
Le traitement de données est au cœur de toute architecture de données. Il consiste à transformer des données brutes en informations exploitables grâce à des techniques d’analyse telles que des algorithmes d’apprentissage automatique ou des modèles statistiques, selon le type de problème à résoudre dans le contexte d’une organisation.
Nous avons vu dans les articles précédents que les données brutes, déjà extraites des sources de données, peuvent être préparées et transformées (à l’aide de Redis Gears) dans le format cible requis par les systèmes en aval. Dans cet article, nous poussons ce concept plus loin en couplant le traitement événementiel de RedisGears et l’ingestion basée sur des streams avec Redis Data Integration (RDI). Ainsi, vous pouvez imaginer que les données circulant dans vos systèmes opérationnels (par exemple, ERP, CRM…) seront ingérées dans Redis via un Change Data Capture (voir Data & Redis - partie 1) et traitées avec RedisGears pour obtenir des décisions opérationnelles rapides en quasi temps réel.
En fait, Redis Data Integration n’est pas seulement un outil d’intégration de données mais aussi un moteur de traitement de données qui repose sur Redis Gears. Il fournit donc un moyen plus simple d’implémenter des transformations de données (fichiers déclaratifs) pour éviter la complexité de Redis Gears.
Pré-requis
1 - Créer une base de données Redis
Pour cet article, vous devez installer et configurer quelques éléments. Tout d’abord, vous devez préparer un cluster Redis Enterprise, qui est le support de stockage cible. Ce support de stockage sera l’infrastructure cible pour les données transformées à cette étape. Vous pouvez utiliser ce projet pour créer un cluster Redis Enterprise chez le fournisseur cloud de votre choix.
Une fois le cluster Redis Enterprise créé, vous devez créer une base de données cible qui contiendra les données transformées. Redis Enterprise Software vous permet de créer et distribuer des bases de données sur un cluster de nœuds. Pour créer une nouvelle base de données, suivez les instructions ici.
Pour Redis Data Integration, vous avez besoin de deux bases de données : la base de données de configuration exposée sur redis-12000.cluster.redis-process.demo.redislabs.com:12000 et la base de données cible sur : redis-13000.cluster.redis-process.demo.redislabs.com:13000. N’oubliez pas d’ajouter le module RedisJSON lors de la création de la base de données cible.
2 - Installer RedisGears
Installons maintenant RedisGears sur le cluster. S’il est absent, suivez ce guide pour l’installer.
curl -s https://redismodules.s3.amazonaws.com/redisgears/redisgears.Linux-ubuntu20.04-x86_64.1.2.5.zip -o /tmp/redis-gears.zip
curl -v -k -s -u "<REDIS_CLUSTER_USER>:<REDIS_CLUSTER_PASSWORD>" -F "module=@/tmp/redis-gears.zip" https://<REDIS_CLUSTER_HOST>:9443/v2/modules
3 - Installer Redis Data Integration (RDI)
Pour la deuxième partie de cet article, vous devrez installer Redis Data Integration (RDI). L’installation de Redis Data Integration se fait via la CLI RDI. La CLI doit avoir un accès réseau à l’API du cluster Redis Enterprise (port 9443 par défaut). Vous devez d’abord télécharger le package hors ligne RDI :
UBUNTU20.04
wget https://qa-onprem.s3.amazonaws.com/redis-di/latest/redis-di-offline-ubuntu20.04-latest.tar.gz -O /tmp/redis-di-offline.tar.gz
UBUNTU18.04
wget https://qa-onprem.s3.amazonaws.com/redis-di/latest/redis-di-offline-ubuntu18.04-latest.tar.gz -O /tmp/redis-di-offline.tar.gz
RHEL8
wget https://qa-onprem.s3.amazonaws.com/redis-di/latest/redis-di-offline-rhel8-latest.tar.gz -O /tmp/redis-di-offline.tar.gz
RHEL7
wget https://qa-onprem.s3.amazonaws.com/redis-di/latest/redis-di-offline-rhel7-latest.tar.gz -O /tmp/redis-di-offline.tar.gz
Copiez et décompressez le fichier redis-di-offline.tar.gz téléchargé dans le nœud maître de votre cluster Redis sous le répertoire /tmp :
tar xvf /tmp/redis-di-offline.tar.gz -C /tmp
Installez ensuite la CLI RDI en décompressant redis-di.tar.gz dans le répertoire /usr/local/bin/ :
sudo tar xvf /tmp/redis-di-offline/redis-di-cli/redis-di.tar.gz -C /usr/local/bin/
Exécutez la commande create pour configurer la base de données de configuration Redis Data Integration (sur le port 13000) dans un cluster Redis Enterprise existant :
redis-di create --silent --cluster-host <CLUSTER_HOST> --cluster-user <CLUSTER_USER> --cluster-password <CLUSTER_PASSWORD> --rdi-port <RDI_PORT> --rdi-password <RDI_PASSWORD> --rdi-memory 512
Enfin, exécutez la commande scaffold pour générer des fichiers de configuration pour Redis Data Integration et le connecteur Debezium Redis Sink :
redis-di scaffold --db-type <cassandra|mysql|oracle|postgresql|sqlserver> --dir <PATH_TO_DIR>
Dans notre article, nous allons capturer une base de données SQL Server, choisissez donc (sqlserver). Les fichiers suivants seront créés dans le répertoire fourni :
├── debezium
│ └── application.properties
├── jobs
│ └── README.md
└── config.yaml
config.yaml- Fichier de configuration Redis Data Integration (définitions de la base de données cible, applier, etc.)debezium/application.properties- Fichier de configuration du serveur Debeziumjobs- Tâches de transformation de données, lire ici
Pour utiliser Debezium comme conteneur Docker, téléchargez l’image Debezium :
wget https://qa-onprem.s3.amazonaws.com/redis-di/debezium/debezium_server_2.1.1.Final_offline.tar.gz -O /tmp/debezium_server.tar.gz
et chargez-la comme image Docker.
docker load < /tmp/debezium_server.tar.gz
Puis étiquetez l’image :
docker tag debezium/server:2.1.1.Final_offline debezium/server:2.1.1.Final
docker tag debezium/server:2.1.1.Final_offline debezium/server:latest
Pour le déploiement sans conteneur, vous devez installer Java 11 ou Java 17. Téléchargez ensuite Debezium Server 2.1.1.Final depuis ici.
Décompressez Debezium Server :
tar xvfz debezium-server-dist-2.1.1.Final.tar.gz
Copiez le fichier application.properties généré par le scaffold (créé par la commande scaffold) dans le répertoire debezium-server/conf extrait. Vérifiez que vous avez configuré ce fichier selon ces instructions.
Si vous utilisez Oracle comme base de données source, notez que Debezium Server n’inclut pas le pilote JDBC Oracle. Vous devez le télécharger et le placer dans le répertoire debezium-server/lib :
cd debezium-server/lib
wget https://repo1.maven.org/maven2/com/oracle/database/jdbc/ojdbc8/21.1.0.0/ojdbc8-21.1.0.0.jar
Démarrez ensuite Debezium Server depuis le répertoire debezium-server :
./run.sh
Traitement de données avec Redis Data Integration
La transformation de données est une partie critique du parcours des données. Ce processus peut effectuer des tâches constructives telles que l’ajout ou la copie d’enregistrements et de champs, des actions destructives comme le filtrage et la suppression de valeurs spécifiques, des ajustements esthétiques pour standardiser les valeurs, ou des changements structurels incluant le renommage de colonnes, leur déplacement et leur fusion.
La fonctionnalité clé offerte par RDI est la correspondance des données provenant du serveur Debezium (représentant des données de ligne d’une base de données source ou un changement d’état de ligne) vers une paire clé/valeur Redis. Les données entrantes incluent le schéma. Par défaut, chaque ligne source est convertie en un Hash ou une clé JSON dans Redis. RDI utilisera un ensemble de handlers pour convertir automatiquement chaque colonne source en un champ Hash Redis ou un attribut JSON en fonction du type Debezium dans le schéma.
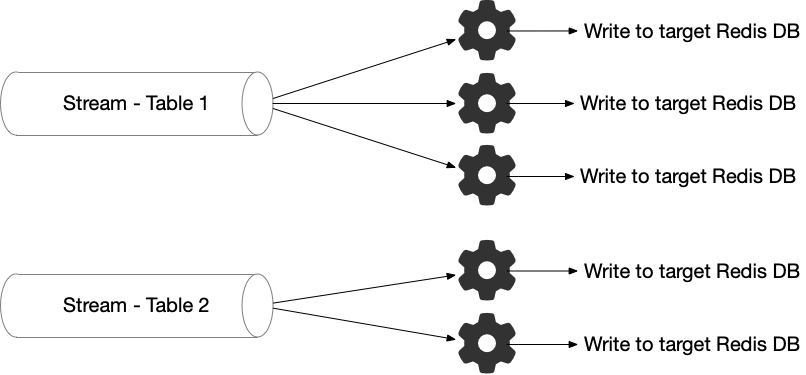
Cependant, si vous souhaitez personnaliser ce mappage par défaut ou ajouter une nouvelle transformation, RDI fournit des Transformations de Données Déclaratives (fichiers YAML). Chaque fichier YAML contient un Job, un ensemble de transformations par table source. La source est généralement une table ou une collection de base de données et est spécifiée comme le nom complet de cette table/collection. Le job contient des étapes logiques pour transformer les données dans la sortie souhaitée et les stocker dans Redis (sous forme de Hash ou JSON). Tous ces fichiers seront téléchargés dans Redis Data Integration à l’aide de la commande deploy lorsqu’ils sont disponibles dans le dossier jobs :
├── debezium
│ └── application.properties
├── jobs
│ └── README.md
└── config.yaml
Nous avons vu dans Data 101 - partie 5 que les pipelines nécessaires pour exécuter les processus de transformation peuvent être implémentés en utilisant l’une de ces approches :
- Outils centrés sur le code : bibliothèques d’analyse et de manipulation construites sur des langages de programmation généralistes (Scala, Java ou Python). Ces bibliothèques manipulent les données en utilisant les structures de données natives du langage de programmation.
- Outils centrés sur les requêtes : utilisent un langage de requête comme SQL (Structured Query Language) pour gérer et manipuler les jeux de données. Ces langages peuvent être utilisés pour créer, mettre à jour et supprimer des enregistrements, ainsi que pour interroger les données pour des informations spécifiques.
- Outils hybrides : implémentent SQL sur des langages de programmation généralistes. C’est le cas des bibliothèques comme Apache Spark ou Apache Kafka, qui fournit un dialecte SQL appelé KSQL.
Redis Data Integration (RDI) utilise l’approche hybride puisque tous les jobs de transformation sont implémentés dans un format lisible par l’homme (fichiers YAML) qui intègre JMESPath et/ou SQL.

Les fichiers YAML acceptent les blocs/champs suivants :
source - Cette section décrit la table sur laquelle ce job opère :
server_name: nom logique du serveur (optionnel)db: nom de la base de données (optionnel)schema: schéma de la base de données (optionnel)table: table de la base de donnéesrow_format: format des données à transformer : data_only (par défaut) - charge utile uniquement, full - enregistrement de modification complet
transform : cette section comprend une série de blocs par lesquels les données doivent passer. Voir la documentation des blocs pris en charge et des fonctions personnalisées JMESPath.
output - Cette section comprend les sorties où les données doivent être écrites :
- Redis :
uses:redis.write: écriture dans une structure de données Redis
with:connection: nom de la connexionkey: permet de remplacer la clé de l’enregistrement en appliquant une logique personnalisée :expression: expression à exécuterlanguage: langage d’expression, JMESPath ou SQL
- SQL :
uses:relational.write: écriture dans un datastore compatible SQL
with:connection: nom de la connexionschema: schématable: table ciblekeys: tableau de colonnes clésmapping: tableau de colonnes de mappageopcode_field: nom du champ dans la charge utile qui contient l’opération (c - create, d - delete, u - update) pour cet enregistrement dans la base de données
J’ai détaillé de nombreux archétypes de transformations de données dans Data 101 - partie 5 et il est intéressant d’évaluer Redis Data Integration à travers cette liste de capacités. Ainsi, vous pouvez voir comment effectuer différents types de transformations avec RDI.
1 - Filtrage
Ce processus sélectionne un sous-ensemble de votre jeu de données (colonnes spécifiques) qui nécessite une transformation, une visualisation ou une analyse. Cette sélection peut être basée sur certains critères, comme des valeurs spécifiques dans une ou plusieurs colonnes, et aboutit généralement à l’utilisation d’une partie seulement des données d’origine. Le filtrage vous permet d’identifier rapidement les tendances et les modèles au sein de votre jeu de données qui n’étaient peut-être pas visibles auparavant. Il vous permet également de vous concentrer sur des aspects particuliers d’intérêt sans avoir à parcourir toutes les informations disponibles. De plus, cette technique peut réduire la complexité en éliminant les détails inutiles tout en préservant les informations importantes sur la structure de données sous-jacente.

En utilisant Redis Data Integration, le filtrage des données des employés (exemple ci-dessus) pour ne conserver que les personnes ayant un salaire supérieur à 1 000 peut être implémenté avec les blocs YAML suivants :
source:
table: Employee
transform:
- uses: filter
with:
language: sql
expression: SAL>1000
Lorsque vous placez ce fichier YAML dans le dossier jobs, Redis Data Integration capturera les modifications de la table source et appliquera le filtre pour ne stocker que les enregistrements confirmant l’expression de filtrage (voir Data & Redis - partie 1 pour la configuration RDI et SQL Server).

2 - Enrichissement
Ce processus comble les lacunes de base dans le jeu de données. Il améliore également les informations existantes en complétant les données incomplètes ou manquantes avec un contexte pertinent. Il vise à améliorer la précision, la qualité et la valeur pour de meilleurs résultats.

Supposons l’exemple ci-dessus. Nous devons remplacer tous les salaires NULL dans la table des employés par une valeur par défaut de 0. En SQL, la fonction COALESCE retourne la première valeur non-NULL dans la liste d’attributs. Ainsi COALESCE(SAL, 0) retourne le salaire s’il n’est pas null ou 0 sinon. Avec RDI, nous pouvons implémenter cet enrichissement en utilisant le job suivant :
source:
table: Employee
transform:
- uses: map
with:
expression:
EMPNO: EMPNO
ENAME: ENAME
SAL: COALESCE(SAL, 0)
language: sql
Dans cette configuration, nous avons utilisé le bloc map qui mappe chaque enregistrement source vers une nouvelle sortie basée sur les expressions. Ici, nous n’avons modifié que le champ salary qui implémente l’expression COALESCE.

Si vous utilisez SQL Server, une autre alternative pour effectuer cet enrichissement est d’utiliser la fonction ISNULL. Ainsi, nous pouvons utiliser ISNULL(SAL, 0) dans le bloc d’expression. La fonction ISNULL et l’expression COALESCE ont un objectif similaire mais peuvent se comporter différemment. Comme ISNULL est une fonction, elle n’est évaluée qu’une seule fois. Cependant, les valeurs d’entrée pour l’expression COALESCE peuvent être évaluées plusieurs fois. De plus, la détermination du type de données de l’expression résultante est différente. ISNULL utilise le type de données du premier paramètre, COALESCE suit les règles d’expression CASE et retourne le type de données de la valeur ayant la précédence la plus élevée.
source:
table: Employee
transform:
- uses: map
with:
expression:
EMPNO: EMPNO
ENAME: ENAME
SAL: ISNULL(SAL, 0)
language: sql
3 - Séparation (Splitting)
La séparation de champs en plusieurs champs consiste en deux opérations atomiques : l’ajout des nouveaux champs selon des règles de transformation spécifiques, puis la suppression du champ source (colonne divisée).

Dans l’exemple ci-dessus, nous séparons EFULLNAME en deux champs : ELASTNAME et EFIRSTNAME. La configuration suivante utilise le bloc add_field pour créer les nouveaux champs ELASTNAME et EFIRSTNAME. Ensuite, nous pouvons utiliser la fonction SUBSTRING de SQL ou la fonction SPLIT de JMESPath. Dans les deux cas, nous avons besoin du bloc supplémentaire remove_field pour supprimer la colonne source EFULLNAME.
source:
table: Employee
transform:
- uses: add_field
with:
fields:
- field: EFIRSTNAME
language: jmespath
expression: split(EFULLNAME, ', ')[0]
- field: ELASTNAME
language: jmespath
expression: split(EFULLNAME, ', ')[1]
- uses: remove_field
with:
field: EFULLNAME
La fonction split décompose EFULLNAME en un tableau en utilisant les séparateurs de chaîne fournis comme paramètres (le caractère virgule comme séparateur).

4 - Fusion (Merging)
La fusion de plusieurs champs en un seul consiste en deux opérations atomiques : l’ajout du nouveau champ selon une règle de transformation spécifique, puis la suppression des champs source (colonnes fusionnées).

Dans l’exemple ci-dessus, nous fusionnons EFIRSTNAME et ELASTNAME en un seul champ : EFULLNAME. La configuration suivante utilise le bloc add_field pour créer le nouveau champ EFULLNAME et deux blocs remove_field pour supprimer les colonnes fusionnées EFIRSTNAME et ELASTNAME. Pour exprimer la règle de transformation, nous pouvons utiliser la fonction CONCAT_WS de SQL ou les fonctions JOIN / CONCAT de JMESPath.
source:
table: Employee
transform:
- uses: add_field
with:
fields:
- field: EFULLNAME
language: jmespath
expression: concat([EFIRSTNAME, ' ', ELASTNAME])
- uses: remove_field
with:
fields:
- field: EFIRSTNAME
- field: ELASTNAME

5 - Suppression (Removing)
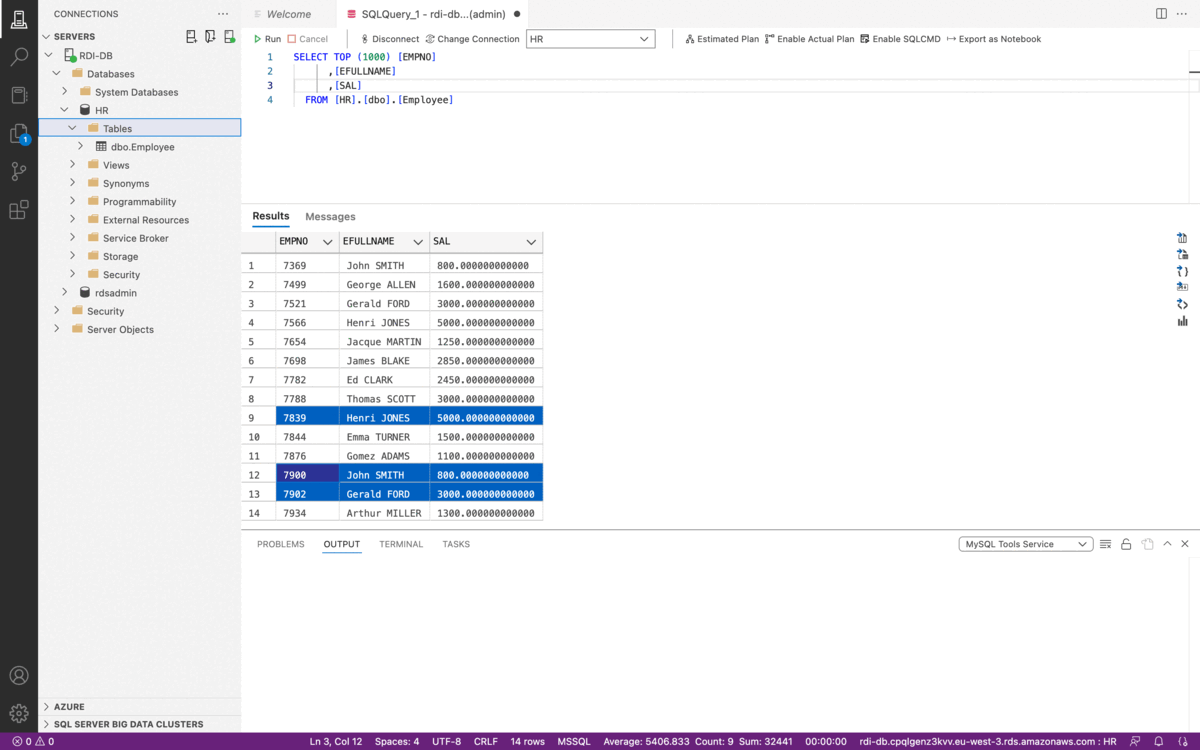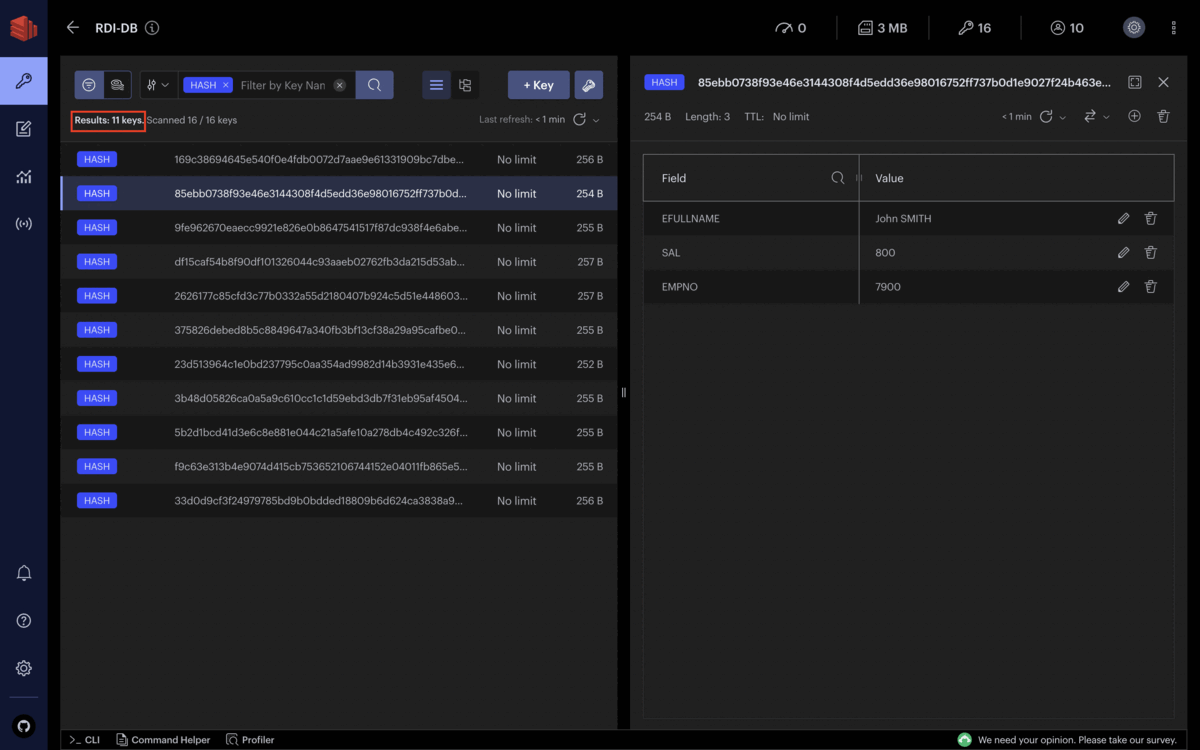
Outre la suppression de colonnes spécifiques de la source avec le bloc remove_field ou même l’évitement du chargement de certaines colonnes par filtrage, nous pourrions avoir besoin de supprimer des parties des données selon une condition spécifique, comme les doublons. Dans ce cas, Redis Data Integration ne dispose pas de bloc ou de fonction spécifique pour effectuer la suppression des doublons. Cependant, nous pouvons utiliser le bloc key pour créer une clé personnalisée pour la sortie composée de tous les champs qui forment le doublon.

Par exemple, supposons le cas d’utilisation ci-dessus. Si nous observons la colonne EMPNO, nous avons un identifiant distinct pour chaque enregistrement. Cependant, trois enregistrements sont en réalité des doublons. Dans ce cas, nous voulons supprimer ces doublons selon les champs EFULLNAME et SAL et non selon EMPNO. La solution dans RDI est de créer une nouvelle clé qui préserve l’unicité des enregistrements : une clé composée de la concaténation de EFULLNAME et SAL. Ainsi, RDI peut supprimer les doublons basés sur la clé nouvellement créée.
source:
table: Employee
output:
- uses: redis.write
with:
connection: target
key:
expression: hash(concat([EFULLNAME, '-', SAL]), 'sha3_512')
language: jmespath
De plus, nous utilisons la fonction hash pour créer un identifiant plutôt qu’un ensemble de champs concaténés. Cependant, sachez qu’il est possible que deux concaténations (chaînes différentes) aient les mêmes valeurs de hachage. Cela peut se produire parce que nous prenons le modulo ‘M’ dans la valeur de hachage finale. Dans ce cas, deux combinaisons différentes de (EFULLNAME ‘-‘ SAL) peuvent avoir les mêmes valeurs de hachage, appelé une collision.
Cependant, les chances de collisions aléatoires sont négligeablement faibles, même pour des milliards de données. Parce que la série SHA-3 est conçue pour offrir une résistance aux collisions de 2n/2. Dans notre transformation, nous avons choisi SHA3-512, qui offre 2256 (soit 1 chance sur 115 792 089 237 316 195 423 570 985 008 687 907 853 269 984 665 640 564 039 457 584 007 913 129 639 936 d’obtenir une autre combinaison de chaînes ayant le même hachage !
6 - Dérivation
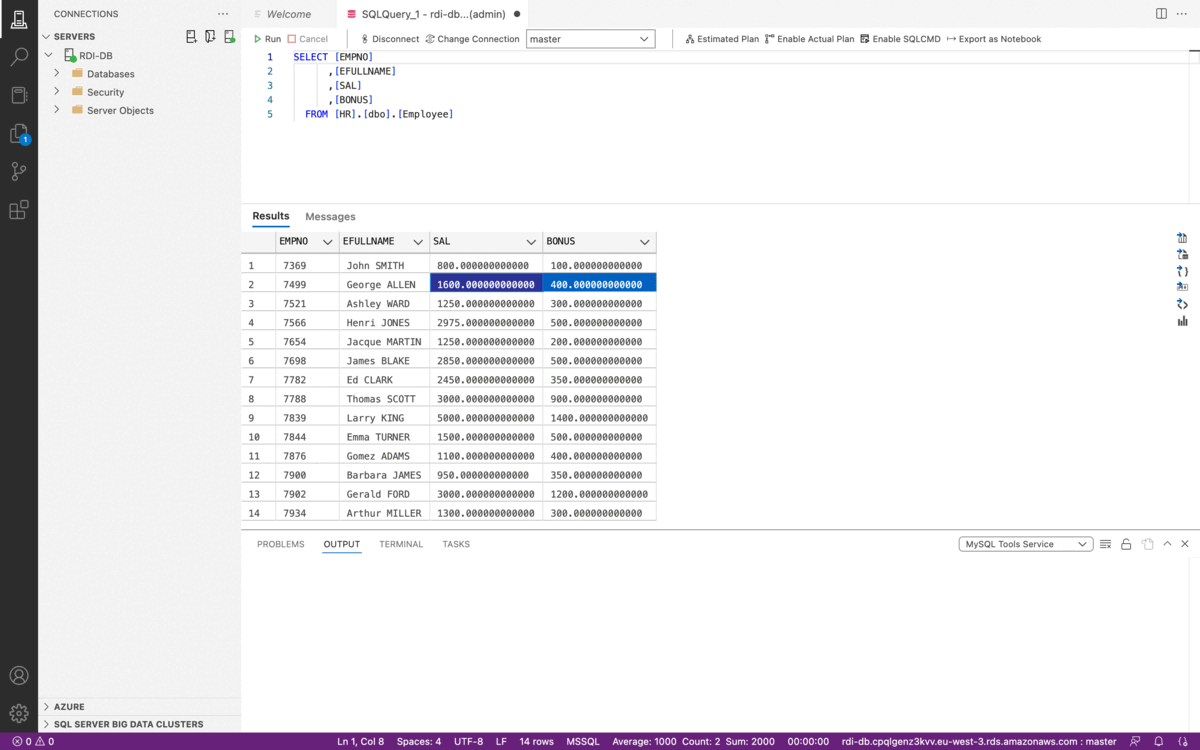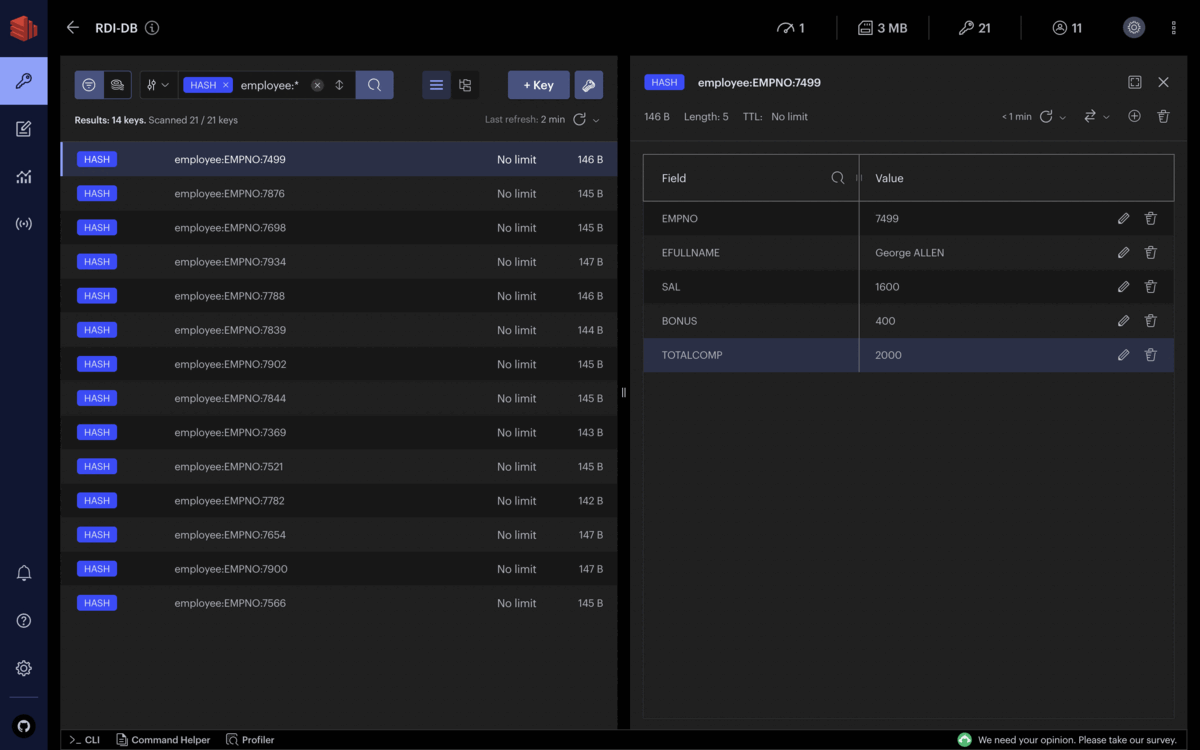
La dérivation consiste en des calculs transversaux entre colonnes. Avec RDI, nous pouvons facilement créer un nouveau champ basé sur des calculs à partir de champs existants. Supposons l’exemple ci-dessous. Nous devons calculer la rémunération totale de chaque employé en fonction des salaires et des primes qu’il reçoit.

Le job suivant implémente ce type de dérivation en SQL en additionnant les champs SAL et BONUS et en les stockant dans un champ supplémentaire appelé TOTALCOMP :
source:
table: Employee
transform:
- uses: add_field
with:
fields:
- field: TOTALCOMP
language: sql
expression: SAL + BONUS
7 - Dénormalisation des données
Redis Data Integration (RDI) a une approche différente pour effectuer des jointures entre deux tables ayant des relations un-à-plusieurs ou plusieurs-à-un. Cette approche est appelée la stratégie d’imbrication (nesting strategy). Elle consiste à organiser les données dans une structure logique où la relation parent-enfant est convertie en un schéma basé sur l’imbrication. Les données dénormalisées contiennent souvent des valeurs dupliquées lorsqu’elles sont représentées sous forme de tables ou de hashes, ce qui augmente les besoins de stockage mais accélère les requêtes puisque toutes les informations pertinentes pour une tâche donnée peuvent se trouver dans une seule table au lieu de devoir joindre plusieurs tables/hashes avant d’exécuter des requêtes.

Cependant, vous pouvez choisir d’effectuer la dénormalisation en format JSON. Dans ce cas, aucune duplication ne sera représentée ; donc aucun impact sur le stockage puisque la relation parent-enfant est simplement reflétée hiérarchiquement.
Supposons les deux tables : Department et Employee. Nous allons créer une transformation de données déclarative qui dénormalise ces deux tables en une structure imbriquée unique en JSON. L’objectif est d’obtenir les détails des employés dans chaque département.

Créons le fichier suivant dans le répertoire jobs. Ce fichier déclaratif fusionne les deux tables en un seul objet JSON. Il démontre également la facilité de configurer une telle transformation complexe avec un simple fichier déclaratif YAML.
source:
table: Employee
output:
- uses: redis.write
with:
nest:
parent:
table: Department
nesting_key: EMPNO # cannot be composite
parent_key: DEPTNO # cannot be composite
path: $.Employees # path must start from root ($)
structure: map
Lors de l’utilisation du connecteur SQL Server Debezium, il est recommandé de disposer d’un utilisateur dédié avec les permissions minimales requises dans SQL Server pour contrôler le rayon d’impact. Pour cela, vous devez exécuter le script T-SQL ci-dessous :
USE master
GO
CREATE LOGIN dbzuser WITH PASSWORD = 'dbz-password'
GO
USE HR
GO
CREATE USER dbzuser FOR LOGIN dbzuser
GO
Et accordez les permissions requises au nouvel utilisateur :
USE HR
GO
EXEC sp_addrolemember N'db_datareader', N'dbzuser'
GO
Vous devez ensuite activer le Change Data Capture (CDC) pour chaque base de données et table que vous souhaitez capturer.
EXEC msdb.dbo.rds_cdc_enable_db 'HR'
GO
Exécutez ce script T-SQL pour chaque table dans la base de données et remplacez le nom de la table dans @source_name par les noms des tables (Employee et Department) :
USE HR
GO
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'<Table_Name>',
@role_name = N'db_cdc',
@supports_net_changes = 0
GO
Enfin, l’utilisateur Debezium créé précédemment (dbzuser) doit avoir accès aux données de modification capturées, il doit donc être ajouté au rôle créé à l’étape précédente.
USE HR
GO
EXEC sp_addrolemember N'db_cdc', N'dbzuser'
GO
Vous pouvez vérifier l’accès en exécutant ce script T-SQL en tant qu’utilisateur dbzuser :
USE HR
GO
EXEC sys.sp_cdc_help_change_data_capture
GO
Dans le fichier de configuration RDI config.yaml, vous devez ajouter certains des paramètres suivants.
connections:
target:
host: redis-13000.cluster.redis-ingest.demo.redislabs.com
port: 13000
user: default
password: rdi-password
applier:
target_data_type: json
json_update_strategy: merge
Attention : Si vous souhaitez exécuter des jobs de normalisation/dénormalisation, il est obligatoire de charger la version 0.100 (au minimum) de Redis Data Integration.
Pour UBUNTU20.04
wget https://qa-onprem.s3.amazonaws.com/redis-di/0.100.0/redis-di-ubuntu20.04-0.100.0.tar.gz -O /tmp/redis-di-offline.tar.gz
Pour UBUNTU18.04
wget https://qa-onprem.s3.amazonaws.com/redis-di/0.100.0/redis-di-ubuntu18.04-0.100.0.tar.gz -O /tmp/redis-di-offline.tar.gz
Pour RHEL8
wget https://qa-onprem.s3.amazonaws.com/redis-di/0.100.0/redis-di-rhel8-0.100.0.tar.gz -O /tmp/redis-di-offline.tar.gz
Pour RHEL7
wget https://qa-onprem.s3.amazonaws.com/redis-di/0.100.0/redis-di-rhel7-0.100.0.tar.gz -O /tmp/redis-di-offline.tar.gz
Installez ensuite la CLI RDI en décompressant redis-di-offline.tar.gz dans le répertoire /usr/local/bin/ :
sudo tar xvf /tmp/redis-di-offline.tar.gz -C /usr/local/bin/
Mettez à niveau votre moteur Redis Data Integration (RDI) pour être compatible avec la nouvelle CLI redis-di. Pour cela, exécutez :
redis-di upgrade --cluster-host cluster.redis-process.demo.redislabs.com --cluster-user [CLUSTER_ADMIN_USER] --cluster-password [ADMIN_PASSWORD] --rdi-host redis-13000.cluster.redis-process.demo.redislabs.com --rdi-port 13000 --rdi-password rdi-password
Exécutez ensuite la commande deploy pour déployer la configuration locale dans la base de données de configuration RDI distante :
redis-di deploy --rdi-host redis-12000.cluster.redis-process.demo.redislabs.com --rdi-port 12000 --rdi-password rdi-password
Changez de répertoire vers votre dossier de configuration Redis Data Integration créé par la commande scaffold, puis exécutez :
docker run -d --name debezium --network=host --restart always -v $PWD/debezium:/debezium/conf --log-driver local --log-opt max-size=100m --log-opt max-file=4 --log-opt mode=non-blocking debezium/server:2.1.1.Final
Vérifiez le journal du serveur Debezium :
docker logs debezium --follow

Redis Data Integration (RDI) effectue la dénormalisation des données de manière performante et complète. Il ne structure pas seulement les tables source en une seule structure, mais peut également gérer les données arrivant en retard : si les données imbriquées sont capturées avant les données du niveau parent, RDI crée une structure JSON pour les enregistrements du niveau enfant, et dès que les données du niveau parent arrivent, RDI crée la structure pour l’enregistrement du niveau parent, puis fusionne tous les enregistrements enfants (imbriqués) dans leur structure parente. Par exemple, considérons ces deux tables : Invoice et InvoiceLine. Lorsque vous essayez d’insérer une InvoiceLine contenue par une Invoice avant cette dernière, RDI créera la structure JSON pour InvoiceLine et attendra la structure Invoice. Dès que vous insérez l’Invoice contenante, RDI initie la structure JSON Invoice et la fusionne avec les InvoiceLines créées précédemment.

L’un des problèmes observés jusqu’à présent avec la dénormalisation de RDI est la limite d’imbrication (limitée à un seul niveau). Il n’est actuellement possible de dénormaliser que deux tables avec des relations un-à-plusieurs ou plusieurs-à-un.
8 - Normalisation des données
En plus de l’ingestion de données, Redis Data Integration (RDI) permet également de synchroniser les données stockées dans une base de données Redis avec certains datastores en aval. Ce scénario est appelé Write-Behind, et vous pouvez le considérer comme un pipeline qui commence avec des événements Capture Data Change (CDC) pour une base de données Redis, puis filtre, transforme et mappe les données vers un datastore cible (par exemple, une base de données relationnelle).

Nous avons vu dans la dernière section que nous pouvons effectuer une dénormalisation des données pour joindre plusieurs tables avec des relations un-à-plusieurs ou plusieurs-à-un en une seule structure dans Redis. D’un autre côté, la normalisation des données est l’une des transformations que nous pouvons effectuer en utilisant le cas d’utilisation Write-Behind. La normalisation des données consiste à organiser les données dans une structure logique pouvant être utilisée pour améliorer les performances et réduire la redondance. Cela implique de décomposer des jeux de données complexes en morceaux plus petits et plus gérables en éliminant les informations redondantes ou en consolidant les éléments liés ensemble. La normalisation contribue également à garantir la cohérence du stockage et de l’accès aux données dans différents systèmes.

Supposons que ce document JSON est stocké dans Redis, composé d’une Invoice avec les détails qu’elle contient (InvoiceLines). Nous voulons normaliser cette structure en deux tables séparées : une table incluant les factures et une autre contenant les lignes de facture. Par exemple, avec une seule structure imbriquée (une facture composée de trois lignes de facture), nous devrions avoir dans la cible deux tables contenant quatre enregistrements : un dans la table Invoice et trois dans la table InvoiceLine.
Dans cette section, nous utiliserons la base de données redis-13000.cluster.redis-process.demo.redislabs.com:13000 comme source de données. Cette base de données doit inclure les modules RedisGears et RedisJSON pour exécuter les actions suivantes.
Vous devez d’abord créer et installer le moteur RDI sur votre base de données Redis source afin qu’il soit prêt à traiter les données. Vous devez exécuter la commande configure si vous n’avez pas utilisé cette base de données Redis avec RDI Write Behind auparavant.
redis-di configure --rdi-host redis-13000.cluster.redis-process.demo.redislabs.com --rdi-port 13000 --rdi-password rdi-password
Exécutez ensuite la commande scaffold avec le type de datastore que vous souhaitez utiliser, par exemple :
redis-di scaffold --strategy write_behind --dir . --db-type mysql
Cela créera un modèle de config.yaml et un dossier nommé jobs dans le répertoire courant. Vous pouvez spécifier n’importe quel nom de dossier avec --dir ou utiliser l’option --preview config.yaml pour obtenir le modèle config.yaml dans le terminal.
Supposons que le point d’accès de votre base de données MySQL cible est rdi-wb-db.cluster-cpqlgenz3kvv.eu-west-3.rds.amazonaws.com. Vous devez ajouter la ou les connexions requises pour les cibles en aval dans la section connections du config.yaml, par exemple :
connections:
my-sql-target:
type: mysql
host: rdi-wb-db.cluster-cpqlgenz3kvv.eu-west-3.rds.amazonaws.com
port: 3306
database: sales
user: admin
password: rdi-password
Dans le serveur MySQL, vous devez créer la base de données sales et les deux tables, Invoice et InvoiceLine :
USE mysql;
CREATE DATABASE `sales`;
CREATE TABLE `sales`.`Invoice` (
`InvoiceId` bigint NOT NULL,
`CustomerId` bigint NOT NULL,
`InvoiceDate` varchar(100) NOT NULL,
`BillingAddress` varchar(100) NOT NULL,
`BillingPostalCode` varchar(100) NOT NULL,
`BillingCity` varchar(100) NOT NULL,
`BillingState` varchar(100) NOT NULL,
`BillingCountry` varchar(100) NOT NULL,
`Total` int NOT NULL,
PRIMARY KEY (InvoiceId)
);
CREATE TABLE `sales`.`InvoiceLine` (
`InvoiceLineId` bigint NOT NULL,
`TrackId` bigint NOT NULL,
`InvoiceId` bigint NOT NULL,
`Quantity` int NOT NULL,
`UnitPrice` int NOT NULL,
PRIMARY KEY (InvoiceLineId)
);
Créons maintenant le fichier suivant dans le répertoire jobs. Ce fichier déclaratif divise la structure JSON et crée les deux tables dans une base de données MySQL appelée sales. Vous pouvez définir différentes cibles pour ces deux tables en définissant d’autres connexions dans le fichier config.yaml.
source:
keyspace:
pattern : invoice:*
output:
- uses: relational.write
with:
connection: my-sql-target
schema: sales
table: Invoice
keys:
- InvoiceId
mapping:
- CustomerId
- InvoiceId
- InvoiceDate
- BillingAddress
- BillingPostalCode
- BillingCity
- BillingState
- BillingCountry
- Total
- uses: relational.write
with:
connection: my-sql-target
schema: sales
table: InvoiceLine
foreach: "IL: InvoiceLineItems.values(@)"
keys:
- IL: InvoiceLineItems.InvoiceLineId
mapping:
- UnitPrice: IL.UnitPrice
- Quantity: IL.Quantity
- TrackId: IL.TrackId
- InvoiceId
Pour démarrer le pipeline, exécutez la commande deploy :
redis-di deploy
Vous pouvez vérifier que le pipeline est en cours d’exécution, reçoit et écrit des données en utilisant la commande status :
redis-di status
Une fois la commande deploy exécutée, le moteur RDI enregistre le job et écoute les notifications de keyspace sur le motif invoice:*. Ainsi, si vous ajoutez ce document JSON, RDI exécutera le job et effectuera la transformation de données en conséquence.

Résumé
Cet article illustre comment effectuer des transformations de données complexes à l’aide de Redis Data Integration (RDI). C’est mon deuxième article sur RDI depuis que je l’ai présenté précédemment comme outil d’ingestion de données. Ici, nous avons poussé le parcours des données plus loin et utilisé RDI comme moteur de traitement et de transformation de données.
Dans les sections précédentes, j’ai présenté un ensemble de scénarios de transformation de données plus souvent requis dans toute plateforme de données d’entreprise et j’ai essayé d’évaluer les capacités de RDI en conséquence. L’outil est encore en développement intensif et en préversion privée, mais il offre de nombreuses capacités prometteuses pour implémenter une plateforme de données en temps réel complète.
Références
- Redis Data Integration (RDI), Guide du développeur