
Le parcours de données ou la chaîne de valeur des données décrit les différentes étapes par lesquelles les données passent depuis leur création jusqu’à leur éventuelle suppression. Le parcours de données comprend de nombreuses étapes. Les principales sont l’ingestion, le stockage, le traitement, l’analyse et le service. Chaque étape a son propre ensemble d’activités et de considérations.
L’ingestion des données est la première étape du cycle de vie des données. C’est là que les données sont collectées à partir de diverses sources internes comme les bases de données, les CRM, les ERP, les systèmes legacy, et de sources externes telles que les enquêtes et les fournisseurs tiers.
Dans cet article, j’introduirai les principales activités de l’étape d’ingestion des données et l’importance de s’assurer que les données acquises sont exactes et à jour pour être utilisées efficacement dans les étapes suivantes du cycle.
Qu’est-ce que l’ingestion des données ?
L’ingestion des données est le processus de déplacement des données d’un endroit à un autre. L’ingestion des données implique le déplacement des données depuis les systèmes sources vers le stockage dans le parcours de données, avec l’ingestion comme étape intermédiaire.
Il est utile de contraster rapidement l’ingestion des données avec l’intégration des données. Alors que l’ingestion des données est le déplacement des données du point A au point B, l’intégration des données combine des données provenant de sources disparates en un nouvel ensemble de données. Par exemple, vous pouvez utiliser l’intégration des données pour combiner des données d’un système CRM, des données analytiques publicitaires et des données d’analyse web afin de créer un profil utilisateur, qui est enregistré dans votre data warehouse.
Activités d’ingestion des données
Dans cette étape, les données brutes sont extraites d’une ou plusieurs sources de données, répliquées, puis ingérées dans un support de stockage d’atterrissage. Vous devez ensuite prendre en compte les caractéristiques des données que vous souhaitez acquérir pour vous assurer que l’étape d’ingestion dispose de la bonne technologie et des bons processus pour atteindre ses objectifs. Comme je l’ai expliqué dans Data 101 - partie 1, les données ont quelques caractéristiques innées. Les plus pertinentes pour cette étape sont : le Volume, la Variété et la Vélocité.
La couche d’ingestion peut être décomposée en trois sous-couches :
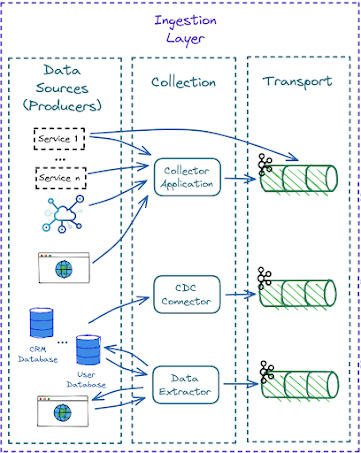 Couche d’ingestion ©SWIRLAI.
Couche d’ingestion ©SWIRLAI.
1 - Sources de données
Un système source de données est l’origine des données utilisées dans le parcours de données. Par exemple, un système source peut être un appareil IoT, une file de messages applicative ou une base de données transactionnelle. Un ingénieur de données consomme des données d’un système source, mais ne possède généralement pas ce système et n’en a pas le contrôle. En tant qu’ingénieur/architecte de données, vous devez comprendre comment les données sont produites et quelles options permettent de les connecter au système de données. Les contrats de données (Data Contracts) seront idéalement mis en œuvre ici.
Nous nous concentrons ici sur les différentes sources de données depuis lesquelles vous pouvez ingérer des données. Bien que je cite quelques méthodes courantes, rappelez-vous que l’univers des pratiques et des technologies d’ingestion des données est vaste et croît chaque jour.
- Connexion directe à une base de données : les données peuvent être extraites des bases de données pour l’ingestion en effectuant des requêtes et en lisant via une connexion réseau. Le plus souvent, cette connexion se fait via ODBC ou JDBC. ODBC utilise un pilote hébergé par un client accédant à la base de données pour traduire les commandes émises vers l’API ODBC standard en commandes émises vers la base de données. La base de données renvoie les résultats de la requête par le réseau, où le pilote les reçoit et les retraduit sous une forme standard lisible par le client. Pour l’ingestion, l’application utilisant le pilote ODBC est un outil d’ingestion. L’outil d’ingestion peut extraire des données via de nombreuses petites requêtes ou une seule grande requête. JDBC est conceptuellement très similaire à ODBC. Un pilote Java se connecte à une base de données distante et sert de couche de traduction entre l’API JDBC standard et l’interface réseau native de la base de données cible. Bien qu’avoir une API de base de données adaptée à un langage de programmation spécifique puisse sembler inhabituel, il existe des raisons convaincantes de le faire.
- Export de bases de données et de fichiers : il est important pour les ingénieurs de données de connaître la façon dont les systèmes de base de données sources gèrent l’export de fichiers. L’export de données implique une analyse extensive qui peut fortement solliciter la base de données, notamment dans les systèmes transactionnels. Les ingénieurs des systèmes sources doivent évaluer le moment le plus approprié pour effectuer ces analyses sans affecter négativement les performances de l’application. Ils peuvent choisir de mettre en œuvre des stratégies pour atténuer la charge. Une option consiste à décomposer les requêtes d’export en segments plus petits, soit en effectuant des requêtes sur des plages de clés ou des partitions individuelles. Une autre approche consiste à utiliser un réplica en lecture pour alléger la charge. Les réplicas en lecture sont particulièrement bénéfiques lorsque les exports de données se produisent fréquemment tout au long de la journée et coïncident avec des périodes de forte charge sur le système source.
- Les API deviennent de plus en plus critiques et populaires comme source de données. De nombreuses organisations peuvent avoir de nombreuses sources de données externes, telles que des plateformes SaaS ou des entreprises partenaires. Malheureusement, il n’existe pas de norme pour l’échange de données via les API, ce qui pose un défi. Les ingénieurs de données peuvent avoir à consacrer un temps considérable à l’étude de la documentation, à la communication avec les propriétaires de données externes et au développement et à la maintenance du code de connexion API.
- Les Webhooks sont parfois appelés API inverses. Dans une API REST traditionnelle, le fournisseur de données partage les spécifications de l’API avec les ingénieurs, qui écrivent ensuite le code pour l’ingestion des données. Le code envoie des requêtes à l’API et reçoit des données dans les réponses. En revanche, avec un webhook, le fournisseur de données définit une spécification de requête API, mais au lieu de recevoir des appels API, le fournisseur de données les effectue. Le consommateur de données est responsable de fournir un endpoint API que le fournisseur peut appeler. De plus, le consommateur doit ingérer chaque requête et gérer l’agrégation, le stockage et le traitement des données.
- Les interfaces web restent un moyen pratique d’accès aux données pour les ingénieurs de données. Cependant, il est courant que les ingénieurs de données se trouvent dans des situations où toutes les données et fonctionnalités d’une plateforme SaaS ne sont pas accessibles via des interfaces automatisées, telles que les API et les dépôts de fichiers. Dans de tels cas, les individus peuvent avoir à accéder manuellement à une interface web, générer un rapport et télécharger un fichier sur une machine locale. Cependant, cette approche présente des inconvénients évidents, comme des oublis d’exécution du rapport ou des problèmes techniques informatiques. Il est donc conseillé de sélectionner des outils et des workflows permettant un accès automatisé aux données dans la mesure du possible.
- Le web scraping est un processus automatisé d’extraction de données de pages web, généralement en analysant les différents éléments HTML de la page. Par exemple, cette technique peut être utilisée pour extraire des données de prix de produits sur des sites e-commerce ou pour agréger des articles d’actualité de plusieurs sources. En tant qu’ingénieur de données, vous pouvez rencontrer le web scraping dans votre travail. Cependant, le web scraping opère dans une zone floue où les limites éthiques et légales peuvent être floues.
- L’appliance de transfert : lorsqu’il s’agit de volumes massifs de données (100 To ou plus), le transfert de données via Internet peut être un processus lent et coûteux. À cette échelle, la façon la plus efficace de déplacer des données est souvent par des moyens physiques. De nombreux fournisseurs cloud offrent la possibilité d’envoyer vos données via un appareil physique appelé appliance de transfert. Pour utiliser ce service, vous commandez l’appliance de transfert, chargez vos données depuis vos serveurs sur l’appareil, puis renvoyez-le au fournisseur cloud qui téléchargera alors vos données dans le cloud.
- L’échange de données informatisé (EDI) : les ingénieurs de données rencontrent souvent l’échange de données informatisé (EDI) comme réalité pratique dans leur travail. Bien que le terme puisse faire référence à n’importe quelle méthode de déplacement de données, il fait généralement référence à des moyens d’échange de fichiers obsolètes, tels que l’e-mail ou les clés USB. Malheureusement, certaines sources de données peuvent uniquement prendre en charge ces méthodes obsolètes en raison de systèmes IT legacy ou de limitations des processus humains. Malgré cela, les ingénieurs peuvent améliorer l’EDI grâce à l’automatisation. Par exemple, ils peuvent configurer un serveur e-mail dans le cloud qui enregistre automatiquement les fichiers dans le stockage d’objets de l’entreprise à la réception. Cela déclenche des processus d’orchestration pour ingérer et traiter les données, ce qui est plus efficace et fiable que les employés téléchargeant et téléversant manuellement des fichiers vers les systèmes internes.
- Le partage de données devient une option populaire pour la consommation de données. Les fournisseurs offrent des ensembles de données à des abonnés tiers, soit gratuitement, soit à un coût. Ces ensembles de données sont généralement partagés dans un format en lecture seule, ce qui signifie qu’ils peuvent être intégrés aux données de l’abonné et à d’autres ensembles de données tiers. Cependant, l’abonné ne possède pas physiquement l’ensemble de données partagé. En ce sens, l’ingestion n’est pas considérée comme donnant à l’abonné une propriété complète de l’ensemble de données. Si le fournisseur révoque l’accès à l’ensemble de données, l’abonné n’y aura plus accès.
La caractéristique la plus importante de cette sous-couche reste la vélocité des données. En fait, les données se présentent sous deux formes : bornées et non bornées. Les données non bornées sont les données telles qu’elles existent dans la réalité, au fur et à mesure que les événements se produisent, de manière sporadique ou continue, en cours et en flux. Les données bornées sont une façon commode de regrouper les données sur une certaine limite, comme le temps.
 Données bornées vs. données non bornées.
Données bornées vs. données non bornées.
Toutes les données sont non bornées jusqu’à ce qu’elles soient bornées. En effet, les processus métier ont longtemps imposé des limites artificielles aux données en découpant des lots discrets. N’oubliez pas le vrai caractère non borné de vos données ; les systèmes d’ingestion en streaming sont simplement un outil pour préserver la nature non bornée des données afin que les étapes suivantes du cycle de vie puissent également les traiter en continu.
2 - Collecte des données
Les données produites par les sources de données seront rarement transmises directement en aval. Ce sous-système agit comme un proxy entre les sources externes et les systèmes de données. Vous verrez très probablement l’un des trois types de proxy suivants :
- Les collecteurs : des applications qui exposent un endpoint public ou privé vers lequel les producteurs de données peuvent envoyer des événements.
- Les connecteurs CDC : des applications qui se connectent aux journaux d’événements des bases de données backend et transmettent les mises à jour sélectionnées de la base de données vers le système de données.
- Les extracteurs : des applications écrites par des ingénieurs qui interrogent les systèmes externes comme les sites web pour détecter les changements et transmettent les données en aval.
Pour la collecte des données, trois patterns sont pertinents : les modèles Push, Pull et Poll. Dans le modèle push d’ingestion des données, un système source écrit des données vers une cible, qu’il s’agisse d’une base de données, d’un store d’objets ou d’un système de fichiers.
Dans le modèle pull, les données sont récupérées du système source. La frontière entre les paradigmes push et pull peut être assez floue ; les données sont souvent poussées et tirées au fur et à mesure qu’elles traversent les différentes étapes d’un pipeline de données.
Un autre pattern lié au pull est le polling. Le polling consiste à vérifier périodiquement une source de données pour détecter tout changement. Lorsque des changements sont détectés, la destination extrait les données comme dans une situation de pull normale.

Considérons, par exemple, le processus ETL (extract, transform, load) couramment utilisé dans les workflows d’ingestion orientés batch. La partie extraction (E) de l’ETL indique clairement que nous utilisons un modèle d’ingestion pull. Dans l’ETL traditionnel, le système d’ingestion interroge un instantané de la table source actuelle selon un calendrier fixe.
Dans un autre exemple, considérons le CDC continu, réalisé de différentes manières. Une méthode courante déclenche un message chaque fois qu’une ligne est modifiée dans la base de données source. Ce message est poussé vers une file d’attente, où le système d’ingestion le récupère.
Une autre méthode CDC courante utilise les journaux binaires, qui enregistrent chaque commit dans la base de données. La base de données pousse vers ses journaux. Le système d’ingestion lit les journaux mais n’interagit pas directement avec la base de données autrement. Cela ajoute peu ou pas de charge supplémentaire à la base de données source.
Certaines versions du CDC par lots utilisent le modèle pull. Par exemple, dans le CDC basé sur les horodatages, un système d’ingestion interroge la base de données source et extrait les lignes modifiées depuis la dernière mise à jour.
Un autre aspect important de la collecte de données est le niveau de couplage entre la source et la cible. Avec l’ingestion synchrone, la source, l’ingestion et la destination sont étroitement couplées avec des dépendances complexes. Chaque étape du parcours de données a des processus directement dépendants les uns des autres. Si un processus en amont échoue, les processus en aval ne peuvent pas démarrer. Ce type de workflow synchrone est courant dans les anciens systèmes ETL, où les données extraites d’un système source doivent d’abord être transformées avant d’être chargées dans un data warehouse. Les processus en aval de l’ingestion ne peuvent pas démarrer tant que toutes les données du lot n’ont pas été ingérées. Si le processus d’ingestion ou de transformation échoue, l’ensemble du processus doit être relancé.
Avec l’ingestion asynchrone, les dépendances peuvent désormais opérer au niveau des événements individuels, tout comme dans un backend logiciel construit à partir de microservices. Les événements individuels deviennent disponibles dans le stockage dès qu’ils sont ingérés individuellement. Prenons l’exemple d’un capteur qui émet des températures dans un backend de files de messages (agissant ici comme tampon). Le flux est lu par un système de traitement en flux, qui analyse et enrichit les événements (par ex., avec des données de géolocalisation) puis les transmet à un système publisher/subscriber (PubSub) qui notifie les abonnés lorsque la température dépasse un certain seuil. Aucun de ces systèmes n’est étroitement couplé à un autre. Si un capteur tombe en panne, le reste de l’architecture reste opérationnel pour gérer les données provenant des autres capteurs.
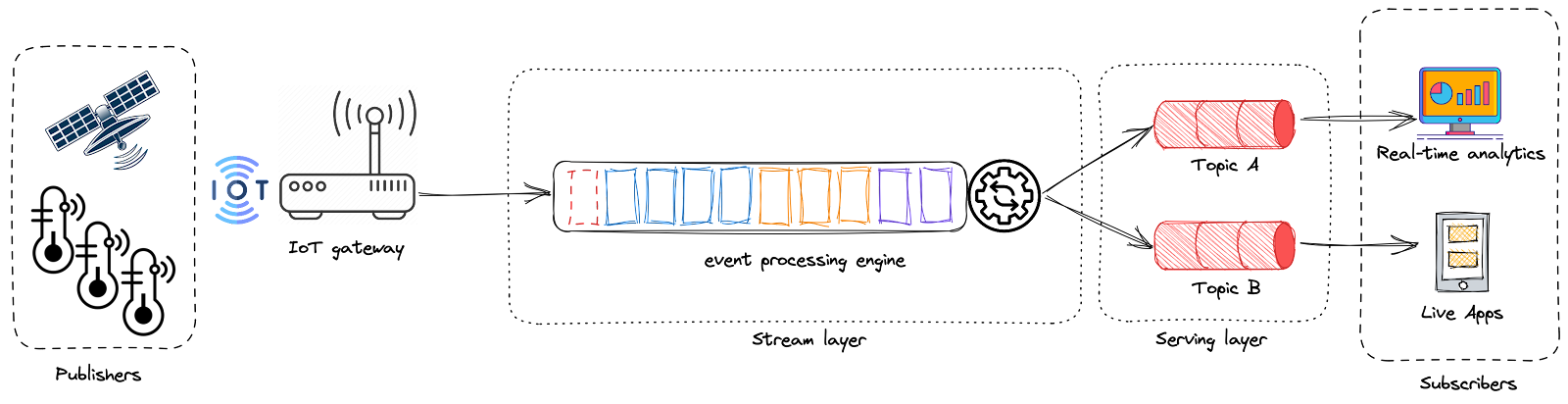
3 - Mouvement des données
Dans la plupart des cas, vous verrez un système de messagerie distribué avant que les données ne se déplacent en aval. De plus, la validation des données peut se produire à cette étape pour alléger les calculs effectués plus bas dans la chaîne de valeur des données. Nous utilisons souvent de manière interchangeable les termes mouvement des données et ingestion des données lorsque nous discutons de la vélocité de l’acquisition des données.
Le déplacement des données de la source vers la destination implique la sérialisation et la désérialisation. Pour rappel, la sérialisation signifie l’encodage des données à partir d’une source et la préparation des structures de données pour la transmission et les étapes de stockage intermédiaire.
Lors de l’ingestion des données, assurez-vous que votre destination peut désérialiser les données qu’elle reçoit. Nous avons vu des données ingérées depuis une source, mais restant inertes et inutilisables dans la destination parce qu’elles ne peuvent pas être correctement désérialisées. Nous parlerons des formats de sérialisation en détail dans l’article sur le traitement des données.
Bien que la plupart des outils d’ingestion puissent gérer un volume élevé de données avec une large gamme de formats (structurés, non structurés…), ils diffèrent dans leur capacité à gérer la vélocité des données. En conséquence, nous distinguons souvent trois catégories principales de mouvement des données : basé sur les lots (batch), en temps réel ou basé sur les flux (stream), et hybride.
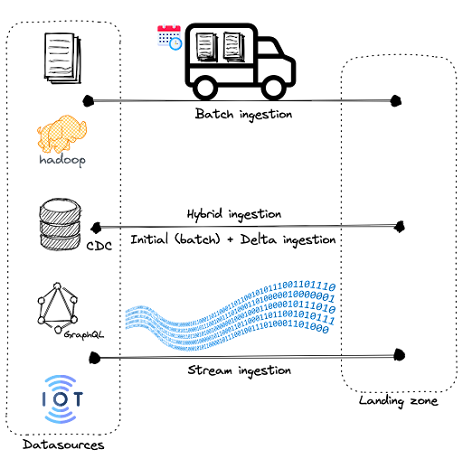 Types de mouvement des données.
Types de mouvement des données.
A. Mouvement des données par lots (Batch)
Le mouvement des données par lots est le processus de collecte et de transfert de données en masse selon des intervalles planifiés. La couche d’ingestion peut collecter des données basées sur des planifications simples, des événements déclencheurs ou tout autre ordonnancement logique. Cela signifie que les données sont ingérées en prenant un sous-ensemble de données d’un système source basé soit sur un intervalle de temps, soit sur la taille des données accumulées. L’ingestion par lots peut être utile pour les entreprises qui ont besoin de collecter des points de données spécifiques quotidiennement ou qui ne nécessitent pas de données pour une prise de décision en temps réel.
L’ingestion par lots à intervalles de temps est répandue dans l’ETL traditionnel pour le data warehousing. Ce pattern est souvent utilisé pour traiter les données une fois par jour, la nuit pendant les heures creuses, pour fournir des rapports quotidiens, mais d’autres fréquences peuvent également être utilisées.
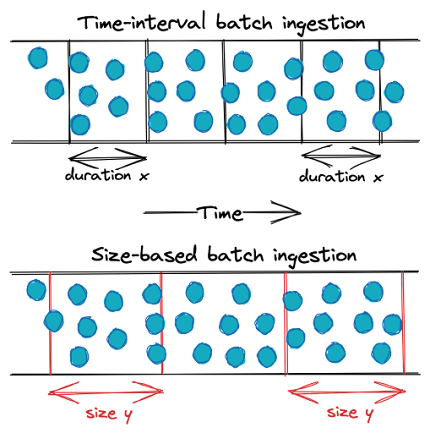 Ingestion par lots : intervalle de temps vs. taille.
Ingestion par lots : intervalle de temps vs. taille.
L’ingestion par lots basée sur la taille est assez courante lorsque des données sont déplacées d’un système de streaming vers un stockage d’objets ; en fin de compte, vous devez découper les données en blocs discrets pour un traitement futur dans un data lake. Certains systèmes d’ingestion basés sur la taille peuvent diviser les données en objets selon divers critères, tels que la taille en octets du nombre total d’événements.
Lors de la mise en œuvre de l’ingestion par lots, les ingénieurs de données doivent prendre en compte quelques points, tels que les instantanés versus l’extraction différentielle, quelle action précède l’autre : transformation ou chargement (ETL vs. ELT), la taille des lots et les contraintes de migration des données…

B. Mouvement des données en flux (Stream)
Le mouvement en temps réel ou par flux est essentiel pour que les organisations puissent répondre rapidement aux nouvelles informations dans des cas d’usage sensibles au temps, tels que le trading boursier ou la surveillance de capteurs. De plus, l’acquisition de données en temps réel est vitale lors de prises de décisions opérationnelles rapides ou d’actions sur des insights récents.
Les systèmes de messagerie publish-subscribe (PubSub) sont pertinents ici, permettant aux applications en temps réel de communiquer leurs données en publiant des messages. Les destinataires sont des abonnés de ces systèmes et reçoivent les données dès qu’elles sont publiées par la source de données. Ces types d’outils doivent être hautement scalables et tolérants aux pannes pour gérer de grands volumes de données.
Lors de la mise en œuvre de l’ingestion en flux, les ingénieurs de données doivent prendre en compte quelques points tels que l’évolution du schema, les données arrivant en retard, les données hors ordre, la relecture des données, le temps de vie (TTL), la taille des messages et la gestion des échecs (par ex., les files de lettres mortes (Dead-Letter queues))…
C. Mouvement des données hybride
Le mouvement des données hybride est une configuration incrémentale qui comprend à la fois des méthodes par lots et en flux. Il effectue une fonction delta entre la cible et la(les) source(s) et évalue les informations manquantes. Initialement, il n’y a pas de données dans la cible. Ainsi, l’outil d’ingestion hybride extrait un instantané des sources de données et le transfère vers la zone d’atterrissage en tant que lot. Une fois le chargement initial terminé, il ingère les données supplémentaires sous forme de flux.

L’un des outils les plus utilisés dans cette catégorie est la capture des changements de données (CDC). Le CDC surveille en permanence les journaux de transactions de la base de données ou les journaux redo et déplace les données modifiées sous forme de flux sans interférer avec la charge de travail de la base de données.
Activités transversales de l’ingestion des données
L’ingénierie des données a évolué au-delà des outils et de la technologie et comprend désormais une variété de pratiques et de méthodologies visant à optimiser l’ensemble du parcours de données, telles que la gestion des données, l’optimisation des coûts et des pratiques plus récentes comme le DataOps.
Ces activités transversales sont importantes pour s’assurer que l’ingestion des données est effectuée de manière efficace. En gérant les données efficacement, en optimisant les coûts et en adoptant les meilleures pratiques comme le DataOps, les ingénieurs de données peuvent s’assurer que les données qu’ils ingèrent sont exactes, fiables et disponibles pour ceux qui en ont besoin quand ils en ont besoin.
-
Sécurité : le déplacement des données introduit des vulnérabilités de sécurité car vous devez transférer des données entre des emplacements. La dernière chose que vous souhaitez est de capturer ou de compromettre les données lors de leur déplacement. Considérez où vivent les données et où elles vont. Les données qui doivent se déplacer au sein de votre VPC doivent utiliser des endpoints sécurisés et ne jamais quitter le périmètre du VPC.
-
Optimisation des coûts : tenez compte des coûts supplémentaires liés au transfert de données de la source vers la cible. Ces coûts peuvent rapidement devenir un obstacle pour toute initiative de données. Comme la sécurité, le mouvement des données est critique et son coût doit être analysé et évalué avant de décider quels outils et technologies d’ingestion vous choisissez.
-
Gestion des données est un aspect essentiel du parcours de données, et elle commence dès l’étape d’ingestion des données. Les ingénieurs de données doivent être attentifs à divers aspects de la gestion des données, notamment la lignée des données, le catalogage, les changements de schema, l’éthique, la confidentialité et la conformité lors de l’ingestion des données. Cela garantit que les données sont bien organisées, facilement accessibles et conformes aux exigences réglementaires. De plus, en mettant en œuvre des pratiques efficaces de gestion des données, les ingénieurs de données peuvent s’assurer que les données sont disponibles pour l’analyse et la prise de décision, soutenant ainsi les objectifs métier.
-
DataOps : la surveillance est essentielle pour garantir la fiabilité des pipelines de données. Une surveillance appropriée permet de détecter les problèmes et les défaillances du pipeline au fur et à mesure qu’ils se produisent, permettant une résolution rapide et empêchant les dépendances en aval d’être affectées. De plus, la surveillance peut aider à identifier les domaines d’amélioration et d’optimisation, conduisant à des pipelines de données plus fiables dans l’ensemble. Dans l’étape d’ingestion, la surveillance est particulièrement critique car tout problème ou défaillance peut avoir un effet d’entraînement sur le reste du parcours de données.
-
Qualité des données : l’observabilité des données est importante pour réaliser la qualité des données et renforcer la confiance des parties prenantes. Elle fournit une vue continue des données et des processus de données. Cependant, avoir des insights sur la fiabilité de vos pipelines n’est pas suffisant. Vous devez envisager d’établir un contrat de données avec un SLA avec les fournisseurs en amont. Un SLA fournit des attentes sur ce que vous pouvez attendre des systèmes sources sur lesquels vous vous appuyez. Je ferai référence à la définition des contrats de données de James Denmore : « Un contrat de données est un accord écrit entre le propriétaire d’un système source et l’équipe qui ingère des données de ce système pour les utiliser dans un pipeline de données. Le contrat doit indiquer quelles données sont extraites, via quelle méthode (complète, incrémentale), à quelle fréquence, et qui (personne, équipe) sont les contacts pour le système source et l’ingestion. Les contrats de données doivent être stockés dans un emplacement bien connu et facile à trouver, comme un dépôt GitHub ou un site de documentation interne. Si possible, formatez les contrats de données sous une forme standardisée afin qu’ils puissent être intégrés dans le processus de développement ou interrogés par programmation. »
-
Orchestration : à mesure que la complexité des pipelines de données augmente, un système d’orchestration robuste devient essentiel. Dans ce contexte, la véritable orchestration désigne un système capable de planifier des graphes de tâches entiers plutôt que des tâches individuelles. Avec un tel système, chaque tâche d’ingestion peut être lancée au moment planifié approprié, et les étapes de traitement et de transformation en aval peuvent démarrer dès que les tâches d’ingestion sont terminées. Cela conduit à un effet en cascade où les étapes de traitement déclenchent des étapes de traitement supplémentaires en aval.
Résumé
L’article discute de l’importance de l’ingestion des données dans le cycle de vie du parcours de données. L’article met en évidence les divers défis auxquels les ingénieurs de données peuvent être confrontés lors de l’ingestion des données, tels que la vélocité des données, la qualité des données, l’accès aux données et la disparité des sources. Il discute également des différentes sous-couches pour l’ingestion et comment choisir les bons outils et technologies pour garantir une ingestion efficace des données.
Il souligne également l’importance de surveiller correctement et de mettre en place des contrats de données pour assurer la fiabilité des données, une meilleure qualité des données et une réponse efficace aux incidents. Enfin, il discute du rôle de la gestion des données dans l’ingestion des données, notamment le catalogage des données, les changements de schema et la conformité aux réglementations sur l’éthique et la confidentialité.
Références
- James Denmore, Data Pipelines Pocket Reference: Moving and Processing Data for Analytics (O’Reilly 2021).
- Reis, J. and Housley, M. Fundamentals of data engineering: Plan and build robust data systems. O’Reilly Media (2022).
- “Decomposing the Data System”, Aurimas Griciūnas (SwirlAI).