
Le parcours de données ou la chaîne de valeur des données décrit les différentes étapes par lesquelles les données passent depuis leur création jusqu’à leur éventuelle suppression. Le parcours de données comprend de nombreuses étapes. Les principales sont l’ingestion, le stockage, le traitement et le service. Chaque étape a son propre ensemble d’activités et de considérations.
Le stockage des données désigne la façon dont les données sont conservées une fois qu’elles ont été acquises. Bien que le stockage soit une étape distincte du parcours de données, il s’intersecte avec d’autres phases comme l’ingestion, la transformation et le service. Le stockage s’étend à l’ensemble du parcours de données, apparaissant souvent à plusieurs endroits dans un pipeline de données, avec des systèmes de stockage qui se recoupent avec les systèmes sources, l’ingestion, la transformation et le service. À bien des égards, la façon dont les données sont stockées influence leur utilisation à toutes les étapes du parcours de données.
Pour comprendre le stockage, nous commencerons par étudier les différents niveaux d’abstraction du stockage et ses caractéristiques, telles que le cycle de vie du stockage (comment les données vont évoluer), les options de stockage (comment les données peuvent être stockées efficacement), les couches de stockage, les formats de stockage (comment les données doivent être stockées en fonction de la fréquence d’accès) et les technologies de stockage dans lesquelles les données sont conservées.
Niveaux d’abstraction du stockage
Le « stockage » signifie différentes choses pour différents utilisateurs. Lorsque nous parlons de stockage, certaines personnes pensent à la façon dont les données sont stockées physiquement ; certains se concentrent sur la matière première qui supporte les systèmes de stockage, tandis que d’autres pensent au système ou à la technologie de stockage pertinente pour leur cas d’usage. Tous ces niveaux sont des attributs importants du stockage, mais ils se concentrent sur différents niveaux d’abstraction.
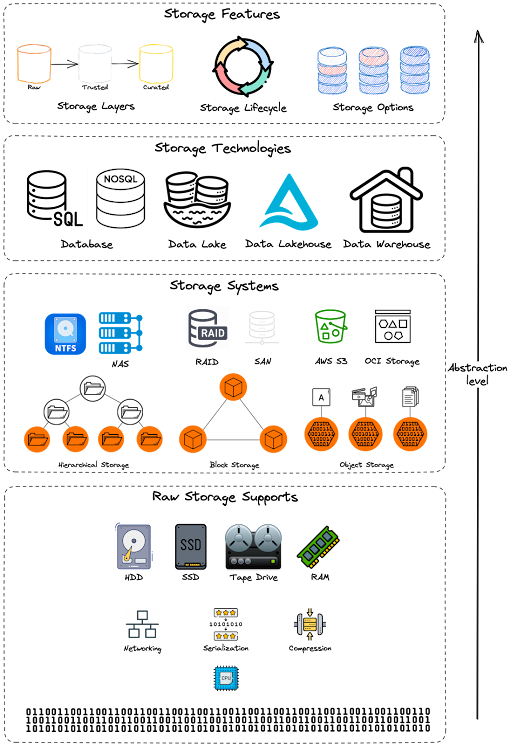 Abstractions de stockage.
Abstractions de stockage.
Bien que certains niveaux d’abstraction du stockage soient hors du contrôle des ingénieurs de données, il est essentiel de comprendre leurs caractéristiques de base pour évaluer les compromis inhérents à toute architecture de stockage. Les sections suivantes discutent des différents niveaux d’abstraction du stockage.
Comment les données sont-elles stockées ?
La plupart des références utilisent le nombre d’octets comme mesure de la capacité de stockage. Les données à traiter sont codées sous forme binaire (base 2) en utilisant divers schémas d’encodage décrits ci-dessous :
- Pour commencer, les chiffres 0 et 1 sont des chiffres binaires, et chacun est appelé un bit en abrégé : 0 représente un état ÉTEINT et 1 représente un état ALLUMÉ.
- Étant donné n bits contenus dans un support de stockage, il y a 2n (lire « 2 à la puissance n ») façons d’arranger les zéros et les uns, par exemple, avec 2 chiffres binaires (1 ou 0), les arrangements peuvent être l’une des quatre (22 ou 2x2 ou 4) possibilités - 00, 01, 10 et 11.
- L’industrie s’est établie sur une séquence de 8 bits (portant le nom d’octet ou byte) comme unité de stockage de base.
- Le terme octet précédé d’un préfixe exprime la capacité de stockage.
Unités de mesure de la capacité de stockage des données :
| 1 Bit | = 1 Chiffre binaire |
| 4 Bits | = 1 Nibble |
| 8 Bits | = 1 Octet (Byte) |
| 210= 1024 Octets | = 1 Kilooctet |
| 220= 1024 Kilooctets | = 1 Mégaoctet |
| 230= 1024 Mégaoctets | = 1 Gigaoctet |
| 240= 1024 Gigaoctets | = 1 Téraoctet |
| 250= 1024 Téraoctets | = 1 Pétaoctet |
Support de stockage brut
Le stockage est omniprésent, ce qui rend facile d’oublier son importance. Par exemple, de nombreux ingénieurs logiciels et de données utilisent le stockage quotidiennement, mais ils peuvent avoir besoin d’acquérir plus de connaissances sur son fonctionnement et les compromis impliqués avec différents supports de stockage.

Les données dans les parcours de données passent généralement par divers supports de stockage tels que les disques magnétiques, les SSD et la mémoire lors des différentes étapes du pipeline de données. Les systèmes de stockage et de requête sont complexes et nécessitent des systèmes distribués, plusieurs couches de stockage matériel et de nombreux services pour fonctionner efficacement. Ces systèmes nécessitent les bons composants pour fonctionner correctement. Il est donc crucial de comprendre ces systèmes sous-jacents et les éléments nécessaires pour assurer un traitement des données efficace. Voici les différents composants qui fonctionnent de manière harmonieuse pour fournir un support de stockage :
- CPU : pourquoi mentionnons-nous le CPU comme support de stockage de données brutes ? Le CPU (Central Processing Unit) est responsable de la gestion du mouvement et de l’accès aux données depuis le support de stockage (HDD, SDD…) vers la mémoire et de l’exécution des opérations sur celles-ci. Le CPU utilise des opérations d’entrée/sortie (E/S) pour lire et écrire des données depuis le stockage, et effectue des opérations de données sur les données chargées en mémoire. Donc la prochaine fois que vous pensez au débit de stockage (le nombre d’opérations par seconde que vous pouvez effectuer sur le stockage), vous avez affaire au CPU.
- Réseau : les considérations réseau jouent un rôle crucial dans la conception et la mise en œuvre des architectures de données, et il est important que les ingénieurs de données comprennent clairement leur impact. Ils doivent naviguer dans les compromis entre la distribution géographique des données pour une meilleure durabilité et disponibilité versus le maintien du stockage des données à proximité de ses utilisateurs ou producteurs pour de meilleures performances et rentabilité.
- Sérialisation : typiquement, les données stockées dans la mémoire système par un logiciel ne sont pas dans un format adapté au stockage sur disque ou à la transmission réseau. Pour y remédier, les données sont sérialisées, ce qui implique de les aplatir et de les compacter dans un format standardisé pouvant être décodé par un lecteur. Les formats de sérialisation fournissent un standard commun d’échange de données, mais chaque choix comporte ses propres compromis. Les ingénieurs de données doivent donc sélectionner soigneusement le format de sérialisation et le configurer pour optimiser les performances selon des exigences spécifiques.
- Compression : la compression est un aspect crucial de l’ingénierie du stockage car elle peut réduire considérablement la taille des données. Cependant, les algorithmes de compression peuvent également interagir avec d’autres détails du système de stockage de manière complexe. Une compression hautement efficace offre trois avantages principaux dans les systèmes de stockage. Premièrement, les données compressées occupent moins d’espace sur le disque. Deuxièmement, la compression améliore la vitesse de balayage pratique par disque. Par exemple, avec un ratio de compression de 10:1, le taux effectif passe de 200 Mo/s par disque magnétique à 2 Go/s par disque. Le troisième avantage concerne les performances réseau. Un ratio de compression de 10:1 peut augmenter la bande passante réseau effective de 10 gigabits par seconde (Gbps) à 100 Gbps, surtout lors du transfert de données entre systèmes. La compression présente aussi des inconvénients. La compression et la décompression des données entraînent une consommation CPU supplémentaire pour lire ou écrire des données.
En plus de ces composants, un ou plusieurs supports de stockage peuvent être mis en œuvre pour fournir la capacité de stockage ; voici une courte liste des plus utilisés :
- Disque dur magnétique (HDD) : un type de dispositif de stockage qui utilise des disques rotatifs recouverts d’un matériau ferromagnétique pour stocker des données. Les disques tournent à grande vitesse tandis que les têtes de lecture/écriture se déplacent de part et d’autre de la surface du disque pour lire et écrire des données. Lorsque des données sont écrites sur un disque magnétique, un courant électrique est utilisé pour magnétiser de minuscules points sur la surface du disque. Ces points représentent les données stockées. Lorsque des données sont lues depuis le disque, les têtes de lecture/écriture utilisent des signaux électriques pour détecter les champs magnétiques sur la surface du disque et les traduire en données numériques lisibles par l’ordinateur.

Malgré les avancées en matière de capacité des disques durs (HDD), leurs performances sont limitées par des contraintes physiques. L’une de ces limitations est la vitesse de transfert du disque, qui désigne le taux auquel les données peuvent être lues et écrites. La vitesse de transfert n’augmente pas proportionnellement avec la capacité du disque car elle évolue avec la densité linéaire (bits par pouce), tandis que la capacité du disque évolue avec la densité surfacique (gigabits stockés par pouce carré). En conséquence, si la capacité du disque augmente d’un facteur 4, la vitesse de transfert n’augmente que d’un facteur 2. Une deuxième limitation majeure est le temps de recherche (seek time). Pour accéder aux données, le lecteur doit physiquement déplacer les têtes de lecture/écriture vers la piste appropriée sur le disque. Troisièmement, pour trouver un élément de données particulier sur le disque, le contrôleur du disque doit attendre que cet élément se retrouve sous les têtes de lecture/écriture. Cela entraîne une latence de rotation.
- Disque SSD (Solid-State Drive) : utilise des cellules de mémoire flash pour stocker les données sous forme de charges, éliminant ainsi les contraintes mécaniques des disques magnétiques. Par conséquent, les données sont lues par des moyens purement électroniques. En conséquence, les SSD sont beaucoup plus rapides que les disques magnétiques traditionnels et peuvent récupérer des données aléatoires en moins de 0,1 ms (100 microsecondes). Ils peuvent également faire évoluer les vitesses de transfert de données et les IOPS en divisant le stockage en partitions avec plusieurs contrôleurs de stockage fonctionnant en parallèle. Grâce à ces caractéristiques de performance exceptionnelles, ils ont révolutionné les bases de données transactionnelles et constituent la norme acceptée pour les déploiements commerciaux des systèmes OLTP. Avec les SSD, les bases de données relationnelles telles que PostgreSQL, MySQL et SQL Server peuvent gérer des milliers de transactions par seconde. Cependant, les SSD ont un coût. Les SSD commerciaux coûtent généralement 20 à 30 centimes (USD) par gigaoctet de capacité, soit près de 10 fois le coût par capacité d’un disque magnétique.
- Lecteur de bandes magnétiques : similaires aux HDD, les lecteurs de bandes sont des dispositifs de stockage qui utilisent des bandes magnétiques pour stocker et récupérer des données. Ils étaient largement utilisés pour la sauvegarde et le stockage d’archives, mais sont devenus moins courants avec l’essor du stockage sur disque. Les lecteurs de bandes fonctionnent en faisant passer une bande magnétique sur une tête de lecture/écriture qui magnétise ou lit les données sur la bande. Les lecteurs de bandes présentent plusieurs avantages par rapport aux autres types de dispositifs de stockage. Ils ont un faible coût par gigaoctet de stockage, peuvent contenir de grandes quantités de données et sont très fiables pour le stockage à long terme (c’est pourquoi ils sont utilisés pour l’archivage des données froides).
- Mémoire vive (RAM) : communément appelée mémoire, elle est utilisée pour stocker temporairement les données qui sont actuellement utilisées ou traitées par le CPU de l’ordinateur. La RAM fournit au CPU un accès rapide à ces données, lui permettant de lire et d’écrire des données rapidement. La RAM est considérée comme une mémoire volatile, ce qui signifie qu’elle perd ses données lorsque l’ordinateur est éteint. Elle diffère des dispositifs de stockage à long terme comme les disques durs et les SSD, qui conservent les données même lorsque l’ordinateur est éteint. La quantité de RAM d’un ordinateur peut affecter considérablement ses performances, car plus de RAM permet de stocker et d’accéder rapidement à plus de données. La mémoire est partitionnée (divisée) en plusieurs conteneurs de données appelés cellules de mémoire. Chaque cellule stocke une quantité spécifique de données appelée un mot. Chaque cellule possède un identifiant d’emplacement associé appelé une adresse.
Systèmes de stockage
Les systèmes de stockage existent à un niveau d’abstraction au-dessus des supports de stockage bruts. Par exemple, les disques magnétiques sont des supports de stockage bruts, tandis que les principales plateformes de stockage d’objets dans le cloud et HDFS sont des systèmes de stockage qui utilisent des disques magnétiques.
Les systèmes de stockage définissent la façon dont la couche de stockage conserve, organise et présente les données indépendamment du support de stockage sous-jacent. Les données peuvent être stockées de différentes manières :
- Stockage de fichiers : également connu sous le nom de stockage au niveau fichier ou stockage basé sur les fichiers, c’est une méthode de stockage des données où chaque information est conservée dans un dossier (stockage hiérarchique). Pour accéder aux données, votre ordinateur doit connaître le chemin où elles se trouvent. Ce type de stockage (appelé « Systèmes de fichiers ») utilise des métadonnées limitées qui indiquent exactement à l’ordinateur où trouver les fichiers, de la même façon que vous utiliseriez un catalogue de bibliothèque pour les livres. Le type de stockage de fichiers le plus familier est celui géré par le système d’exploitation sur les partitions de disque locales (par ex., NTFS, ext4). Les systèmes de fichiers locaux supportent généralement une cohérence complète de lecture après écriture ; lire immédiatement après une écriture renverra les données écrites. Un autre stockage de fichiers bien connu est le NAS. Les systèmes NAS (Network-Attached Storage) fournissent un système de stockage de fichiers aux clients via un réseau.
- Stockage en blocs : divise les données en blocs et les stocke individuellement, chacun avec un identifiant unique. Cela permet au système de stocker ces morceaux d’information plus petits dans l’emplacement le plus efficace. Le stockage en blocs est une excellente solution pour les entreprises qui nécessitent un accès rapide et fiable à de grandes quantités de données. Il est généralement déployé dans des environnements SAN (Storage Area Network) et doit être connecté à un serveur actif avant utilisation.
- Stockage d’objets : est une structure plate dans laquelle les fichiers sont divisés en morceaux et répartis sur le matériel. Au lieu d’être conservées sous forme de fichiers dans des dossiers ou de blocs sur des serveurs, les données sont divisées en unités discrètes appelées objets avec des identifiants uniques pour leur récupération dans un système distribué. Le stockage d’objets est mieux utilisé pour de grandes quantités de données non structurées, notamment lorsque la durabilité, le stockage illimité, la scalabilité et la gestion de métadonnées complexes sont des facteurs pertinents pour les performances globales.

Technologies de stockage
Le choix d’une technologie de stockage dépend de plusieurs facteurs, tels que les cas d’usage, les volumes de données, la fréquence d’ingestion et le format des données. Il n’y a pas de recommandation de stockage universelle qui convienne à tous les scénarios. Chaque technologie de stockage a ses avantages et ses inconvénients. Avec d’innombrables variétés de technologies de stockage disponibles, il peut être difficile de sélectionner l’option la plus adaptée à votre architecture de données.
Ces dernières années, nous avons vu de nombreuses technologies de support de stockage émerger pour stocker et gérer les données : bases de données, data warehouses, data marts, data lakes ou, récemment, data lakehouses. Tous commencent par « data ». Bien sûr, les données sont partout, mais le type de données, la portée et l’utilisation illustreront la meilleure technologie pour votre organisation.
Une base de données est une collection de données structurées stockées sur un disque, en mémoire ou les deux. Les bases de données existent en de nombreuses variantes :
-
Bases de données structurées : une base de données qui stocke des données dans un format organisé et prédéfini (schémas). Les bases de données structurées peuvent être relationnelles ou analytiques :
- Bases de données relationnelles qui utilisent le modèle relationnel pour organiser les données en tables, champs (colonnes) et enregistrements (lignes). Ces tables peuvent être liées à l’aide de relations entre différents champs de chaque table. Ce type de base de données permet des requêtes complexes (jointures) sur de grands ensembles de données et des transactions telles que les mises à jour, insertions ou suppressions sur plusieurs enregistrements liés (OLTP).
- Bases de données analytiques conçues pour des tâches analytiques complexes comme l’analyse des tendances et les prévisions. Ces bases de données (OLAP) ont généralement de grandes quantités de données dénormalisées stockées dans moins de tables mais plus larges, avec de nombreuses colonnes contenant des informations détaillées sur chaque transaction ou événement analysé.
-
Bases de données semi-structurées et non structurées, également connues sous le nom de Not-Only SQL (NoSQL), ne suivent pas la même structure que les bases de données SQL traditionnelles mais permettent aux utilisateurs de stocker des données non structurées ou semi-structurées sans avoir à définir des schémas fixes au préalable. Elles peuvent être classifiées en huit catégories :
- Bases de données de documents : stockent les données dans des documents organisés en collections contenant des paires clé-valeur ou d’autres structures imbriquées complexes (par ex., JSON).
- Stores clé-valeur : ce type de base de données NoSQL stocke chaque élément comme un nom d’attribut (ou « clé ») avec sa valeur ; ils fournissent un moyen simple de stocker de grandes quantités de données structurées pouvant être rapidement accessibles en spécifiant la clé unique pour chaque information.
- Bases de données colonnes : ce type est optimisé pour les requêtes sur de grands ensembles de données, en stockant les colonnes de données séparément plutôt que les lignes.
- Bases de données de graphes : une base de données de graphes utilise des nœuds connectés par des arêtes, ce qui la rend idéale pour les applications où les relations entre les entités nécessitent des temps d’accès rapides et une capacité de stockage efficace.
- Bases de données de séries temporelles : une base de données de séries temporelles est une base de données NoSQL optimisée pour stocker et analyser des données de séries temporelles telles que les relevés de capteurs, les cours des actions, les métriques système, etc.
- Registres immuables : un registre immuable est un système de tenue des registres dans lequel les enregistrements ne peuvent pas être modifiés ou supprimés une fois écrits. L’un des exemples les plus connus est la blockchain.
- Bases de données géospatiales : un datastore géospatial est un type de base de données qui stocke et gère spécifiquement les données géospatiales décrivant la localisation et les relations spatiales d’objets et de caractéristiques à la surface de la Terre.
- Bases de données de recherche : les bases de données de recherche sont explicitement conçues pour chercher et récupérer des informations basées sur des critères spécifiques, tels que des mots-clés ou des vecteurs.

Un data warehouse est une architecture de données OLAP standard. Il tend à gérer de grandes quantités de données rapidement, permettant aux utilisateurs d’analyser des faits selon plusieurs dimensions simultanément (Cube). Les data warehouses ont été un pilier des applications de support décisionnel et de business intelligence depuis la fin des années 1980. Cependant, ils ne sont pas bien adaptés pour gérer de grands volumes de données non structurées ou semi-structurées avec une grande variété, vélocité et volume. Pour divers usages, il peut être utilisé pour des analyses et des rapports quasi-temps réel sur des systèmes opérationnels en constante évolution (ODS), ou ils peuvent être divisés en plusieurs sous-ensembles et adaptés pour des usages spécifiques (c’est-à-dire des data marts).
Il y a une dizaine d’années, les architectes ont commencé à conceptualiser un système unique pour stocker des données provenant de plusieurs sources pouvant être utilisées par divers produits et charges de travail analytiques. Cela a conduit au développement des data lakes. Un data lake est un grand référentiel centralisé de données structurées et non structurées pouvant être utilisé à n’importe quelle échelle.
Contrairement aux bases de données ou aux data warehouses, un data lake capture tout ce que l’organisation juge précieux pour une utilisation future. Le data lake représente un processus tout-en-un. Les données proviennent de sources disparates et servent des consommateurs disparates. Nous voyons souvent les data lakes travailler avec des outils complémentaires comme les data warehouses et les data marts.
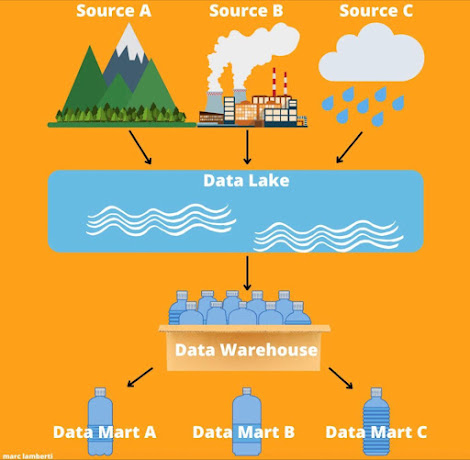 Démystifier le stockage des données - Crédit Marc Lamberti.
Démystifier le stockage des données - Crédit Marc Lamberti.
Le besoin continu d’outils complémentaires a poussé de nombreux fournisseurs technologiques à créer un nouveau concept qui combine les meilleurs éléments des data lakes et des data warehouses. Cette nouvelle technologie est appelée data lakehouse.
Un data lakehouse combine le stockage à faible coût et évolutif d’un data lake et les fonctionnalités de structure et de gestion d’un data warehouse. Cet environnement permet des économies tout en appliquant des schémas sur des sous-ensembles des données stockées, évitant ainsi de devenir un « data swamp » ingérable. Pour cela, il inclut les fonctionnalités suivantes (liste non exhaustive) :
- Mutation des données : la plupart des data lakes sont construits sur des technologies immuables (par ex., HDFS ou S3). Pour résoudre ce problème d’évolution du schema, les data lakehouses permettent deux approches : copy-on-write et merge-on-read.
- ACID : prise en charge des transactions pour permettre des opérations de lecture et d’écriture simultanées tout en garantissant que les données sont ACID (Atomiques, Cohérentes, Isolées et Durables).
- Voyage dans le temps (Time-travel) : la capacité transactionnelle du lakehouse permet de remonter dans le temps sur un enregistrement de données en gardant une trace des versions.
- Enforcement du schema : la qualité des données comporte de nombreux composants, mais le plus important est de s’assurer que les données respectent un schema lors de l’ingestion.
- Streaming de bout en bout : les organisations sont confrontées à de nombreux défis avec les données en streaming. Le data lakehouse résout notamment le problème des données hors ordre via le watermarking.

Fonctionnalités de stockage
1 - Couches de stockage
L’architecture du data lake était initialement considérée comme la solution pour stocker de très grands volumes de données. Mais ils sont plutôt devenus des « data swamps » remplis de pétaoctets d’informations structurées et non structurées inutilisables.
Pour résoudre ce problème, il est important de comprendre comment créer des zones au sein d’un data lake afin d’éviter efficacement de se retrouver avec un marécage de données.
Les data lakes sont divisés en trois zones principales : Raw (brute), Trusted (de confiance) et Curated (organisée). Les organisations peuvent nommer ces zones différemment selon leurs préférences, mais leurs fonctions sont identiques.
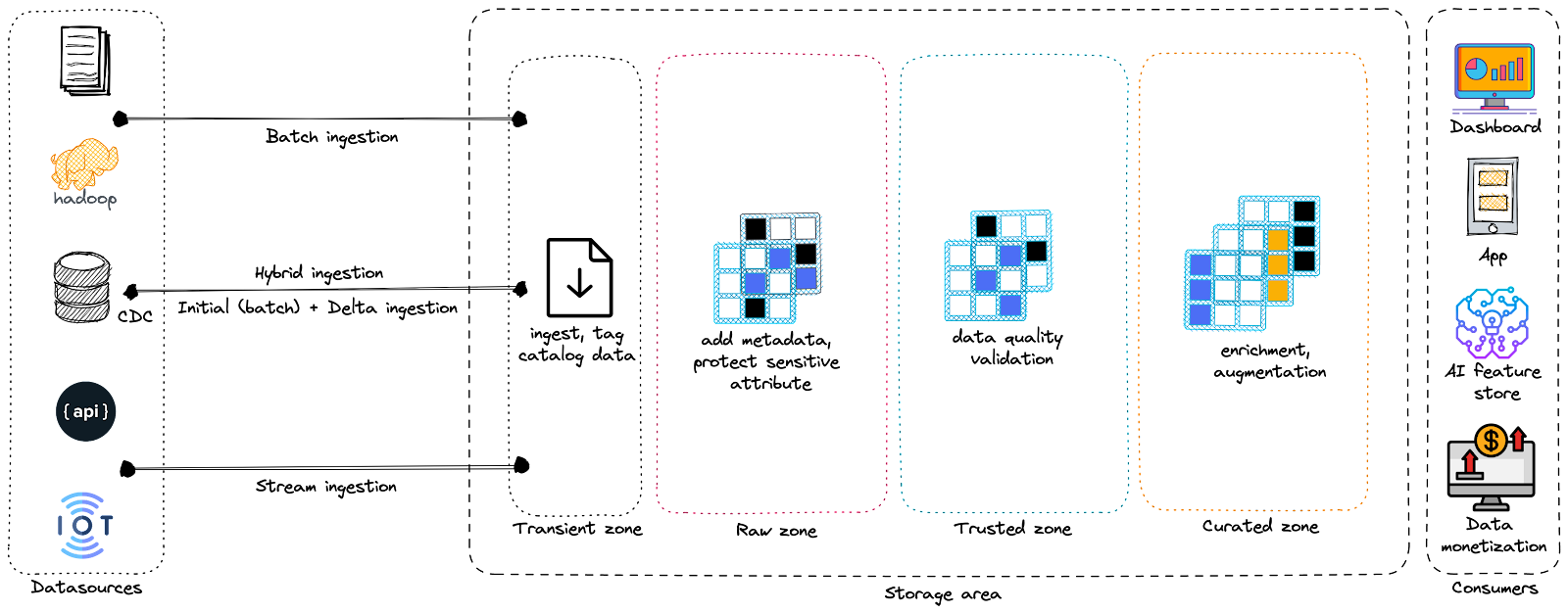
- Zone brute (Raw zone) : également connue sous le nom de zone d’atterrissage, zone bronze ou marécage. Dans cette zone, les données sont stockées dans leur format natif sans transformation ni liaison à des règles métier. Bien que toutes les données démarrent dans la zone brute, elle est trop vaste pour les utilisateurs finaux métier (moins techniques). Les utilisateurs typiques de la zone brute comprennent les ingénieurs de données, les gestionnaires de données, les analystes de données et les data scientists.
- Zone de confiance (Trusted zone) : également appelée zone d’exploration, sandbox, zone argent ou étang. C’est l’endroit où les données peuvent être découvertes et explorées. Elle comprend des zones privées pour chaque utilisateur individuel et une zone partagée pour la collaboration d’équipe. La zone de données de confiance contient les données comme « source unique de vérité » pour les zones et systèmes en aval.
- Zone organisée (Curated zone) : également connue sous le nom de données raffinées, zone de production, zone or, zone de service ou lagune. C’est là que les données propres, manipulées et enrichies sont stockées dans le format optimal pour orienter les décisions métier. Cette zone a des mesures de sécurité strictes pour limiter l’accès aux données.
Dans certaines plateformes, vous pouvez trouver des zones transitoires supplémentaires qui contiennent des données éphémères non traitées (c’est-à-dire des copies temporaires, des pools de streaming…) stockées temporairement avant d’être déplacées vers l’une des trois zones permanentes.
2 - Cycle de vie du stockage
Les patterns de récupération des données peuvent varier considérablement selon la nature des données stockées et les requêtes effectuées. En conséquence, le concept de « températures » a émergé. La fréquence d’accès aux données détermine la température des données.
Les données auxquelles on accède le plus fréquemment sont appelées données chaudes (hot data). Les données chaudes peuvent être accédées plusieurs fois par jour ou même plusieurs fois par seconde, comme dans les systèmes qui traitent les demandes des utilisateurs. Les données tièdes (warm data) sont accédées occasionnellement, comme une fois par semaine ou par mois.
Les données froides (cold data) sont rarement interrogées et sont mieux stockées dans un système d’archivage. Cependant, les données froides sont souvent conservées pour des raisons de conformité ou comme protection en cas de défaillance catastrophique d’un autre système.
Il est nécessaire de mettre en place des politiques pour gérer le stockage des données en fonction de leur « température » ou du degré de leur fiabilité. C’est pourquoi le cycle de vie du stockage devient une tâche critique.

Le cycle de vie du stockage est le processus de gestion des données stockées tout au long de leur cycle de vie complet, depuis la création initiale dans le support jusqu’à la suppression finale. Dans votre plateforme de données, vous devez gérer vos objets de données avec un ensemble de règles définissant les actions à appliquer lorsque des conditions prédéfinies sont vérifiées. Il existe deux types d’actions :
-
Actions de transition : définissent quand les objets de données passent d’une zone isolée à une autre. Dans la plupart des plateformes de données, la zone d’atterrissage est la première zone de stockage dans laquelle les données brutes sont ingérées. Il est ensuite nécessaire de définir des actions de transition pour transférer les données d’une zone de stockage à une autre (par ex., organisée, enrichie ou conforme…).
Vous pouvez également définir quand les objets de données passent d’une classe de stockage à une autre (par ex., étiqueter les données comme froides lorsqu’elles sont moins fréquemment utilisées ou archiver les données de plus d’un an), ce qui peut permettre un meilleur contrôle des coûts de stockage.
-
Actions d’expiration : vous pouvez définir quand vos données doivent être supprimées (expirées).
Ces types d’actions sont généralement effectuées par des outils ETL, mais certains services de stockage (notamment ceux fournis par les fournisseurs cloud) peuvent offrir de telles capacités (par ex., les politiques de cycle de vie AWS S3).
3 - Options de stockage
Stocker des données collectées depuis plusieurs sources vers un système de stockage cible a toujours été un défi global pour les organisations. Par conséquent, l’option de stockage choisie est un domaine d’intérêt pour améliorer le parcours de données. Vous utilisez soit la méthode en masse (également appelée chargement complet) soit la méthode de chargement incrémental pour effectuer le stockage des données.
Dans le stockage en masse, l’ensemble du jeu de données cible est vidé puis entièrement réécrit : remplacé par une version mise à jour lors de chaque exécution de chargement de données. L’exécution d’un chargement complet des données est un processus facile à mettre en œuvre nécessitant une maintenance minimale et une conception simple. Cette technique supprime simplement l’ancien jeu de données et le remplace par un jeu de données entièrement mis à jour, éliminant le besoin de gérer les deltas (changements).
Cependant, en utilisant l’approche de chargement complet des données, on peut rencontrer des difficultés pour maintenir le chargement des données avec un petit nombre d’enregistrements, des performances lentes lors du traitement de grands ensembles de données et une incapacité à préserver les données historiques.
 Stockage en masse vs. stockage incrémental.
Stockage en masse vs. stockage incrémental.
D’autre part, le chargement incrémental est une méthode sélective de stockage des données d’une ou plusieurs sources vers un emplacement de stockage cible. Le modèle de chargement incrémental tentera de comparer les données entrantes des systèmes sources avec les données existantes dans la destination pour toute nouvelle valeur ou valeur modifiée depuis la dernière opération de chargement.
Le principal avantage du stockage incrémental par rapport à un chargement complet en masse est qu’il minimise la quantité de travail nécessaire à chaque lot. Cela peut rendre le chargement incrémental beaucoup plus rapide dans l’ensemble, surtout lors du traitement de grands ensembles de données. De plus, étant donné que seules les nouvelles données ou les données modifiées sont stockées à chaque fois, il y a moins de risques d’erreurs introduites dans les jeux de données cibles.
Lors de l’utilisation du stockage de données incrémental, des défis potentiels peuvent survenir, comme des problèmes d’incompatibilité pouvant apparaître lorsque de nouveaux enregistrements invalident les données existantes en raison de formats ou de types de données incompatibles. De plus, les systèmes distribués utilisés pour le traitement des données entrantes pourraient entraîner des changements ou des suppressions se produisant dans une séquence différente (événements hors ordre) de celle dans laquelle ils ont été reçus à l’origine.
Activités transversales du stockage des données
Les activités transversales du stockage sont importantes car le stockage est une étape critique pour toutes les activités du parcours de données. Les ingénieurs de données doivent donc aborder ces activités avec soin :
-
Sécurité : bien que la sécurité soit souvent perçue comme un obstacle au travail des ingénieurs de données, ils doivent reconnaître que la sécurité est en réalité un facilitateur essentiel. En mettant en œuvre des mesures de sécurité robustes (chiffrement, anonymisation…) pour les données au repos et en mouvement, et un contrôle d’accès granulaire aux données, les ingénieurs de données peuvent permettre un partage et une consommation plus larges des données au sein d’une entreprise, conduisant à une augmentation significative de la valeur des données.
-
Gestion des données est critique lorsque nous lisons et écrivons des données avec des systèmes de stockage. Avoir des métadonnées robustes améliore la qualité des données. Le catalogage des métadonnées permet aux data scientists, aux analystes et aux ingénieurs ML de découvrir et d’utiliser les données efficacement. La lignée des données, qui trace le chemin des données, peut accélérer le processus d’identification et de résolution des problèmes de données. Notez que le RGPD et d’autres réglementations sur la confidentialité ont considérablement influencé la conception des systèmes de stockage. Les données contenant des informations sensibles nécessitent une stratégie spécifique de gestion du cycle de vie.
-
DataOps : la principale préoccupation est la surveillance opérationnelle des systèmes de stockage et des données elles-mêmes. La surveillance des données est devenue intimement liée à la qualité des données et aux métadonnées. En fait, les professionnels de la donnée doivent surveiller l’infrastructure de stockage, le coût de stockage (FinOps) et l’accès aux données.
-
Orchestration et stockage sont étroitement liés. Le stockage facilite le flux de données à travers les pipelines, tandis que l’orchestration agit comme la pompe qui entraîne le mouvement des données. L’orchestration joue un rôle critique dans la gestion de la complexité des systèmes de données en permettant aux ingénieurs de combiner plusieurs systèmes de stockage et moteurs de requête.
-
Architecture de données : comme je l’ai souligné dans Data 101 - partie 3, une bonne architecture de données doit principalement répondre aux exigences métier avec un ensemble d’éléments de construction largement réutilisables tout en préservant des meilleures pratiques bien définies et en faisant les compromis appropriés. Vous pouvez évaluer votre architecture selon les six piliers du AWS Well-Architected Framework (WAF) :
- Excellence opérationnelle : vous devez définir, capturer et analyser les métriques de stockage pour obtenir de la visibilité et prendre les mesures appropriées.
- Sécurité : vous devez prendre les mesures nécessaires pour classifier vos données, les protéger contre les fuites et restreindre leur accès aux seuls utilisateurs pertinents.
- Fiabilité : vous devez définir les processus nécessaires pour sauvegarder les données et respecter vos exigences prédéfinies et vos SLA concernant les objectifs de temps de récupération (RTO) et les objectifs de point de récupération (RPO).
- Efficacité des performances : vous devez choisir votre solution de stockage en fonction de la méthode d’accès requise (bloc, fichier ou objet), des patterns d’accès (aléatoire ou séquentiel), du débit requis, de la fréquence d’accès (en ligne, hors ligne, archives), de la fréquence de mise à jour (WORM, dynamique) et des contraintes de disponibilité et de durabilité.
- Optimisation des coûts : vous devez surveiller et gérer l’utilisation et les coûts de stockage et mettre en œuvre un contrôle des changements et une gestion des ressources du début à la fin du projet.
- Durabilité : pour minimiser les impacts environnementaux, vous devez mettre en œuvre des pratiques de gestion des données pour réduire le stockage provisionné nécessaire pour soutenir votre charge de travail. Utilisez des cycles de vie du stockage pour supprimer les données qui ne sont plus nécessaires.
Résumé
Cet article a présenté les différents niveaux d’abstraction qui forment le stockage dans un parcours de données. J’ai d’abord discuté des supports de stockage bruts, des systèmes et d’autres fonctionnalités qui rendent le stockage plus résilient et performant. Ensuite, j’ai illustré les technologies utilisées pour stocker les données et comment les données peuvent être conservées et utilisées sans transformer la zone de stockage en un « data swamp » ingérable. Pour cela, j’ai donné un aperçu de l’évolution des technologies de stockage des années 80 du siècle dernier jusqu’à ces dernières années.
Enfin, j’ai souligné que la tâche la plus critique pour tout ingénieur de données est de comprendre les données à conserver, de prédire les méthodes et patterns d’accès, et d’effectuer une évaluation dimensionnelle pour connaître le débit requis, la fréquence d’accès et les mises à jour de ces données.
Références
- Reis, J. and Housley, M. Fundamentals of data engineering: Plan and build robust data systems. O’Reilly Media (2022).
- “Incremental Data Load vs Full Load ETL: 4 Critical Differences”, Sanchit Agarwal (Hevo)
- “Productionizing Machine Learning with Delta Lake”, Brenner Heintz and Denny Lee (Databricks Engineering Blog)
- “Data Lake Governance Best Practices”, Parth Patel, Greg Wood, and Adam Diaz (DZone).
- “File storage, block storage, or object storage?”, Redhat Blog
- “From Raw to Refined: The Staging Areas of Your Data Lake (Part 1)”, Bertrand Cariou (Trifacta Blog)
- “The Four Essential Zones of a Healthcare Data Lake”, Bryan Hinton