
Félicitations ! Vous avez atteint la dernière étape du parcours des données : servir les données pour les cas d’utilisation en aval. Maintenant que les données ont été ingérées, stockées et traitées dans des structures cohérentes et valorisées, il est temps de tirer profit de vos données.
Le service de données est la partie la plus passionnante du cycle de vie des données. C’est là que la magie opère : l’étape de service concerne les données en action. Elle offre aux utilisateurs un accès cohérent et transparent aux données, indépendamment des systèmes de traitement ou d’ingestion sous-jacents. De plus, cette étape joue un rôle essentiel dans l’activation des applications en temps réel comme les tableaux de bord et l’analytique qui nécessitent un accès rapide aux informations actuelles, permettant ainsi une prise de décision opérationnelle rapide.
Nous avons vu dans les articles précédents comment nous utilisons Redis pour acquérir, traiter et stocker des données. Dans cet article, nous verrons l’étape en aval du parcours des données, qui est le service de données. À cet effet, je vais présenter une série d’outils Redis qui aident à exposer et à accélérer les données pour différents consommateurs (outils de visualisation de données, IA/ML…).
Dans cet article, vous verrez différentes façons de servir les données : vous préparerez des données pour la visualisation. Ce sont les domaines de service de données les plus traditionnels, où les parties prenantes métier obtiennent une visibilité et des insights à partir des données brutes collectées. Ensuite, vous verrez comment Redis peut servir de feature store à faible latence pour différentes applications de Machine Learning.
Enfin, vous verrez comment servir des données via un ETL inversé (Reverse ETL). Le Reverse ETL désigne le renvoi des données traitées vers les sources de données. Cela est devenu de plus en plus important alors que les organisations cherchent à utiliser leurs données de manière plus significative et impactante. En déplaçant les données traitées vers les systèmes opérationnels, les organisations peuvent permettre une prise de décision basée sur les données au moment de l’action. Cela permet aux entreprises de réagir aux conditions changeantes et de prendre des décisions en temps réel mieux informées.
Pré-requis
1 - Créer une base de données Redis
Vous devez installer et configurer quelques éléments pour cet article. Tout d’abord, vous devez préparer un cluster Redis Enterprise. Ce support de stockage sera l’infrastructure cible pour les données à accélérer et à servir dans cette étape. Vous pouvez installer Redis OSS en suivant les instructions ici, ou vous pouvez utiliser ce projet pour créer un cluster Redis Enterprise chez le fournisseur cloud de votre choix. Supposons une base de données cible sur le point d’accès : redis-12000.cluster.redis-serving.demo.redislabs.com:12000. Lors de la création de cette base de données, assurez-vous d’ajouter les modules RedisJSON et RediSearch.
2 - Installer et configurer Redis SQL Trino
Pour la deuxième partie de cet article, vous devez télécharger et installer le serveur Trino :
wget https://repo1.maven.org/maven2/io/trino/trino-server/403/trino-server-403.tar.gz
mkdir /usr/lib/trino
tar xzvf trino-server-403.tar.gz --directory /usr/lib/trino --strip-components 1
Trino nécessite une version 64 bits de Java 17+ en plus de Python. Trino a également besoin d’un répertoire de données pour stocker les journaux, etc. Par conséquent, il est recommandé de créer un répertoire de données en dehors du répertoire d’installation, permettant de le conserver facilement lors des mises à niveau de Trino.
mkdir -p /var/trino
Créez un répertoire etc dans le répertoire d’installation pour contenir les fichiers de configuration.
mkdir /usr/lib/trino/etc
Créez le fichier /usr/lib/trino/etc/node.properties
node.environment=production
Créez un fichier de configuration JVM dans /usr/lib/trino/etc/jvm.config
-server
-Xmx16G
-XX:InitialRAMPercentage=80
-XX:MaxRAMPercentage=80
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-XX:+UnlockDiagnosticVMOptions
-XX:+UseAESCTRIntrinsics
Créez le fichier de propriétés de configuration /usr/lib/trino/etc/config.properties
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
discovery.uri=http://localhost:8080
Créez un fichier de configuration de journalisation /usr/lib/trino/etc/log.properties
io.trino=INFO
Vous devez maintenant télécharger la dernière version du connecteur RediSearch et le décompresser sans aucune structure de répertoire dans /usr/lib/trino/plugin/redisearch :
mkdir /usr/lib/trino/plugin/redisearch
wget https://github.com/redis-field-engineering/redis-sql-trino/releases/download/v0.3.3/redis-sql-trino-0.3.3.zip -O /usr/lib/trino/plugin/redisearch/redis-sql-trino-0.3.3.zip
unzip -j /usr/lib/trino/plugin/redisearch/redis-sql-trino-0.3.3.zip -d /usr/lib/trino/plugin/redisearch
Créez le sous-répertoire catalog /usr/lib/trino/etc/catalog :
mkdir /usr/lib/trino/etc/catalog
Créez une configuration du connecteur RediSearch dans /usr/lib/trino/etc/catalog/redisearch.properties et modifiez/ajoutez des propriétés selon vos besoins.
connector.name=redisearch
redisearch.uri=redis://redis-12000.cluster.redis-serving.demo.redislabs.com:12000
Démarrez le serveur Trino :
/usr/lib/trino/bin/launcher run
Téléchargez trino-cli-403-executable.jar pour utiliser l’interface en ligne de commande (CLI) de Trino :
wget https://repo1.maven.org/maven2/io/trino/trino-cli/403/trino-cli-403-executable.jar -O /usr/local/bin/trino
chmod +x /usr/local/bin/trino
La plupart des applications réelles utiliseront le pilote JDBC Trino pour émettre des requêtes. Le pilote JDBC Trino permet aux utilisateurs d’accéder à Trino depuis des applications basées sur Java ou des applications non-Java s’exécutant dans une JVM. Consultez la documentation Trino pour les instructions de configuration.
Analytique
L’analytique est au cœur de la plupart des initiatives de données. Elle consiste à interpréter et à tirer des insights des données traitées pour prendre des décisions éclairées ou faire des prédictions sur les tendances futures. Les outils de visualisation de données peuvent être utilisés ici pour aider à visualiser les données de manière plus significative.
Une fois que les données organisées passent par différentes étapes d’analyse (voir Data 101 - partie 8), les résultats (insights) peuvent être partagés avec les parties prenantes ou d’autres parties intéressées. Cela peut se faire via des rapports, des présentations ou des tableaux de bord, selon le type d’informations à partager et avec qui elles sont partagées. Les données organisées et/ou les insights peuvent également être partagés « tels quels » à des fins ultérieures, telles que des feature stores pour des algorithmes d’apprentissage automatique, la monétisation des données, les API, etc.

Dans la plupart des cas, les outils de visualisation exécutent des requêtes SQL complexes pour obtenir les données à visualiser. Ces requêtes sont exécutées contre des technologies backend lentes comme les entrepôts de données (par exemple, Impala, Hive…) et peuvent prendre des heures pour charger les données souhaitées, ce qui rend tout rafraîchissement dans les outils de visualisation un cauchemar pour les analystes métier.
C’est là qu’intervient Redis. Il fournit des outils qui exposent et accélèrent les données servies de deux manières : en mettant en cache les résultats de requêtes lentes et répétées pour éviter des appels coûteux vers des systèmes plus lents (par exemple, bases de données, systèmes de fichiers distribués…) et en améliorant considérablement les temps de réponse grâce à Redis Smart Cache. D’autre part, en indexant les données dans Redis pour accélérer les requêtes et en fournissant une intégration pour les outils utilisant intensivement SQL (par exemple, outils de visualisation de données…) via Redis SQL Trino et Redis SQL ODBC. Voyons comment utiliser chacun de ces outils.
1 - Redis Smart Cache
Comme vous pouvez l’imaginer d’après son nom, Redis Smart Cache utilise Redis pour mettre en cache les résultats de requêtes lentes et répétées afin d’éviter des appels coûteux vers des systèmes backend plus lents (par exemple, bases de données, systèmes de fichiers distribués…), améliorant ainsi leurs temps de réponse.
Redis Smart Cache fonctionne comme un wrapper autour du pilote JDBC de votre base de données backend et place les requêtes SQL les plus fréquemment appelées dans le cache. Imaginez un tableau de bord qui prend quelques minutes à se rafraîchir parce qu’il envoie continuellement la même requête coûteuse vers des datastores backend lents (HDFS, Oracle…). Nous savons tous que les systèmes distribués comme HDFS ont fait des compromis sur la latence juste pour fournir un débit élevé. Avec Redis Smart Cache, vous pouvez préserver vos systèmes existants tout en accélérant considérablement leur temps de réponse.

Pour utiliser Redis Smart Cache avec une application existante, vous devez ajouter le pilote JDBC Redis Smart Cache comme dépendance d’application.
Maven :
<dependency>
<groupId>com.redis</groupId>
<artifactId>redis-smart-cache-jdbc</artifactId>
<version>0.2.1</version>
</dependency>
Gradle :
dependencies {
implementation 'com. redis:redis-smart-cache-jdbc:0.2.1'
}
Ensuite, définissez votre URI JDBC vers l’URI de votre instance Redis préfixée par JDBC:, par exemple :
jdbc:redis://redis-12000.cluster.redis-serving.demo.redislabs.com:12000
Voir la syntaxe URI de Lettuce pour tous les paramètres URI possibles que vous pouvez utiliser ici.
L’étape suivante est de fournir une configuration de démarrage. La configuration de Redis Smart Cache se fait via les propriétés JDBC. Les propriétés requises à configurer sont le nom de classe du pilote JDBC de la base de données backend que vous souhaitez envelopper (par exemple, oracle.jdbc.OracleDriver) et l’URL JDBC pour la base de données backend (par exemple, jdbc:oracle:thin:@myhost:1521:orcl). Vous pouvez également inclure toute propriété requise par votre pilote JDBC backend, comme username ou password. Celles-ci seront transmises telles quelles au pilote JDBC backend. Pour le Smart Cache, vous devez configurer quelques paramètres concernant le cache Redis, tels que le préfixe de clé pour les requêtes mises en cache, la durée d’invalidation du cache (rafraîchissement des requêtes mises en cache), les configurations du cluster comme TLS, les informations d’identification, la capacité du cache… La liste complète des paramètres de Redis Smart Cache est disponible ici.
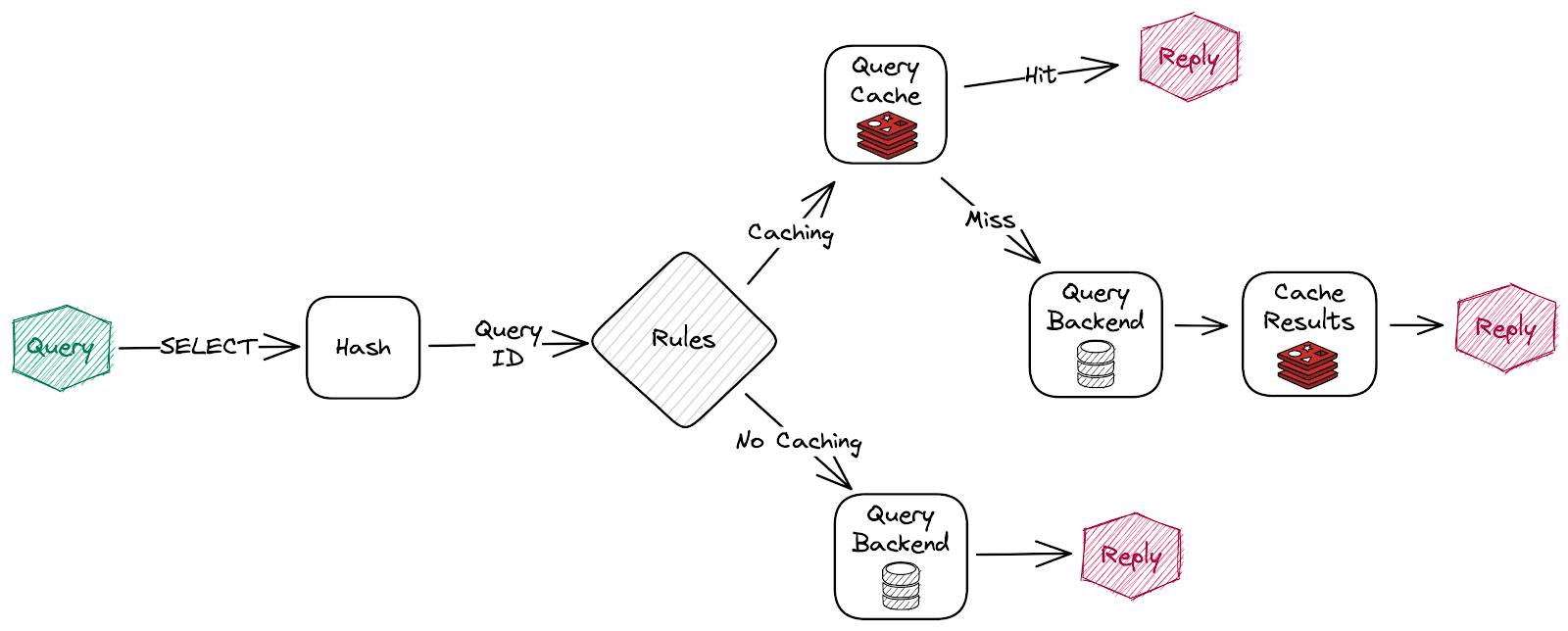
Redis Smart Cache utilise des règles pour déterminer comment les requêtes SQL sont mises en cache. La configuration des règles est stockée dans un document Redis JSON à la clé smartcache:config et peut être modifiée à l’exécution. De plus, Redis Smart Cache se met à jour dynamiquement pour refléter les modifications apportées au document JSON (voir la propriété smartcache.ruleset.refresh pour modifier le taux de rafraîchissement).
Voici la configuration de règle par défaut :
{
"rules": [
{
"tables": null,
"tablesAny": null,
"tablesAll": null,
"regex": null,
"queryIds": null,
"ttl": "1h"
}
]
}
Cette configuration par défaut contient une règle de passage unique où tous les résultats de requêtes SQL se verront attribuer une TTL de 1 heure.
Les règles sont traitées dans l’ordre, composées de critères (conditions) et d’actions (résultats). Seule la première règle avec des critères correspondants sera prise en compte, et son action sera appliquée.
- Le critère
tablesse déclenche si les tables données sont exactement les mêmes que la liste dans la requête SQL (l’ordre n’est pas important). - Le critère
tablesAnyse déclenche si l’une des tables données apparaît dans la requête SQL. - Le critère
tablesAllse déclenche si toutes les tables données apparaissent dans la requête SQL. queryIdsse déclenche si l’identifiant de la requête SQL correspond à l’un des identifiants donnés. Un identifiant est le hachage CRC32 de la requête SQL. Vous pouvez utiliser un calculateur CRC32 en ligne comme celui-ci pour calculer l’identifiant.regexse déclenche si l’expression régulière fournie correspond à la requête SQL (par exemple, SELECT \* FROM test\.\w*)- Actuellement, il n’existe qu’une seule action disponible qui est
ttl. Ce paramètre définit la durée de vie des entrées de cache correspondantes spécifiées dans les critères.
Vous pouvez également utiliser la CLI Redis Smart Cache qui permet de gérer Redis Smart Cache. Bien que vous puissiez configurer Smart Cache entièrement en utilisant des propriétés JDBC, la CLI vous permet de construire des règles de requêtes de manière interactive et d’appliquer de nouvelles configurations dynamiquement. Avec la CLI, vous pouvez également visualiser les requêtes paramétrées ou les instructions préparées de votre application et la durée de chaque requête.

Après avoir ajouté la dépendance Redis Smart Cache et défini quelques configurations de base, votre application JDBC peut tirer parti de Redis comme cache sans aucune modification de votre code. Essayons cet exemple pour comprendre comment fonctionne Redis Smart Cache. Cet exemple présente une application qui effectue continuellement des requêtes contre une base de données MySQL (interrogeant intensément les tables Products, Customers, Orders et OrderDetails) et utilise Redis Smart Cache pour mettre en cache les résultats des requêtes.
Si vous avez un serveur MySQL installé, vous pouvez exécuter cet exemple sur votre machine locale. Ou bien, vous pouvez simplement cloner ce dépôt git :
git clone https://github.com/redis-field-engineering/redis-smart-cache.git
cd redis-smart-cache
Et utiliser Docker Compose pour lancer des conteneurs pour MySQL, Grafana, Redis Stack et l’instance d’application Redis Smart Cache :
docker compose up
L’application commence à interroger les quatre tables en les joignant toutes. Ensuite, pour chaque commande avec l’identifiant x, la requête demande à la base de données de dormir x secondes pour simuler un temps de réponse lent. À l’inverse, Redis Smart Cache lit les règles depuis le document JSON à la clé smartcache:config et crée une structure de données hash contenant la requête SQL, les tables interrogées et le hachage CRC32 de la requête SQL. Ensuite, il met en cache la réponse de chaque requête avec la TTL définie.

Une fois que l’application utilise le wrapper JDBC Redis, elle commence à interroger la base de données backend de manière transparente. Redis Smart Cache stocke la requête et ses résultats dans le cache s’ils ne sont pas disponibles (manquants). Lorsque l’application appelle une requête déjà mise en cache (succès), Redis retourne les résultats stockés dans le cache avec une faible latence.
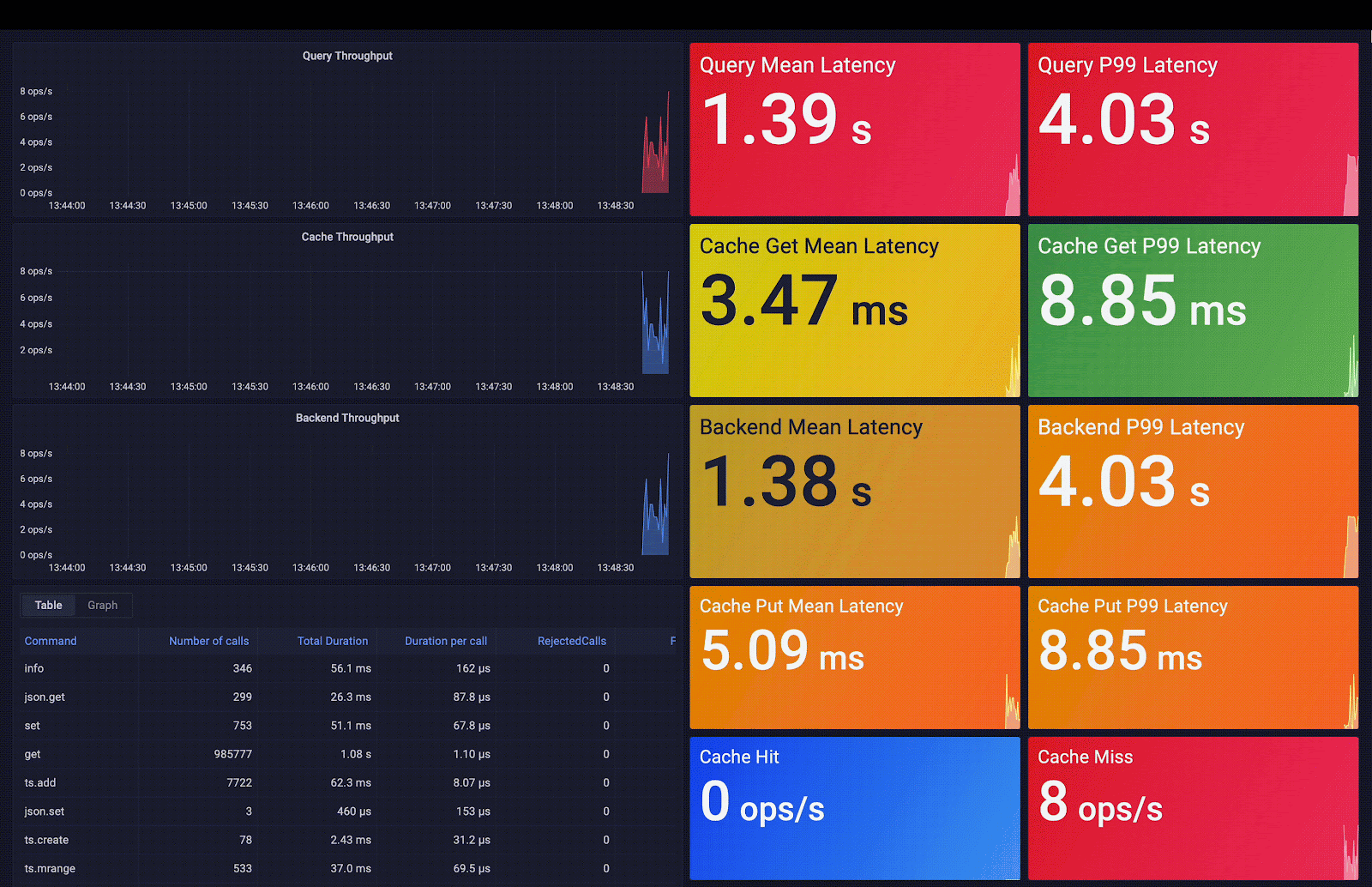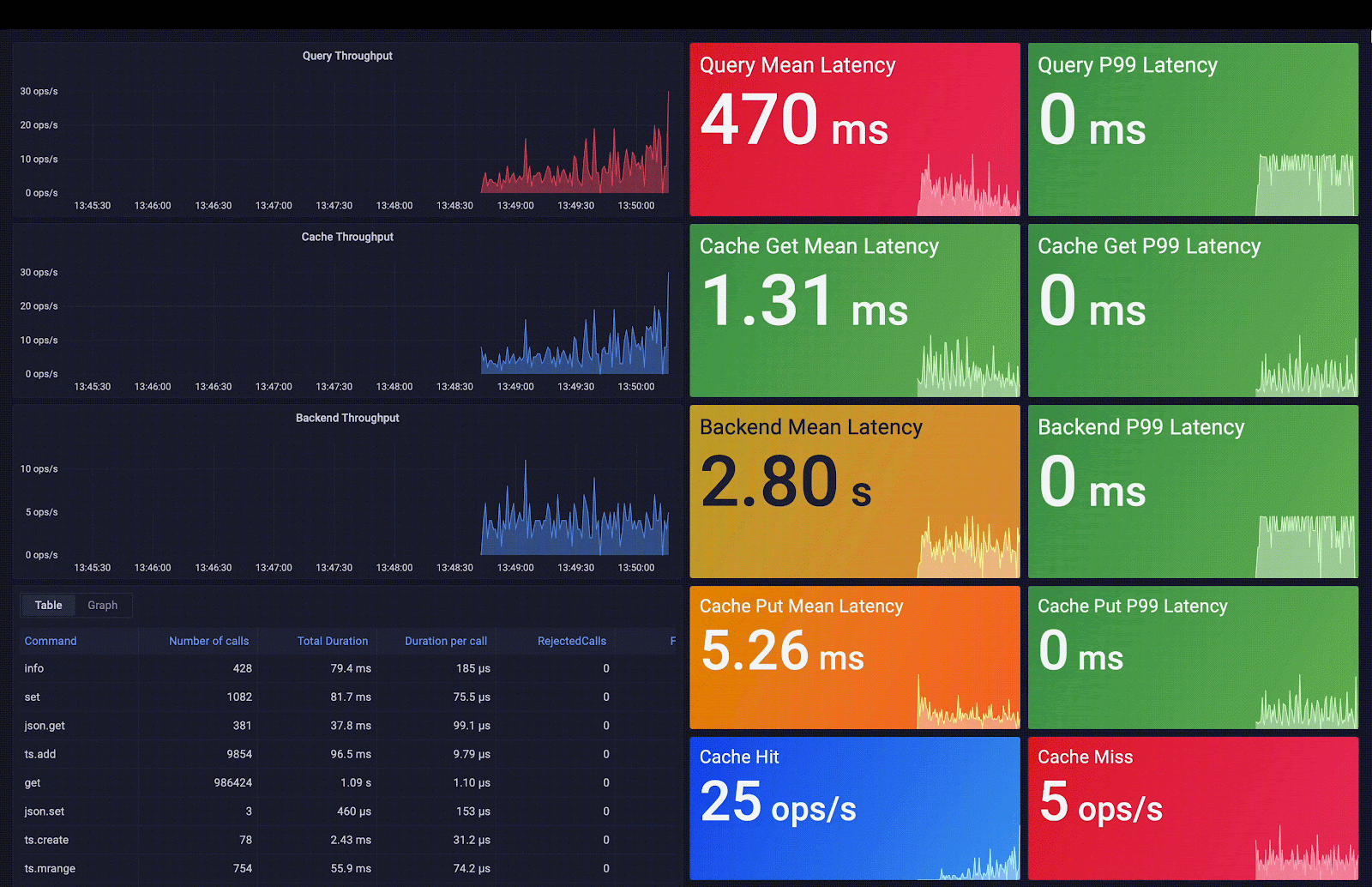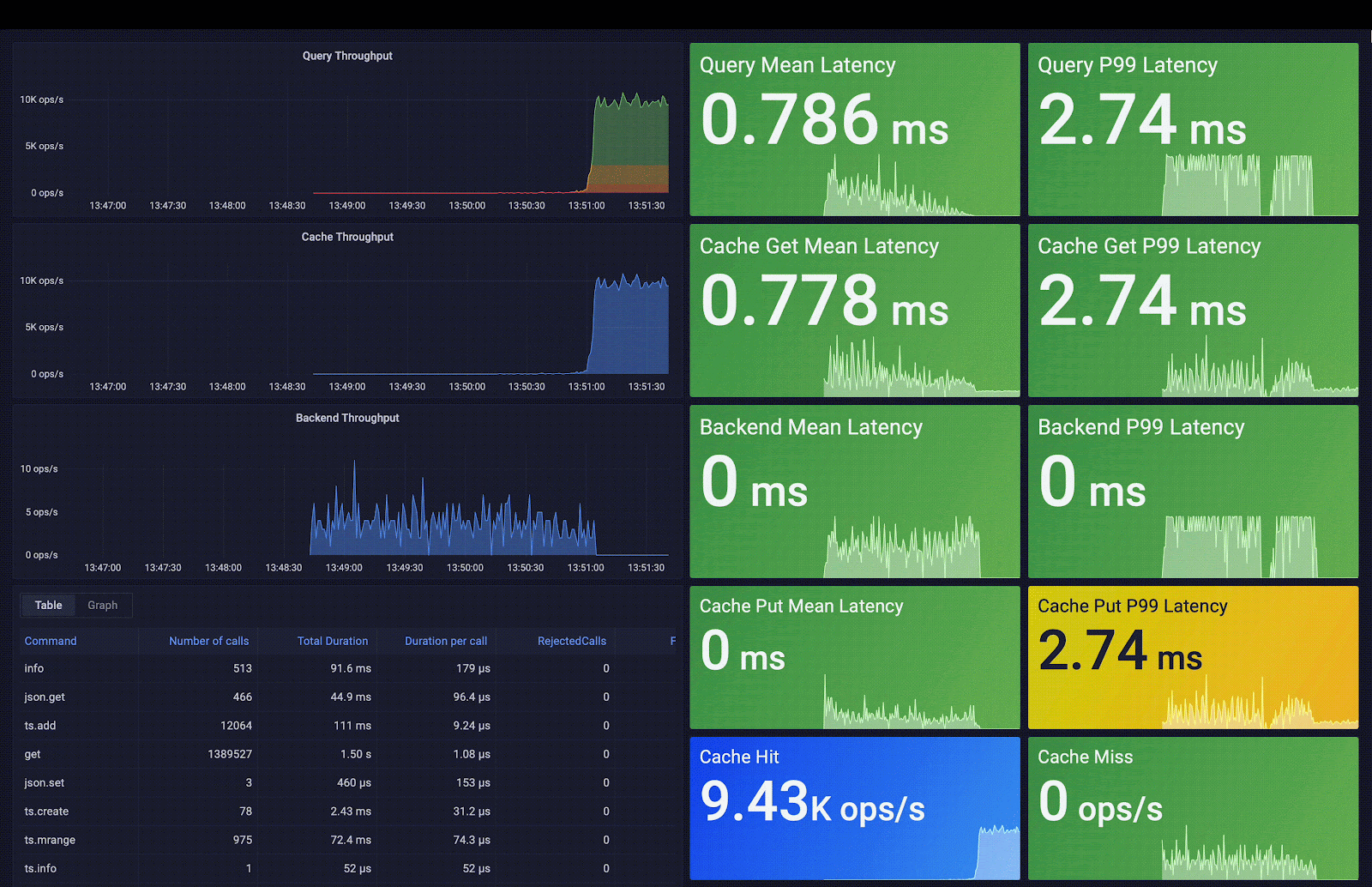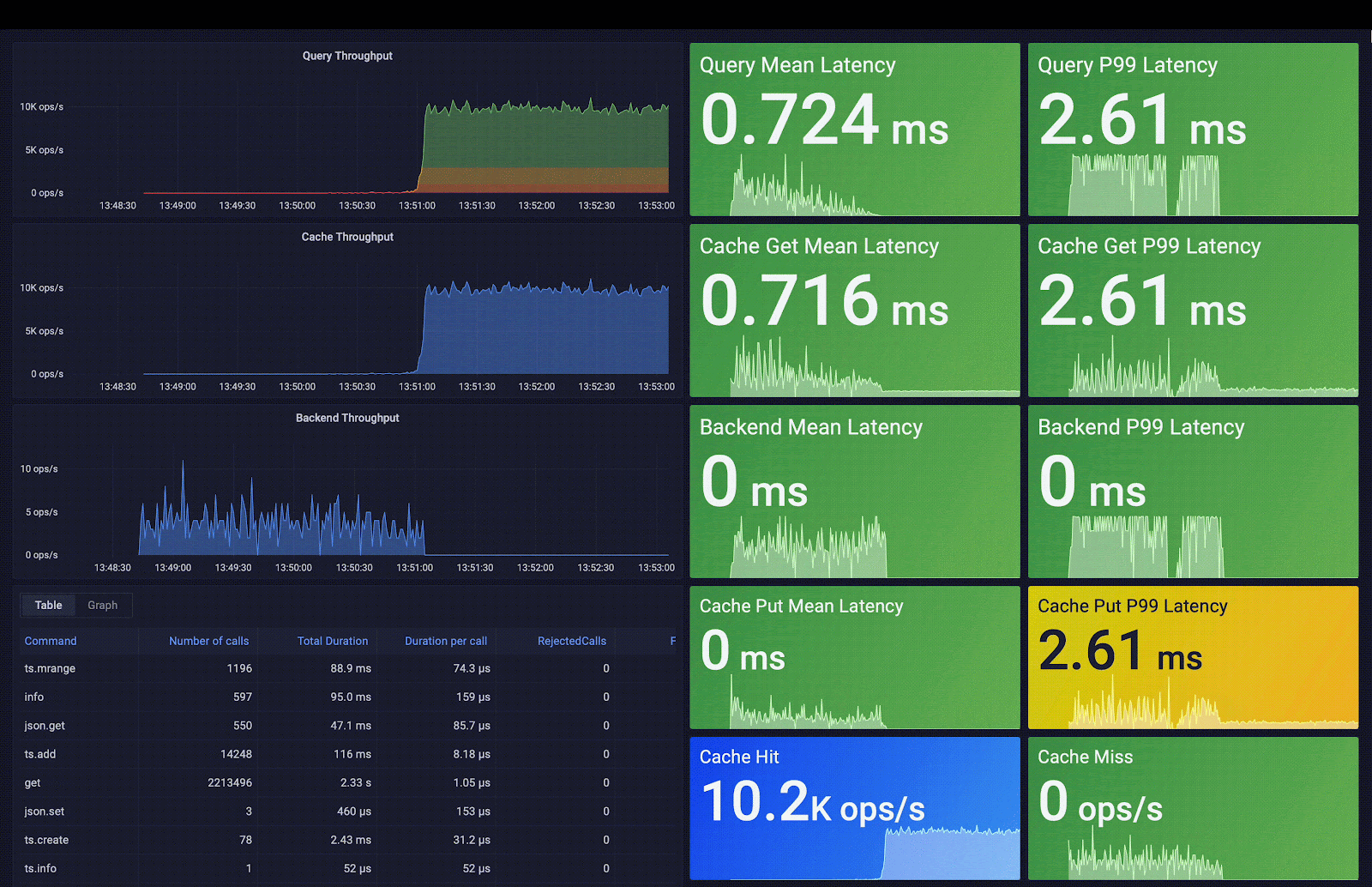
Redis Smart Cache capture la fréquence d’accès, le temps moyen de requête, les métadonnées des requêtes et des métriques supplémentaires. Ces métriques sont exposées via des tableaux de bord Grafana préconstruits ; les visualisations incluses vous aident à décider quelles règles de mise en cache des requêtes appliquer. Comme vous pouvez l’observer dans la capture d’écran suivante, la latence moyenne des requêtes passe de 3 secondes (latence backend moyenne) à 0,7 ms (latence cache moyenne), ce qui signifie une accélération de 4 200 fois la latence initiale.
2 - Redis SQL
Comme la plupart des bases de données NoSQL sur le marché, Redis ne vous permet pas d’interroger et d’inspecter les données avec le Structured Query Language (SQL). Redis fournit plutôt un ensemble de commandes pour récupérer les structures de données natives (Clé/valeurs, Hashes, Sets…). Cependant, ces commandes ne sont pas aussi complètes et complexes que ce que vous pouvez faire avec SQL (par exemple, obtenir les données personnelles des personnes ayant plus de 35 ans ou habitant à San Francisco).
Pour cette raison, Redis a développé un module appelé RediSearch qui permet l’interrogation, l’indexation secondaire et la recherche en texte intégral pour Redis. Ces fonctionnalités permettent des requêtes multi-champs, l’agrégation, la correspondance de phrases exactes, le filtrage numérique, le géo-filtrage et la recherche sémantique par similarité vectorielle en plus des requêtes textuelles.
L’idée est de créer des indices secondaires autres que les clés (primaires) et d’effectuer des requêtes sur ces indices. Par exemple, nous utilisons la commande FT.CREATE pour créer un index sur les clés préfixées par person: avec les champs : name, age et gender. Tout hash existant préfixé par person: est automatiquement indexé lors de la création.
FT.CREATE myIdx
ON HASH PREFIX 1 "person:"
SCHEMA
name TEXT NOSTEM
age NUMERIC SORTABLE
gender TAG SORTABLE
Vous pouvez maintenant utiliser la commande FT.SEARCH pour rechercher dans l’index des personnes dont les noms contiennent des mots spécifiques.
FT.SEARCH myIdx "Amine" RETURN 1 name
La commande précédente retourne toutes les personnes dont les noms contiennent « Amine ». Cherchons les personnes de plus de 35 ans dans Redis. Vous pouvez utiliser la commande FT.SEARCH pour rechercher dans l’index des personnes avec des champs age supérieurs à 35.
FT.SEARCH myIdx "@age:[(35 inf]"
En plus des hashes Redis, vous pouvez indexer et rechercher des documents JSON si votre base de données dispose à la fois de RediSearch et de RedisJSON.
Jusqu’ici, tout va bien ! Lorsque votre application utilise une bibliothèque cliente Redis, elle pourra facilement rechercher et interroger les données servies par Redis avec une faible latence. Pendant ce temps, vos analystes métier sont habitués au standard industriel, SQL. De nombreux outils puissants s’appuient sur SQL pour l’analytique, la création de tableaux de bord, la création de rapports enrichis et d’autres travaux de business intelligence, mais malheureusement, ils ne prennent pas en charge les commandes Redis nativement. C’est là qu’intervient Redis SQL sous deux formes : Redis SQL JDBC (Trino) et Redis SQL ODBC.
A - Redis SQL JDBC (Connecteur Trino)
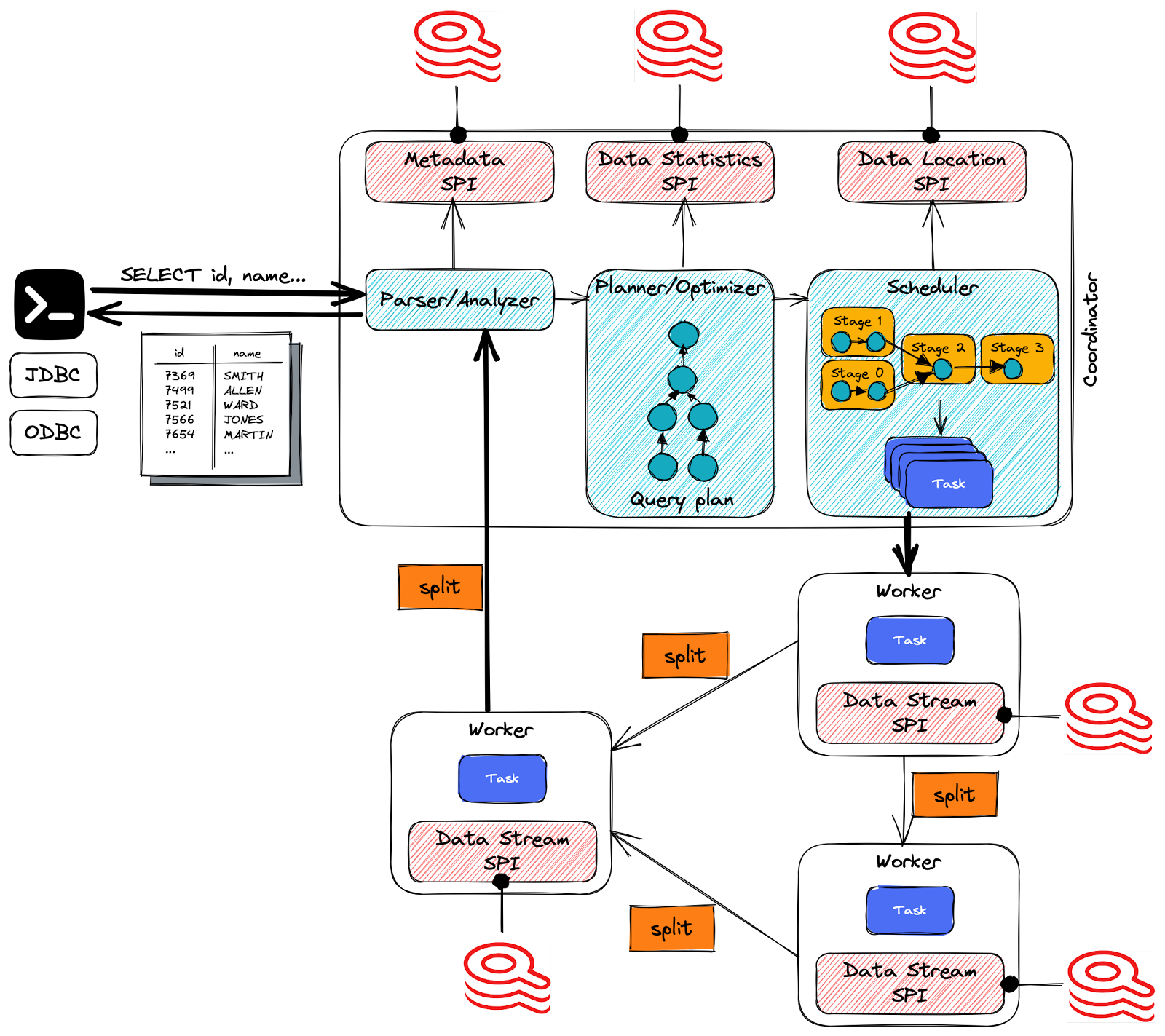
Redis SQL JDBC est un connecteur Trino qui permet l’accès aux données RediSearch depuis Trino. Trino est un moteur SQL distribué conçu pour interroger de grands ensembles de données sur une ou plusieurs sources de données hétérogènes. Il est conçu pour interroger efficacement de grandes quantités de données en utilisant des requêtes distribuées.
Trino a été initialement conçu pour interroger des données depuis HDFS et est devenu le choix évident pour interroger des données depuis n’importe où : stockage d’objets, systèmes de gestion de bases de données relationnelles (SGBDR), bases de données NoSQL et autres systèmes. Trino a également été conçu pour gérer l’entreposage de données et l’analytique : l’analyse de données, l’agrégation de grandes quantités de données et la production de rapports. Ces charges de travail sont souvent classées comme traitement analytique en ligne (OLAP).
Trino interroge les données là où elles se trouvent et ne nécessite pas de migration de données vers un emplacement unique. Trino peut interroger pratiquement n’importe quoi et est véritablement un système SQL-sur-Tout. Cela signifie que les utilisateurs n’ont plus besoin de s’appuyer sur des langages de requête ou des outils spécifiques pour interagir avec les données dans ces systèmes particuliers. Ils peuvent simplement utiliser Trino, leurs compétences SQL existantes, et leurs outils d’analytique, de tableaux de bord et de reporting bien compris.

Dans Trino, l’architecture basée sur les connecteurs est au cœur de la séparation du stockage et du calcul : un connecteur fournit à Trino une interface pour accéder à une source de données arbitraire. Chaque connecteur fournit une abstraction basée sur des tables sur la source de données sous-jacente. Tant que les données peuvent être exprimées en termes de tables, colonnes et lignes en utilisant les types de données disponibles pour Trino, un connecteur peut être créé et le moteur de requête peut utiliser les données pour le traitement des requêtes.
Trino est un moteur de requêtes SQL qui fonctionne de manière similaire aux bases de données et moteurs de requêtes à traitement parallèle massif (MPP). Cependant, au lieu de dépendre de la mise à l’échelle verticale d’un seul serveur, Trino peut distribuer horizontalement toutes les tâches de traitement sur un cluster de serveurs. Cela permet l’ajout de nœuds supplémentaires pour augmenter la puissance de traitement.
Le serveur coordinateur Trino effectue plusieurs tâches cruciales, notamment la réception des instructions SQL des utilisateurs, leur analyse, la planification des requêtes et la gestion des nœuds workers. En tant que composant central de la configuration Trino, il est le principal point de contact pour les clients se connectant à l’installation Trino.
Redis SQL est un connecteur Trino qui implémente le SPI, de sorte que Trino peut traduire les requêtes entrantes (SQL) vers les concepts de stockage de la source de données sous-jacente (Redis). Par exemple, ce connecteur permet d’effectuer des requêtes sur les indices RediSearch. Ainsi, vous pouvez interroger les données Redis en utilisant SQL et vous intégrer facilement avec n’importe quelle application compatible JDBC, comme les frameworks de visualisation, tels que Tableau et SuperSet, et les plateformes qui prennent en charge les bases de données compatibles JDBC (par exemple, Mulesoft).
Voyons comment cela fonctionne en pratique. Considérons ce fichier, qui contient le grand livre général d’une organisation. Un grand livre général représente le système de tenue des registres des données financières d’une entreprise, avec des enregistrements de comptes débiteurs et créditeurs. Il contient un enregistrement de chaque transaction financière qui se déroule pendant la vie d’une entreprise en exploitation et contient les informations de compte nécessaires pour préparer les états financiers de l’entreprise. Chaque transaction financière est associée à un numéro de compte (ACCOUNTNUM).
Dans la plupart des organisations, les numéros de compte font partie d’un Plan de Comptes (CoA). Un plan de comptes répertorie les noms des comptes qu’une entreprise a identifiés et mis à disposition pour enregistrer les transactions dans son grand livre général. Considérons le Plan de Comptes qui répertorie les comptes utilisés dans le grand livre général présenté précédemment et la table Nature Comptable, qui regroupe les comptes par nature (Actif, Capitaux Propres ou Passif).

Tout d’abord, ingérons ces trois tables à l’aide de l’outil RIOT-file. Pour la procédure d’installation et de configuration, voir Data & Redis - Partie 1
Nous allons ingérer et intégrer la table Grand Livre Général comme Hashes dans Redis. Pour cela, exécutez la commande suivante :
riot-file -h redis-12000.cluster.redis-serving.demo.redislabs.com -p 12000 -a redis-password import https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/GeneralLedger.csv --header hset --keyspace GeneralLedger --keys RECID
Nous faisons de même pour les autres tables, Plan de Comptes et Nature Comptable.
riot-file -h redis-12000.cluster.redis-serving.demo.redislabs.com -p 12000 -a redis-password import https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/ChartAccounts.csv --header hset --keyspace CoA --keys ACCOUNTNUM
riot-file -h redis-12000.cluster.redis-serving.demo.redislabs.com -p 12000 -a redis-password import https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/AccountingNature.csv --header hset --keyspace AccountingNature --keys AccountingNatureCode
Une fois vos données ingérées dans Redis, vous pouvez créer des indices secondaires sur les trois tables :
general_ledger comme index secondaire pour la table Grand Livre Général. Nous n’avons besoin d’indexer que le Numéro de Compte, le Montant de la Transaction (AMOUNTMST) et le Code de Devise.
FT.CREATE general_ledger
ON HASH
PREFIX 1 "GeneralLedger:"
SCHEMA
ACCOUNTNUM TEXT SORTABLE
AMOUNTMST NUMERIC SORTABLE
CURRENCYCODE TAG SORTABLE
chart_accounts comme index secondaire pour la table Plan de Comptes.
FT.CREATE chart_accounts
ON HASH
PREFIX 1 "CoA:"
SCHEMA
ACCOUNTNUM TEXT SORTABLE
Description TEXT NOSTEM
Nature TEXT SORTABLE
Statement TAG SORTABLE
AccountingNatureCode TAG SORTABLE
Et accounting_nature comme index secondaire pour la table Nature Comptable.
FT.CREATE accounting_nature
ON HASH
PREFIX 1 "AccountingNature:"
SCHEMA
AccountingNatureCode TAG SORTABLE
AccountingNature TEXT SORTABLE
Description TEXT NOSTEM
AccountGroup TAG SORTABLE
Vous pouvez maintenant tester ces indices en exécutant les commandes suivantes :
FT.SEARCH general_ledger "@AMOUNTMST:[(100000 inf] @CURRENCYCODE:{EUR|USD}"
FT.SEARCH chart_accounts "@ACCOUNTNUM:61110801"
FT.SEARCH accounting_nature "@AccountGroup:{Payables|Receivables}"
La première requête retourne les transactions financières supérieures à 10 000 euros ou dollars américains. La deuxième retourne les détails du numéro de compte 61110801. Enfin, la dernière requête retourne tous les numéros de comptes Fournisseurs1 et Clients2. Vous pouvez observer que l’utilisation des commandes RediSearch n’est pas évidente pour les ingénieurs de données et peut s’avérer être un vrai casse-tête si vous souhaitez effectuer des requêtes complexes.
Maintenant, lançons la CLI Trino pour constater rapidement qu’exécuter des requêtes SQL est beaucoup plus facile et simple :
trino --catalog redisearch --schema default
Essayons les mêmes requêtes RediSearch précédentes avec la syntaxe SQL en utilisant Redis SQL Trino.

Essayons une requête plus avancée similaire à celles exécutées dans les charges de travail analytiques. Nous utilisons Redis SQL Trino pour effectuer des jointures et des fonctions de fenêtrage entre les trois indices RediSearch : je demanderais d’obtenir la somme de toutes les transactions Clients et Fournisseurs dans le grand livre général. Pour cela, vous devez joindre general_ledger à chart_accounts via le AccountNumber, joindre chart_accounts à accounting_nature pour pouvoir regrouper et sommer les montants des transactions par AccountingGroup, puis filtrer les résultats pour ne sélectionner que les transactions liées aux Clients et Fournisseurs.

Le cas d’utilisation le plus pratique de Redis SQL Trino est de connecter des outils de visualisation de données à un datastore à faible latence comme Redis. En effet, Redis est un datastore en mémoire, et sa puissance réside dans sa capacité à servir les données avec les temps de réponse les plus rapides possibles.
Pour cette raison, Redis est fréquemment utilisé comme couche de service dans les architectures de pipelines de données (par exemple, architectures kappa, feature stores en ligne, etc.) et pour mettre en cache les requêtes d’applications OLAP afin d’accélérer le temps de réponse.
Par exemple, pour améliorer les performances de visualisation des données (par exemple, lors du rafraîchissement des tableaux de bord analytiques et des rapports), vous pouvez utiliser Redis pour stocker les jeux de données les plus fréquemment interrogés, créer des indices secondaires sur eux avec RediSearch, puis bénéficier du connecteur Trino pour RediSearch afin d’utiliser des requêtes SQL plutôt que des commandes RediSearch.
Voici un exemple d’URL JDBC utilisé pour créer une connexion de Tableau vers Redis SQL Trino :
jdbc:trino://localhost:8080/redisearch/default

B - Redis SQL ODBC
ODBC (Open Database Connectivity) est une spécification d’interface qui permet aux applications d’accéder aux données de divers systèmes de gestion de bases de données (SGBD) en utilisant un ensemble commun d’appels de fonctions. ODBC fait partie de l’Architecture des Services Ouverts Windows de Microsoft (WOSA), qui offre un moyen pour les applications de bureau basées sur Windows de se connecter à plusieurs environnements informatiques sans nécessiter de modification de l’application.
Redis SQL ODBC est un pilote ODBC natif qui vous permet d’intégrer Redis en toute transparence avec des applications de bureau basées sur Windows comme Microsoft Excel ou Power BI. Tout comme les autres outils présentés précédemment, cet outil peut considérablement améliorer les temps de réponse de vos requêtes Power BI. Avec le pilote Redis SQL ODBC installé, Power BI peut effectuer des requêtes sur une seule table contre des index secondaires (RediSearch) sur des hashes ou des documents JSON Redis en temps réel.

Redis SQL ODBC prend le SQL généré par les applications des utilisateurs finaux, comme Power BI, le traduit dans le langage de requête RediSearch, effectue la requête sur les hashes ou les documents JSON Redis en utilisant les index secondaires, puis arrange les résultats dans un ensemble de résultats conforme à ODBC pour la consommation par le frontend.
L’intégration de Redis SQL ODBC avec des applications de bureau Windows nécessite seulement une petite modification de configuration. Il vous suffit d’installer le pilote en téléchargeant le pack d’installation depuis la dernière version de Redis SQL ODBC. Décompressez-le, puis exécutez le fichier .msi inclus. Suivez ensuite les étapes du MSI pour installer le pilote.
Vous pouvez ensuite configurer la source de données Redis, en exécutant :
1. la commande suivante dans PowerShell (Windows 10+) en remplaçant l’hôte, le port, le nom d’utilisateur et le mot de passe par les informations d’identification appropriées.
Add-OdbcDSN -Name "Redis" -DriverName "Redis" -Platform "64-bit" -DsnType "User" -SetPropertyValue @("host=hostname", "port=portNum", "username=username", "password=password")
Ici, je réutilise la même base de données que la dernière section (Trino) :
Add-OdbcDSN -Name "Redis" -DriverName "Redis" -Platform "64-bit" -DsnType "User" -SetPropertyValue @("host=redis-12000.cluster.redis-serving.demo.redislabs.com", "port=12000", "username=default", "password=redis-password")
2. Ou, avec l’interface graphique des sources de données ODBC :

Pour cet outil, nous allons charger un jeu de données amusant ! Tim Renner a rassemblé un jeu de données sur data world avec de nombreux signalements d’ovnis ; nous allons charger ce jeu de données dans Redis, en utilisant RIOT-File (voir Data & Redis - Partie 1) et voir ce que nous pouvons en faire avec des applications de bureau basées sur Windows.
$ riot-file -h redis-12000.cluster.redis-serving.demo.redislabs.com -p 12000 -a redis-password import https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/nuforc_reports.csv.gz --process id="#index" --header hset --keyspace Report --keys id
Ensuite, nous allons créer un index secondaire sur les rapports ingérés créés par la dernière commande :
FT.CREATE ufo_report
ON HASH
PREFIX 1 "Report:"
SCHEMA
shape TEXT SORTABLE
city TEXT SORTABLE
state TEXT SORTABLE
country TEXT SORTABLE
city_longitude NUMERIC SORTABLE
city_latitude NUMERIC SORTABLE
Testons le pilote ODBC Redis avec une feuille Microsoft Excel. D’abord, nous exécutons « obtenir des données depuis une autre source » dans le menu Données, puis nous choisissons le menu « depuis un pilote ODBC ».
Ensuite, nous choisissons la source de données Redis dans l’invite et mettons la requête SQL que nous voulons exécuter contre l’index secondaire. Nous pouvons maintenant interroger des données dans notre base de données Redis Enterprise. Dans notre cas, nous avons un index RediSearch appelé ufo_reports, représentant les rapports de signalements d’ovnis stockés.

Maintenant que nous avons analysé nos données dans Microsoft Excel, nous pouvons créer quelques visualisations/graphiques de base dans Excel lui-même, ou nous pouvons exploiter notre pilote ODBC pour réaliser des visualisations de données plus avancées dans Power BI. De même qu’Excel, vous pouvez charger des données dans Power BI en choisissant le menu « Obtenir des données depuis une autre source de données » ou en cliquant sur le menu déroulant « Obtenir des données » et en appuyant sur « Plus… ». Vous pouvez également choisir de transformer les données et d’effectuer un filtrage sur les données chargées.
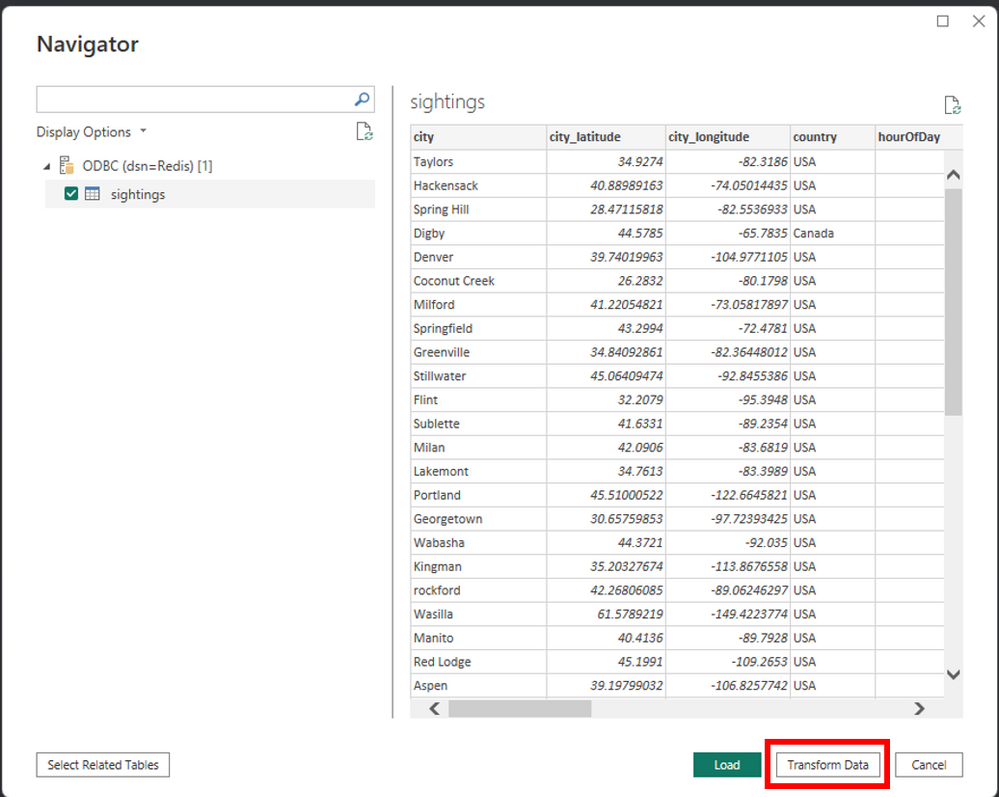
Vous pouvez filtrer vos données depuis l’Éditeur Power Query et sélectionner les colonnes que vous souhaitez charger. Par exemple, filtrons les états vers la Floride : d’abord, cliquez sur la flèche à côté de la colonne state puis sur « (Sélectionner tout) » pour désélectionner tous les états. Ensuite, cochez la case à côté de « FL » pour filtrer sur la Floride. Cliquez ensuite sur « OK » pour terminer le filtrage. Maintenant que nous avons chargé toutes nos données de « signalements » dans Power BI, créons un tableau de bord pour visualiser nos données.

Ce tutoriel montre que Redis SQL ODBC est une intégration transparente entre Redis et Power BI. Avec lui, nous pouvons apporter la vitesse et l’efficacité de Redis à nos rapports en utilisant le vénérable standard ODBC.
Machine Learning
Le deuxième domaine majeur du service de données est l’apprentissage automatique (ML). Avec l’émergence du génie ML comme domaine parallèle au génie des données, vous pourriez vous demander où les ingénieurs de données s’inscrivent dans le tableau. Mais pour être aligné avec l’état de l’art, le rôle principal des ingénieurs de données est de fournir aux data scientists et ingénieurs ML les données dont ils ont besoin pour faire leur travail. Dans les prochains articles, je présenterai plus en détail les outils et capacités fournis par Redis pour servir les applications d’apprentissage automatique. En bref, les façons les plus courantes de servir les données Redis pour les applications de Machine Learning sont :
1. L’échange de fichiers est une façon assez courante de servir des données. Les données organisées sont traitées et générées sous forme de fichiers à consommer directement par les utilisateurs finaux. Par exemple, une unité commerciale peut recevoir des données de factures d’une entreprise partenaire sous forme de CSV (données structurées). Un data scientist peut charger un fichier texte (données non structurées) de messages clients pour analyser les sentiments des plaintes clients. Nous avons utilisé RIOT dans Data & Redis - Partie 1 comme outil d’ingestion par lots. Nous avons souvent utilisé le paramètre import pour charger des données dans Redis. Cependant, RIOT-File permet également d’exporter (commande export) des données depuis Redis sous forme de fichier délimité, JSON ou XML. Vous pouvez également exporter des données par lots depuis Redis comme objets AWS S3 ou GCP Storage.
2. Les bases de données peuvent jouer le rôle de feature stores pour l’IA. Un feature store est un référentiel centralisé spécialement conçu pour gérer, stocker et partager les features utilisées dans les modèles d’apprentissage automatique. En apprentissage automatique, les features sont les variables d’entrée ou prédicteurs qui entraînent les modèles à faire des prédictions ou des classifications. Le feature store permet aux data scientists et ingénieurs de stocker, découvrir, partager et réutiliser des features entre différents modèles et applications, améliorant la collaboration et la productivité. Dans les prochains articles, j’utiliserai Redis comme Feature Store pour quelques applications de Machine Learning, comme les moteurs de recommandation ou les applications de détection de fraude.
Une autre façon de servir des données pour le ML est via des bases de données vectorielles. Une base de données vectorielle est un type de feature store qui contient des données sous forme de vecteurs (représentations mathématiques de points de données). Les algorithmes de Machine Learning permettent cette transformation de données non structurées en représentations numériques (vecteurs) qui capturent le sens et le contexte, bénéficiant des avancées dans le traitement du langage naturel et la vision par ordinateur.

La Recherche par Similarité Vectorielle (VSS) est une fonctionnalité clé d’une base de données vectorielle. Elle trouve des points de données similaires à un vecteur de requête donné dans une base de données vectorielle. Les cas d’utilisation populaires du VSS incluent les systèmes de recommandation, la recherche d’images et de vidéos, le traitement du langage naturel (comme ChatGPT) et la détection d’anomalies. Dans les prochains articles, je présenterai Redis comme base de données vectorielle pour les applications d’apprentissage automatique, telles que l’Analyse de Sentiments ou les Chatbots conversationnels.
3. Les moteurs de virtualisation de données : dans les sections précédentes, nous avons vu divers outils Redis qui permettent la virtualisation des données. Par exemple, la suite Redis SQL (JDBC et ODBC) fournit un moyen d’effectuer des requêtes fédérées : où les données sont extraites des index secondaires Redis, puis exposées aux systèmes et applications qui utilisent des requêtes SQL.
ETL Inversé (Reverse ETL)
De nos jours, le Reverse ETL est un terme populaire qui désigne le chargement de données d’une base de données en aval vers un système source. Par exemple, un ingénieur de données peut extraire des données clients et de commandes d’un CRM et les stocker dans un entrepôt de données pour les utiliser dans l’entraînement d’un modèle de scoring des prospects. Les résultats du modèle sont ensuite stockés dans l’entrepôt de données. L’équipe commerciale de l’entreprise a l’intention d’utiliser ces prospects scorés pour stimuler les ventes et nécessite donc d’y accéder. L’utilisation du Reverse ETL et le rechargement des prospects scorés dans le CRM est l’approche la plus simple pour ce produit de données. Le Reverse ETL prend les données traitées du côté sortie du parcours des données et les réinjecte dans les systèmes sources.
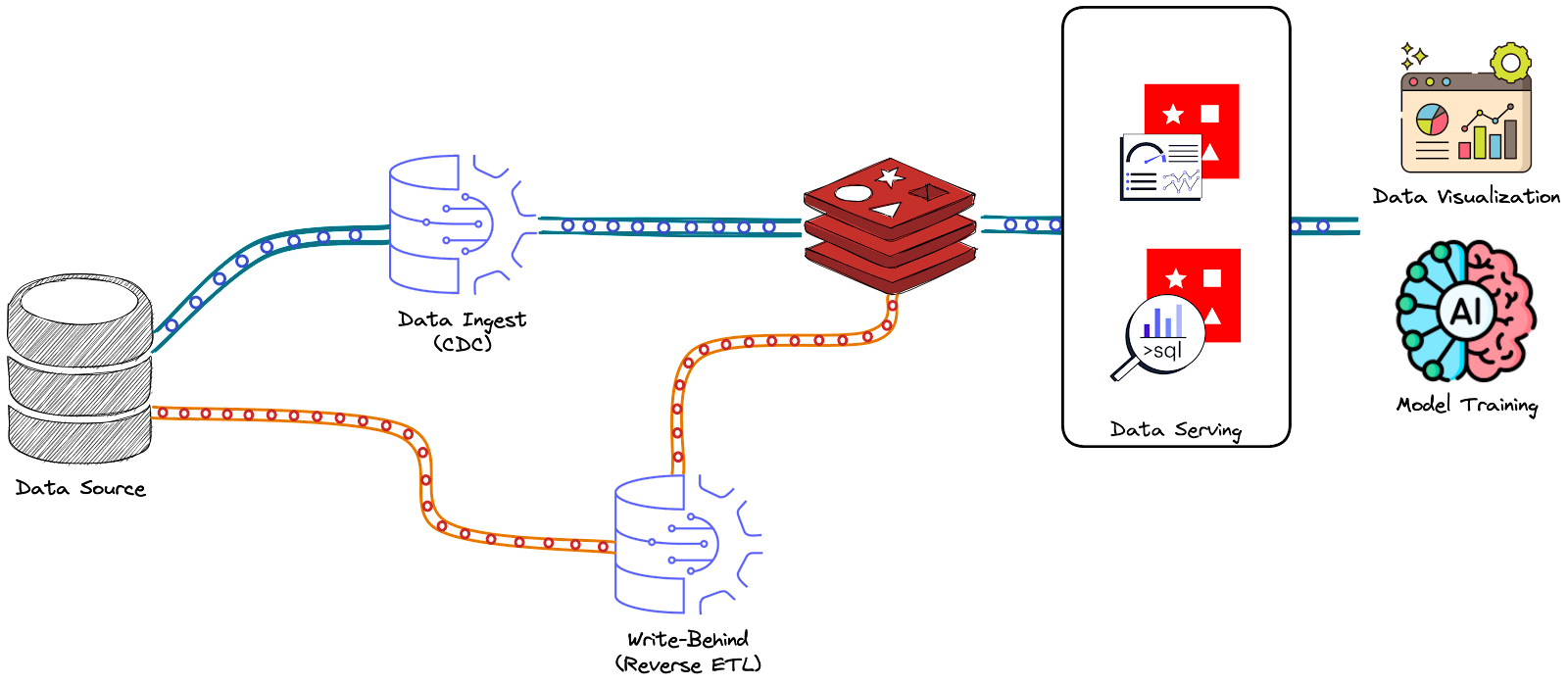
Dans Data & Redis - Partie 4, nous avons vu la politique Write-Behind fournie par Redis Data Integration (RDI). Dans ce scénario, les données sont synchronisées dans une base de données Redis et renvoyées vers certaines sources de données. En fait, cette politique peut être considérée comme un processus de Reverse ETL puisque vous pouvez la considérer comme un pipeline qui commence avec des données organisées dans Redis, puis filtre, transforme et les mappe vers les structures de données du datastore source. Cependant, RDI Write Behind est encore en développement et ne prend en charge que les datastores suivants : Cassandra, MariaDB, MySQL, Oracle, PostgreSQL et SQL Server.
Résumé
L’étape de service concerne les données en action. Mais qu’est-ce qu’une utilisation productive des données ? Pour répondre à cette question, vous devez considérer deux choses : quel est le cas d’utilisation, et qui est l’utilisateur ?
Le cas d’utilisation des données va bien au-delà de la consultation de rapports et de tableaux de bord. Des données de haute qualité et à fort impact attireront inévitablement de nombreux cas d’utilisation passionnants. Mais en recherchant des cas d’utilisation, demandez toujours : « Quelle action ces données vont-elles déclencher, et qui va effectuer cette action ? » avec la question de suivi appropriée : « Cette action peut-elle être automatisée ? ». Dans la mesure du possible, donnez la priorité aux cas d’utilisation avec le ROI le plus élevé possible.
Maintenant que nous avons parcouru le parcours des données, vous savez comment concevoir, architecturer, construire, maintenir et améliorer vos produits de données en utilisant Redis Enterprise. Dans les prochains articles, j’attirerai votre attention sur le cas d’utilisation le plus utilisé de Redis comme plateforme de données en temps réel. Cela impliquera un parcours de données de bout en bout appliquant tout ce que vous avez appris dans cette série.
Références
- A. I. Maarala, M. Rautiainen, M. Salmi, S. Pirttikangas et J. Riekki, “Low latency analytics for streaming traffic data with Apache Spark,” 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 2015, pp. 2855-2858, doi: 10.1109/BigData.2015.7364101.
- M. Fuller, M. Moser, M. Traverso, “Trino: The Definitive Guide”, 2e édition, O’Reilly Media, Inc. ISBN: 9781098137236
- Redis Smart Cache, Redis.
- Redis SQL Trino, Guide du développeur.
- “How to use Redis as a Data Source for Power BI with Redis SQL ODBC”, Blog Microsoft Azure.
- Features Store, Blog Redis.
- Vector Database, Blog Redis.
- Redis Data Integration (RDI), Guide du développeur.
1. Comptes Fournisseurs (AP) : les obligations à court terme d’une entreprise envers ses créanciers (par exemple, les fournisseurs) qui doivent encore être payées.
2. Comptes Clients (AR) : l’argent que les clients d’une entreprise doivent pour des biens ou services qu’ils ont reçus mais pas encore payés.