
Aux débuts de l’informatique, la « cohérence » avait un foyer clair : la base de données. Si vos transactions étaient atomiques et vos index équilibrés, vous pouviez dormir tranquille en sachant que votre système était sain.
Mais le monde a changé. Les données ont échappé au monolithe, se répandant dans les microservices, les caches, les bus d’événements, les pipelines analytiques et les systèmes d’autorisation. Aujourd’hui, une action d’un utilisateur final peut se répercuter à travers une demi-douzaine de systèmes : une passerelle API, un fournisseur d’identité, un service d’autorisation et plusieurs bases de données répliquées, dans des régions différentes.
Quelque part dans cette chaîne, chaque système doit s’accorder non seulement sur ce qui s’est passé, mais aussi sur qui est autorisé à le savoir. C’est la nouvelle forme de cohérence : pas seulement la correction des données, mais la correction des permissions. Il s’agit de garantir que les informations et les permissions évoluent ensemble dans un monde distribué.
Chez Cockroach Labs, nous avons passé des années à aider les équipes à atteindre la cohérence des données à l’échelle mondiale. Mais de plus en plus, nous voyons les mêmes principes de systèmes distribués être appliqués aux permissions et à l’autorisation, et ce chevauchement n’est pas accidentel.
Cet article explique comment les défis d’autorisation modernes reflètent ceux des bases de données distribuées, et pourquoi les résoudre nécessite la même approche de la cohérence. Vous apprendrez comment CockroachDB et AuthZed travaillent ensemble pour synchroniser les données et les permissions à l’échelle mondiale, garantissant un contrôle d’accès fiable et sécurisé à travers les systèmes distribués.
Pourquoi l’autorisation est-elle un problème de systèmes distribués ?
Qu’est-ce que l’autorisation ? L’autorisation répond à la question : « Que peut faire un utilisateur une fois qu’il s’est connecté avec succès ? » Se connecter à un système ne signifie pas un accès illimité. Au lieu de cela, l’autorisation garantit que les utilisateurs n’accèdent qu’à ce qui est nécessaire pour leur rôle. Les modèles d’autorisation varient dans la façon dont ils déterminent ce qu’un utilisateur peut faire.
Le passage du contrôle d’accès au niveau de l’application à l’autorisation distribuée reflète l’évolution des bases de données du stockage sur un seul nœud vers le SQL distribué.
Les systèmes traditionnels de contrôle d’accès basé sur les rôles (RBAC) étaient autrefois intégrés directement dans la couche applicative. Vous vérifiez le rôle d’un utilisateur par rapport à une table locale et vous continuez. Ce modèle s’effondre à l’échelle mondiale, où :
- Les utilisateurs existent dans plusieurs régions de données.
- Les permissions dépendent de relations dynamiques entre entités.
- L’évaluation des permissions nécessite le contexte de plusieurs sources de données.
Heureusement, nous avons maintenant des alternatives qui résolvent l’autorisation à grande échelle. Les systèmes d’autorisation modernes, tels que ceux inspirés du document Google Zanzibar et implémentés par des projets comme AuthZed, distribuent les décisions d’autorisation à travers des clusters de machines.
AuthZed se concentre exclusivement sur l’autorisation et fournit des solutions gérées/cloud et open-source via SpiceDB. Cela permet aux entreprises d’implémenter une gestion des permissions sécurisée, cohérente et évolutive dans les applications cloud modernes sans construire leurs propres systèmes depuis zéro.
À son cœur, SpiceDB est derrière le modèle d’autorisation fourni par tous les produits d’AuthZed. Il est conçu pour être entièrement agnostique aux solutions d’authentification/fournisseurs d’identité. SpiceDB implémente un modèle de permissions basé sur les relations qui supporte la cohérence forte, la réplication mondiale et une très haute échelle, traitant des millions de requêtes d’autorisation par seconde pour les applications modernes et distribuées.
SpiceDB est un moteur de graphes qui stocke centralement les données d’autorisation (relations et permissions). Les requêtes d’autorisation (par exemple, checkPermission, lookupResources) sont résolues via un dispatcher qui parcourt le graphe de permissions.
Mais cette conception introduit les mêmes défis fondamentaux que ceux auxquels font face les bases de données distribuées :
- Comment garantir que chaque vérification de permission reflète une vue cohérente de l’état ?
- Comment gérer le décalage de réplication et l’invalidation du cache ?
- Comment raisonner sur l’exactitude en présence de mises à jour concurrentes ?
L’autorisation, en d’autres termes, est un problème de systèmes distribués. Ce n’est plus seulement une question de sécurité, c’est une question de coordination.
Comment CockroachDB permet-il des permissions cohérentes ?
Lorsque les architectes de données parlent de « cohérence », ils se réfèrent généralement au « C » dans ACID, s’assurant que chaque transaction fait passer la base de données d’un état valide à un autre.
Mais dans les systèmes distribués, ce concept se fragmente. Il existe maintenant plusieurs plans de cohérence :
- La Cohérence des Données : La vision du monde par la base de données.
- La Cohérence des Permissions : La compréhension par le système d’autorisation de qui peut accéder à quoi.
- La Cohérence Opérationnelle : La cohérence des flux d’événements, des caches et des tâches d’arrière-plan qui s’appuient sur ces données.
Ces plans doivent évoluer ensemble. Si vos données se mettent à jour avant que votre système d’autorisation ne voie le changement, vous risquez des permissions obsolètes. Si votre permission révoque l’accès avant que les données soient mises à jour, les utilisateurs peuvent connaître des refus ou des erreurs transitoires.
L’objectif n’est pas la simultanéité parfaite, cela est physiquement impossible dans les systèmes distribués, mais une cohérence prévisible : chaque composant observant une ligne temporelle cohérente d’événements. Tout comme les bases de données ont évolué pour gérer la cohérence distribuée, les systèmes d’autorisation subissent une transformation similaire, et c’est là que les garanties de CockroachDB ont de l’importance.
CockroachDB a été construit autour de ce principe : son modèle d’isolation sérialisable fournit la garantie de cohérence transactionnelle la plus forte en SQL, non pas « éventuelle », non pas « lecture validée », mais linéarisable à travers un cluster mondial. Cette même propriété est ce que les systèmes d’autorisation émergents poursuivent maintenant, mais pour les politiques plutôt que pour les données. C’est pourquoi SpiceDB utilise CockroachDB comme datastore sous-jacent. Avec cette conception, il obtient une base SQL globalement distribuée et fortement cohérente.
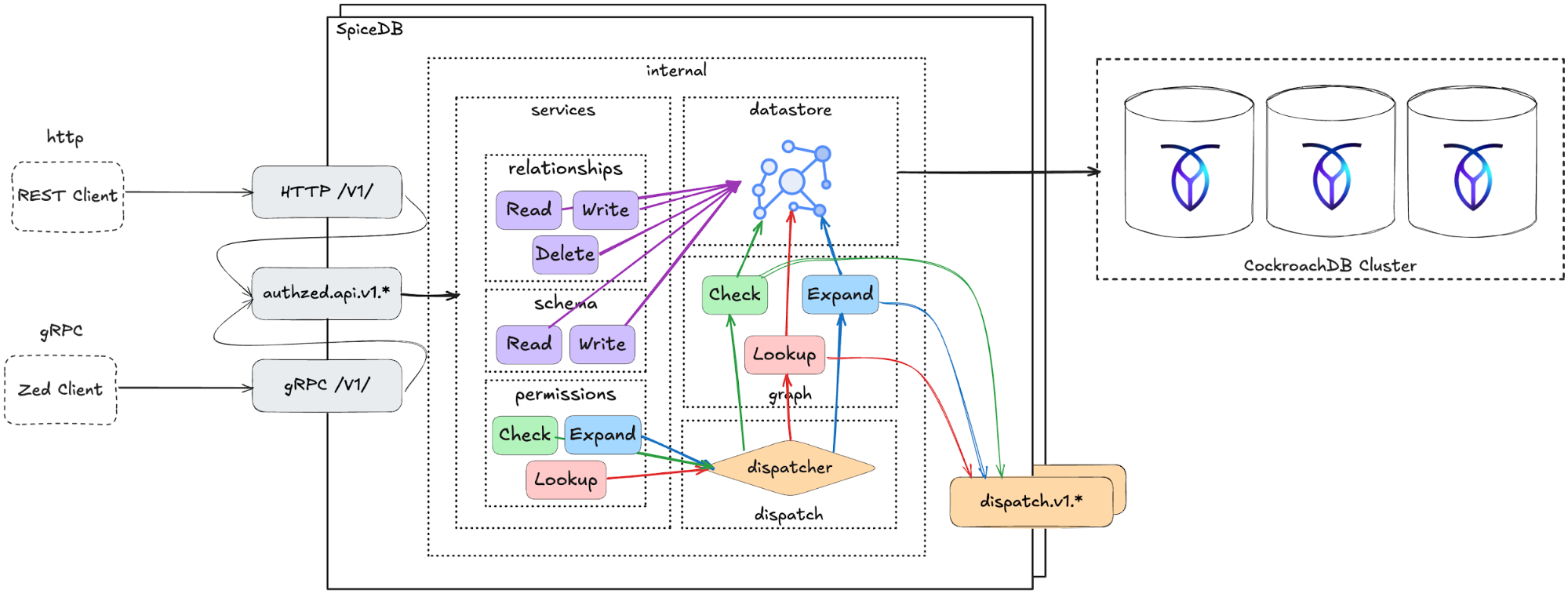
Internals de SpiceDB connectés à un cluster CockroachDB
La réplication multi-région et la haute disponibilité de CockroachDB garantissent que les décisions d’autorisation sont cohérentes, à faible latence et résilientes à travers les géographies. Ensemble, cette architecture combine le modèle d’autorisation flexible et orienté API de SpiceDB avec la plateforme de base de données tolérante aux pannes de CockroachDB pour offrir un contrôle d’accès sécurisé, à grain fin et fortement cohérent qui s’adapte aux charges de travail d’entreprise dans le monde entier.
Les Parallèles entre les Bases de Données et les Systèmes d’Autorisation
Les architectes conçoivent souvent les bases de données distribuées et les systèmes d’autorisation séparément. Mais quand vous alignez leurs défis, la ressemblance est frappante.
Les deux domaines nécessitent :
- Des garanties d’ordonnancement (ce qui s’est passé en premier)
- L’idempotence (nouvelles tentatives sûres)
- La cohérence sous concurrence (pas d’états conflictuels)
- L’observabilité (savoir ce que le système croit à tout moment)
Ce chevauchement conceptuel crée une opportunité de conception : si votre base de données garantit déjà une cohérence mondiale et fournit un historique des changements fiable, elle peut agir comme « l’ancre de vérité » pour les systèmes de niveau supérieur comme les systèmes d’autorisation et de contrôle d’accès.
Exemple Pratique : Comment utiliser CockroachDB et AuthZed ensemble ?
Décomposons cela en pratique. Nous allons montrer comment CockroachDB peut servir de source de vérité pour la cohérence des données et des politiques en modélisant une application mondiale de gestion de projets avec des vérifications d’autorisation alimentées par AuthZed.
Imaginons que nous construisons une application mondiale de gestion de contenu qui utilise SpiceDB, comme système de contrôle d’accès soutenu par CockroachDB sur plusieurs régions.
0. Prérequis
Pour exécuter ce scénario avec succès, vous aurez besoin :
- d’un cluster CockroachDB sécurisé et accessible (auto-hébergé ou Cloud), d’une version CRDB actuelle supportée, et d’un accès réseau depuis votre runtime SpiceDB vers le port 26257.
- Créez une base de données dédiée
spicedbet un utilisateur pour SpiceDB, en accordant suffisamment de privilèges pour exécuter ses migrations et fonctionner normalement.
Du côté SpiceDB, vous devez installer le binaire/conteneur ou utiliser l’Opérateur Kubernetes, puis exécuter la commande suivante :
spicedb datastore migrate head --datastore-engine=cockroachdb --datastore-conn-uri="postgres://root@CRDB_URI:26257/spicedb?sslmode=disable"
puis, démarrez le service SpiceDB en pointant vers votre URI CockroachDB :
spicedb serve --grpc-preshared-key="<preshared_key>" --http-enabled=true --datastore-engine=cockroachdb --datastore-conn-uri="postgres://root@CRDB_URI:26257/spicedb?sslmode=disable"
Pour interagir avec SpiceDB via la CLI zed (AuthZed), vous devez installer les dernières versions binaires de zed en utilisant le tap officiel :
brew install authzed/tap/zed
Une fois installé, vous pouvez vous connecter à SpiceDB exposé dans le client avec la commande ci-dessous. Pour le développement local, nous pouvons utiliser le drapeau --insecure pour nous connecter via du texte en clair. Assurez-vous d’utiliser la même preshared_key que celle utilisée dans la commande spicedb serve.
zed context set my_context <SpiceDB_IP>:50051 <preshared_key> --insecure
Vous pouvez vérifier que la commande ci-dessus a fonctionné en exécutant :
zed version
Si la sortie de zed version indique la version du serveur comme « unknown », votre CLI n’a pas pu se connecter, vous devrez peut-être revérifier certaines valeurs dans les étapes précédentes telles que la preshared_key, l’IP ou le port sur lequel votre instance SpiceDB s’exécute.
1. Définir le schéma
L’écriture d’une ou plusieurs définitions de types d’objets est la première étape dans le développement d’un schéma de relation d’autorisation.
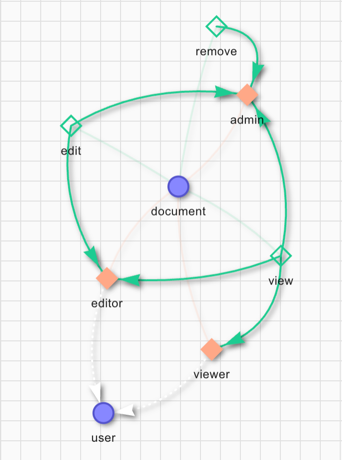
Schéma de relation d’autorisation
Dans l’exemple ci-dessus, nous définissons les concepts user et document. L’utilisateur peut être un viewer, un editor ou un admin. La définition donne la permission remove uniquement au rôle admin. Pour edit un fichier, l’utilisateur doit être soit un editor, soit un admin. La permission de view un document est définie pour les rôles viewer, editor et admin. La syntaxe de la définition du schéma est la suivante :
definition user {}
definition document {
relation editor: user
relation viewer: user
relation admin: user
permission view = viewer + editor + admin
permission edit = editor + admin
permission remove = admin
}
Une fois le schéma, qui définit les ressources et les permissions nécessaires, créé, il peut être sauvegardé dans SpiceDB en utilisant soit la CLI zed soit ses APIs (REST et gRPC). Bien que l’API REST soit moins performante et non testée à grande échelle, faisant de gRPC le choix préféré, nous utiliserons l’API REST à des fins de démonstration pour mettre en évidence ses fonctionnalités.
Tout d’abord, sauvegardons le schéma créé précédemment comme schema.zed et exécutons la commande suivante :
zed schema write ./schema.zed
Si cela fonctionne, nous devrions voir notre schéma d’autorisation imprimé lors de l’exécution de la commande suivante :
zed schema read
Il existe une autre façon moins recommandée de stocker le schéma dans SpiceDB, en utilisant l’API REST. Dans ce cas, la définition du schéma est intégrée dans le corps de la requête :
curl --location 'http://<SpiceDB_IP>:8443/v1/schema/write' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer <preshared_key>' \
--data '{
"schema": "definition user {} \n definition document { \n relation editor: user \n relation viewer: user \n relation admin: user \n permission view = viewer + editor + admin \n permission edit = editor + admin \n permission remove = admin \n}"
}'
# output:
# {"writtenAt":{"token":"GhUKEzE3NTgxMjkyOTM0MDE2MDYxNDA="}}
2. Créer des relations
Dans SpiceDB, les relations sont représentées sous forme de tuples de relation. Chaque tuple contient une ressource, une relation et un sujet. Dans notre cas, la ressource est le nom d’un document, la relation est soit admin, viewer ou editor, et le sujet est le nom d’un utilisateur.
Simulons un nouveau flux de création de contenu : un utilisateur amine crée un nouveau document appelé (doc1) et en devient l’admin, ce qui signifie qu’il peut tout faire avec doc1 (voir, modifier et supprimer). Supposons un utilisateur supplémentaire jake avec le rôle viewer pour le document (doc1).
zed relationship touch document:doc1 admin user:amine
zed relationship touch document:doc1 viewer user:jake
Maintenant jake peut seulement voir le document doc1. Nous pouvons créer un autre utilisateur de test evan et l’ajouter comme editor du document doc1 en utilisant l’API REST.
curl --location 'http://<SpiceDB_IP>:8443/v1/relationships/write' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer <preshared_key>' \
--data '{
"updates": [
{
"operation": "OPERATION_TOUCH",
"relationship": {
"resource": {
"objectType": "document",
"objectId": "doc1"
},
"relation": "editor",
"subject": {
"object": {
"objectType": "user",
"objectId": "evan"
}
}
}
}
]
}'
# output :
# {"writtenAt":{"token":"GhUKEzE3NTgxMjk3MDg2NTc4MDQ5ODk="}}
3. Vérifier les permissions
Pour vérifier que notre schéma fonctionne correctement, nous pouvons émettre quelques requêtes de vérification. Comme jake n’est qu’un viewer pour doc1, nous nous attendons à ce qu’il ait la permission de vue mais pas les permissions edit ou remove.
zed permission check document:doc1 view user:jake
# output: true
zed permission check document:doc1 edit user:jake
# output: false
Maintenant, vérifions que jake n’a pas la permission remove sur le document doc1, cette fois en utilisant l’API REST :
curl --location 'http://<client IP>:8443/v1/permissions/check' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer <preshared_key>' \
--data '{
"consistency": {
"minimizeLatency": true
},
"resource": {
"objectType": "document",
"objectId": "doc1"
},
"permission": "remove",
"subject": {
"object": {
"objectType": "user",
"objectId": "jake"
}
}
}'
# output :
# {"checkedAt":{"token":"GhUKEzE3NTgxMjk5NTAwMDAwMDAwMDA="}, "permissionship":"PERMISSIONSHIP_NO_PERMISSION"}
À l’inverse, comme amine est un admin, nous nous attendons à ce qu’il ait toutes les permissions.
zed permission check document:doc1 view user:amine
# output: true
zed permission check document:doc1 remove user:amine
# output: true
zed permission check document:doc1 edit user:amine
# output: true
Du schéma à la cohérence mondiale
Une fois votre schéma d’autorisation défini et appliqué, chaque changement de relation et de permission devient une transaction soutenue par le modèle d’isolation sérialisable de CockroachDB. Cela garantit que la compréhension de votre application sur « qui peut faire quoi » ne dérive jamais hors de synchronisation, indépendamment de la géographie ou de l’échelle. Que l’utilisateur soit à New York, Sydney ou Francfort, la même vérification renverra toujours le même résultat, ancré au même état cohérent.
Par exemple, quand un viewer est promu editor, ce changement est immédiatement reflété dans toutes les régions, de manière atomique et sans décalage de réplication. Quand l’accès est révoqué, aucun cache ni réplique ne continue à servir des permissions obsolètes (sauf lors de l’utilisation de minimize_latency, les permissions peuvent être en retard de cinq secondes au maximum). Ce couplage étroit entre les données d’autorisation et les garanties transactionnelles de CockroachDB élimine les conditions de concurrence et les décalages temporels qui surviennent souvent dans les systèmes distribués, garantissant que vos permissions sont toujours aussi à jour que vos données.
La cohérence ne s’arrête pas à l’exactitude : elle s’étend à la visibilité. Dans les environnements distribués complexes, comprendre pourquoi une décision d’autorisation particulière a été prise est tout aussi critique que de la prendre correctement. Pour éviter le problème de double écriture et tous les défis qui en découlent, les changefeeds de CockroachDB peuvent diffuser chaque mutation de politique (c’est-à-dire, les attributions de permissions, les révocations et les mises à jour de rôles) dans des systèmes d’événements comme Kafka ou Pub/Sub.
Associé aux journaux d’audit d’AuthZed, cela crée une couche d’observabilité complète pour votre graphe d’autorisation. Les développeurs et les équipes de conformité peuvent surveiller les changements de données d’autorisation en temps réel, rejouer les événements historiques pour les audits et réconcilier automatiquement les états d’autorisation attendus et réels. Avec cette architecture, l’autorisation devient un composant mesurable et testable de votre infrastructure, et non plus une boîte noire enfouie dans le code applicatif.
Où CockroachDB et AuthZed gagnent-ils ensemble ?
Comprendre comment AuthZed structure ses offres aide à clarifier où CockroachDB s’inscrit dans le paysage plus large de l’autorisation. AuthZed se concentre exclusivement sur l’infrastructure d’autorisation (pas l’authentification ou la gestion des identités) et offre ses solutions via SpiceDB, une base de données de permissions basée sur les relations et à haute performance, inspirée du Zanzibar de Google.
SpiceDB est le moteur central derrière tous les produits AuthZed, disponible sous plusieurs formes selon les besoins de déploiement et de support :
- SpiceDB (Open Source) : La version communautaire fondamentale du moteur d’autorisation, gratuite à utiliser et auto-hébergée sous la licence Apache 2.0.
- SpiceDB Enterprise : Une édition entreprise auto-gérée qui inclut la journalisation des audits, le contrôle d’API à grain fin, la cryptographie validée FIPS et un support dédié.
- AuthZed Dedicated : Une offre SaaS entièrement gérée et à locataire unique qui fournit toutes les fonctionnalités entreprise ainsi que des déploiements mondiaux distribués régionalement et des APIs intégrées pour le filtrage des permissions.
- AuthZed Cloud : Une plateforme gérée multi-locataires conçue pour les équipes qui souhaitent démarrer rapidement sans surcharge opérationnelle.
À tous ces niveaux, CockroachDB joue un rôle critique en tant que datastore sous-jacent. Dans un monde où la disponibilité de l’autorisation et la résilience ne sont pas négociables, une seule mise à jour de permission manquée peut se traduire par des erreurs de sécurité ou d’accès.
L’architecture multi-active de CockroachDB permet à ces déploiements de survivre aux pannes de nœuds, de zones de disponibilité ou même de régions avec zéro temps d’arrêt. Plus important encore, elle permet une évolutivité horizontale des écritures, permettant à AuthZed de supporter des charges de travail réelles atteignant des dizaines de milliers d’écritures par seconde.
La synergie est claire : CockroachDB fournit la base de cohérence mondiale et de résilience, tandis qu’AuthZed offre la couche d’autorisation spécialisée par-dessus. Ensemble, ils alimentent les systèmes distribués où l’intégrité des données et l’exactitude des politiques évoluent main dans la main.
Réunir l’autorisation et les systèmes distribués
Les défis des systèmes distribués ont toujours tourné autour du maintien des données en synchronisation à travers l’espace et le temps. Mais à mesure que les architectures de données deviennent plus composables et interconnectées, les mêmes principes doivent maintenant s’étendre au-delà de la base de données, aux règles mêmes qui régissent l’accès, la vie privée et la sécurité.
Garantir l’exactitude des politiques parallèlement à l’exactitude des données n’est pas seulement une préoccupation de sécurité ; c’est un défi de cohérence. Les systèmes qui ne font pas évoluer les deux attributs ensemble risquent des expériences utilisateurs incohérentes, des problèmes de conformité et une fragilité opérationnelle.
Les entreprises qui associent la couche de données globalement cohérente et tolérante aux pannes de CockroachDB au modèle d’autorisation distribué d’AuthZed obtiennent un avantage commercial distinct : elles peuvent concevoir des systèmes où les politiques et les données évoluent de manière fiable, prévisible et à l’échelle planétaire.