
“Data & Snowflake” is a new series introducing Snowflake as a comprehensive data platform. Through this series, you will learn how to collect, store, process, analyze, and expose data using Snowflake’s various tools.
The Snowflake data platform is not built on any existing database technology or “big data” software platforms such as Hadoop. Instead, Snowflake combines a completely new SQL query engine with an innovative architecture natively designed for the cloud. To the user, Snowflake provides all of the functionality of an enterprise analytic database, along with many additional special features and unique capabilities.
Snowflake is a genuine self-managed service, meaning:
- Snowflake runs entirely on cloud infrastructure. All components of Snowflake’s service (except optional command line clients, drivers, and connectors) run in public cloud infrastructures.
- Snowflake uses virtual compute instances for its compute needs and storage service for persistent data storage. Snowflake cannot be run on private cloud infrastructures (on-premises or hosted).
- Snowflake is not a packaged software offering that a user can install. Snowflake manages all aspects of software installation and updates.
In the last posts, I explained that data architecture is a pivotal component of any data strategy. So, unsurprisingly, choosing the right data architecture should be a top priority for many organizations. Data architectures can be classified based on data velocity, and the most popular ones in this category are Lambda and Kappa.
In this first article, I will illustrate how Snowflake can implement each of these architectures using the myriad of tools and features it provides. A detailed implementation of each data lifecycle stage will be published in future posts.
What makes a “Good” Data Architecture?
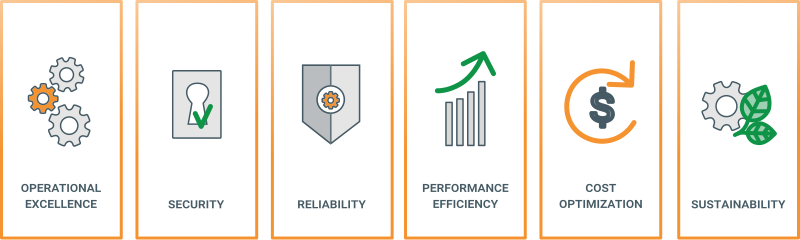
You know “good” when you see the worst. Bad data architectures are tightly coupled, rigid, overly centralized, and use the wrong tools for the job, hampering development and change management. A good data architecture should primarily serve business requirements with a widely reusable set of building blocks while preserving well-defined best practices (principles) and making appropriate trade-offs. We borrow inspiration for “good” data architecture principles from several sources, especially the AWS Well-Architected Framework. It consists of six pillars:
- Performance efficiency: A system’s ability to adapt to load changes.
- Reliability: The ability of a system to recover from failures and continue to function.
- Cost optimization: Managing costs to maximize the value delivered.
- Security: Protecting applications and data from threats.
- Operational excellence: Operations processes that keep a system running in production.
- Sustainability: Minimizing the environmental impacts of running the system workloads.
In the second part of this article, I will evaluate the data architectures implemented with Snowflake regarding this set of principles.
Because data architecture is an abstract discipline, it helps to reason by categories of architecture. The following section outlines prominent examples of famous data architecture today. Though this set of examples is not exhaustive, the intention is to expose you to some of the most common data architecture patterns and make an overview of the trade-off analysis needed when designing a good architecture for your use case.
Lambda data architecture with Snwoflake
The term “Lambda” is derived from lambda calculus (λ), which describes a function that runs in distributed computing on multiple nodes in parallel. Lambda data architecture was designed to provide a scalable, fault-tolerant, and flexible system for processing large amounts of data and allows access to batch-processing and stream-processing methods in a hybrid way. It was developed in 2011 by Nathan Marz, the creator of Apache Storm, to solve the challenges of real-time data processing at scale.
The Lambda architecture is an ideal architecture when you have a variety of data workloads and velocities. It can handle large volumes of data and provide low-latency query results, making it suitable for real-time analytics applications like dashboards and reporting. In addition, this architecture is useful for batch processing (e.g., cleansing, transforming, or data aggregation), for stream processing tasks (e.g., event handling, real-time recommendation, anomaly detection, or fraud prevention), and for building centralized repositories known as ‘data lakes’ to store structured/unstructured information.
The critical feature of Lambda architecture is that it uses two separate processing systems to handle different types of data processing workloads. The first is a batch processing system, which processes data in large batches and stores the results in a centralized data store (e.g., a data warehouse or a data lake). The second system is a stream processing system, which processes data in real-time as it arrives and stores the results in a distributed data store.
Lambda Architecture with Snowflake.
In the diagram above, you can see the main components of Lambda Architecture implemented with Snowflake. On a high level, the architecture consists of the following layers:
- Ingestion Layer: In this layer, raw data are extracted from one or more data sources, replicated, and then ingested into a snowflake stage. Depending on data Volume and Velocity, you would choose batch ingestion or stream ingestion (differences are extensively discussed here). Snowflake offers different tools that allow both kinds of ingestion:
1- Raw (As Is) data is copied from the source into the Snowflake Landing area. To implement this operation, Snowflake Virtual Warehouse executes Snowflake COPY commands triggered by an orchestrator such as Apache Airflow.
Raw data copied into stages.
2- Snowpipe loads data from files as soon as they are available in a stage. The data is loaded according to the COPY statement defined in a referenced pipe. A pipe is a named, first-class Snowflake object containing a COPY statement Snowpipe used. The COPY statement identifies the source location of the data files (i.e., a stage) and a target table. All data types, including semi-structured data types such as JSON and Avro, are supported.
Low-frequency batch ingestion.
3- Calling the Snowpipe Streaming API prompts the low-latency loading of streaming data rows using the Snowflake Ingest SDK and your own managed application code. The streaming ingest API writes rows of data to Snowflake tables, unlike bulk data loads or Snowpipe, which write data from staged files. This architecture results in lower load latencies with corresponding lower costs for loading similar data volumes, making it a powerful tool for handling real-time data streams.
Medium-frequency streaming ingestion.
4- Dynamic tables are the building blocks of declarative data transformation pipelines. They significantly simplify data engineering in Snowflake and provide a reliable, cost-effective, and automated way to transform your data for consumption. Instead of defining data transformation steps as a series of tasks and having to monitor dependencies and scheduling, you can determine the end state of the transformation using dynamic tables and leave the complex pipeline management to Snowflake.
Dynamic tables.
5- Some analytical workloads, like fraud detection or complex events processing, require more horsepower. The current limitations of dynamic tables might grow less over time, for example, when UDFs become available for dynamic tables. Until then, complex analytics could be handled by an external service with a dedicated analytical tool like Apache Flink.
High-frequency streaming analytics.
-
Batch Layer: In the batch layer, all of the incoming data is saved as batch views to ready it for indexing. This layer serves two important purposes. First, it manages the master data set where it is immutable and append-only, preserving a trusted historical record of the incoming data from all sources. Second, it precomputes the batch views. This layer helps fix errors, synchronize the data with other third-party systems, and conduct data quality checks. The processed data is stored in Snowflake in Core DWH and Data Mart layers and replaces online data from the previous day.
The COPY command is highly feature-rich, giving you the flexibility to decide where in the pipeline to handle specific functions or transformations, such as using ELT (Extract/Load/Transform) instead of traditional ETL.
Using the COPY command, data can be loaded from data storage in parallel, enabling loading hundreds of Terabytes (TB) in hours without compromising near real-time access to data that has been loaded. The COPY command can be executed from the Worksheet tab in the UI, just like any other DDL or DML operation, or programmatically using one of the supported languages, such as Python, Node.js, ODBC, JDBC, or Spark.
In addition, The Snowpark library provides an intuitive library for querying and processing data at scale in Snowflake. Using a library for any of three languages (Java, Python, and Scala), you can build applications that process data in Snowflake without moving data to the system where your application code runs and processes at scale as part of the elastic and serverless Snowflake engine.
StreamSets engine for Snowpark.
-
Speed Layer: By design, the batch layer has high latency, typically delivering batch views to the serving layer at a rate of once or twice daily. The job of the speed layer is to narrow the gap between when the data is created and when it’s available for querying. The speed layer does this by indexing all of the data in the serving layer’s current indexing job and all the data that’s arrived since the most recent indexing job began. After the serving layer completes an indexing job, all of the data included in the job is no longer needed in the speed layer and is deleted.
As part of the speed layer, the data goes through the following steps:
- The source system’s asynchronous event service acts as a filter to capture traffic from the source system as JSON messages. Then, it routes the messages to Kafka topics.
- StreamSets Data Collector (SDC) tool is used to consume events from Kafka topics and process them:
- Filters required messages,
- Enriches the data on the fly using the source system API (for instance, gets an entity name by passing its ID),
- Applies other required transformations to the data (data masking, filtering, etc.),
- Converts the data into CSV file format and puts the file into a data lake (e.g., S3 bucket),
- In parallel, original messages are put into the Data Lake.
- A Snowflake external table (Live View on the diagram) lets us query the information directly from the Data Lake S3 bucket. Thus, the data is not stored in the database but only passes through a Snowflake Virtual Warehouse when queried from the serving layer.
-
Serving Layer: The data serving layer receives the batch views from the batch layer on a predefined schedule, combines the batch and speed layers data through Snowflake DB view, and responds to end-user ad-hoc queries. This layer also receives near real-time views from the speed layer. Here, the batch views are indexed to make them available for querying. As one indexing job runs, the serving layer queues newly arriving data for inclusion in the next indexing run.
The serving layer is implemented as a set of Snowflake DB views that combine the information from data marts (prepared in the batch dataflow) and the Snowflake external tables (Live View on the diagram). As a result, the actual data from the end-user applications is ready for consumption through customized dashboards and self-service data discovery capability. Using Live Connection mode, the end-user applications make queries directly against Snowflake DB.
While Lambda architectures offer many advantages, such as scalability, fault-tolerance, and flexibility to handle a wide range of data processing workloads (batches and streams), they also come with drawbacks that organizations must consider before deciding whether to use or not. Lambda architecture is a complex system that uses multiple technology stacks to process and store data. In addition, the underlying logic is duplicated in the Batch and the Speed Layers for every stage. As a result, it can be challenging to set up and maintain, especially for organizations with limited resources. However, using Snowflake as a unique stack for both layers can help reduce the complexity encountered in Lambda architectures.
Kappa data architecture with Snowflake
In 2014, while working at LinkedIn, Jay Kreps started a discussion where he pointed out some drawbacks of the Lambda architecture. This discussion further led the big data community to another alternative that used fewer code resources.
The principal idea behind this is that a single technology stack can be used for both real-time and batch data processing. This architecture was called Kappa. Kappa architecture is named after the Greek letter “Kappa” (ϰ), which is used in mathematics to represent a “loop” or “cycle.” The name reflects the architecture’s emphasis on continuous data processing or reprocessing rather than a batch-based approach. At its core, it relies on streaming architecture: incoming data is first stored in an event streaming log, then processed continuously by a stream processing engine, like Kafka, either in real-time or ingested into any other analytics database or business application using various communication paradigms such as real-time, near real-time, batch, micro-batch, and request-response.
Kappa architecture is designed to provide a scalable, fault-tolerant, and flexible system for processing large amounts of data in real-time. The Kappa architecture is considered a simpler alternative to the Lambda architecture as it uses a single technology stack to handle both real-time and historical workloads, treating everything as streams. The primary motivation for inventing the Kappa architecture was to avoid maintaining two separate code bases (pipelines) for the batch and speed layers. This allows it to provide a more streamlined and simplified data processing pipeline while providing fast and reliable access to query results.
Kappa Architecture with Snowflake.
The most important requirement for Kappa was Data reprocessing, making visible the effects of data changes on the results. Consequently, the Kappa architecture with Snowflake comprises only two layers: the stream layer and the serving one. The Serving Layer of Kappa is quite similar to Lambda’s one.
The stream processing layer collects, processes, and stores live-streaming data. This approach eliminates the need for batch-processing systems by using an advanced stream processing engine such as Snowpark, Apache Flink, or Apache Spark Streaming to handle high volumes of data streams and provide fast, reliable access to query results. The stream processing layer is divided into two components: the ingestion component, which collects data from various sources, and the processing component, which processes this incoming data in real-time.
- Ingestion component: This layer collects incoming data from various sources, such as logs, database transactions, sensors, and APIs. The data is ingested in real-time using Apache Kafka with Snowpipe Streaming API and stored in Snowflake stages for processing.
- Processing component: The Processing component of the Kappa architecture is responsible for handling high-volume data streams and providing fast and reliable access to query results. It uses event-processing engines like Snowpark to process incoming data in real-time. In addition, multiple Snowflake integrations exist for other event processing engines like Apache Spark Streaming (Spark-Snowflake), Apache Kafka (Snowflake Kafka connectors), or dbt coonector for Snowflake.
Snowpipe streaming.
Nowadays, real-time data beats slow data. That’s true for almost every use case. Nevertheless, Kappa Architecture cannot be taken as a substitute for Lambda architecture. On the contrary, it should be seen as an alternative to be used in those circumstances where the active performance of the batch layer is not necessary for meeting the standard quality of service.
One of the most famous examples that leverage Kappa Architecture with Snowflake is the IoT architecture. The Internet of Things (IoT) is a network of physical devices, vehicles, appliances, and other objects (aka, things) embedded with sensors, software, and connectivity that enables them to collect and exchange data. These devices can be anything from smart home appliances to industrial machinery to medical devices, and they are all connected to the Internet.
IoT Architecture with Snowflake.
The data collected by IoT devices can be used for various purposes, such as monitoring and controlling devices remotely, optimizing processes, improving efficiency and productivity, and enabling new services and business models. IoT Data is generated from devices that collect data periodically or continuously from the surrounding environment and transmit it to a destination.
Although the concept of IoT devices dates back several decades, the widespread adoption of smartphones created a massive swarm of IoT devices almost overnight. Since then, various new categories of IoT devices have emerged, including smart thermostats, car entertainment systems, smart TVs, and smart speakers. The IoT can revolutionize many industries, including healthcare, manufacturing, transportation, and energy. It has transitioned from a futuristic concept to a significant domain in data engineering. It is expected to become one of the primary ways data is generated and consumed.
Data Mesh architecture with Snowflake
Data mesh was introduced in 2019 by Zhamak Dehghani. In her blog post, she argued that a decentralized architecture was necessary due to the shortcomings of centralized data warehouses and lakes.
A data mesh is a framework that enables business domains to own and operate their domain-specific data without needing a centralized intermediary. It draws from distributed computing principles, where software components are shared among multiple computers running together as a system. This way, data ownership is spread across different business domains, each responsible for creating its products. Additionally, it allows easier contextualization of the collected information to generate deeper insights while facilitating collaboration between domain owners to develop tailored solutions according to specific needs.
In a subsequent article, Zhamak revised her position by proposing four principles that form this new paradigm.
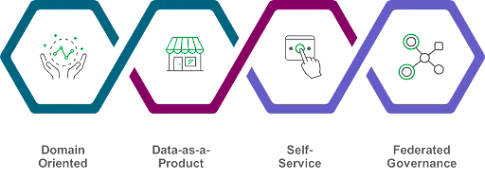 Data mesh principles.
Data mesh principles.
Snowflake offers several key capabilities for implementing automated data transformation pipelines and creating and governing data products. Snowflake’s platform is designed for ease of use, near-zero maintenance, and instantaneous scaling of resources to enable a true self-service experience. Each domain team can deploy and scale its resources according to its needs without impacting others and freeing them from relying on an infrastructure team.
Snowflake’s platform allows domain teams to operate independently and yet easily share data products with each other. Each domain can designate which data objects to share and then publish product descriptions in a Snowflake Data Exchange, which serves as an inventory of all data products in the data mesh. Other teams can search that inventory to discover data products that meet their requirements.
Snowflake databases as domains.
1- Data as a product: Data teams apply product thinking to their datasets. In this approach, an organization assigns a product owner to data. It involves the rigors of product principles to data assets to provide real value to its end customers (e.g., data scientists and analysts).
Data producers in Snowflake can share data, data services, or applications with other accounts by publishing metadata (“listings”). Producers can use listing discovery controls to privately share with other accounts or groups of accounts or publicly share via the Snowflake Marketplace. Data producers can specify SLAs or SLOs for the data they share, such as the update frequency, the amount of history, the temporal granularity of the data, and other properties that help describe the data as a product.
2- Domain ownership: Data ownership is federated among domain experts responsible for producing assets for analysis and business intelligence. Snowflake is a distributed but interconnected platform that avoids silos and enables distributed teams to exchange data in a governed and secure manner. Different domain teams can work autonomously using independent compute power in separate databases or accounts while still using the underlying Snowflake platform to share data assets with each other.
Snowflake accounts as domains.
3- Self-serve data platforms: A central platform handles the underlying infrastructure needs of processing data while providing the tools necessary for domain-specific autonomy.
Some of the most common reasons to choose Snowflake include ease of use and near-zero maintenance. These are critical properties for a self-service platform. For example, users can easily instantiate and scale their compute clusters without the IT infrastructure team’s support. Cloning dev and test environments is equally straightforward. A change data capture mechanism can be set up with a 1-line SQL DDL statement. This focus on ease of use has been a guiding principle for all features and functions on the Snowflake platform.
4- Federated computational governance: A universal set of centrally defined standards ensures adherence to data quality, security, and policy compliance across data domains and owners.
Federated governance is arguably one of the most challenging parts of a data mesh journey and often requires one or more combined tools to satisfy all requirements. Snowflake supports role-based access control, row-level access policies, column-level data masking, external tokenization, data lineage, audit capabilities, and more at the platform level. Users can also assign one or more metadata tags (key-value pairs) to almost any kind of object in Snowflake, such as accounts, databases, schemas, tables, columns, compute clusters, users, roles, tasks, shares, and other objects.
Tags are inherited through the object hierarchy and can be exploited to discover, track, restrict, monitor, and audit objects based on user-defined semantics. Additionally, tag-based access policies enable users to associate an access restriction with a tag such that the access policy is automatically applied to any matching data object that carries the relevant tag.
Data Mesh implementation using Snowflake.
Data Architectures with Snowflake: are they “Good” Architectures?
As discussed earlier, The AWS Well-Architected framework is designed to help cloud architects create secure, reliable, high-performing, cost-effective, and sustainable architectures. This system consists of six key pillars: operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability, providing customers with a consistent way to evaluate and implement scalable architectures. I borrowed inspiration for “good” data architecture principles from the AWS Well-Architected Framework and assessed whether Snowflake could make “good” data architectures or not.
1. Performance efficiency stands for the ability of a system to adapt to load changes. The Main challenge we can observe with many data architectures is the operational complexity when deploying and managing their technical tools and solutions. More often, it is difficult to anticipate and handle demand peaks of such platforms, resulting in wasted money on underused resources that are already over-provisioned due to poor scaling processes. In this study, the author performed synthetic benchmarks (TPC-DS) to measure the performance impacts of broadly applicable changes. In other words, how much faster has Snowflake become over time using stable building blocks (stable data warehouses and stable recurrent queries)?
Query Duration for Customers’ Recurring Workloads Improves by 15%.
2. Reliability is the precondition for trust.1 This mantra is valid in data architecture, especially when end-users seek real-time decision-making. Reliability stands for The ability of a system to recover from failures and continue to function as expected. The main challenge regarding a data platform’s reliability is meeting the required SLAs. Downtimes or slow response times can consequently lead to revenue loss, damaged reputation, and customer churn. Snowflake provides powerful features for ensuring the maintenance and availability of your historical data (i.e., data that has been changed or deleted): - Querying, cloning, and restoring historical data in tables, schemas, and databases for up to 90 days through Snowflake Time Travel. - Disaster recovery of historical data (by Snowflake) through Snowflake Fail-safe.
These features are included for all accounts, i.e., no additional licensing is required; however, standard Time Travel is one day. Extended Time Travel (up to 90 days) requires Snowflake Enterprise Edition. In addition, both Time Travel and Fail-safe require additional data storage, which has associated fees.
Snowflake also provides several mechanisms to create Replication groups to replicate data to one or more target accounts and Failover groups that provide read-only access for the replicated objects when a failure occurs.
3. Cost optimization stands for managing costs to maximize the value delivered. Snowflake architecture separates the storage from the compute, allowing various workloads to run inside the same warehouse without any awareness of each other and, therefore, isolated to prevent them from affecting one another. The main advantage of this multi-tenancy is the ability to share infrastructure capabilities by multiple databases, thus reducing the Total Cost of Ownership (TCO) of your data platform (30% to 70% of cost reduction).
Another lever that optimizes your data platform cost is reduced administration and maintenance costs (Snowflake is a fully managed platform). Using the built-in performance features, each workload in Snowflake is as fast, stable, and efficient as possible. Finally, Snowflake continuously improves customers’ price for performance through native cost and workload optimization features, performance improvements, and learning resources for cost management. Snowflake has reduced the average cost of warehouse queries by more than 20% over the last three years.
4. Security stands for protecting the data platform from threats. Although security is often perceived as a hindrance to the work of data engineers, they must recognize that security is, in fact, a vital enabler. By implementing robust security measures (encryption, network whitelisting, network peering, multi-factor authentication, Single-Sign-On, OAuth, SCIM, mutual TLS, trusted CA…) for data at rest and in motion and fine-grained data access control, a data architecture using Snowflake can enable wider data sharing and consumption within a company, leading to a significant increase in data value. In addition, the principle of least privilege is implemented through Discretionary Access Control (DAC) and Role-Based Access Control (RBAC), meaning that data access is only granted proportionally to those who require it.
5. Operational excellence is the ability to keep a system running in production optimally. First, Snowflake provides multiple integrations to allow operational monitoring of your data platform, the underlying infrastructure, and data access (audit trail). Thus, you can gain visibility and take the appropriate actions.
6. Sustainability tends to minimize your data platform’s environmental footprint. Snowflake supports several deployment options that allow you to choose the region, storage technologies, and configurations that best support the business value of your data (multi-cloud, hybrid cloud). In addition, features like multi-tenancy and data tiering can reduce the provisioned infrastructure required to support your data platform and the resources needed to use it. Consequently, using Snowflake helps reduce the environmental footprint of your data platform.
Summary
In this article, I introduce Snowflake as a self-service data platform that implements the most popular data architectures using the myriad of tools and features it provides.
Data types are increasing, usage patterns have grown significantly, and a renewed emphasis has been placed on building pipelines with Lambda and Kappa architectures in the form of data hubs or fabrics. Either grouped by velocity or the kind of topology they provide, data architectures are not orthogonal. The data architectures and paradigms we presented in this post can be used side-by-side, alternately when there is a need to alternate between them. In addition, of course, they can be mixed in architectures like data mesh, in which each data product is a standalone artifact. We can imagine that a Lambda architecture is implemented in some data products and Kappa architectures in others.
Overall, this article provides a comprehensive overview of how Snowflake can be used as a modern data platform and the various data architectures that can be implemented. Then, I evaluated these architectures, regarding the AWS Well-Architected Framework, to assess if those are “good” data architectures. The result of this evaluation provides valuable insights into building well-architected data platforms.
References
- “Three-speed architecture on Snowflake”, Reinout Korbee, Medium 2023.
- “Fundamentals of data engineering: Plan and build robust data systems”, Reis, J. and Housley M., O’Reilly Media (2022).
- “Lambda vs. Kappa Architecture. A Guide to Choosing the Right Data Processing Architecture for Your Needs”, Dorota Owczarek.
- “A brief introduction to two data processing architectures: Lambda and Kappa for Big Data”, Iman Samizadeh, Ph.D.
- “What Is Lambda Architecture?”, Hazelcast Glosary.
- “What Is the Kappa Architecture?”, Hazelcast Glosary.
- “Kappa Architecture is Mainstream Replacing Lambda”, Kai Waehner.
- “Data processing architectures – Lambda and Kappa”, Julien Forgeat.
- “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh”, Zhamak Dehghani (Martin Fowler Blog).
- “Data Mesh Principles and Logical Architecture”, Zhamak Dehghani (Martin Fowler Blog).
- “Benchmarking Real World Customer-Experienced Performance Using the Snowflake Performance Index (SPI)”, Louis Magarshack, Medium 2023.
1. Wolfgang Schäuble - a German lawyer, politician, and statesman whose political career spans over five decades.