
Modern AI applications are no longer single-shot inference calls. They are long-running agents that plan, act, observe, and retry across time. An AI agent loop that retrieves context from a vector store, calls an LLM, writes results to a database, waits for human approval, and then triggers downstream actions can run for minutes, hours, or even days. Without a durable orchestration layer, any transient infrastructure failure restarts the entire loop from scratch: re-billing expensive LLM calls, duplicating side effects, and losing all accumulated context.
Platforms like Temporal solve this by deploying a dedicated orchestration cluster (a separate server process with its own persistence backend) that your application workers connect to over gRPC. This is powerful, but it means an extra service to provision, monitor, scale, and keep available before your first workflow can run.
DBOS takes a fundamentally different approach: it embeds durable execution directly into your application as a Python or TypeScript library, using the database you already have. There is no orchestration server, no task queue, no sidecar process. Your application writes workflow state to tables in its own database as a natural side effect of execution, and recovers from those tables on restart. Pair DBOS with CockroachDB and you get a globally distributed, self-healing execution platform with no additional infrastructure to manage.
A durable workflow is a function whose execution state (which steps have completed, what they returned, what inputs were given) is persisted to the database after every step. If the process crashes mid-run, it restarts and replays from the last committed step: no work is lost, no step is re-executed, no external side effect is duplicated.
What Is DBOS?
DBOS is a Python and TypeScript library that decorates ordinary functions with durable execution guarantees. There is no server to deploy, no task queue to operate, no separate persistence cluster to manage. DBOS writes workflow state to tables in your application database as a side effect of normal execution, and recovers from those tables on restart.
Core Concepts
| Concept | Definition |
|---|---|
@DBOS.workflow() |
Decorator that makes a Python function durable; state is persisted before each step |
@DBOS.step() |
A unit of work inside a workflow; executes at least once but never re-executes after completion |
| Workflow ID | The idempotency key; launching the same workflow ID twice is safe and returns the existing execution |
DBOS.set_event() |
Publishes a named value from inside a workflow for external consumers to read |
DBOS.get_event() |
Polls a workflow for a named event value with an optional timeout |
| System Database | The PostgreSQL-compatible database where DBOS stores all workflow state, step completions, and events |
Architecture
DBOS is implemented entirely as an open-source library embedded in your application: there is no orchestration server and no external dependencies except a PostgreSQL-compatible database. While your application runs, DBOS checkpoints workflow and step state to that database. On failure, it uses those checkpoints to resume each workflow from the last completed step.
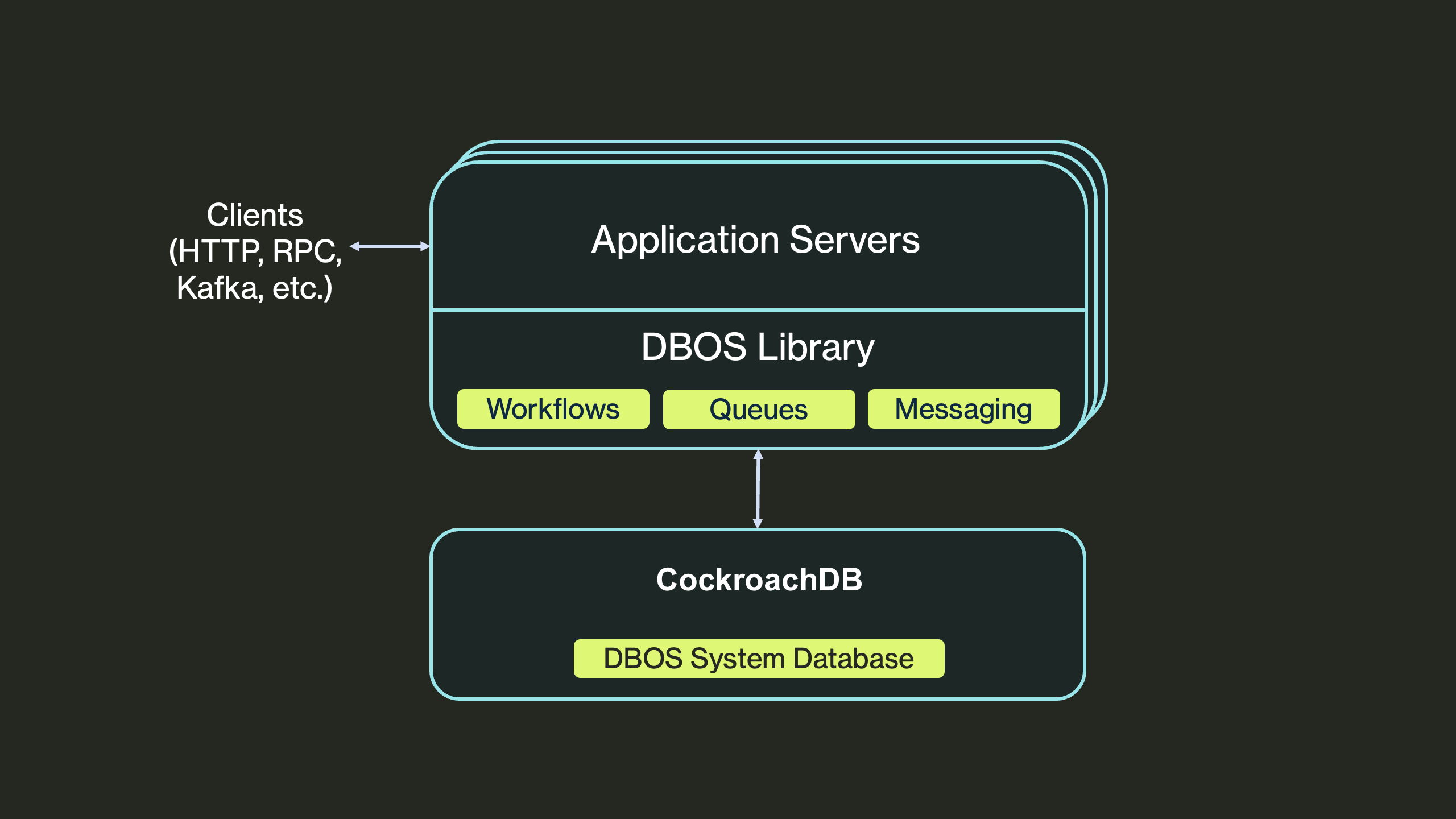
DBOS architecture: the durable execution library lives inside your application process; the only external dependency is a Postgres-compatible database
Checkpointing model
Every workflow execution produces a fixed number of database writes regardless of complexity:
- One write at workflow start: inputs are persisted before any step runs
- One write per completed step: the step’s return value is stored so replay can skip it
- One write at workflow end: the final status is committed
Write sizes are proportional to your inputs and outputs. For large payloads (files, embeddings), the recommended pattern is to store them externally (e.g., S3) and have steps return pointers only.
Distributed deployment
DBOS scales naturally to a fleet of servers. All application servers connect to the same system database, the only coordination point. By default, each workflow runs on a single server; durable queues distribute work across the fleet with configurable rate and concurrency limits.
For multi-application setups (e.g., an API server, a data-ingestion service, and an AI agent loop), each application connects to its own isolated system database. A single physical database host can serve multiple system databases. The DBOS Client lets external code enqueue jobs and monitor results across application boundaries.
Workflow recovery
When a process crashes, DBOS detects incomplete workflows and replays them in three steps:
- Detection: at startup, DBOS scans for pending workflows. In distributed deployments, Conductor coordinates detection across the fleet.
- Restart: each interrupted workflow is called again with its original checkpointed inputs.
- Resume: as the workflow re-executes, every step whose output is already checkpointed is skipped instantly. Execution resumes from the first un-checkpointed step.
Two requirements for safe recovery:
- Determinism: the workflow function must produce the same steps in the same order given the same inputs. Non-deterministic operations (DB access, API calls, random numbers, timestamps) must live inside
@DBOS.step()decorators, never directly in the workflow body. - Idempotency: steps may be retried on recovery and must be safe to re-execute.
Conductor (optional)
For production deployments, DBOS recommends connecting to Conductor, a management service that adds distributed recovery coordination, workflow dashboards, and queue observability. Conductor is architecturally off the critical path: each server opens an outbound websocket connection to it, and if the connection drops the application continues operating normally. Conductor has no direct access to your database and is never involved in workflow execution itself.
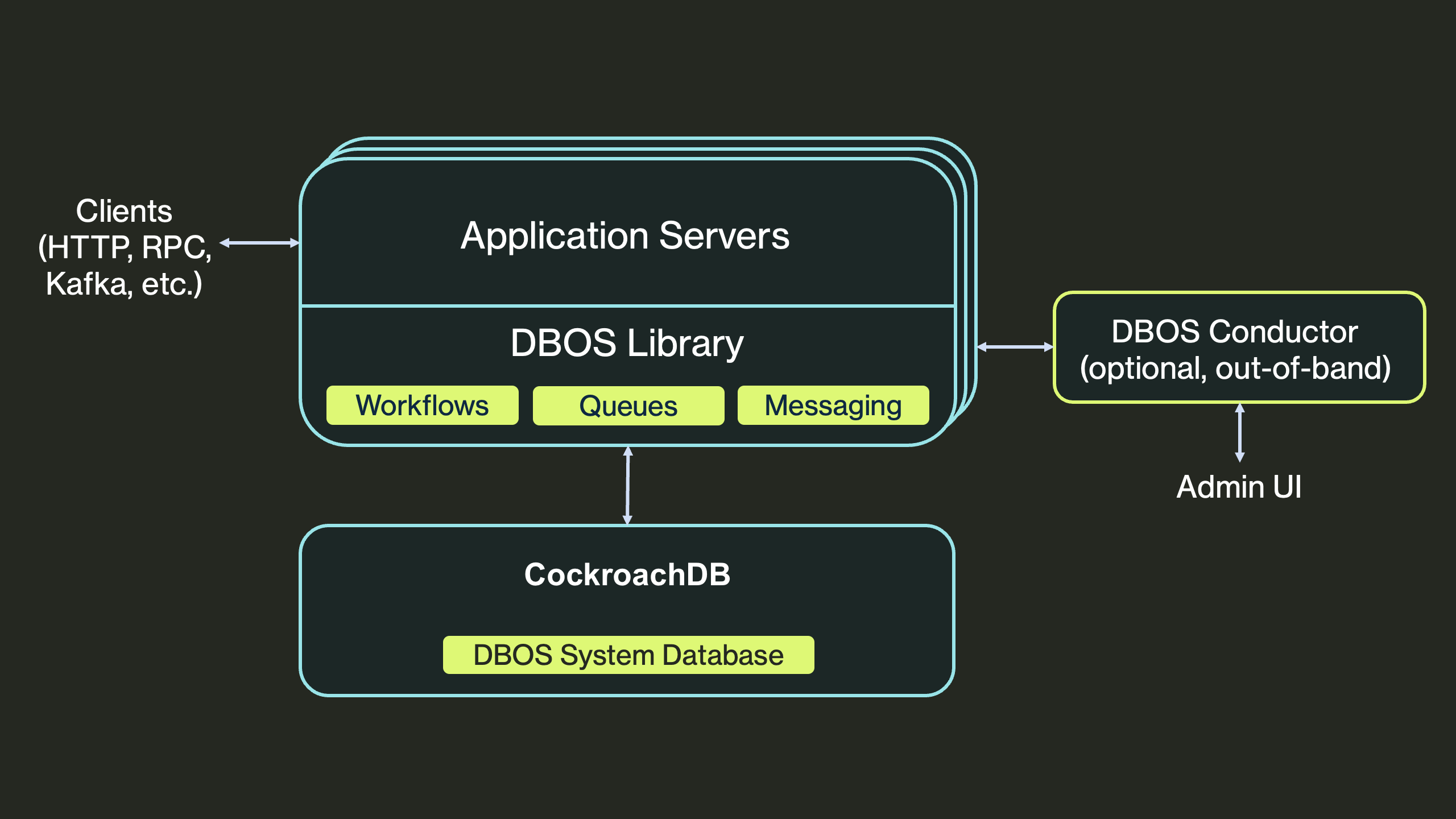
Conductor is out of band: application servers open outbound websocket connections to it for observability and recovery, never for workflow execution
Why CockroachDB for DBOS?
DBOS uses the PostgreSQL wire protocol, so it connects to CockroachDB directly without any driver changes. What CockroachDB adds over a single-node PostgreSQL is the persistence tier you always wanted but couldn’t justify operating separately:
- Serializable isolation: concurrent workflow executions never produce lost updates or phantom reads
- Multi-region active-active replication: workflow state is durable across data-center failures without manual intervention
- Horizontal scalability: the system database scales with your application without re-sharding
- Automatic failover: CockroachDB node failures are transparent to DBOS, which simply retries on the next available node
When DBOS connects to CockroachDB, it provisions three categories of tables in the system database:
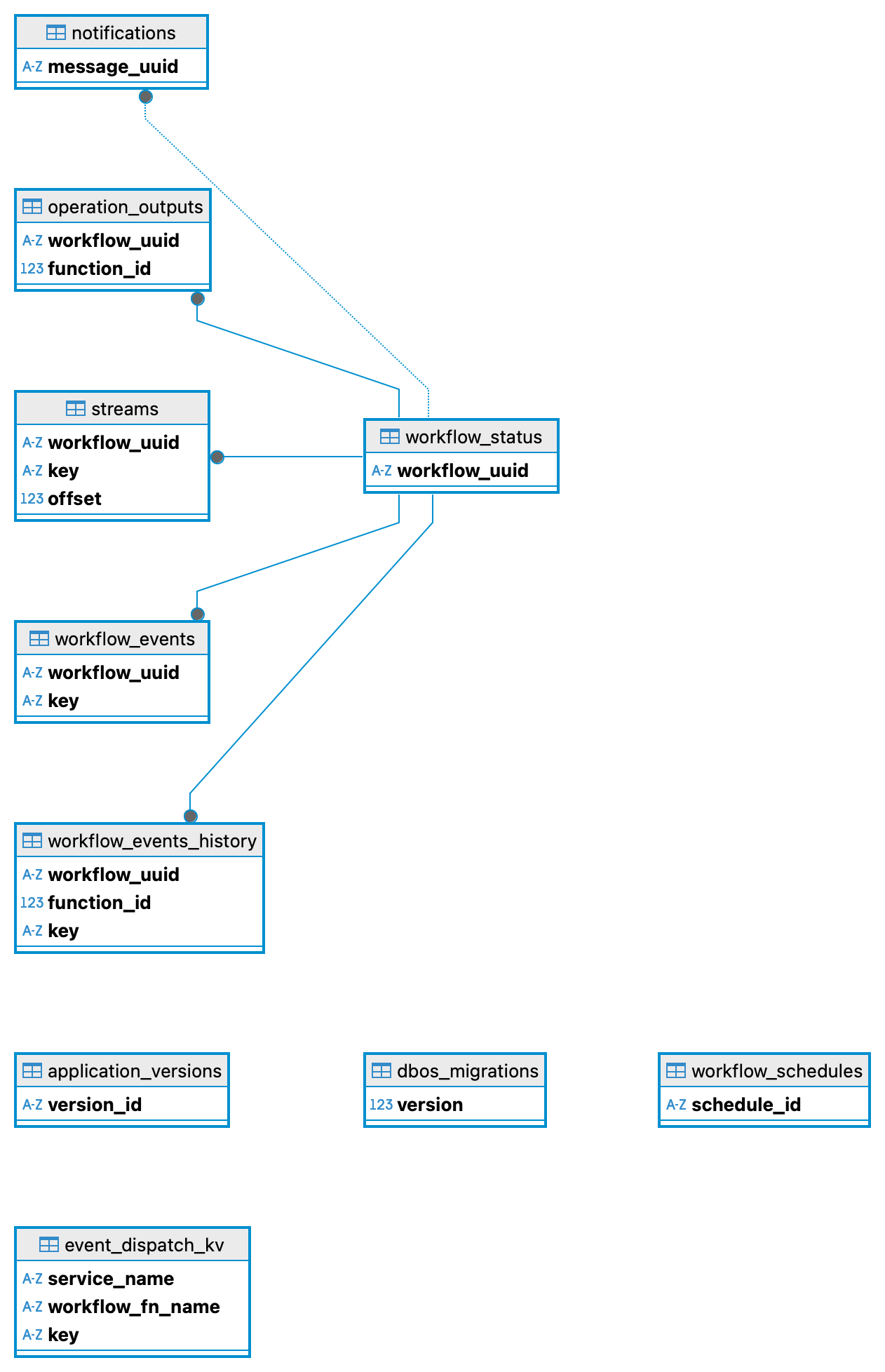
Tables created by DBOS in CockroachDB: workflow state, step outputs, and events, all in your existing database
- Workflow status table: one row per execution, tracking ID, status, and function inputs
- Operation outputs table: one row per completed step, storing the serialised return value for replay
- Events table: named key-value pairs published within workflows and consumed via
get_event
For teams that want globally resilient agentic workflows without the complexity of a Temporal cluster, DBOS + CockroachDB is the lowest-overhead path.
| Capability | DBOS + CockroachDB |
|---|---|
| No extra infrastructure | Durable execution runs inside your FastAPI / application process |
| Exactly-once steps | Steps never re-execute after their output is committed to CockroachDB |
| Idempotent launches | Same workflow ID always returns the existing execution |
| Global durability | CockroachDB multi-region replication protects workflow state across regions |
| Zero driver changes | PostgreSQL wire protocol; no CockroachDB-specific SDK required |
| Observable progress | set_event / get_event expose real-time step completion to frontends |
Deploying DBOS on CockroachDB
There are two required configuration changes when using CockroachDB instead of PostgreSQL.
Prerequisites
| Requirement | Details |
|---|---|
| Python 3.10+ | DBOS 2.x requires Python 3.10 or later |
| CockroachDB cluster | A running CockroachDB instance (local, CockroachDB Cloud, or self-hosted) |
| System database | A dedicated database for DBOS state; create it once: CREATE DATABASE dbos_system; |
| Python packages | dbos[otel], fastapi[standard], psycopg2-binary, sqlalchemy-cockroachdb, uvicorn |
pip install "dbos[otel]==2.15.0" "fastapi[standard]" psycopg2-binary sqlalchemy-cockroachdb
export DBOS_COCKROACHDB_URL="postgresql://<user>:<password>@<crdb-host>:26257/dbos_system?sslmode=verify-full&sslrootcert=/certs/ca.crt"
1. Disable LISTEN/NOTIFY
PostgreSQL’s LISTEN/NOTIFY mechanism is used by DBOS to wake up waiting workflows without polling. CockroachDB does not implement this mechanism, so it must be disabled explicitly; DBOS falls back to polling automatically:
from dbos import DBOS, DBOSConfig
from sqlalchemy import create_engine
import os
database_url = os.environ["DBOS_COCKROACHDB_URL"]
# SQLAlchemy's postgresql dialect cannot parse CockroachDB's version string;
# the cockroachdb dialect (sqlalchemy-cockroachdb) handles it correctly.
crdb_url = database_url.replace("postgresql://", "cockroachdb://", 1)
engine = create_engine(crdb_url)
config: DBOSConfig = {
"name": "my-agent-app",
"system_database_url": database_url,
# Pass a pre-built SQLAlchemy engine so DBOS uses the CockroachDB driver
"system_database_engine": engine,
# CockroachDB does not support LISTEN/NOTIFY; use polling instead
"use_listen_notify": False,
}
DBOS(config=config)
2. Set the system database URL
In dbos-config.yaml, point the system database at CockroachDB using the standard PostgreSQL connection string format:
name: my-agent-app
language: python
runtimeConfig:
start:
- python3 app/main.py
system_database_url: ${DBOS_COCKROACHDB_URL}
Set the environment variable with your CockroachDB connection string:
export DBOS_COCKROACHDB_URL="postgresql://dbos_user:password@<crdb-host>:26257/dbos_system?sslmode=verify-full&sslrootcert=/certs/ca.crt"
A Complete DBOS Agentic Workflow on CockroachDB
The following example implements a three-step durable agent workflow backed by CockroachDB. The workflow publishes progress events after each step that a frontend can poll in real time. If the process crashes mid-execution, restarting it resumes from the last completed step: no re-billing, no duplicate writes, no lost context.
import os
import time
import uvicorn
from dbos import DBOS, DBOSConfig, SetWorkflowID
from fastapi import FastAPI
from sqlalchemy import create_engine
app = FastAPI()
# ── CockroachDB connection ──────────────────────────────────────────────────
database_url = os.environ["DBOS_COCKROACHDB_URL"]
# Use cockroachdb:// dialect so SQLAlchemy can parse CockroachDB's version string
crdb_url = database_url.replace("postgresql://", "cockroachdb://", 1)
engine = create_engine(crdb_url)
config: DBOSConfig = {
"name": "agent-workflow",
"system_database_url": database_url,
"system_database_engine": engine,
"use_listen_notify": False, # Required: CockroachDB has no LISTEN/NOTIFY
}
DBOS(config=config)
STEPS_EVENT = "steps_event"
# ── Workflow steps ──────────────────────────────────────────────────────────
@DBOS.step()
def retrieve_context(task: str) -> str:
"""Step 1: retrieve relevant context from the knowledge base."""
time.sleep(3)
DBOS.logger.info(f"Context retrieved for: {task}")
return f"context_for_{task}"
@DBOS.step()
def call_agent(context: str) -> str:
"""Step 2: call the LLM/agent with the context."""
time.sleep(3)
DBOS.logger.info("Agent invocation completed")
return f"agent_response_given_{context}"
@DBOS.step()
def persist_result(response: str) -> None:
"""Step 3: write the agent's output to the application database."""
time.sleep(3)
DBOS.logger.info(f"Result persisted: {response}")
# ── Durable workflow ────────────────────────────────────────────────────────
@DBOS.workflow()
def agent_workflow(task: str) -> None:
context = retrieve_context(task)
DBOS.set_event(STEPS_EVENT, 1)
response = call_agent(context)
DBOS.set_event(STEPS_EVENT, 2)
persist_result(response)
DBOS.set_event(STEPS_EVENT, 3)
# ── HTTP endpoints ──────────────────────────────────────────────────────────
@app.post("/agent/{task_id}")
def start_agent(task_id: str, task: str) -> dict:
"""Idempotently launch a durable agent workflow."""
with SetWorkflowID(task_id):
DBOS.start_workflow(agent_workflow, task)
return {"workflow_id": task_id, "status": "started"}
@app.get("/agent/{task_id}/progress")
def get_progress(task_id: str) -> dict:
"""Poll workflow progress (0-3 completed steps)."""
try:
step = DBOS.get_event(task_id, STEPS_EVENT, timeout_seconds=0)
except KeyError:
return {"completed_steps": 0}
return {"completed_steps": step if step is not None else 0}
if __name__ == "__main__":
DBOS.launch()
uvicorn.run(app, host="0.0.0.0", port=8000)
Install dependencies and run:
pip install "dbos[otel]==2.15.0" "fastapi[standard]" psycopg2-binary sqlalchemy-cockroachdb
export DBOS_COCKROACHDB_URL="postgresql://dbos_user:pass@localhost:26257/dbos_system?sslmode=disable"
python3 app/main.py
Scalability Benchmarking
Test environment
All benchmarks ran from an EC2 instance co-located in AWS us-east-1, eliminating WAN overhead:
- PostgreSQL RDS 17:
db.m7i.24xlarge, 96 vCPU, 384 GB RAM, gp3 500 GiB, 16,000 IOPS, 1,000 MB/s throughput - CockroachDB 3 nodes:
3× m7i.8xlarge, 96 vCPU total, nodes spread across multiple us-east-1 AZs (genuine zone-redundant deployment)
Benchmark artefacts: all scripts and raw JSON results are published in the repository under
assets/bench/dbos-cockroachdb/:raw_write_bench.py·bench_direct.py·results_raw_pg.json·results_raw_crdb.json·results_pg.json·results_coloc.json
Step 1: Fact-check what the DBOS blog actually measured
The DBOS engineering team published a benchmark claiming 144K database writes per second on PostgreSQL (db.m7i.24xlarge, 96 vCPU, 384 GB RAM). Reading the methodology carefully reveals an important distinction: that figure measures raw INSERT throughput into a simple 3-column table, not end-to-end DBOS workflow completions. The benchmark client was co-located on the same host as the database, and the test performed bare INSERT statements with autocommit (no workflow orchestration, no step sequencing, no durability checkpointing).
We replicated this exact methodology on both PostgreSQL and CockroachDB to establish an honest baseline before comparing real workflow performance.
Raw write benchmark: 3-column table (id, val, ts), single-row INSERT per operation, autocommit, concurrent writers:
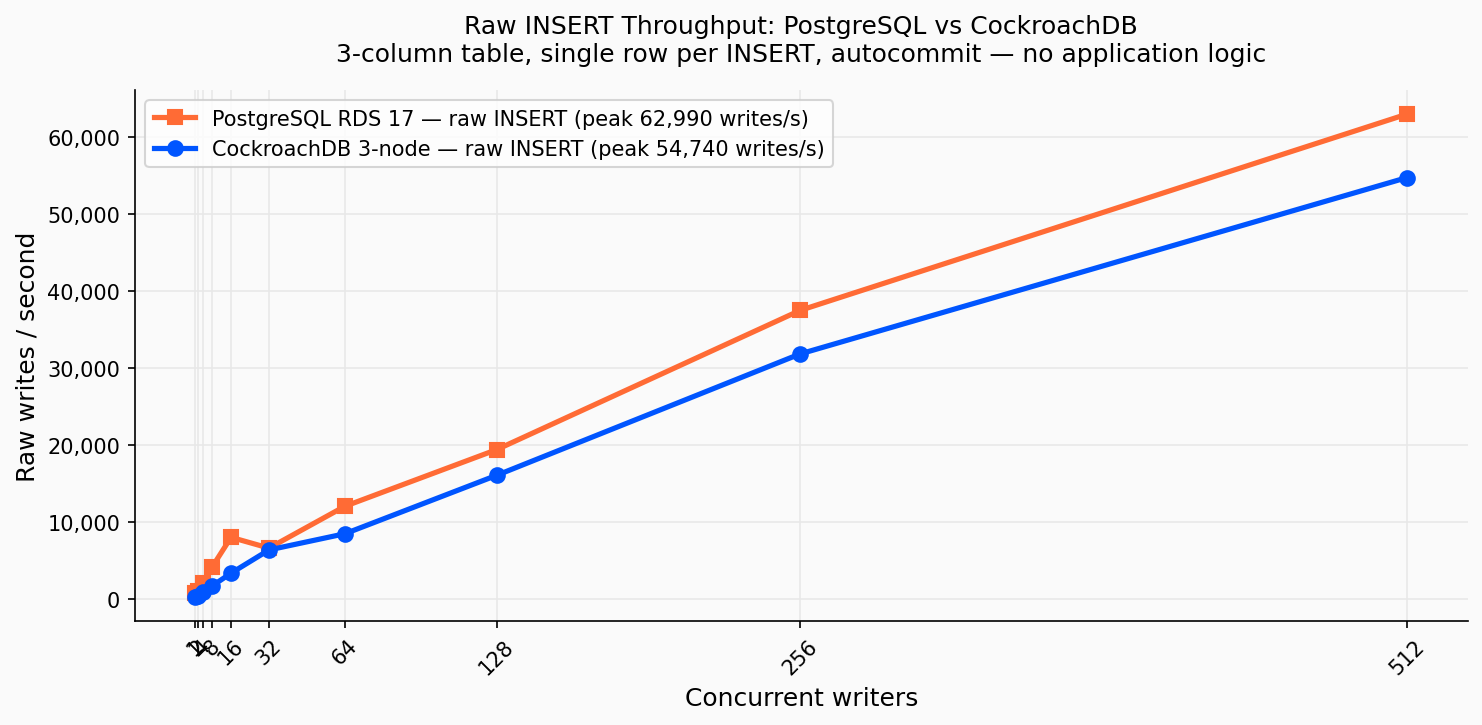
Raw INSERT peak: PostgreSQL 62,990 writes/s · CockroachDB 54,740 writes/s. PG is faster on raw writes; its local WAL flush (~1.9 ms p50) beats CockroachDB’s cross-AZ Raft quorum (~4–8 ms p50). Both are far below the DBOS blog’s 144K claim, which used a higher-IOPS storage configuration co-located with the benchmark client.
| Concurrency | PG writes/s | PG p50 (ms) | CRDB writes/s | CRDB p50 (ms) |
|---|---|---|---|---|
| 1 | 728 | 1.4 | 277 | 3.6 |
| 8 | 4,125 | 1.9 | 1,659 | 4.7 |
| 32 | 6,584 | 4.1 | 6,344 | 4.9 |
| 64 | 12,016 | 4.3 | 8,448 | 6.8 |
| 128 | 19,380 | 5.1 | 16,039 | 7.1 |
| 256 | 37,478 | 5.1 | 31,820 | 7.1 |
| 512 | 62,990 | 5.8 | 54,740 | 8.3 |
Our raw write numbers are lower than the DBOS blog’s 144K because their storage configuration had significantly higher provisioned IOPS and the benchmark client ran on the same host as the database (zero network round-trip). Our setup (EC2 client to RDS over the us-east-1 network, gp3 at 16K IOPS) reflects real-world deployment conditions, not a co-located best-case.
Step 2: Why raw writes ≠ workflow completions
A DBOS 2-step workflow is not a single INSERT. It produces 4 sequential, acknowledged database writes:
- Workflow start: inputs persisted before any step runs
- Step 1 output committed: return value stored for replay
- Step 2 output committed: return value stored for replay
- Workflow completion: final status updated
Critically, each write must be fully acknowledged before the next step begins. This is the durability guarantee: if the process crashes after step 1, step 2 is never re-executed. The sequential commit chain means workflow latency ≈ 4 × single-write latency; throughput does not scale with raw write capacity.
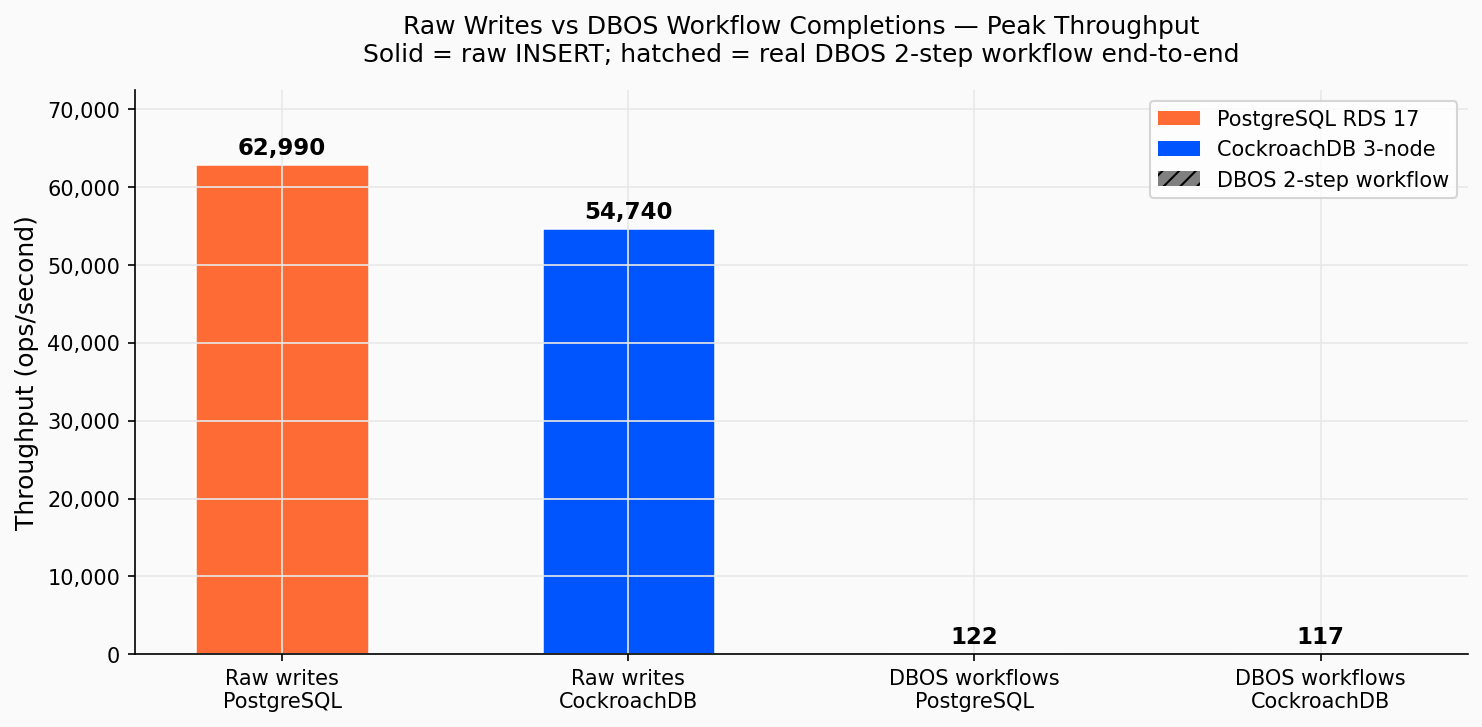
Raw writes vs actual DBOS workflow completions at peak throughput. The ~500× gap between raw writes and workflow throughput is not a bug; it is the cost of durable, exactly-once execution guarantees.
| Metric | PostgreSQL | CockroachDB (3 nodes) |
|---|---|---|
| Raw writes/s (peak) | 62,990 | 54,740 |
| DBOS workflows/s (peak) | 122 | 117.5 |
| Ratio (raw ÷ workflow) | ~516× | ~466× |
The ratio is the overhead of durable orchestration: every workflow completion serialises 4 round-trips through the database, each one waiting for acknowledgement before the next begins.
Step 3: Real DBOS Workflow Benchmark PostgreSQL vs CockroachDB
Results: Throughput PostgreSQL vs CockroachDB
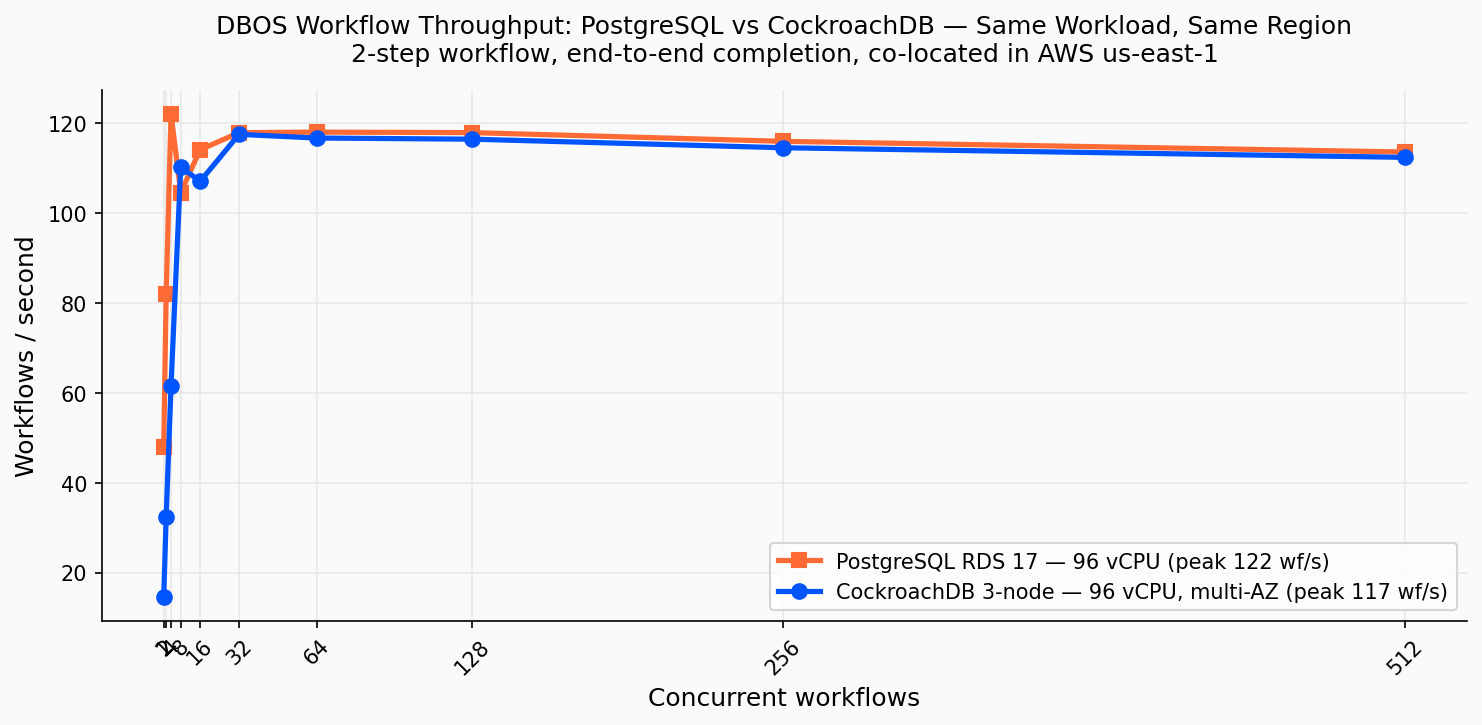
Both databases plateau at ~117 wf/s. PostgreSQL peaks faster (122 wf/s at c=4); CockroachDB reaches its 3-node ceiling at c=32 (117.5 wf/s). The bottleneck is the sequential step-commit pattern in DBOS, not the database engine.
Results: Latency PostgreSQL vs CockroachDB
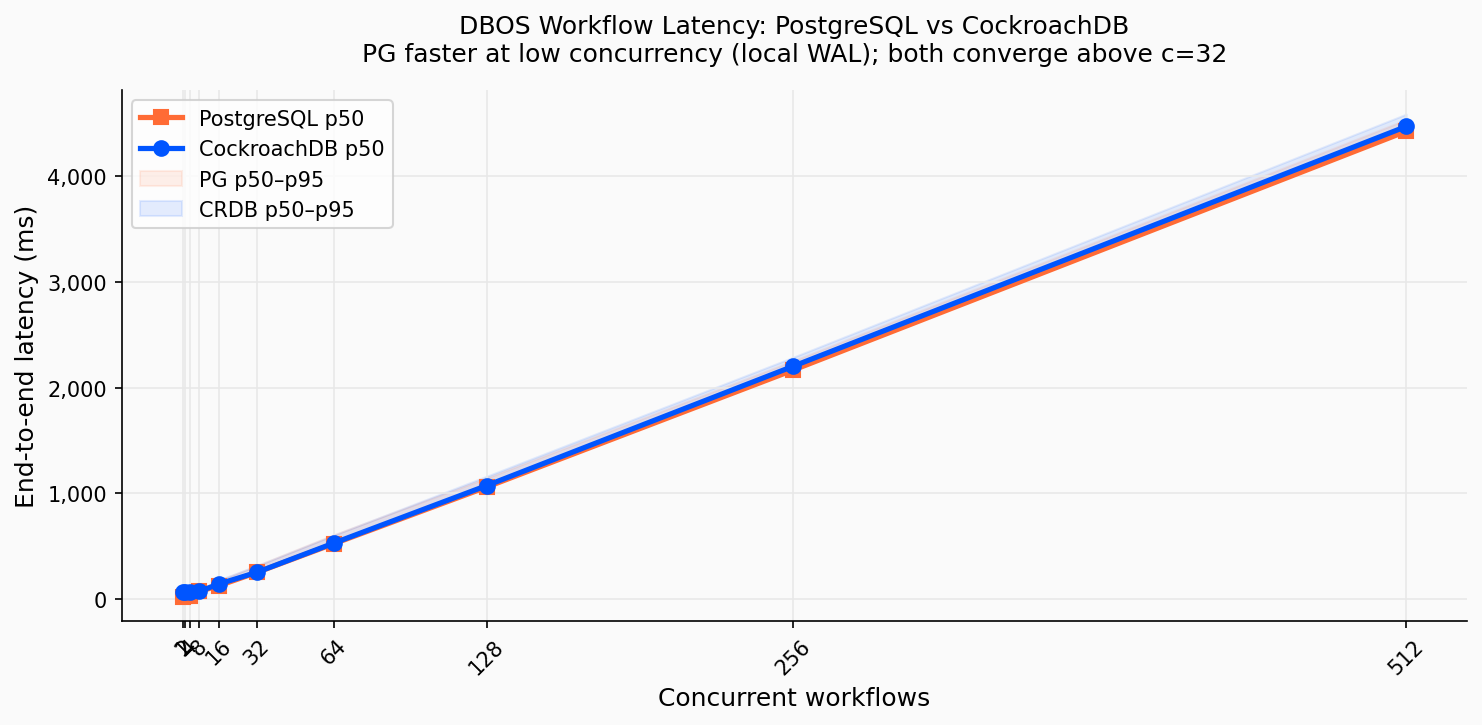
PostgreSQL is faster at low concurrency (19 ms p50 at c=1 (local WAL flush)). At c=8 both databases converge to identical p50: 69 ms. Above c=32 both plateau at ~250 ms; the sequential commit pattern dominates completely. Both benchmarks run at Read Committed isolation.
| Concurrency | PG wf/s | PG p50 (ms) | CRDB wf/s | CRDB p50 (ms) |
|---|---|---|---|---|
| 1 | 48.0 | 19 | 14.6 | 65 |
| 4 | 122.0 (peak) | 29 | 61.5 | 62 |
| 8 | 104.5 | 69 | 110.2 | 69 |
| 16 | 114.0 | 122 | 107.0 | 138 |
| 32 | 117.8 | 248 | 117.5 (peak) | 250 |
| 64 | 118.0 | 519 | 116.6 | 525 |
| 256 | 115.9 | 2,166 | 114.5 | 2,202 |
| 512 | 113.5 | 4,428 | 112.3 | 4,474 |
The scalability argument
Both databases saturate at ~117 wf/s under this DBOS workflow load : the bottleneck is DBOS’s sequential step-commit pattern, not the database. The difference is what happens when you need more than 117 wf/s.
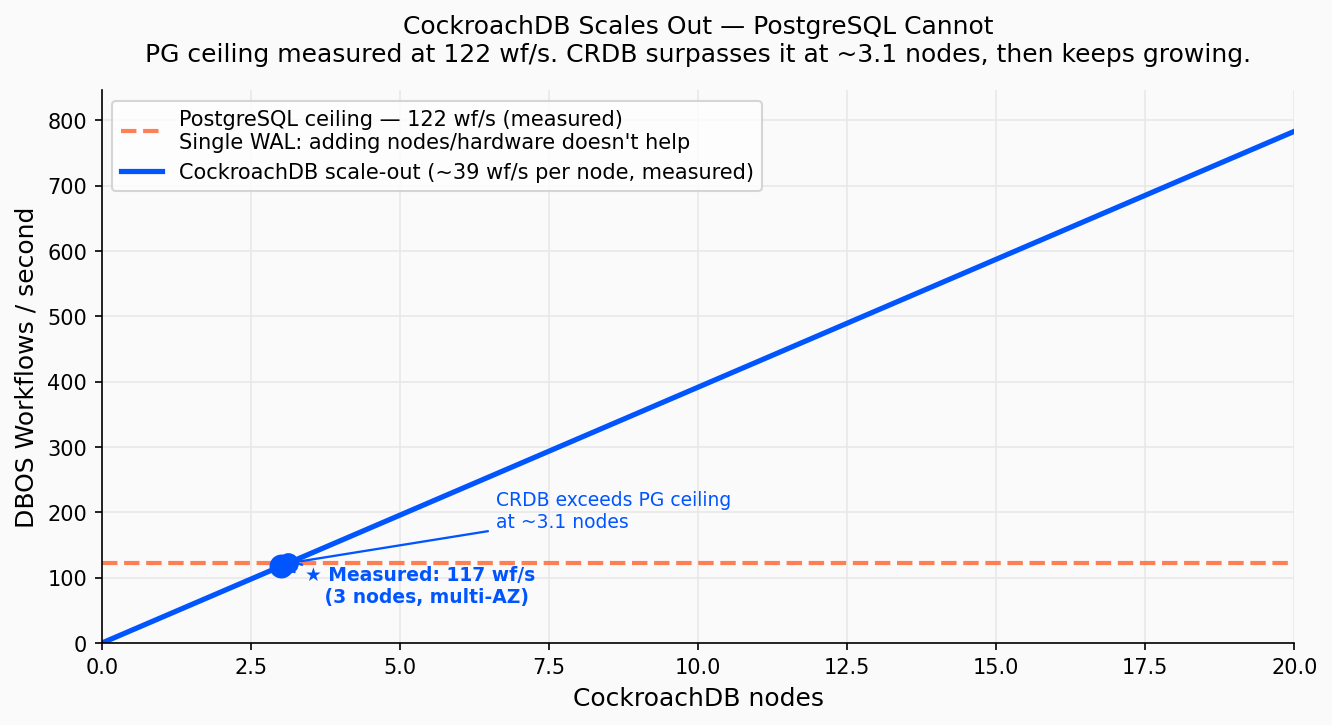
PostgreSQL’s ceiling is measured at 122 wf/s, a hard limit of its single-node WAL. CockroachDB surpasses that ceiling at just ~3.1 nodes and keeps scaling linearly. Each node adds ~39 wf/s.
PostgreSQL’s Write-Ahead Log serialises every write through a single flush path. Once that path is saturated, no additional hardware increases write throughput; you can scale reads with replicas, but writes are bounded by one node forever. CockroachDB replaces the single WAL with a distributed Raft log: each node flushes its own log, and writes are spread across the cluster. The throughput ceiling rises with every node you add.
With just 4 nodes, CockroachDB (~156 wf/s projected) already exceeds PostgreSQL’s measured ceiling. And it keeps scaling: 10 nodes means ~390 wf/s, with zone-redundant durability throughout.
Summary
| PostgreSQL RDS 17 (96 vCPU) | CockroachDB (3 nodes, multi-AZ) | CockroachDB (N nodes) | |
|---|---|---|---|
| Peak wf/s | 122 wf/s (measured) | 117.5 wf/s (measured) | ~39 × N wf/s |
| p50 at c=1 | 19 ms (local WAL) | 65 ms (Raft, cross-AZ) | ~65 ms |
| p50 at c=8 | 69 ms | 69 ms | ~69 ms |
| p50 at saturation (c=32+) | ~250 ms | ~250 ms | ~250 ms |
| Write scale-out | No (WAL is one node) | Yes | Yes (linear) |
| Node failure | Manual failover | Automatic | Automatic |
| Multi-region durability | External tooling | Built-in | Built-in |
Both benchmarks ran at Read Committed isolation. PostgreSQL’s advantage at low concurrency (19 ms vs 65 ms p50 at c=1) is purely the cost of Raft cross-AZ quorum; it disappears at c=8 where both databases land at identical 69 ms p50. At saturation both converge to ~250 ms. The decisive difference is what happens at scale: PostgreSQL has hit its ceiling, CockroachDB has not even started climbing.