
Les applications d’IA modernes ne sont plus de simples appels d’inférence ; ce sont des agents de longue durée qui planifient, agissent, observent et réessaient au fil du temps. Une boucle d’agent IA qui récupère du contexte depuis un vector store, appelle un LLM, écrit des résultats en base de données, attend une validation humaine, puis déclenche des actions en aval peut s’exécuter pendant des minutes, des heures, voire des jours. Sans une couche d’orchestration durable, toute défaillance d’infrastructure transitoire relance l’intégralité de la boucle depuis le début : refacturant des appels LLM coûteux, dupliquant les effets de bord et perdant tout le contexte accumulé.
Des plateformes comme Temporal résolvent ce problème en déployant un cluster d’orchestration dédié (un processus serveur séparé avec son propre backend de persistance) auquel vos workers applicatifs se connectent via gRPC. C’est puissant, mais cela implique un service supplémentaire à provisionner, surveiller, mettre à l’échelle et maintenir disponible avant même de pouvoir exécuter le premier workflow.
DBOS adopte une approche fondamentalement différente : il intègre l’exécution durable directement dans votre application sous forme de bibliothèque Python ou TypeScript, en utilisant la base de données que vous avez déjà. Il n’y a pas de serveur d’orchestration, pas de file de tâches, pas de processus sidecar. Votre application écrit l’état des workflows dans des tables de sa propre base de données comme effet de bord naturel de l’exécution, et reprend depuis ces tables au redémarrage. Associez DBOS à CockroachDB et vous obtenez une plateforme d’exécution distribuée globalement et auto-réparante, sans infrastructure supplémentaire à gérer.
Un workflow durable est une fonction dont l’état d’exécution, à savoir quelles étapes ont été complétées, ce qu’elles ont retourné et quelles entrées ont été fournies, est persisté en base après chaque étape. Si le processus crashe en cours d’exécution, il redémarre et reprend depuis la dernière étape validée : aucun travail n’est perdu, aucune étape n’est ré-exécutée, aucun effet de bord externe n’est dupliqué.
Qu’est-ce que DBOS ?
DBOS est une bibliothèque Python et TypeScript qui décore des fonctions ordinaires avec des garanties d’exécution durable. Il n’y a pas de serveur à déployer, pas de file de tâches à opérer, pas de cluster de persistance séparé à gérer. DBOS écrit l’état des workflows dans des tables de votre base applicative comme effet secondaire de l’exécution normale, et récupère depuis ces tables au redémarrage.
Concepts clés
| Concept | Définition |
|---|---|
@DBOS.workflow() |
Décorateur rendant une fonction Python durable. L’état est persisté avant chaque étape. |
@DBOS.step() |
Unité de travail dans un workflow ; s’exécute au moins une fois mais jamais après complétion |
| Workflow ID | La clé d’idempotence ; lancer deux fois le même ID de workflow est sans danger |
DBOS.set_event() |
Publie une valeur nommée depuis l’intérieur d’un workflow pour les consommateurs externes |
DBOS.get_event() |
Interroge un workflow pour une valeur d’événement nommée avec timeout optionnel |
| Base système | La base compatible PostgreSQL où DBOS stocke l’état des workflows, les completions d’étapes et les événements |
Architecture
DBOS est implémenté entièrement comme une bibliothèque open-source embarquée dans votre application : il n’y a pas de serveur d’orchestration et pas de dépendances externes excepté une base compatible PostgreSQL. Pendant l’exécution, DBOS crée des checkpoints de l’état des workflows et des étapes dans cette base. En cas de défaillance, il utilise ces checkpoints pour reprendre chaque workflow depuis la dernière étape complétée.
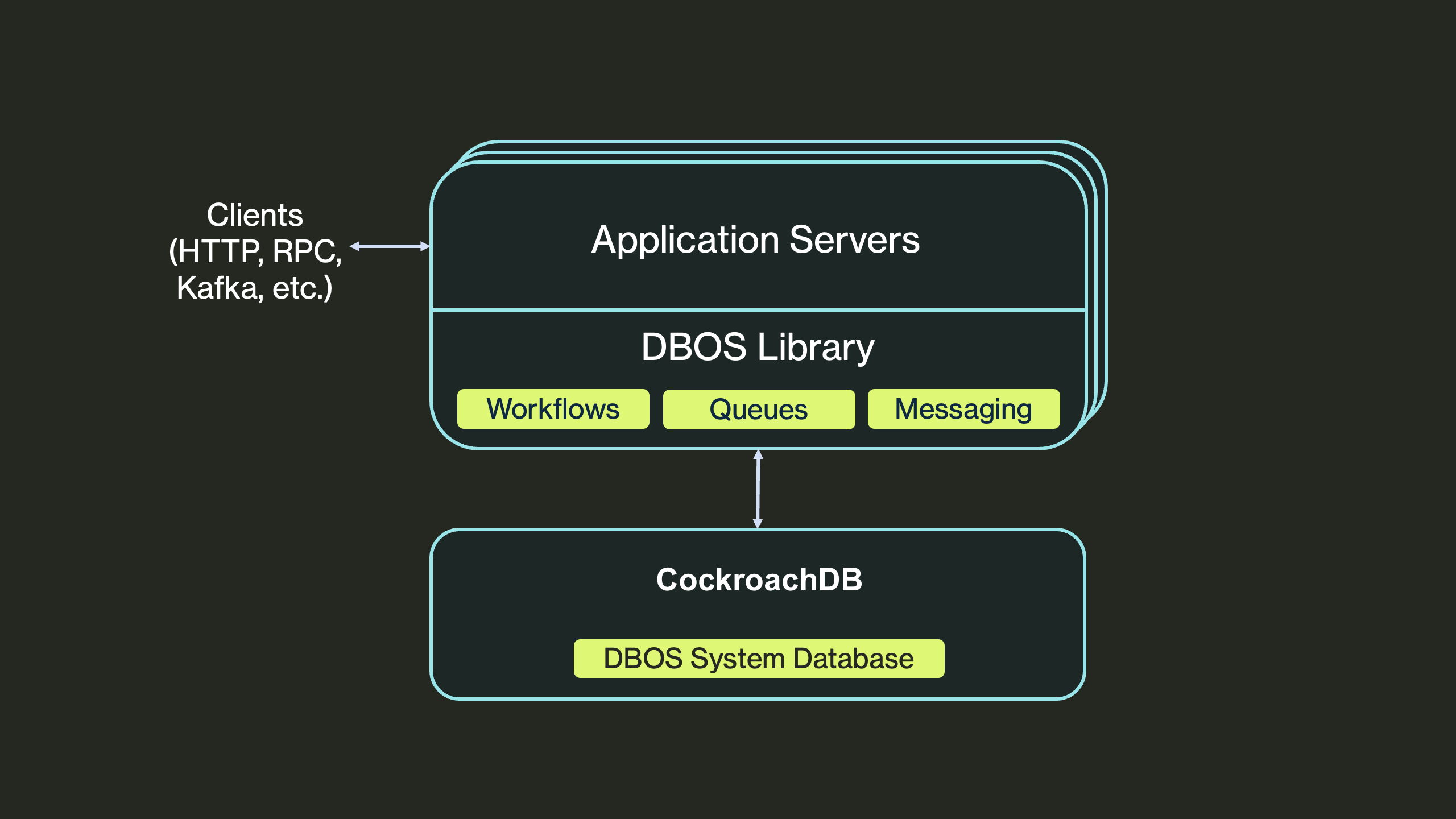
Architecture DBOS : la bibliothèque d’exécution durable vit dans votre processus applicatif ; la seule dépendance externe est une base compatible Postgres
Modèle de checkpointing
Chaque exécution de workflow produit un nombre fixe d’écritures en base quelle que soit sa complexité :
- Une écriture au démarrage du workflow : les entrées sont persistées avant l’exécution de toute étape
- Une écriture par étape complétée : la valeur de retour de l’étape est stockée pour que la reprise puisse la sauter
- Une écriture à la fin du workflow : le statut final est validé
La taille des écritures est proportionnelle à vos entrées et sorties. Pour les charges importantes (fichiers, embeddings), la pratique recommandée est de les stocker en externe (ex. S3) et de n’avoir les étapes retourner que des pointeurs.
Déploiement distribué
DBOS passe naturellement à l’échelle d’une flotte de serveurs. Tous les serveurs applicatifs se connectent à la même base système, le seul point de coordination. Par défaut, chaque workflow s’exécute sur un seul serveur ; les files durables distribuent le travail sur la flotte avec des limites configurables de débit et de concurrence.
Pour les setups multi-applications (ex. un serveur API, un service d’ingestion de données, et une boucle d’agent IA), chaque application se connecte à sa propre base système isolée. Un seul hôte de base de données peut servir plusieurs bases système. Le DBOS Client permet au code externe d’enqueuer des jobs et de surveiller les résultats entre applications.
Récupération des workflows
Quand un processus crashe, DBOS détecte les workflows incomplets et les rejoue en trois étapes :
- Détection : au démarrage, DBOS scanne les workflows en attente. Dans les déploiements distribués, Conductor coordonne la détection sur toute la flotte.
- Redémarrage : chaque workflow interrompu est rappelé avec ses entrées originales checkpointées.
- Reprise : lors de la ré-exécution, toute étape dont la sortie est déjà checkpointée est ignorée instantanément. L’exécution reprend depuis la première étape sans checkpoint.
Deux conditions requises pour une récupération sûre :
- Déterminisme : la fonction de workflow doit produire les mêmes étapes dans le même ordre pour les mêmes entrées. Les opérations non-déterministes (accès DB, appels API, nombres aléatoires, timestamps) doivent être dans des décorateurs
@DBOS.step(), jamais directement dans le corps du workflow. - Idempotence : les étapes peuvent être rejouées lors de la récupération et doivent être sûres à ré-exécuter.
Conductor (optionnel)
Pour les déploiements en production, DBOS recommande de se connecter à Conductor, un service de gestion qui ajoute la coordination de récupération distribuée, les tableaux de bord de workflows et l’observabilité des files. Conductor est architecturalement hors du chemin critique : chaque serveur ouvre une connexion websocket sortante vers lui, et si la connexion tombe l’application continue de fonctionner normalement. Conductor n’a pas d’accès direct à votre base de données et n’est jamais impliqué dans l’exécution des workflows elle-même.
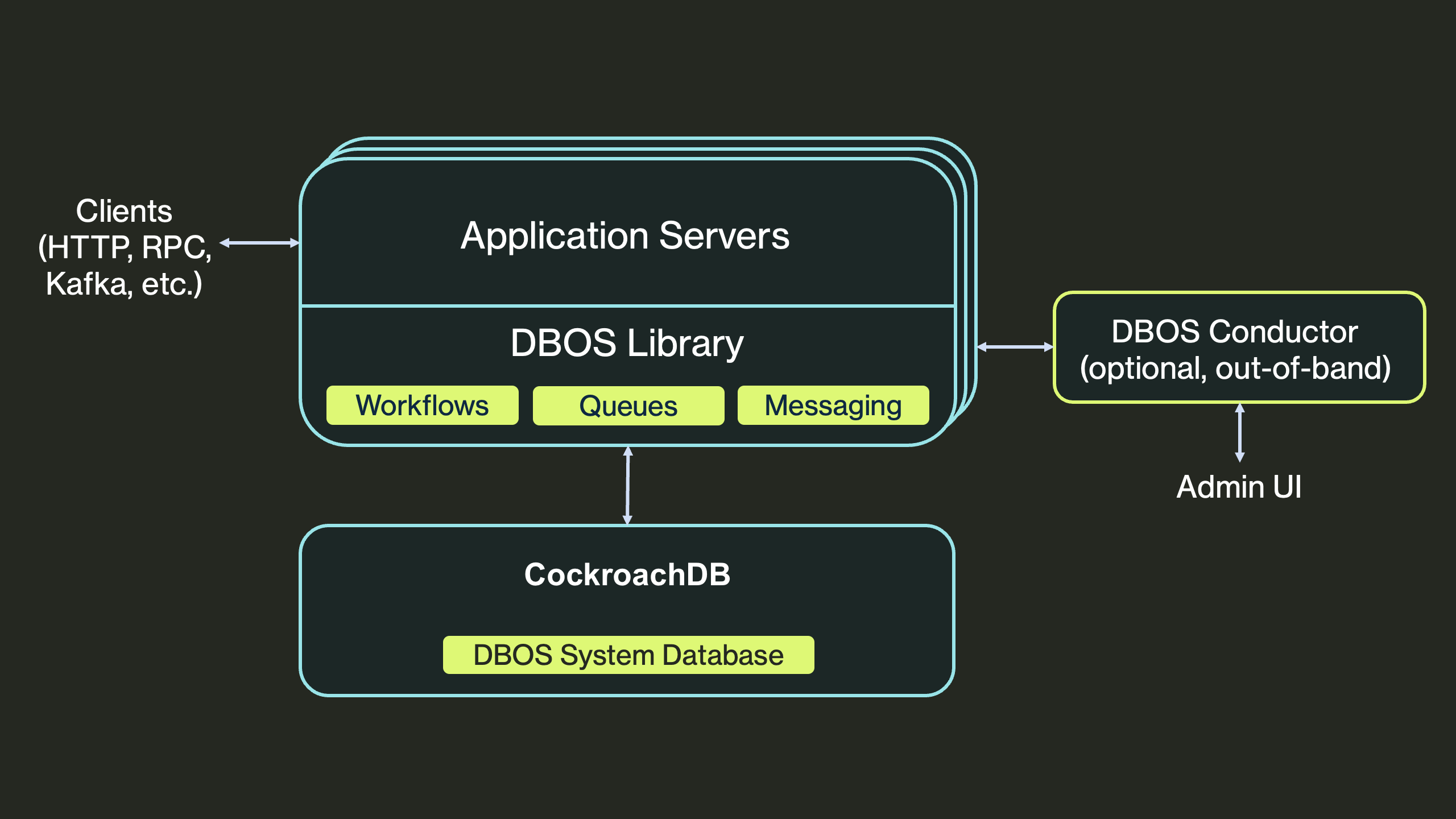
Conductor est hors bande : les serveurs applicatifs ouvrent des connexions websocket sortantes vers lui pour l’observabilité et la récupération, jamais pour l’exécution des workflows
Pourquoi CockroachDB pour DBOS ?
DBOS utilisant le protocole filaire PostgreSQL, il se connecte à CockroachDB directement sans modification de driver. Ce que CockroachDB ajoute par rapport à un PostgreSQL mono-nœud, c’est le niveau de persistance que vous avez toujours voulu mais que vous ne pouviez pas justifier d’opérer séparément :
- Isolation sérialisable : les exécutions de workflow concurrentes ne produisent jamais de mises à jour perdues ni de lectures fantômes
- Réplication active-active multi-région : l’état des workflows est durable à travers les défaillances de data center sans intervention manuelle
- Scalabilité horizontale : la base système passe à l’échelle avec votre application sans re-sharding
- Basculement automatique : les défaillances de nœuds CockroachDB sont transparentes pour DBOS, qui réessaie simplement sur le nœud suivant disponible
Lorsque DBOS se connecte à CockroachDB, il provisionne trois catégories de tables dans la base système :
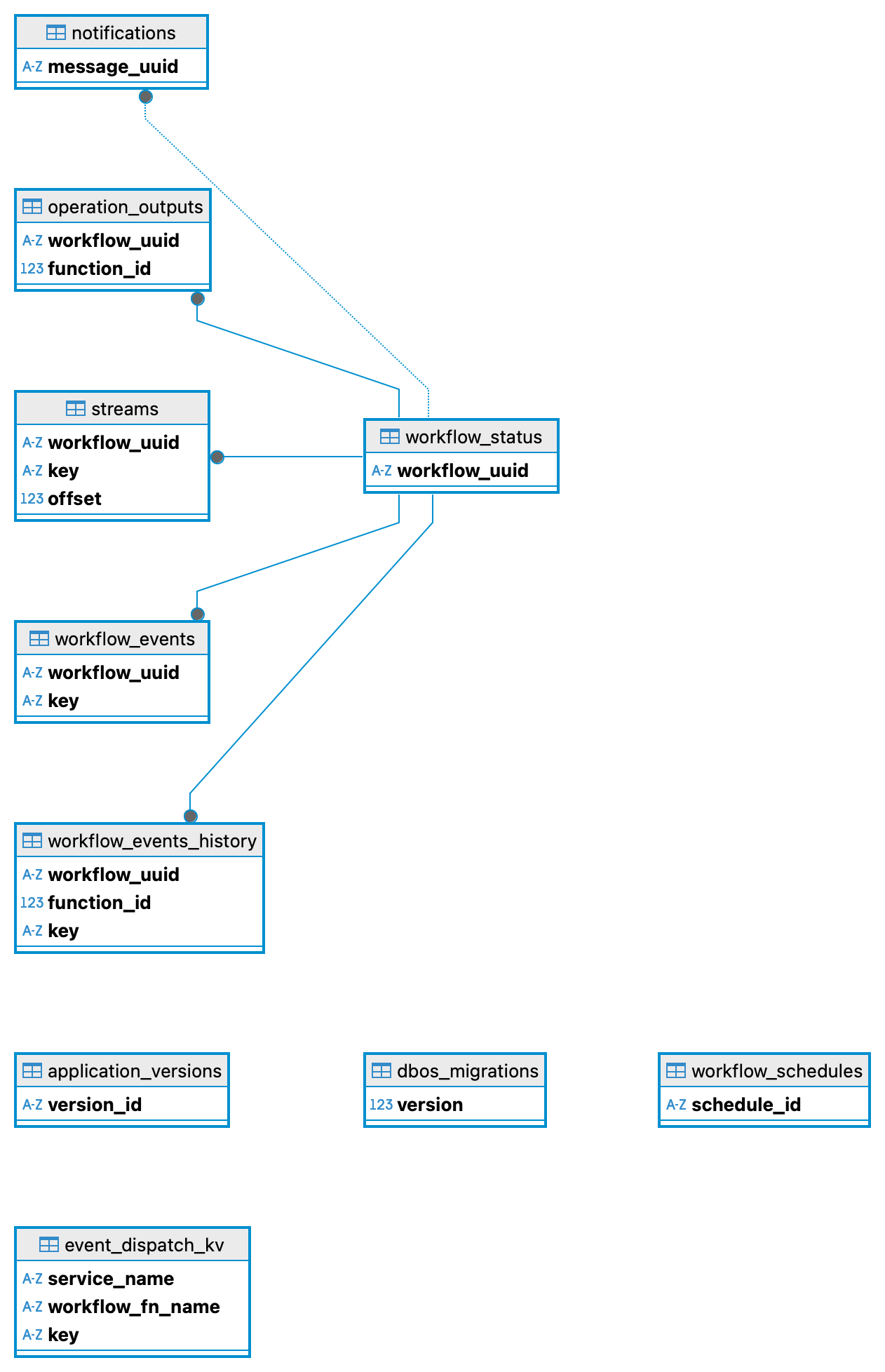
Tables créées par DBOS dans CockroachDB : statut des workflows, sorties des étapes et événements, le tout dans votre base existante
- Table de statut des workflows : une ligne par exécution, suivant l’ID, le statut et les entrées de la fonction
- Table des sorties d’opérations : une ligne par étape complétée, stockant la valeur de retour sérialisée pour la reprise
- Table d’événements : paires clé-valeur nommées publiées dans les workflows et consommées via
get_event
Pour les équipes souhaitant des workflows agentiques résilients globalement sans la complexité d’un cluster Temporal, DBOS + CockroachDB est le chemin à moindre overhead.
| Capacité | DBOS + CockroachDB |
|---|---|
| Pas d’infrastructure supplémentaire | L’exécution durable s’exécute dans votre processus FastAPI / applicatif |
| Étapes exactement-une-fois | Les étapes ne sont jamais ré-exécutées après que leur sortie est validée dans CockroachDB |
| Lancements idempotents | Le même ID de workflow retourne toujours l’exécution existante |
| Durabilité globale | La réplication multi-région de CockroachDB protège l’état des workflows entre régions |
| Zéro modification de driver | Protocole filaire PostgreSQL ; pas de SDK CockroachDB spécifique requis |
| Progression observable | set_event / get_event exposent la complétion des étapes aux frontends en temps réel |
Déployer DBOS sur CockroachDB
Deux modifications de configuration sont nécessaires lors de l’utilisation de CockroachDB à la place de PostgreSQL.
Prérequis
| Prérequis | Détails |
|---|---|
| Python 3.10+ | DBOS 2.x requiert Python 3.10 ou supérieur |
| Cluster CockroachDB | Une instance CockroachDB en fonctionnement (locale, CockroachDB Cloud ou auto-hébergée) |
| Base système | Une base dédiée à l’état DBOS ; à créer une seule fois : CREATE DATABASE dbos_system; |
| Packages Python | dbos[otel], fastapi[standard], psycopg2-binary, sqlalchemy-cockroachdb, uvicorn |
pip install "dbos[otel]==2.15.0" "fastapi[standard]" psycopg2-binary sqlalchemy-cockroachdb
export DBOS_COCKROACHDB_URL="postgresql://<user>:<password>@<crdb-host>:26257/dbos_system?sslmode=verify-full&sslrootcert=/certs/ca.crt"
1. Désactiver LISTEN/NOTIFY
Le mécanisme LISTEN/NOTIFY de PostgreSQL est utilisé par DBOS pour réveiller les workflows en attente sans polling. CockroachDB n’implémente pas ce mécanisme et il doit être désactivé explicitement. DBOS bascule automatiquement sur le polling :
from dbos import DBOS, DBOSConfig
from sqlalchemy import create_engine
import os
database_url = os.environ["DBOS_COCKROACHDB_URL"]
# SQLAlchemy's postgresql dialect cannot parse CockroachDB's version string;
# the cockroachdb dialect (sqlalchemy-cockroachdb) handles it correctly.
crdb_url = database_url.replace("postgresql://", "cockroachdb://", 1)
engine = create_engine(crdb_url)
config: DBOSConfig = {
"name": "my-agent-app",
"system_database_url": database_url,
# Pass a pre-built SQLAlchemy engine so DBOS uses the CockroachDB driver
"system_database_engine": engine,
# CockroachDB does not support LISTEN/NOTIFY: use polling instead
"use_listen_notify": False,
}
DBOS(config=config)
2. Définir l’URL de la base système
Dans dbos-config.yaml, pointer la base système vers CockroachDB en utilisant le format de chaîne de connexion PostgreSQL standard :
name: my-agent-app
language: python
runtimeConfig:
start:
- python3 app/main.py
system_database_url: ${DBOS_COCKROACHDB_URL}
Définissez la variable d’environnement avec votre chaîne de connexion CockroachDB :
export DBOS_COCKROACHDB_URL="postgresql://dbos_user:password@<crdb-host>:26257/dbos_system?sslmode=verify-full&sslrootcert=/certs/ca.crt"
Un workflow agentique DBOS complet sur CockroachDB
L’exemple suivant implémente un workflow d’agent durable en trois étapes adossé à CockroachDB. Le workflow publie des événements de progression après chaque étape qu’un frontend peut interroger en temps réel. Si le processus crashe en cours d’exécution, le redémarrer reprend depuis la dernière étape complétée, sans refacturation, pas d’écriture en double, pas de perte de contexte.
import os
import time
import uvicorn
from dbos import DBOS, DBOSConfig, SetWorkflowID
from fastapi import FastAPI
from sqlalchemy import create_engine
app = FastAPI()
# ── CockroachDB connection ──────────────────────────────────────────────────
database_url = os.environ["DBOS_COCKROACHDB_URL"]
# Use cockroachdb:// dialect so SQLAlchemy can parse CockroachDB's version string
crdb_url = database_url.replace("postgresql://", "cockroachdb://", 1)
engine = create_engine(crdb_url)
config: DBOSConfig = {
"name": "agent-workflow",
"system_database_url": database_url,
"system_database_engine": engine,
"use_listen_notify": False, # Required: CockroachDB has no LISTEN/NOTIFY
}
DBOS(config=config)
STEPS_EVENT = "steps_event"
# ── Workflow steps ──────────────────────────────────────────────────────────
@DBOS.step()
def retrieve_context(task: str) -> str:
"""Step 1: retrieve relevant context from the knowledge base."""
time.sleep(3)
DBOS.logger.info(f"Context retrieved for: {task}")
return f"context_for_{task}"
@DBOS.step()
def call_agent(context: str) -> str:
"""Step 2: call the LLM/agent with the context."""
time.sleep(3)
DBOS.logger.info("Agent invocation completed")
return f"agent_response_given_{context}"
@DBOS.step()
def persist_result(response: str) -> None:
"""Step 3: write the agent's output to the application database."""
time.sleep(3)
DBOS.logger.info(f"Result persisted: {response}")
# ── Durable workflow ────────────────────────────────────────────────────────
@DBOS.workflow()
def agent_workflow(task: str) -> None:
context = retrieve_context(task)
DBOS.set_event(STEPS_EVENT, 1)
response = call_agent(context)
DBOS.set_event(STEPS_EVENT, 2)
persist_result(response)
DBOS.set_event(STEPS_EVENT, 3)
# ── HTTP endpoints ──────────────────────────────────────────────────────────
@app.post("/agent/{task_id}")
def start_agent(task_id: str, task: str) -> dict:
"""Idempotently launch a durable agent workflow."""
with SetWorkflowID(task_id):
DBOS.start_workflow(agent_workflow, task)
return {"workflow_id": task_id, "status": "started"}
@app.get("/agent/{task_id}/progress")
def get_progress(task_id: str) -> dict:
"""Poll workflow progress (0-3 completed steps)."""
try:
step = DBOS.get_event(task_id, STEPS_EVENT, timeout_seconds=0)
except KeyError:
return {"completed_steps": 0}
return {"completed_steps": step if step is not None else 0}
if __name__ == "__main__":
DBOS.launch()
uvicorn.run(app, host="0.0.0.0", port=8000)
Installez les dépendances et lancez :
pip install "dbos[otel]==2.15.0" "fastapi[standard]" psycopg2-binary sqlalchemy-cockroachdb
export DBOS_COCKROACHDB_URL="postgresql://dbos_user:pass@localhost:26257/dbos_system?sslmode=disable"
python3 app/main.py
Benchmarking de scalabilité
Environnement de test
Tous les benchmarks ont été exécutés depuis une instance EC2 co-localisée dans AWS us-east-1, sans latence WAN :
- PostgreSQL RDS 17 :
db.m7i.24xlarge, 96 vCPU, 384 Go RAM, gp3 500 Gio, 16 000 IOPS, 1 000 Mo/s de débit - CockroachDB 3 nœuds :
3× m7i.8xlarge, 96 vCPU au total, nœuds répartis sur plusieurs AZ de us-east-1 (déploiement réellement redondant)
Artefacts du benchmark : tous les scripts et résultats JSON bruts sont publiés dans le dépôt sous
assets/bench/dbos-cockroachdb/:raw_write_bench.py·bench_direct.py·results_raw_pg.json·results_raw_crdb.json·results_pg.json·results_coloc.json
Étape 1 : Fact-check ce que le blog DBOS a réellement mesuré
L’équipe DBOS a publié un benchmark affirmant 144K écritures par seconde sur PostgreSQL (db.m7i.24xlarge, 96 vCPU, 384 Go RAM). En lisant attentivement la méthodologie, une distinction importante apparaît : ce chiffre mesure le débit d’INSERT bruts dans une table à 3 colonnes, pas des completions de workflows DBOS bout en bout. Le client de benchmark tournait sur le même hôte que la base de données, et le test effectuait de simples INSERT en autocommit (sans orchestration de workflow, sans séquencement d’étapes, sans checkpointing de durabilité).
Nous avons répliqué exactement cette méthodologie sur PostgreSQL et CockroachDB pour établir une baseline honnête avant de comparer les performances réelles en workflows.
Benchmark d’écritures brutes : table à 3 colonnes (id, val, ts), INSERT d’une ligne par opération, autocommit, writers concurrents :
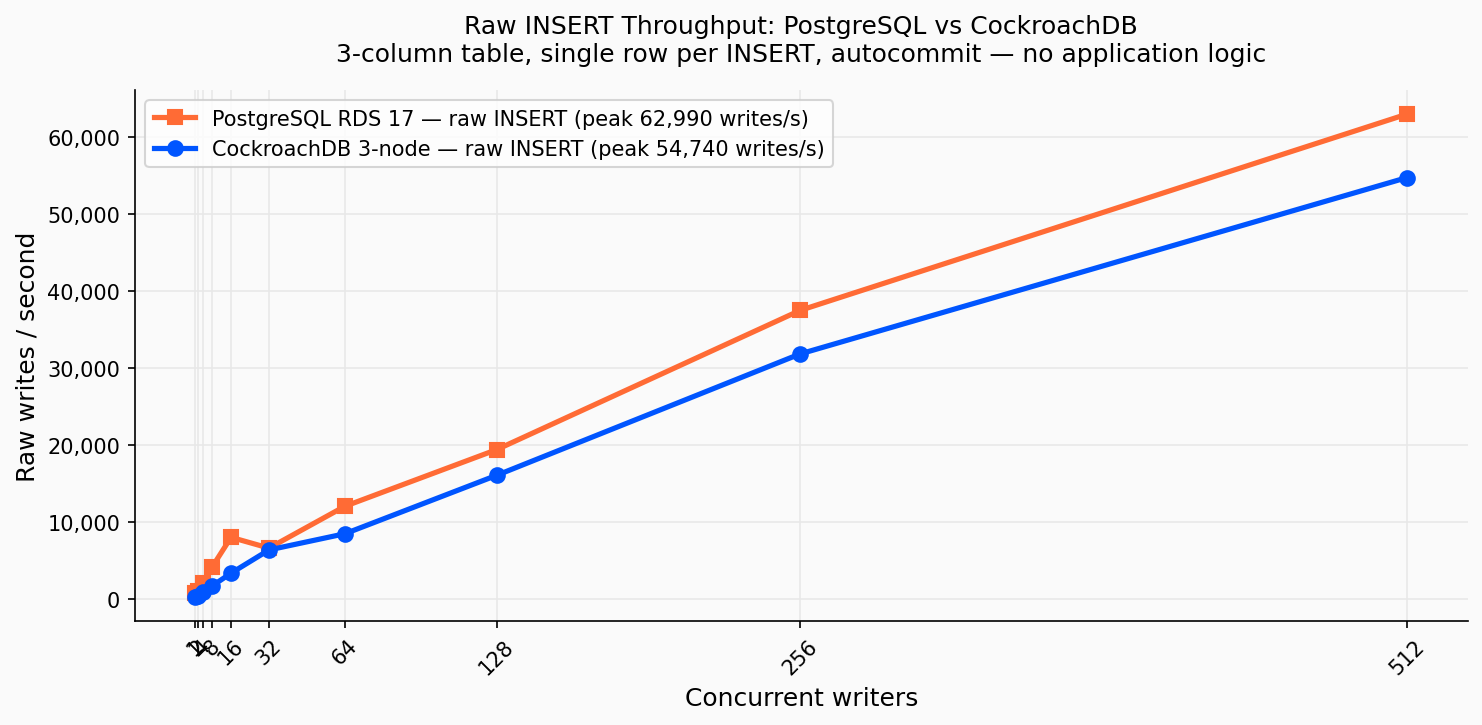
Pic d’INSERT bruts : PostgreSQL 62 990 écritures/s · CockroachDB 54 740 écritures/s. PG est plus rapide sur les écritures brutes ; son flush WAL local (~1,9 ms p50) l’emporte sur le quorum Raft cross-AZ de CockroachDB (~4–8 ms p50). Les deux sont bien en dessous des 144K du blog DBOS, qui utilisait une configuration de stockage à IOPS bien plus élevés avec le client co-localisé sur la DB.
| Concurrence | PG écritures/s | PG p50 (ms) | CRDB écritures/s | CRDB p50 (ms) |
|---|---|---|---|---|
| 1 | 728 | 1,4 | 277 | 3,6 |
| 8 | 4 125 | 1,9 | 1 659 | 4,7 |
| 32 | 6 584 | 4,1 | 6 344 | 4,9 |
| 64 | 12 016 | 4,3 | 8 448 | 6,8 |
| 128 | 19 380 | 5,1 | 16 039 | 7,1 |
| 256 | 37 478 | 5,1 | 31 820 | 7,1 |
| 512 | 62 990 | 5,8 | 54 740 | 8,3 |
Nos chiffres d’écritures brutes sont inférieurs aux 144K du blog DBOS car leur configuration de stockage avait des IOPS provisionnés bien plus élevés et le client tournait sur le même hôte que la base (zéro latence réseau). Notre setup (client EC2 vers RDS sur le réseau us-east-1, gp3 à 16 000 IOPS) reflète des conditions de déploiement réelles, pas un cas optimal co-localisé.
Étape 2 : Pourquoi écritures brutes ≠ completions de workflows
Un workflow DBOS à 2 étapes n’est pas un simple INSERT. Il produit 4 écritures séquentielles et acquittées :
- Démarrage du workflow : entrées persistées avant toute étape
- Sortie de l’étape 1 validée : valeur de retour stockée pour la reprise
- Sortie de l’étape 2 validée : valeur de retour stockée pour la reprise
- Complétion du workflow : statut final mis à jour
Chaque écriture doit être entièrement acquittée avant que l’étape suivante commence. C’est la garantie de durabilité : si le processus crashe après l’étape 1, l’étape 2 ne sera jamais ré-exécutée. La chaîne de commits séquentiels implique que la latence du workflow ≈ 4 × latence d’une écriture ; le débit ne scale pas avec la capacité d’écriture brute.
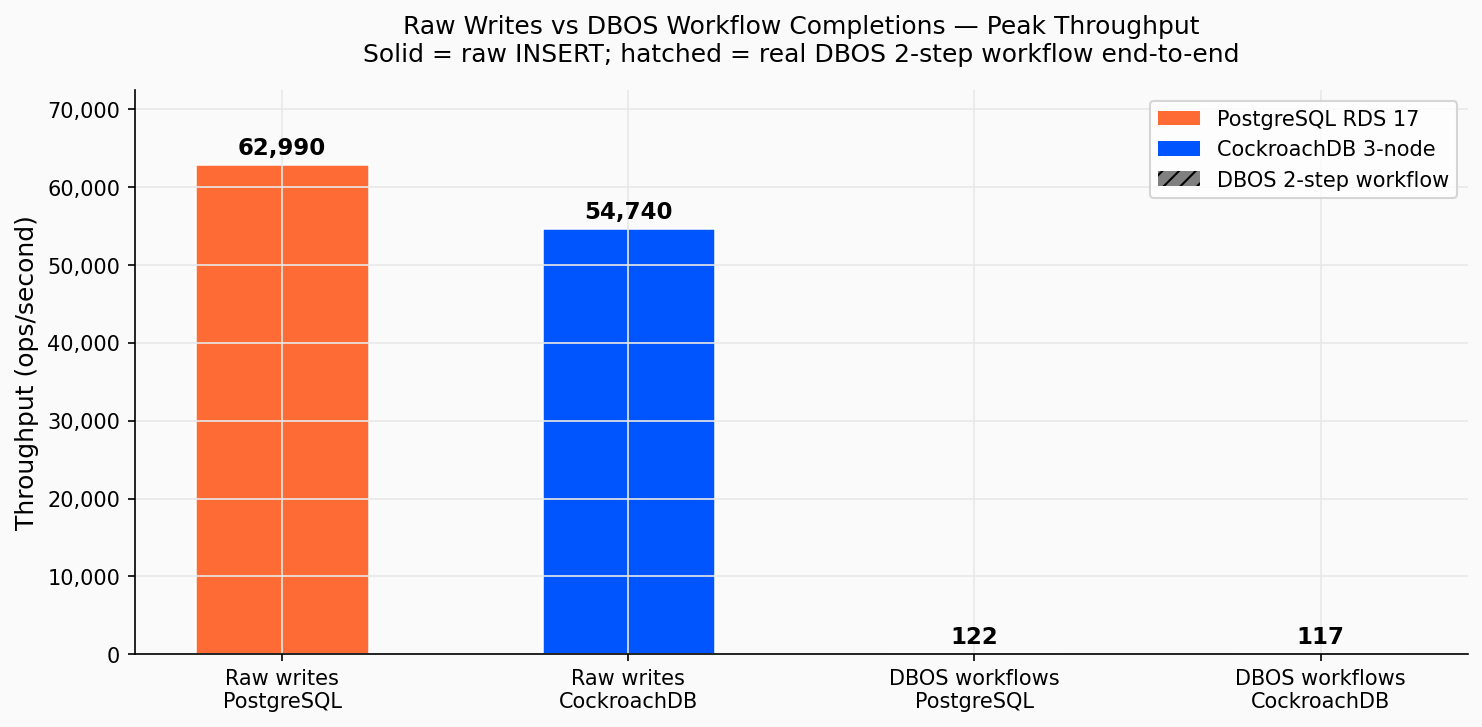
Écritures brutes vs completions réelles de workflows DBOS au pic de débit. L’écart ~500× entre écritures brutes et débit de workflows n’est pas un bug ; c’est le coût des garanties d’exécution durable et exactement-une-fois.
| Métrique | PostgreSQL | CockroachDB (3 nœuds) |
|---|---|---|
| Écritures brutes/s (pic) | 62 990 | 54 740 |
| Workflows DBOS/s (pic) | 122 | 117,5 |
| Ratio (brut ÷ workflow) | ~516× | ~466× |
Le ratio représente l’overhead de l’orchestration durable : chaque completion de workflow sérialise 4 allers-retours vers la base de données, chacun attendant l’acquittement avant de commencer le suivant.
Étape 3 : Benchmark réel de workflows DBOS PostgreSQL vs CockroachDB
Résultats : Débit PostgreSQL vs CockroachDB
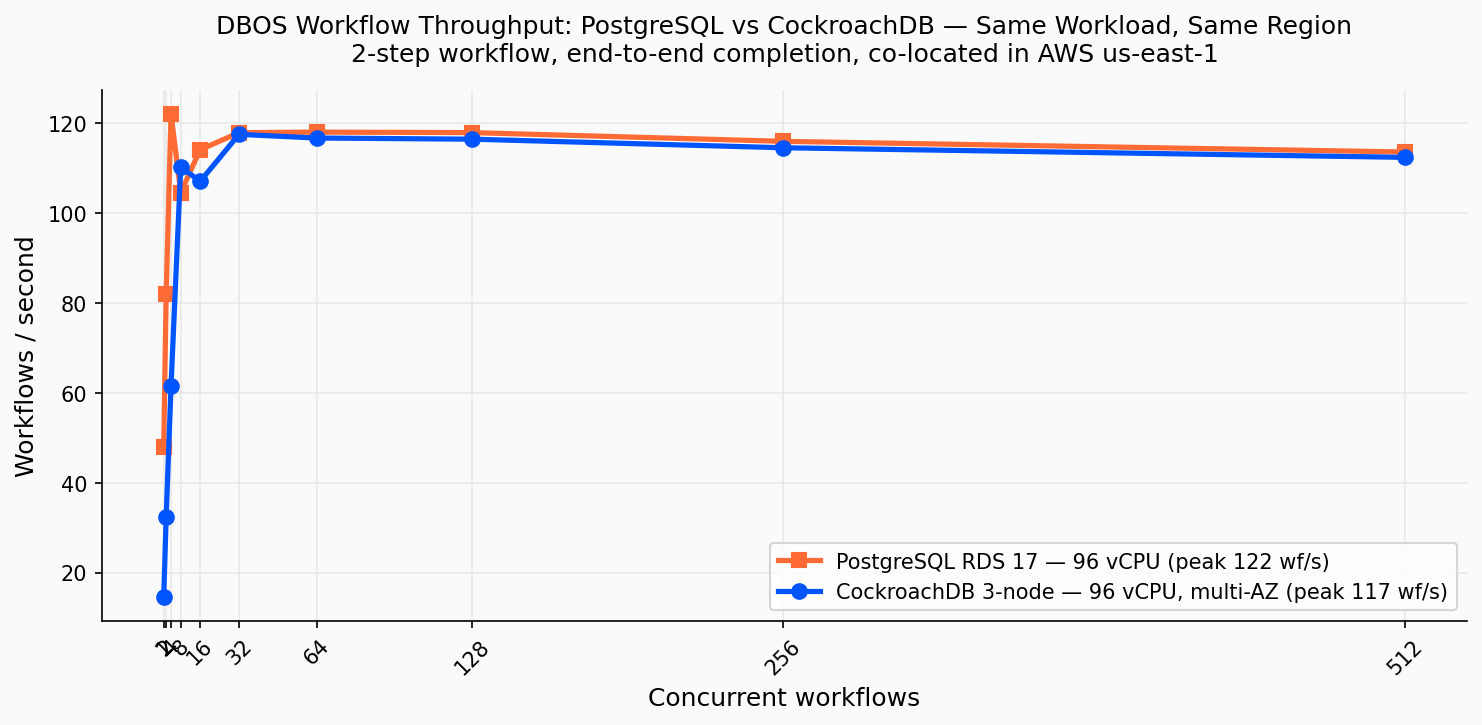
Les deux bases plafonnent à ~117 wf/s. PostgreSQL atteint son pic plus vite (122 wf/s à c=4) ; CockroachDB atteint le plafond de ses 3 nœuds à c=32 (117,5 wf/s). Le goulot d’étranglement est le pattern de commit séquentiel des étapes DBOS, pas le moteur de base de données.
Résultats : Latence PostgreSQL vs CockroachDB
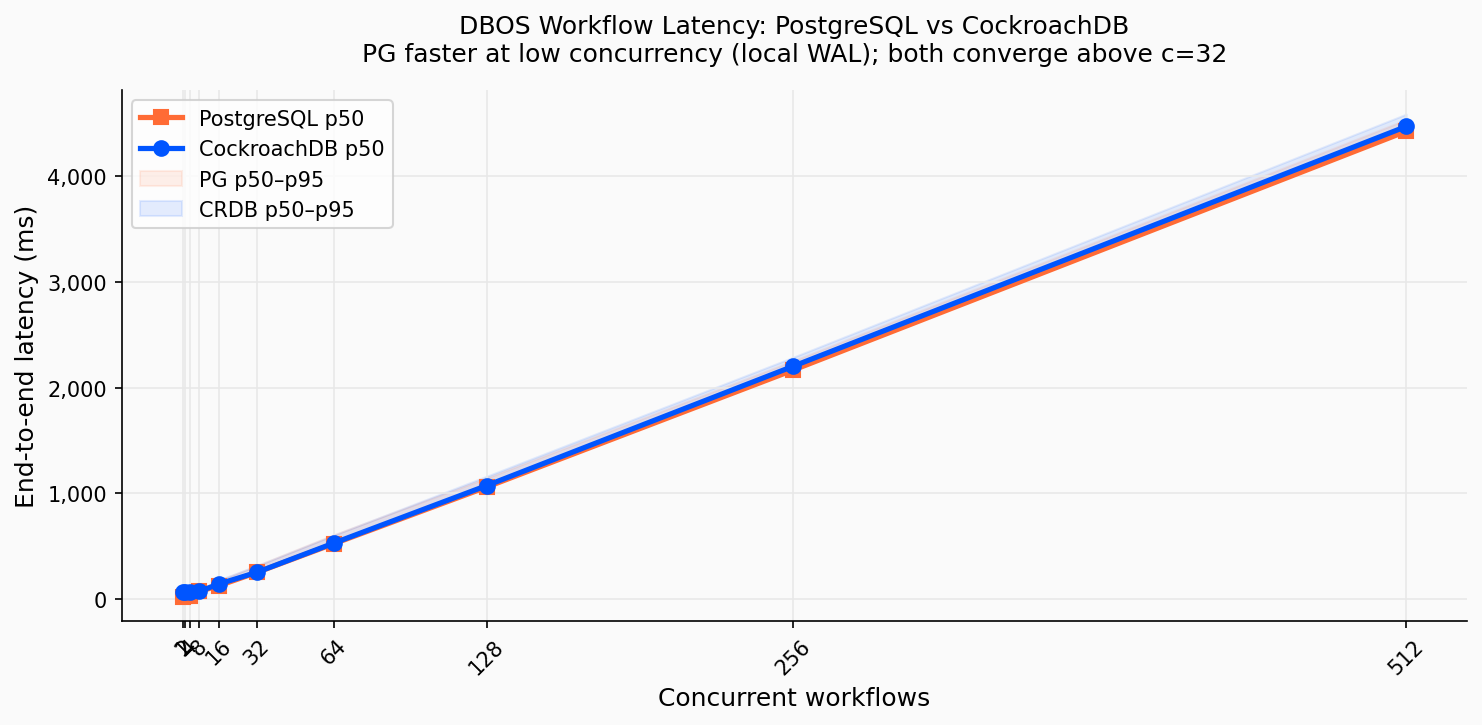
PostgreSQL est plus rapide à faible concurrence (19 ms p50 à c=1 (flush WAL local)). À c=8 les deux bases convergent à un p50 identique : 69 ms. Au-delà de c=32 les deux plafonnent à ~250 ms ; le pattern de commit séquentiel domine complètement. Les deux benchmarks tournent en isolation Read Committed.
| Concurrence | PG wf/s | PG p50 (ms) | CRDB wf/s | CRDB p50 (ms) |
|---|---|---|---|---|
| 1 | 48,0 | 19 | 14,6 | 65 |
| 4 | 122,0 (pic) | 29 | 61,5 | 62 |
| 8 | 104,5 | 69 | 110,2 | 69 |
| 16 | 114,0 | 122 | 107,0 | 138 |
| 32 | 117,8 | 248 | 117,5 (pic) | 250 |
| 64 | 118,0 | 519 | 116,6 | 525 |
| 256 | 115,9 | 2 166 | 114,5 | 2 202 |
| 512 | 113,5 | 4 428 | 112,3 | 4 474 |
L’argument de la scalabilité
Les deux bases saturent à ~117 wf/s sous cette charge de workflows DBOS : le goulot est le pattern de commit séquentiel des étapes, pas la base de données. La différence est ce qui se passe quand on a besoin de plus de 117 wf/s.
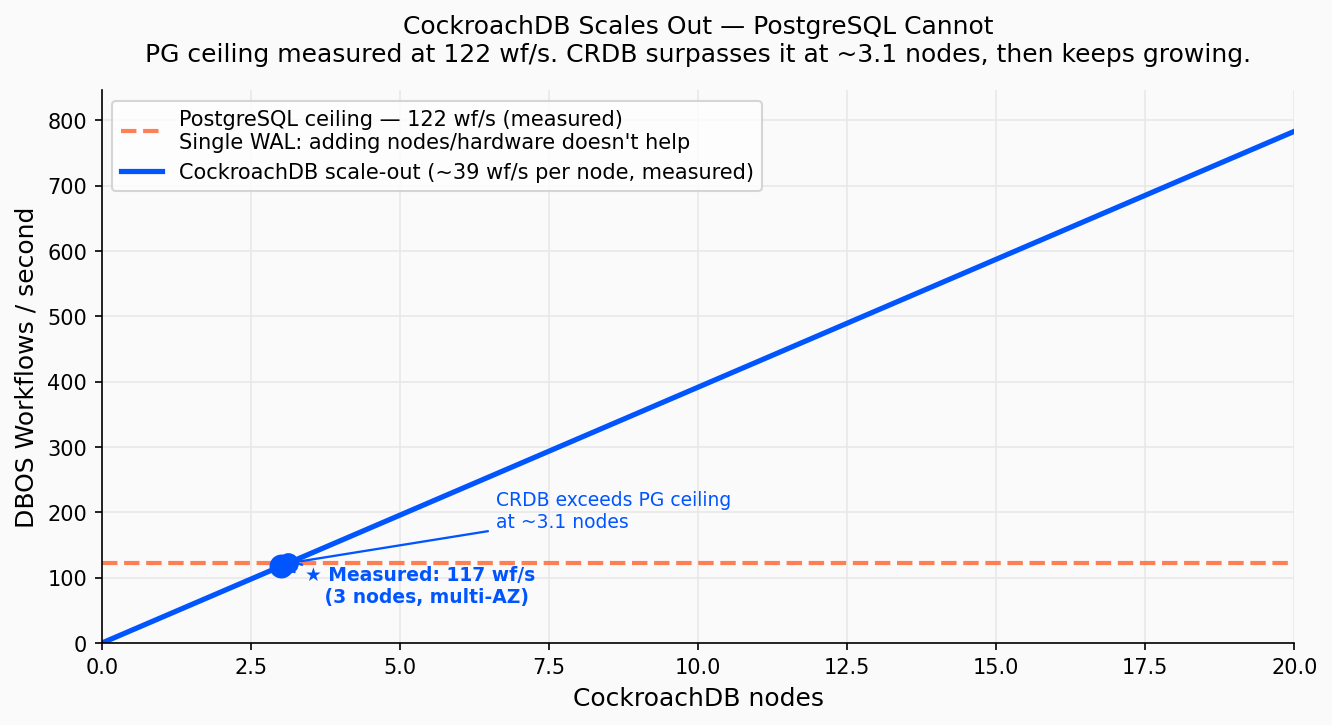
Le plafond PostgreSQL est mesuré à 122 wf/s, limite absolue de son WAL mono-nœud. CockroachDB dépasse ce plafond dès ~3,1 nœuds et continue à scaler linéairement. Chaque nœud ajoute ~39 wf/s.
Le Write-Ahead Log de PostgreSQL sérialise chaque écriture dans un seul chemin de flush. Une fois ce chemin saturé, aucun matériel supplémentaire n’améliore le débit d’écriture ; on peut scaler les lectures avec des réplicas, mais les écritures restent bornées par un seul nœud pour toujours. CockroachDB remplace le WAL unique par un log Raft distribué : chaque nœud flush son propre log, et les écritures se répartissent sur le cluster. Le plafond de débit monte avec chaque nœud ajouté.
Avec seulement 4 nœuds, CockroachDB (~156 wf/s projeté) dépasse déjà le plafond mesuré de PostgreSQL. Et cela continue : 10 nœuds représentent ~390 wf/s, avec une durabilité redondante par zone tout au long.
Synthèse
| PostgreSQL RDS 17 (96 vCPU) | CockroachDB (3 nœuds, multi-AZ) | CockroachDB (N nœuds) | |
|---|---|---|---|
| Débit wf maximum | 122 wf/s (mesuré) | 117,5 wf/s (mesuré) | ~39 × N wf/s |
| p50 à c=1 | 19 ms (WAL local) | 65 ms (Raft, cross-AZ) | ~65 ms |
| p50 à c=8 | 69 ms | 69 ms | ~69 ms |
| p50 à saturation (c=32+) | ~250 ms | ~250 ms | ~250 ms |
| Scale-out en écriture | Non (WAL = 1 nœud) | Oui | Oui (linéaire) |
| Défaillance de nœud | Basculement manuel | Automatique | Automatique |
| Durabilité multi-région | Outillage externe | Natif | Natif |
Les deux benchmarks tournent en isolation Read Committed. L’avantage de PostgreSQL à faible concurrence (19 ms vs 65 ms p50 à c=1) est uniquement le coût du quorum Raft cross-AZ ; il disparaît à c=8 où les deux bases atteignent un p50 identique de 69 ms. À saturation les deux convergent à ~250 ms. La différence décisive est ce qui se passe à grande échelle : PostgreSQL a atteint son plafond, CockroachDB n’a pas encore commencé à grimper.