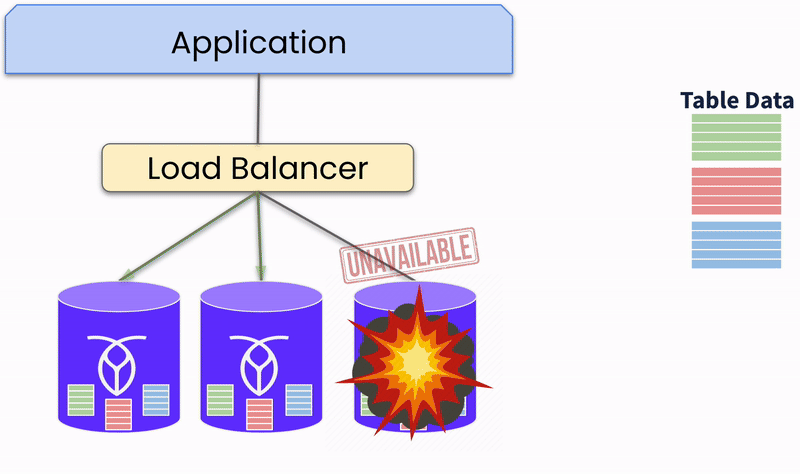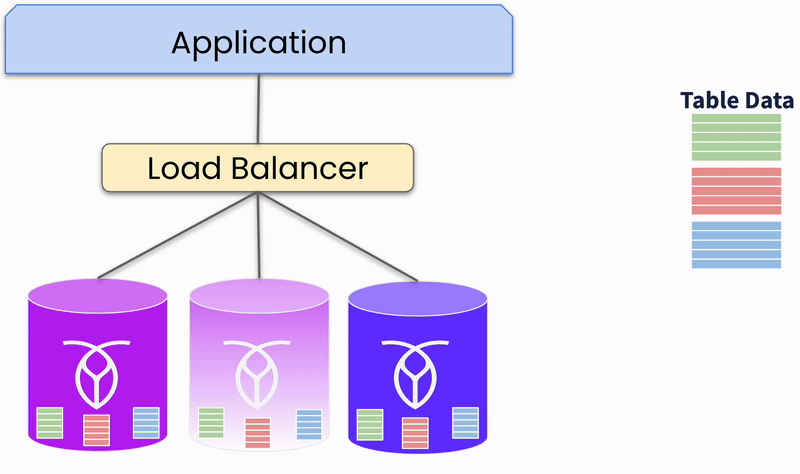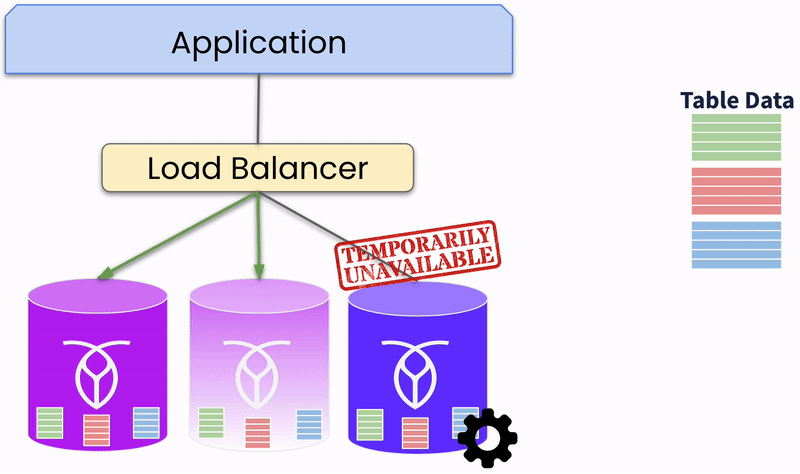
Réplication des données de table sur les nœuds
Pour cette capacité, les bases de données distribuées s’appuient sur des protocoles de consensus tels que Paxos et Raft (Replication And Fault Tolerance) qui permettent d’atteindre le consensus entre les nœuds distribués. Le consensus est établi par des mécanismes basés sur le quorum, garantissant qu’une majorité de nœuds s’accordent sur une transaction avant qu’elle ne soit validée. Ainsi, les nœuds doivent s’accorder sur l’état des données ou l’ordre des transactions, et une transaction n’est considérée réussie que si un quorum de nœuds l’approuve. Le système assure ainsi l’intégrité et la cohérence des données même en présence de pannes de nœuds. Ces protocoles équilibrent cohérence et disponibilité dans un système partitionné (théorème CAP).
Gestion décentralisée
La gestion décentralisée est fondamentale aux bases de données distribuées, les distinguant des systèmes de bases de données traditionnels centralisés. Cette approche distribue le contrôle et la gestion sur plusieurs nœuds, améliorant la scalabilité globale, la tolérance aux pannes et la résilience du système. Dans un système décentralisé, chaque nœud fonctionne de manière indépendante tout en se coordonnant avec les autres nœuds, via des protocoles de consensus, pour gérer les données et traiter les transactions.
De plus, la gestion décentralisée permet un meilleur équilibrage de charge et une meilleure distribution des ressources. En empêchant qu’un seul nœud ne devienne un goulot d’étranglement, le système peut utiliser ses ressources plus efficacement, améliorant les performances.
Enfin, la gestion décentralisée permet à chaque nœud du cluster de s’adapter rapidement aux changements des modèles de charge de travail et de distribution des données. Cette flexibilité les rend bien adaptés aux environnements dynamiques où les modèles d’accès aux données varient au fil du temps.
Défis des bases de données distribuées
Les bases de données distribuées offrent plusieurs avantages, tels que la scalabilité et la résilience. CockroachDB, par exemple, fournit des fonctionnalités comme le traitement de la base de données comme un déploiement à instance unique et l’offre de flux CDC (change data capture) pour les applications pilotées par les événements, simplifiant les flux de travail des développeurs. Cependant, les bases de données distribuées présentent également des inconvénients potentiels :
-
Complexité opérationnelle accrue : La gestion d’une base de données distribuée peut être plus complexe que celle d’une base de données à instance unique, bien que les options de DBaaS (database as a service) géré puissent alléger ce problème.
-
Courbe d’apprentissage : Les équipes peuvent avoir besoin de temps pour s’adapter aux nouvelles bonnes pratiques, notamment avec les bases de données NoSQL qui peuvent utiliser des langages de requête propriétaires.
Des facteurs supplémentaires incluent le coût, qui peut varier en fonction de la base de données choisie, de la méthode de déploiement, des exigences de charge de travail et de la configuration. Bien que les bases de données distribuées puissent sembler plus coûteuses en raison de multiples instances, elles peuvent s’avérer rentables en évitant les coûts financiers élevés des temps d’arrêt. Le DBaaS géré peut également réduire les charges opérationnelles, les rendant potentiellement plus économiques à long terme.
Les organisations investissent généralement des ressources significatives dans les tests et l’évaluation des options de bases de données pour déterminer laquelle est la plus adaptée à leur budget et à leurs exigences.
Configurations des bases de données distribuées
L’objectif principal d’une base de données distribuée est d’assurer une haute disponibilité, ce qui signifie que la base de données et toutes ses données restent accessibles en tout temps. Dans un système distribué, les données sont répliquées sur plusieurs instances physiques, et il existe diverses méthodes pour configurer ces réplicas :
-
Actif-passif : Une configuration actif-passif achemine tout le trafic vers un seul réplica actif, avec les données ensuite copiées vers des réplicas passifs pour la sauvegarde. Par exemple, dans une configuration à trois nœuds, les données sont écrites sur le nœud 1 (actif) et copiées vers les nœuds 2 et 3 (passifs). Cette méthode est simple mais introduit des problèmes potentiels :
- Réplication synchrone : Assure la cohérence mais peut sacrifier la disponibilité si un réplica tombe en panne.
- Réplication asynchrone : Maintient la disponibilité mais peut entraîner des incohérences ou des pertes de données.
Les configurations actif-passif sont simples mais impliquent des compromis affectant la disponibilité et la cohérence de la base de données.
-
Actif-actif : Dans une configuration actif-actif, plusieurs réplicas actifs gèrent le trafic simultanément, assurant une haute disponibilité, car les autres réplicas peuvent gérer le trafic si l’un tombe hors ligne. Cette configuration est cependant plus complexe à configurer et peut toujours faire face à des problèmes de cohérence lors des pannes. Par exemple, si un réplica actif (A) reçoit une écriture et tombe en panne avant que les données ne soient répliquées vers un autre réplica (B), les lectures ultérieures depuis B peuvent ne pas refléter la dernière écriture, conduisant à des incohérences. Une configuration et des tests minutieux sont essentiels pour atténuer ces risques.
-
Multi-actif : CockroachDB est un exemple de base de données utilisant une configuration multi-actif, améliorant la disponibilité au-delà des configurations actif-passif et actif-actif. Dans un système multi-actif, tous les réplicas peuvent gérer les lectures et les écritures.
Cependant, contrairement à l’actif-actif, le multi-actif élimine les incohérences en utilisant un système de réplication par consensus. Les écritures ne sont validées que lorsqu’une majorité de réplicas confirme leur réception, définissant la correction par consensus majoritaire. Cette approche garantit que la base de données reste cohérente et en ligne même si certains réplicas sont hors ligne. Si une majorité est hors ligne, la base de données devient indisponible pour éviter les incohérences.
Fonctionnement d’une base de données distribuée
Les bases de données distribuées sont intrinsèquement complexes. Bien que cet article ne plonge pas dans tous les détails, il fournira une vue d’ensemble de haut niveau du fonctionnement d’une base de données SQL distribuée.
Réplication
Du point de vue de votre application, une base de données distribuée fonctionne comme une base de données à instance unique : vous vous y connectez et envoyez des données de manière similaire. Cependant, une fois que les données atteignent la base de données, elles sont automatiquement répliquées et distribuées sur trois nœuds ou plus (instances individuelles de la base de données distribuée).
Pour illustrer ce processus, concentrons-nous sur un seul morceau de données (appelé range dans CockroachDB) écrit dans la base de données dans un cluster à trois nœuds et une seule région. Bien que des bases de données comme CockroachDB prennent en charge les déploiements multi-régions et un grand nombre de nœuds, cet exemple simplifie l’explication.
Lorsque des données dans un range sont envoyées à la base de données, elles sont écrites dans trois réplicas, un sur chaque nœud. L’un de ces nœuds est désigné comme le « leaseholder » pour ce range, coordonnant les requêtes de lecture et d’écriture pour les données. Cependant, n’importe quel nœud peut recevoir des requêtes, distinguant CockroachDB des systèmes actif-passif où toutes les requêtes doivent passer par un nœud « actif » central.
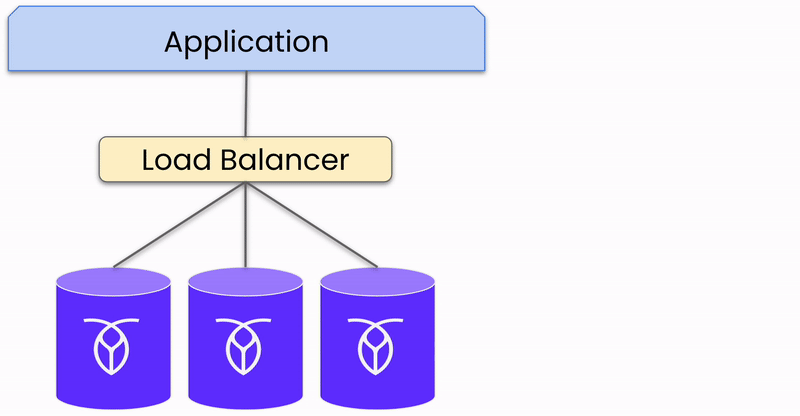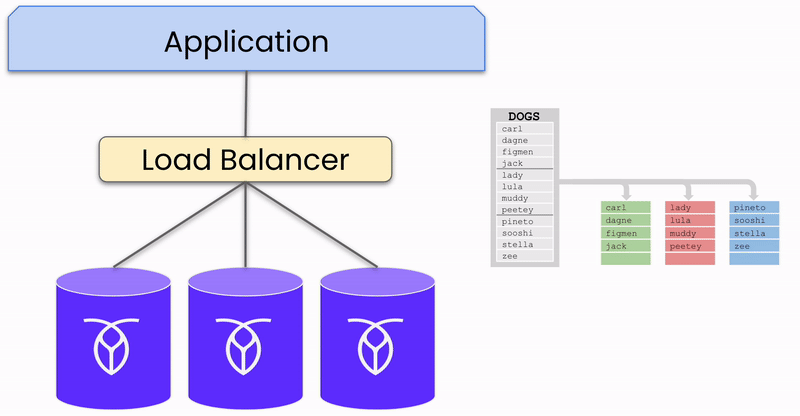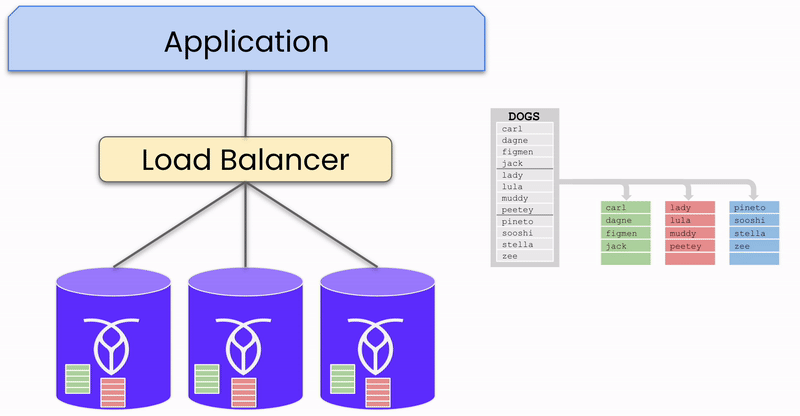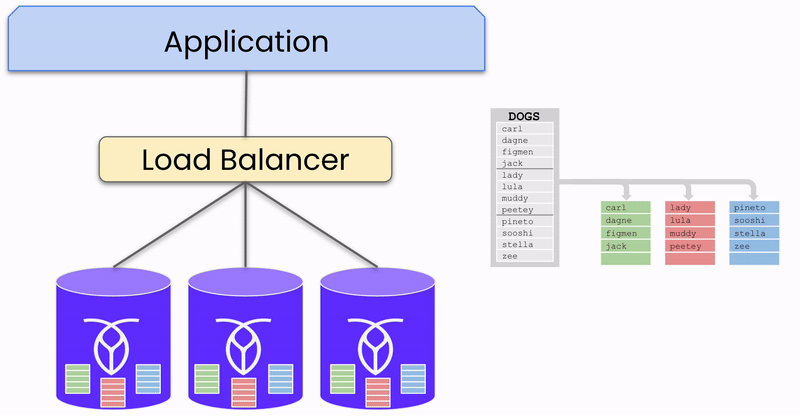
Réplication des données sur les nœuds du cluster
La cohérence entre les réplicas est maintenue à l’aide de l’algorithme de consensus Raft, garantissant qu’une majorité de réplicas s’accordent sur l’exactitude des données avant de valider une écriture.
Consensus
Le consensus est un problème fondamental dans les systèmes distribués tolérants aux pannes. Le consensus implique que plusieurs serveurs s’accordent sur des valeurs. Une fois qu’ils parviennent à une décision sur une valeur, cette décision est définitive. Les algorithmes de consensus typiques progressent lorsqu’une majorité de leurs serveurs est disponible ; par exemple, un cluster de cinq serveurs peut continuer à fonctionner même si deux serveurs tombent en panne. Si davantage de serveurs tombent en panne, ils cessent de progresser (le quorum n’est pas atteint).
Le protocole Raft (Replication and Fault Tolerance) est un algorithme de consensus conçu pour les systèmes distribués, introduit par Diego Ongaro et John Ousterhout en 2014. Il est connu pour sa simplicité et son efficacité, ce qui a conduit à son adoption généralisée dans l’industrie. Raft garantit que tous les nœuds dans un système distribué s’accordent sur un seul état, même en cas de pannes ou de partitions réseau. Les composants clés de Raft sont :
-
Élection du leader : Les nœuds communiquent pour élire un leader responsable de prendre des décisions et de recevoir les requêtes des clients. Si le leader tombe en panne, un nouveau leader est élu par un processus de vote parmi les nœuds restants.
-
Réplication des journaux : Le leader maintient un journal de toutes les transactions validées et réplique ces entrées de journal vers les autres nœuds. Chaque nœud applique les entrées de journal à sa machine d’état pour assurer la cohérence avec le leader.
-
Sécurité : Raft garantit qu’une majorité de nœuds doit s’accorder sur toute décision avant qu’elle ne soit validée. Cela empêche les décisions conflictuelles de différents leaders.
De nombreuses bases de données distribuées, comme CockroachDB, utilisent le protocole Raft pour assurer la cohérence et la fiabilité sur ses nœuds. Raft permet à CockroachDB de fonctionner comme un système multi-actif, où tous les nœuds peuvent recevoir des requêtes de lecture et d’écriture sans risquer des problèmes de cohérence.
Consensus : concepts préalables
Pour comprendre le fonctionnement de Raft, vous devez connaître les concepts suivants :
-
Quorum : Si votre système distribué a N nœuds, vous avez besoin d’au moins (N/2) + 1 nœuds pour s’accorder sur une valeur. Vous avez besoin d’une majorité (plus de 50 %) des votes pour avoir un consensus (comme dans toute élection politique). Un vote majoritaire garantit que lorsque (N/2) + 1 nœuds fonctionnent et répondent, au moins un nœud contient la valeur la plus récente pour une donnée donnée, pour les requêtes de lecture et d’écriture, même en cas de partition réseau ou autre défaillance dans le système.
-
Tolérance aux pannes : Dans un système basé sur le quorum, votre cluster peut tolérer N/2 pannes de nœuds si N est impair. (N/2)-1 sinon.
-
Taille du cluster : Considérez un cluster de quatre nœuds ; la majorité requise est de trois, et vous ne pouvez tolérer qu’une seule panne de nœud. Pour un cluster de cinq nœuds, la majorité est toujours de trois, mais vous pouvez tolérer deux pannes de nœuds. Donc, du point de vue de la gestion des pannes, un nombre pair de nœuds n’apporte pas beaucoup de valeur car la tolérance aux pannes est moindre. Il vaut donc mieux choisir des nombres impairs de nœuds en production, à un coût légèrement plus élevé, afin de pouvoir tolérer davantage de pannes de nœuds !
-
États des nœuds : Les nœuds Raft peuvent être dans trois états : Leader, Follower et Candidate. Le leader est la source de vérité. Les journaux transitent toujours du leader vers les followers.
-
Journal : Un journal est un fichier sur disque où des objets appelés entrées de journal sont généralement ajoutés séquentiellement en données binaires. Dans le contexte Raft, on trouve deux types de journaux :
-
Journaux validés : Une entrée de journal est validée uniquement lorsque la majorité des nœuds du cluster la répliquent. Un journal validé ne peut jamais être écrasé. Il est durable et finit par être exécuté par tous les nœuds du cluster Raft.
-
Journaux non validés : Si une entrée de journal client n’a pas encore été répliquée vers la majorité des nœuds du cluster, elle est appelée journal non validé. Les journaux non validés peuvent être écrasés dans un nœud follower.
-
-
Machine d’état : Chaque nœud possède sa propre machine d’état. Raft doit s’assurer que toutes les entrées de journal validées sont finalement appliquées à la machine d’état, qui sert de source de vérité pour les données en mémoire.
-
Terme ou bail : Il représente une période de temps pendant laquelle un nœud agit en tant que leader. Le concept est basé sur le temps logique (pas le temps global) ; c’est simplement un compteur géré par chaque nœud individuellement. Une fois qu’un terme se termine, un autre terme commence avec un nouveau leader. Même si les termes/baux entre nœuds peuvent différer à un moment donné, Raft dispose d’un mécanisme pour les synchroniser et les faire converger vers la même valeur.
-
RPC : Les nœuds participant à Raft communiquent entre eux en utilisant un Remote Procedure Call (RPC) par-dessus TCP. Ce protocole est adapté à la communication entre centres de données, systèmes internes et services (et non aux produits ou services destinés aux utilisateurs). Raft utilise deux types différents de requêtes RPC. À un niveau élevé :
-
RequestVote (RV) : Lorsqu’un nœud souhaite devenir leader, il envoie cette requête aux autres nœuds pour leur demander de voter pour lui.
-
AppendEntries (AE) : Ce message demande aux followers d’ajouter une entrée à leur fichier journal. Le leader peut envoyer un message vide comme signal de présence (heartbeat), indiquant aux followers que le nœud est toujours actif.
-
Fonctionnement du consensus Raft
Pour notre explication, nous utiliserons un cluster de cinq nœuds. Tous les nœuds démarrent avec un délai aléatoire de journaux vides et commencent à décompter.
Comme mentionné précédemment, un nœud peut être dans différents états selon la situation du cluster. Pour comprendre la transition d’état, examinons le diagramme suivant :
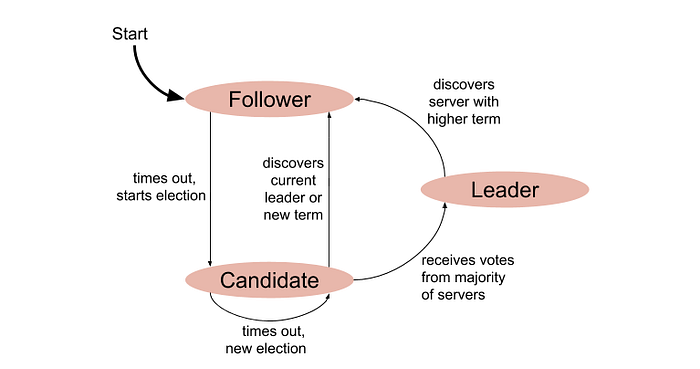
Transitions d’état des nœuds Raft
Chaque nœud commence dans l’état Follower. Une fois le délai d’élection écoulé, il entre dans l’état Candidate, ce qui signifie que le nœud est maintenant éligible pour devenir Leader. Une fois qu’un candidat obtient une nette majorité des votes, il entre dans l’état Leader.
S’il n’y a pas de gagnant clair pendant le processus d’élection, le candidat expire à nouveau, reste dans l’état Candidate, et une nouvelle élection commence. Pour comprendre comment un candidat peut être élu leader du cluster, examinons les séquences suivantes :
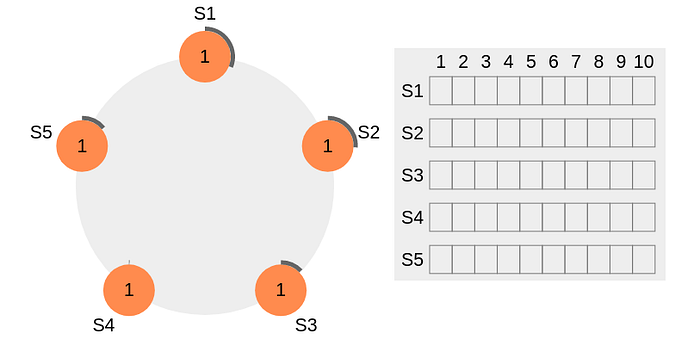
Étape 1 de l’élection du leader du cluster Raft
Le périmètre noir épais autour des nœuds représente le délai d’attente. Notez que les longueurs du périmètre représentent différentes valeurs de délai pour chaque nœud. Ici, chaque nœud est initialisé avec le terme = 1. S4 expire en premier, démarre un nouveau processus d’élection et incrémente la valeur du terme local de 1. S4 vote pour lui-même et envoie un message RequestVote (RV) à tous les autres nœuds du cluster.
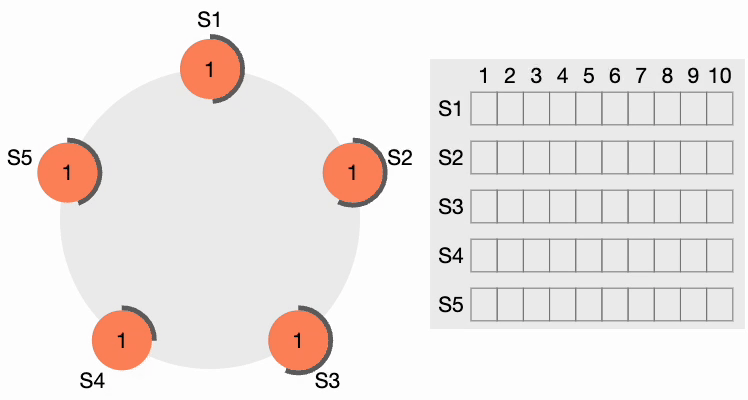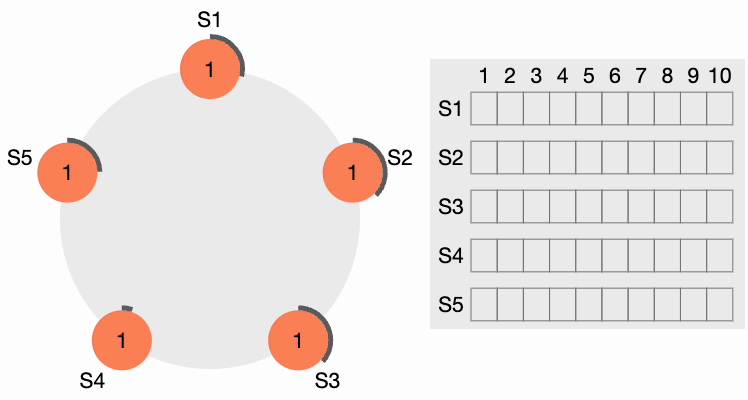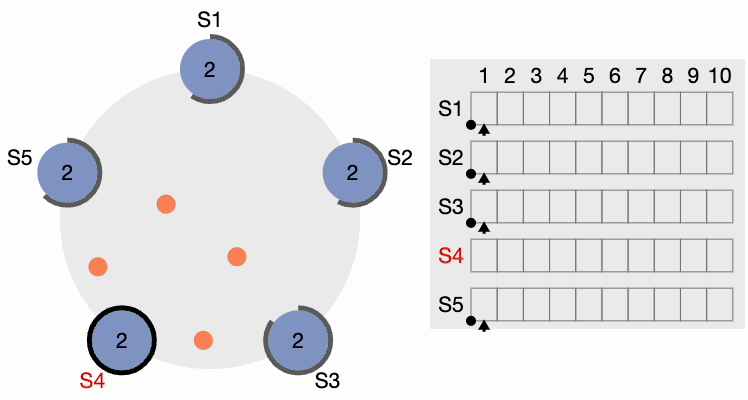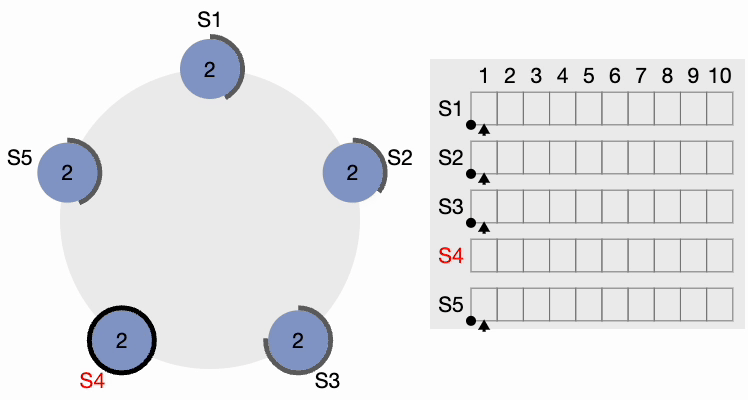
Étape 2 de l’élection du leader du cluster Raft
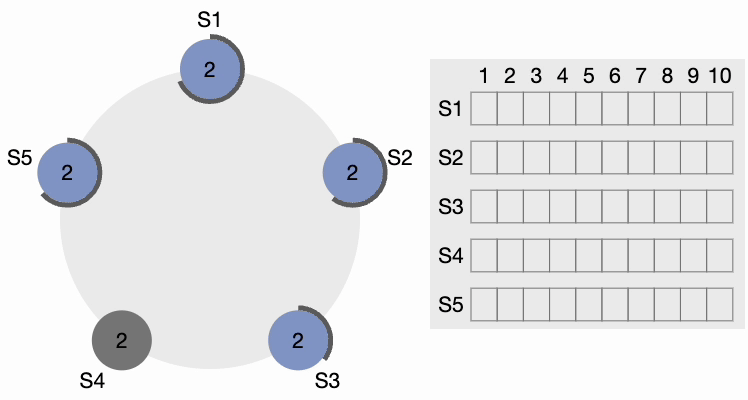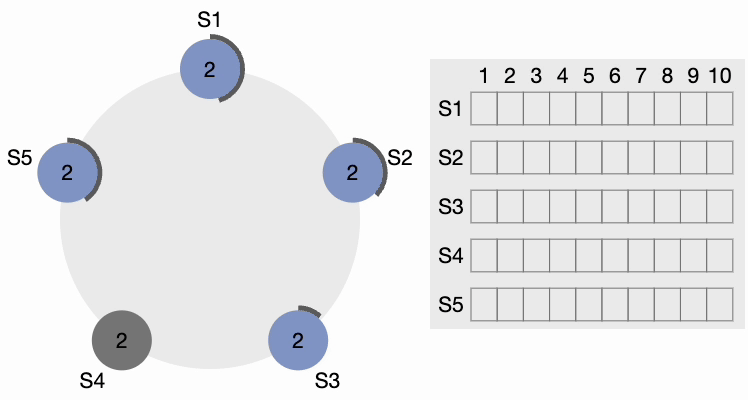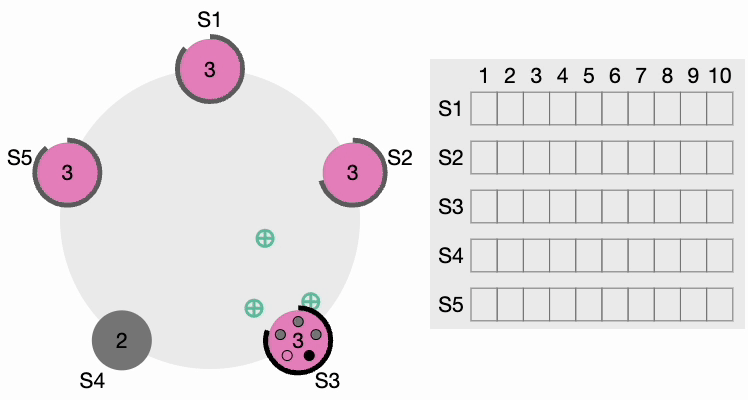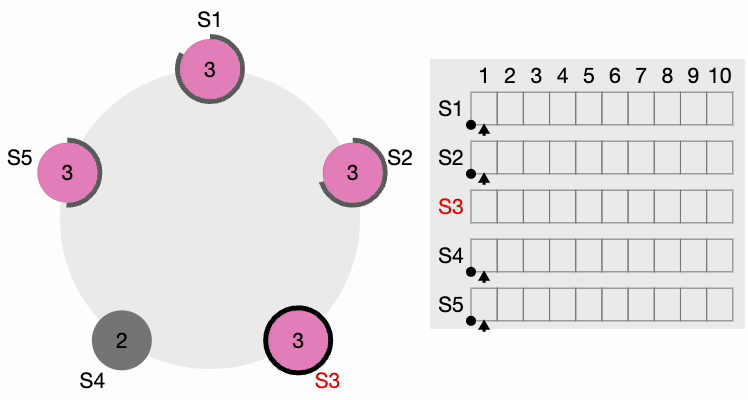
Tous les autres nœuds reçoivent la requête. Ils réinitialisent d’abord leur terme local à 2 puisque leur terme actuel est inférieur, puis accordent un vote pour la requête. S4 obtient une nette majorité et devient le leader. Le périmètre noir épais autour de S4 dans la figure suivante indique qu’il est devenu le leader du cluster :
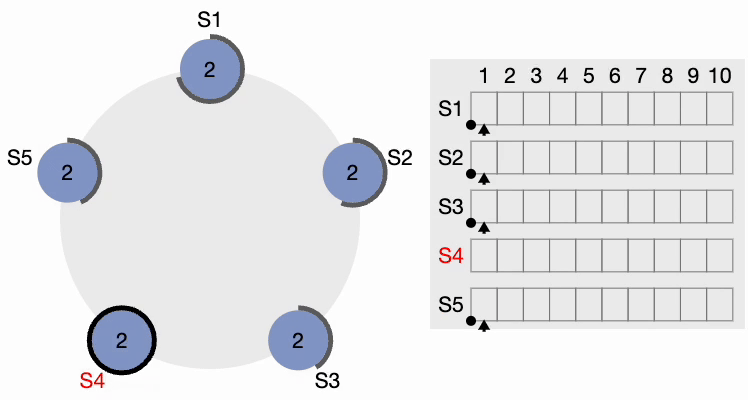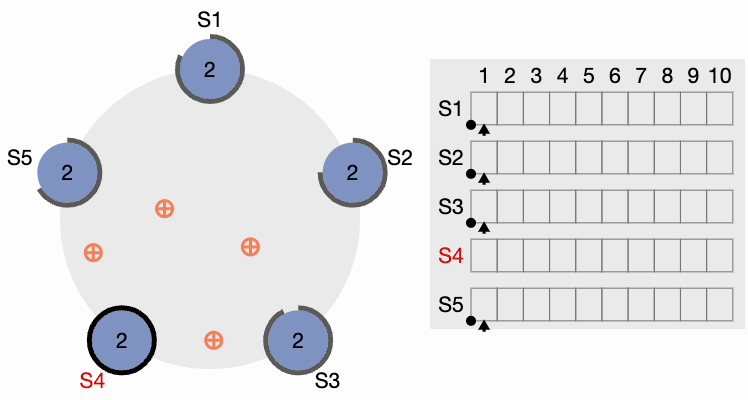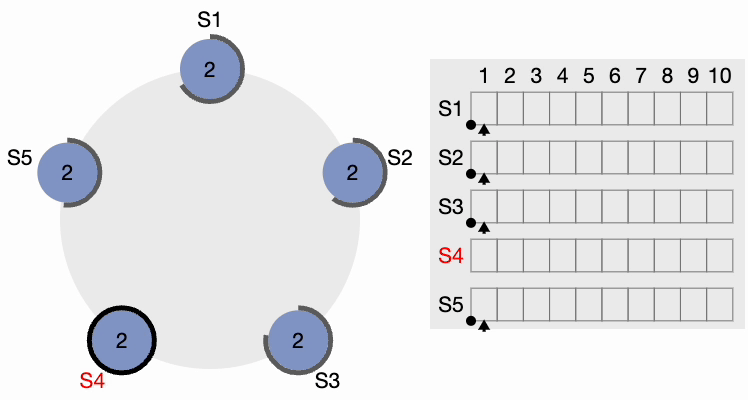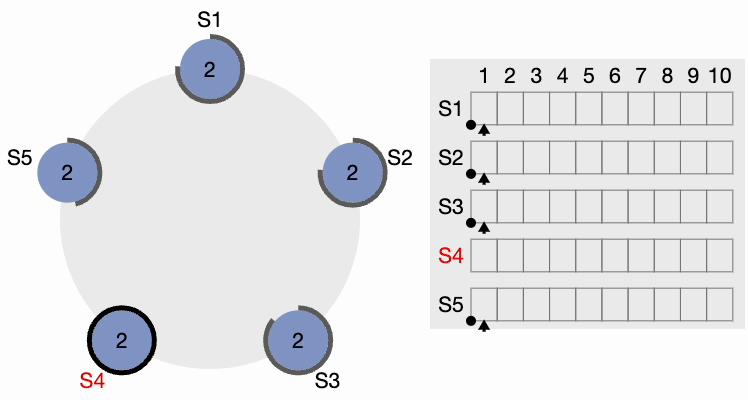
Étape 3 de l’élection du leader du cluster Raft
Maintenant, S4 envoie des messages AppendEntries (AE) à tous les autres nœuds. Les followers accusent réception de chaque message AppendEntries. Il existe également ce qu’on appelle le « délai de heartbeat », qui devrait être configurable dans le système. Le leader continue d’envoyer des messages AppendEntries vides aux intervalles spécifiés par l’intervalle de heartbeat, indiquant qu’il est toujours actif afin que le cluster n’initie pas inutilement un autre processus d’élection du leader.
Heartbeat du leader du cluster Raft
Si un candidat reçoit un message d’un leader nouvellement élu, il se rétrograde et devient un Follower. En cas de partition réseau, le leader actuel peut se retrouver déconnecté de la majorité du cluster, et la majorité sélectionne alors un nouveau leader.
Lorsque l’ancien leader revient, il découvre qu’un nouveau leader a déjà été élu avec un terme plus élevé, donc l’ancien leader se rétrograde et devient un Follower.
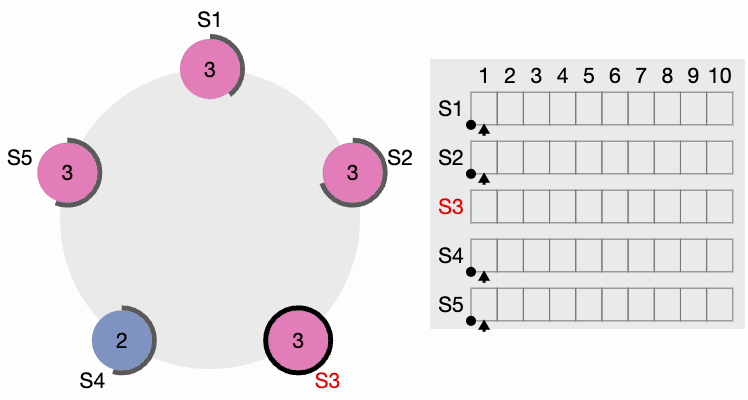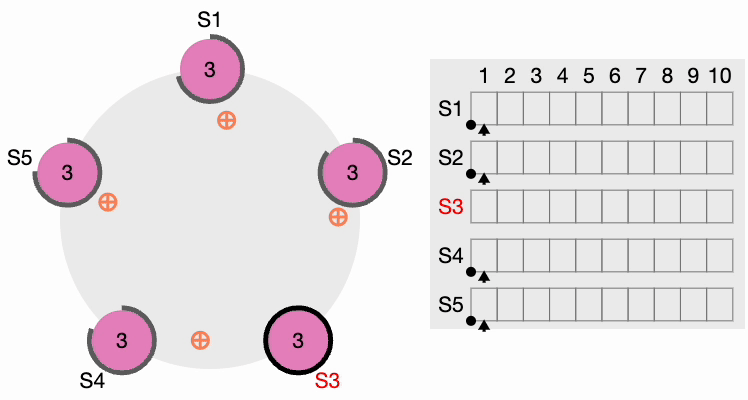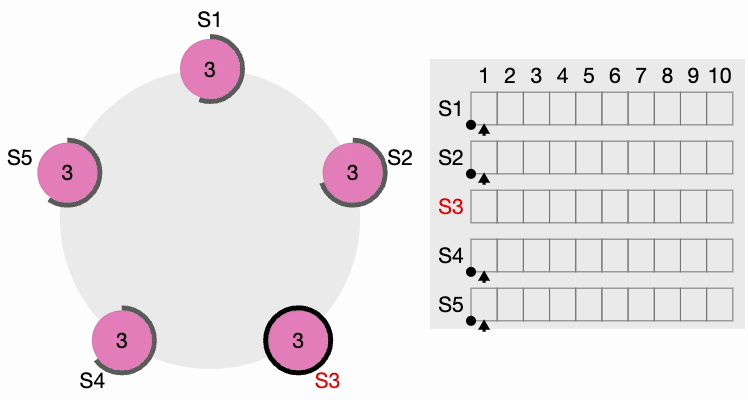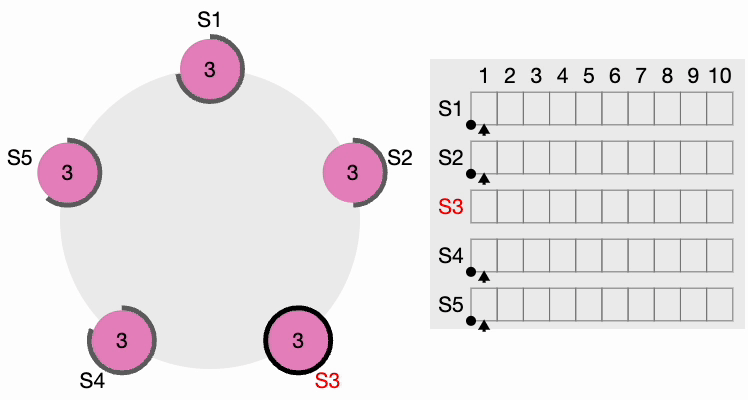
Basculement et récupération du leader Raft
Comme vous pouvez le voir, l’algorithme de consensus Raft, développé pour assurer la fiabilité dans les systèmes distribués, permet aux nœuds de s’accorder sur un seul état, même dans des scénarios de pannes. Raft fonctionne en élisant un leader parmi les nœuds, qui coordonne ensuite les journaux de transactions pour maintenir la cohérence du système. Ce processus de consensus implique des nœuds passant entre trois états (Follower, Candidate et Leader) pour garantir qu’un seul leader est actif à la fois.
Lors des transactions, un quorum, ou accord majoritaire entre les nœuds, est requis pour que les modifications soient validées. Raft garantit que toute entrée validée reste durable et reflète l’état système le plus récent, facilitant à la fois la cohérence des données et la tolérance aux pannes dans le cluster. CockroachDB étend Raft en un système MultiRaft, l’optimisant pour gérer de nombreuses transactions concurrentes dans une architecture hautement distribuée.
MultiRaft : Raft adapté à CockroachDB
Dans CockroachDB, les données sont divisées en ranges, chacun ayant son propre groupe de consensus, ce qui signifie que chaque nœud peut participer à des centaines de milliers de groupes de consensus ! Cela présente des défis uniques, que nous avons résolus en introduisant une couche au-dessus de Raft que nous appelons « MultiRaft ».
Avec un seul range, un nœud (parmi trois ou cinq) est élu leader, et il envoie périodiquement des messages heartbeat aux followers. À mesure que le système se développe pour inclure davantage de ranges, le volume de trafic nécessaire pour gérer les heartbeats augmente également.
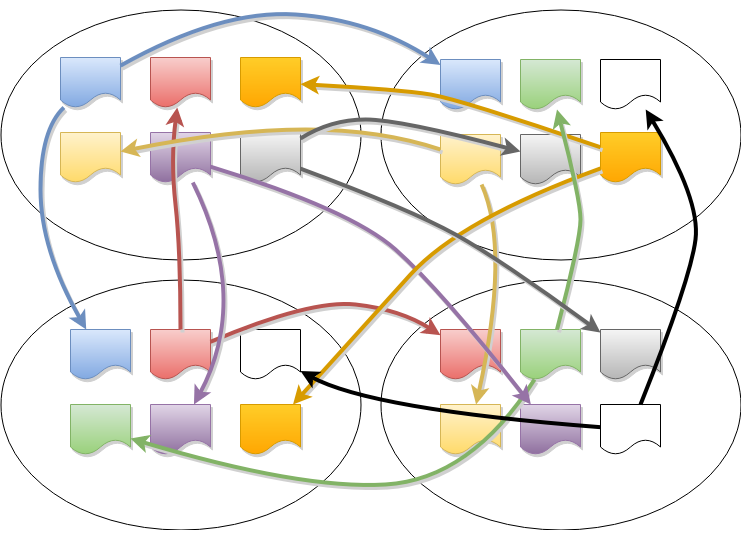
Heartbeats Raft par range
Le nombre de ranges dans une base de données distribuée est significativement plus grand que le nombre de nœuds. Cela contribue à améliorer les temps de récupération lorsqu’un nœud tombe en panne en maintenant les ranges de petite taille. Cependant, cela entraîne également un grand nombre de ranges aux membres qui se chevauchent.
Pour gérer cette situation efficacement, MultiRaft est utilisé. Au lieu d’exécuter Raft indépendamment pour chaque range, MultiRaft gère tous les ranges d’un nœud comme un groupe. Cela signifie que chaque paire de nœuds ne doit échanger des heartbeats qu’une seule fois par tick, quel que soit le nombre de ranges qu’ils partagent.
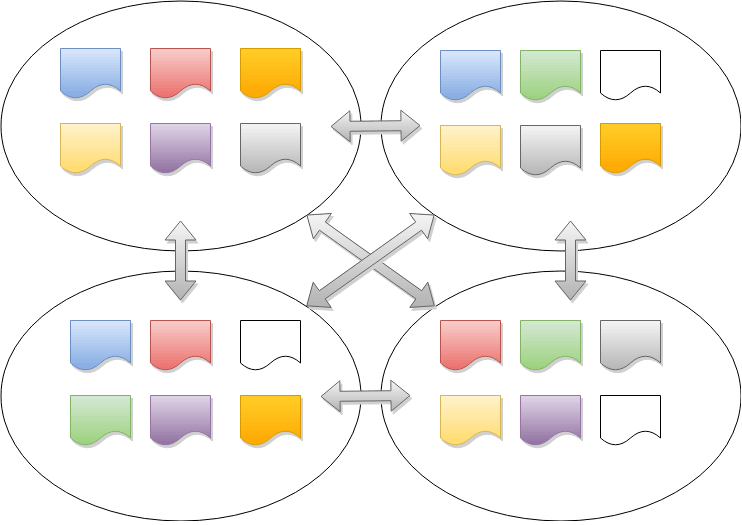
Heartbeats consolidés MultiRaft
Le cycle de vie d’une transaction distribuée
CockroachDB gère les transactions distribuées en coordonnant les données sur plusieurs nœuds pour assurer cohérence et fiabilité. Lorsqu’une transaction est initiée, elle suit un processus impliquant l’écriture d’intentions, le consensus via le protocole Raft, et des décisions de validation ou d’annulation.
Chaque transaction interagit avec le système distribué d’une manière qui garantit l’atomicité, la cohérence, l’isolation et la durabilité (ACID). Cette approche permet à CockroachDB de gérer efficacement des opérations complexes, même dans un environnement distribué, assurant l’intégrité des données et la tolérance aux pannes.
Tolérance aux pannes des transactions distribuées
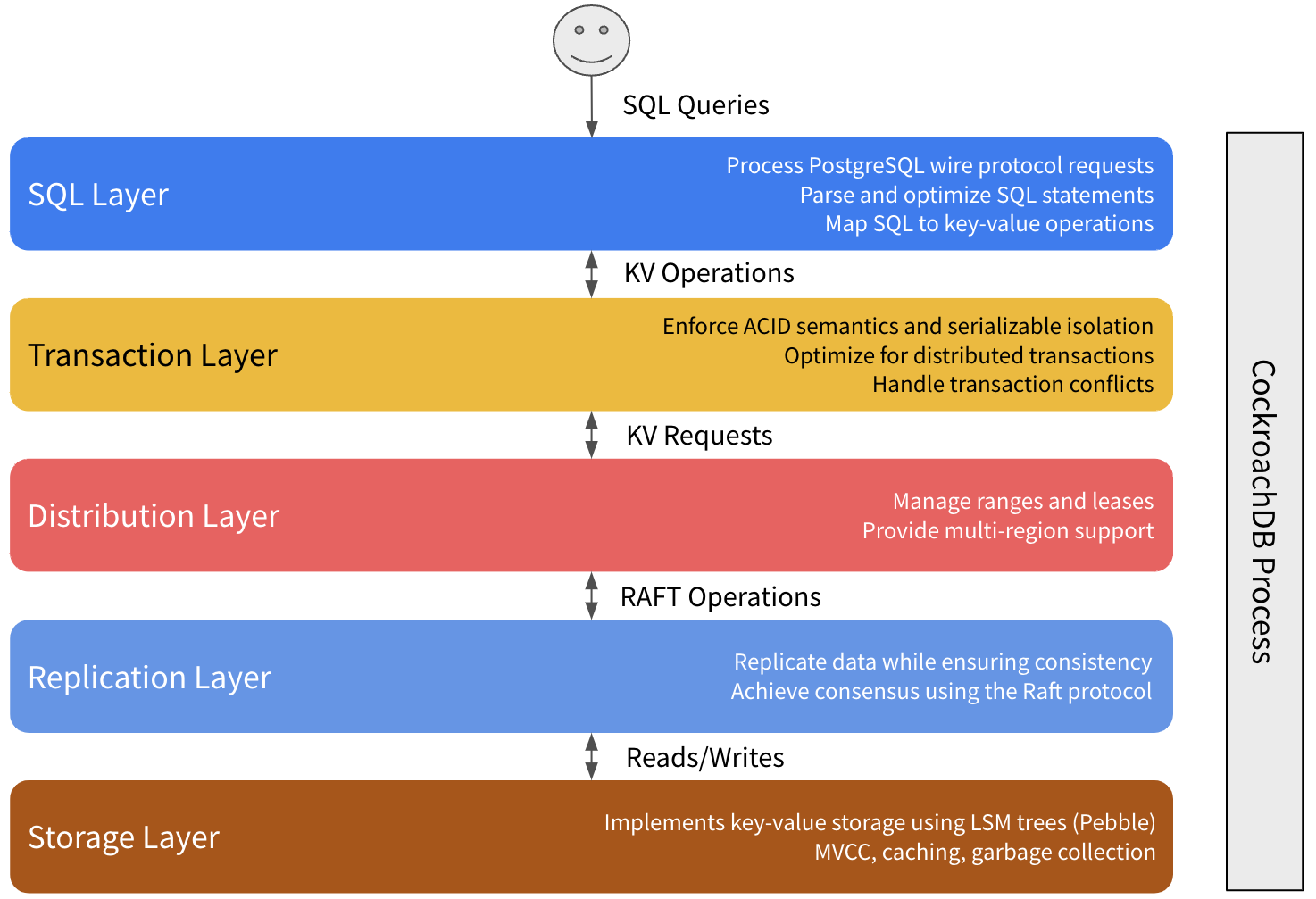
Pour démarrer la transaction, un client SQL (par exemple, une application) effectue une logique métier contre votre cluster CockroachDB, telle que l’insertion d’un nouvel enregistrement client. Cette requête est envoyée via une connexion à votre cluster CockroachDB établie à l’aide d’un driver PostgreSQL. Le nœud passerelle gère la connexion avec le client, recevant et répondant à la requête.
Comme nous l’avons expliqué précédemment, tous les nœuds CockroachDB ont un accès parfaitement symétrique aux données (Multi-Actif). Cela signifie que votre équilibreur de charge peut connecter votre client à n’importe quel nœud du cluster et accéder à toutes les données tout en garantissant une forte cohérence.
Le nœud passerelle analyse d’abord l’instruction SQL du client pour s’assurer qu’elle est valide selon le dialecte SQL de CockroachDB, et utilise ces informations pour générer un plan SQL logique. Étant donné que CockroachDB est une base de données distribuée, il est également important de tenir compte de la topologie d’un cluster, de sorte que le plan logique est ensuite converti en plan physique, ce qui signifie parfois pousser des opérations sur les machines physiques qui contiennent les données.
Bien que CockroachDB présente une interface SQL aux clients, la base de données réelle est construite au-dessus d’un stockage clé-valeur. Pour assurer cette médiation, le plan physique généré à la fin de l’analyse SQL est passé à l’exécuteur SQL, qui exécute le plan en effectuant des opérations clé-valeur via TxnCoordSender. Par exemple, l’exécuteur SQL convertit les instructions INSERT en opérations Put().
Le nœud passerelle reçoit des BatchRequests du TxnCoordSender. Il démantèle le BatchRequest initial en prenant chaque opération et en trouvant quelle machine physique doit recevoir la requête pour le range, connu comme le leaseholder du range. L’adresse du leaseholder actuel du range est facilement disponible à la fois dans les caches locaux et dans les méta-ranges du cluster.
Toutes les opérations d’écriture propagent également l’adresse du leaseholder au TxnCoordSender, afin qu’il puisse suivre et nettoyer les opérations d’écriture si nécessaire.
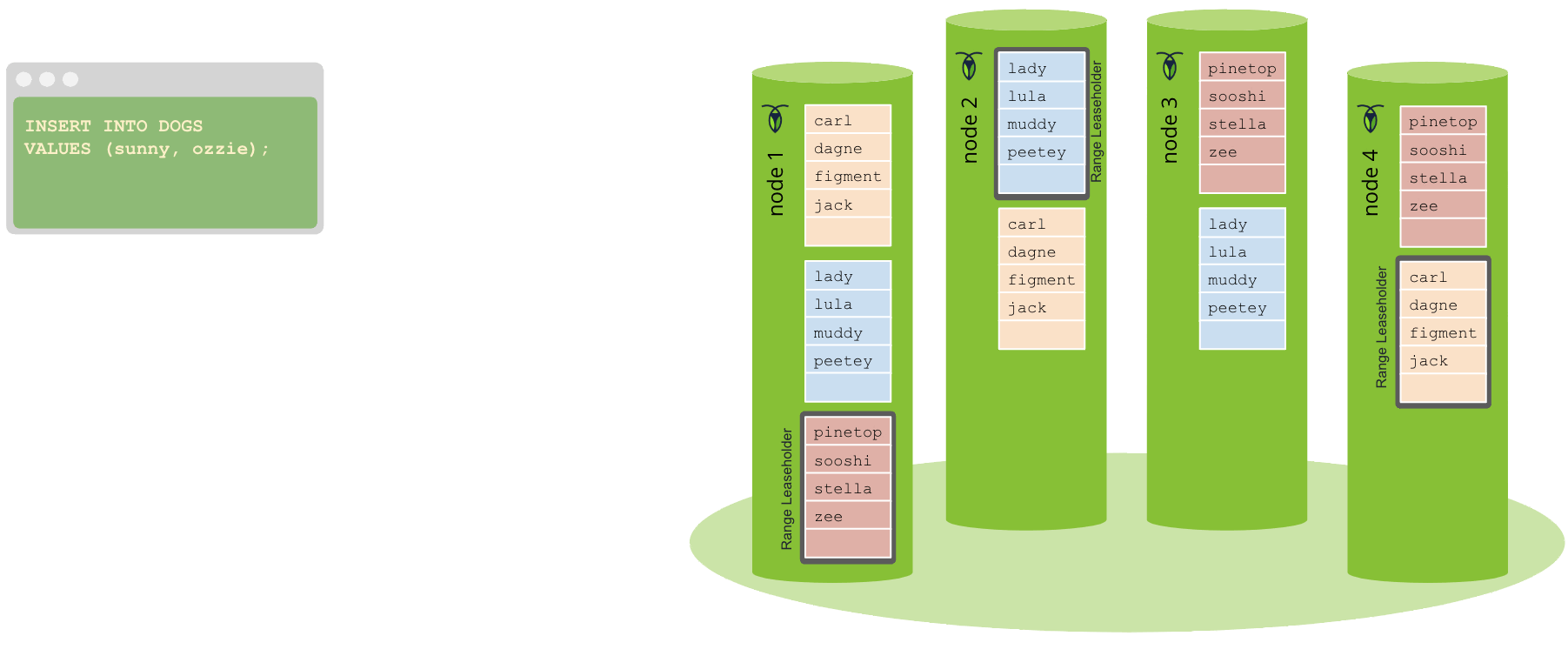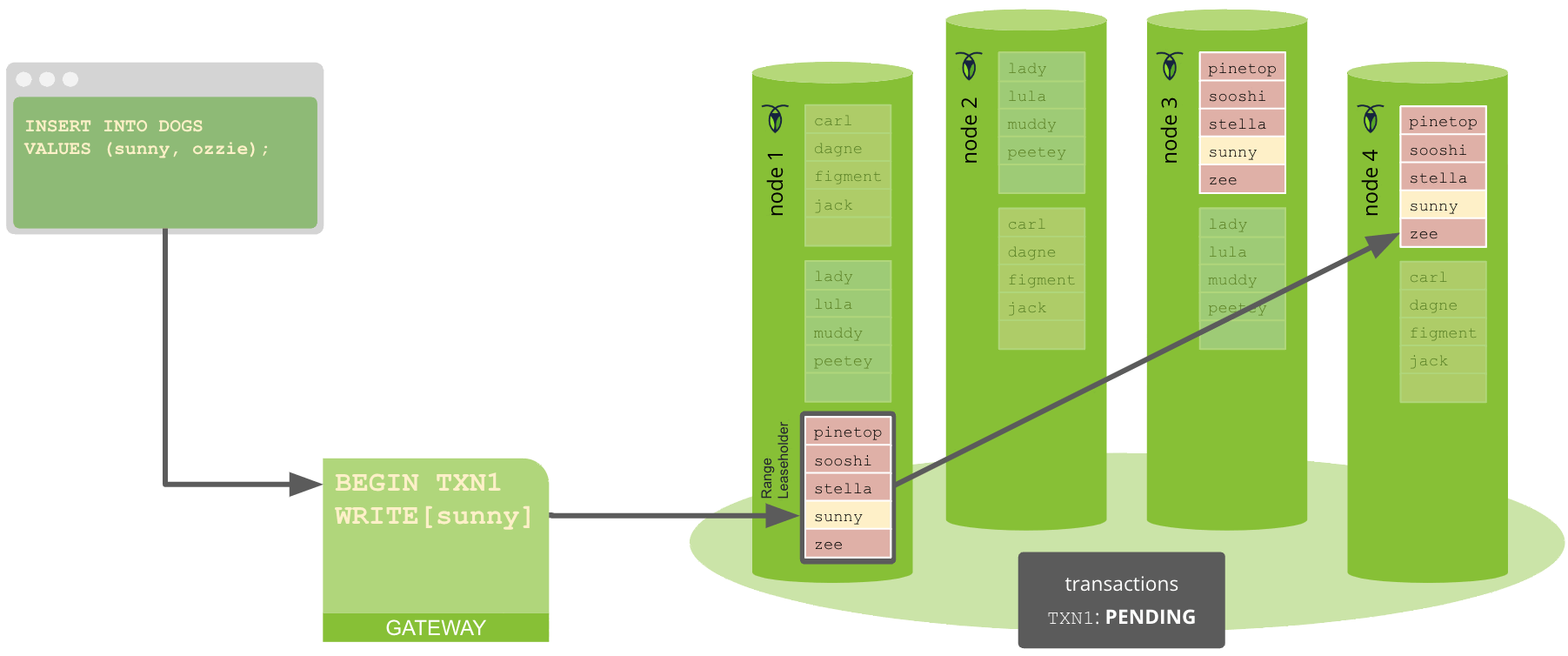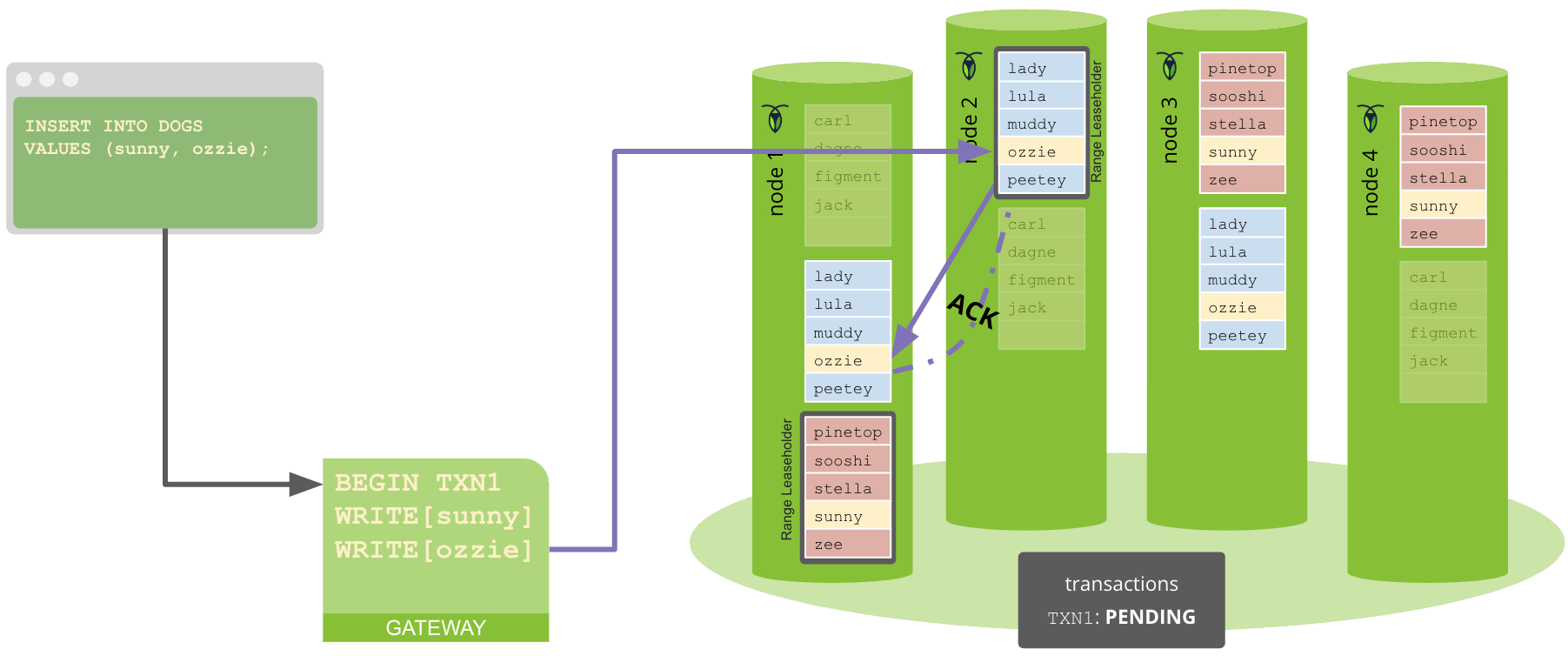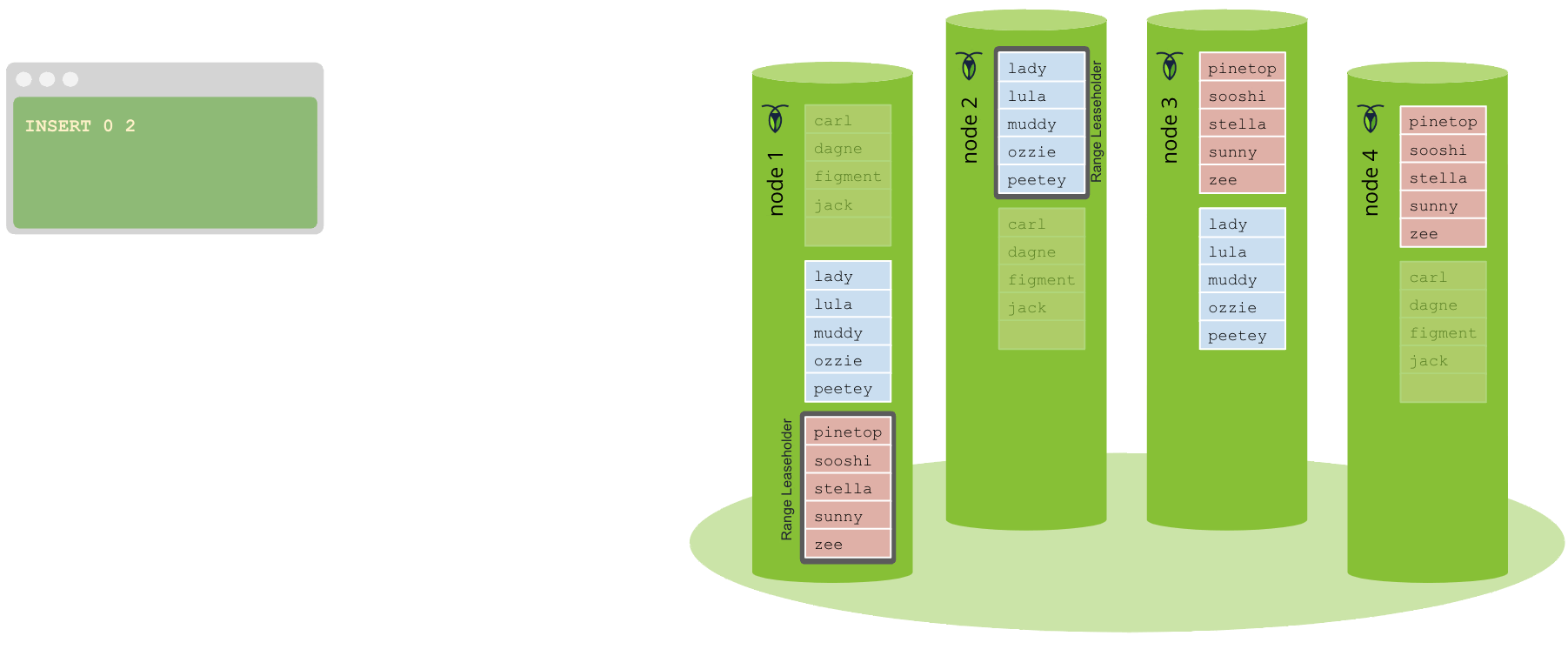
Le nœud passerelle envoie le premier BatchRequest pour chaque range en parallèle. Dès qu’il reçoit un accusé de réception provisoire (ACK) de l’évaluateur du nœud leaseholder, il envoie le prochain BatchRequest pour ce range.
Le nœud passerelle attend ensuite (état PENDING) de recevoir des accusés de réception pour toutes ses opérations d’écriture, ainsi que des valeurs pour toutes ses opérations de lecture. Cependant, cette attente n’est pas nécessairement bloquante, et le nœud passerelle peut encore effectuer des opérations avec des transactions en cours.
En termes d’exécution des transactions, le leader Raft reçoit les commandes Raft proposées du leaseholder. Chaque commande Raft est une écriture utilisée pour représenter un changement d’état atomique des paires clé-valeur sous-jacentes stockées dans le moteur de stockage.
Toutes les opérations (y compris les écritures) commencent par une lecture de l’instance locale du moteur de stockage pour vérifier les intentions d’écriture pour la clé de l’opération.
Pour les opérations d’écriture, et après avoir garanti l’absence d’intentions d’écriture existantes pour les clés, les opérations BatchRequest (opérations KV) sont converties en opérations Raft et leurs valeurs sont converties en intentions d’écriture.
Si une opération rencontre une intention d’écriture pour une clé, elle tente de résoudre l’intention d’écriture en vérifiant l’état de la transaction de l’intention d’écriture (COMMITTED, ABORTED, PENDING, MISSING).
Si la lecture ne rencontre pas d’intention d’écriture et que l’opération clé-valeur est destinée à servir une lecture, elle peut simplement utiliser la valeur lue depuis l’instance du leaseholder du moteur de stockage. Cela fonctionne car le leaseholder devait faire partie du groupe de consensus Raft pour que toute écriture soit complète, ce qui signifie qu’il doit avoir la version la plus récente des données du range. Le leaseholder agrège toutes les réponses de lecture dans un BatchResponse qui sera renvoyé au nœud passerelle.
Une fois que la commande atteint le consensus (c’est-à-dire qu’une majorité de nœuds, y compris lui-même, reconnaissent la commande Raft), elle est validée dans le journal Raft du leader Raft et écrite dans le moteur de stockage. En même temps, le leader Raft envoie également une commande à tous les autres nœuds pour inclure la commande dans leurs journaux Raft.
Une fois que le leader valide l’entrée du journal Raft, elle est considérée comme validée. L’interface SQL répond ensuite au client, et est maintenant prête à continuer à accepter de nouvelles connexions. À ce stade, la valeur est considérée comme écrite, et si une autre opération arrive et effectue une lecture depuis le moteur de stockage pour cette clé, elle rencontrera cette valeur.
Journal Raft validé et appliqué
Bases de données distribuées : scalabilité, disponibilité et performance inégalées
L’architecture de bases de données distribuées représente une avancée significative dans la gestion des données, particulièrement à l’ère du cloud computing. Ces systèmes offrent une scalabilité, une disponibilité et des performances inégalées en exploitant la puissance de plusieurs nœuds.
Les principes sous-jacents aux bases de données distribuées, tels que la distribution des données, la transparence, la fiabilité et la gestion décentralisée, leur permettent de répondre aux besoins dynamiques des applications modernes. Malgré la complexité opérationnelle et la courbe d’apprentissage, leurs avantages en matière de tolérance aux pannes et d’optimisation des ressources les rendent précieuses. Les organisations peuvent mettre en œuvre avec succès des bases de données distribuées pour améliorer leurs initiatives axées sur les données en comprenant ces principes et configurations.
Références
- D. Ongaro et J. Ousterhout, In Search of an Understandable Consensus Algorithm, Stanford University.
- Visualisation RAFT.
- C. Custer, What are distributed databases, and how do they work, Cockroach Labs Blog.
- Life of a distributed transaction, Cockroach Labs Docs.