
Dans l’article précédent, nous avons exploré les univers captivants des bases de données vectorielles et de la recherche par similarité vectorielle. Vous avez découvert le potentiel transformateur qu’ils offrent pour le stockage et la récupération de données non structurées, débloquant de nouvelles dimensions de compréhension dans divers domaines.
Aujourd’hui, nous nous lançons dans une nouvelle expédition, une qui vous emmène au-delà des limites des méthodes de recherche singulières. Nous plongeons dans le domaine de la « Recherche Hybride », une approche multifacette qui synergise les atouts de la recherche par similarité vectorielle avec une riche tapisserie d’autres paradigmes de recherche. Dans cet article, nous explorerons comment la recherche hybride exploite la puissance de diverses techniques de recherche, telles que textuelles, numériques, conditionnelles, géographiques, et plus encore, pour fournir des solutions holistiques pour la récupération d’information.
RediSearch : un moteur de recherche polyvalent
RediSearch est un module Redis qui fournit des capacités d’interrogation, d’indexation secondaire et de recherche en texte intégral pour Redis. Écrit en C, Redis Search est extrêmement rapide par rapport à d’autres moteurs de recherche open-source. Il implémente plusieurs types de données et commandes qui changent fondamentalement ce que vous pouvez faire avec Redis. RediSearch prend en charge des capacités de recherche et de filtrage, telles que les requêtes géospatiales, le filtrage par plages numériques, la récupération de documents par champs spécifiques et le scoring de documents personnalisé. Les agrégations peuvent combiner les opérations map, filter et reduce/group-by dans des pipelines personnalisés qui s’exécutent instantanément sur des millions d’éléments.
RediSearch prend également en charge la complétion automatique avec correspondance de préfixe floue et l’insertion atomique en temps réel de nouveaux documents dans un index de recherche. Avec la dernière version de RediSearch, créer un index secondaire sur vos données existantes est plus facile que jamais. Vous pouvez simplement ajouter des capacités de recherche et de requête à votre base de données Redis existante, créer un index et commencer à l’interroger sans migrer vos données ni utiliser de nouvelles commandes pour ajouter des données à l’index.
De plus, en tant que moteur de recherche polyvalent, RediSearch offre les fondations techniques pour stocker, indexer et interroger les embeddings vectoriels. Il fournit des capacités avancées d’indexation et de recherche nécessaires pour effectuer des recherches à faible latence dans de grands espaces vectoriels, allant généralement de dizaines de milliers à des centaines de millions de vecteurs distribués sur plusieurs machines.

La Recherche par Similarité Vectorielle se concentre sur la détermination de la similarité ou de la dissimilarité entre deux vecteurs. Une fois que vous avez créé vos embeddings et les avez stockés dans Redis, vous devez créer une structure de données d’index pour permettre une recherche intelligente par similarité qui équilibre la vitesse et la qualité de recherche. Redis prend en charge deux types d’indexation vectorielle :
- FLAT : une approche par force brute utilisant la recherche K-Nearest Neighbor (KNN) à travers tous les vecteurs possibles. Cette indexation est simple et efficace pour les petits jeux de données ou les cas où l’interprétabilité est importante ;
- Hierarchical Navigable Small Worlds (HNSW) : une recherche approximative (ANN) qui donne des résultats plus rapides avec une précision moindre. C’est plus adapté pour les tâches complexes nécessitant la capture de modèles et de relations complexes, en particulier avec de grands jeux de données.
Le choix entre Flat et HNSW dépend uniquement de votre utilisation, de vos caractéristiques de données et de vos exigences. Les index ne doivent être créés qu’une seule fois et seront automatiquement ré-indexés à mesure que de nouveaux hashes sont stockés dans Redis. Les deux méthodes d’indexation ont les mêmes paramètres obligatoires : Type, Dimension et Métrique de Distance.
Les métriques de distance fournissent un moyen fiable et mesurable de calculer la similarité ou la dissimilarité de deux vecteurs. Vous pouvez utiliser de nombreuses métriques de distance pour le calcul du score de similarité, mais actuellement, seules les métriques Euclidienne (L2), Produit Intérieur (IP) et Similarité Cosinus sont disponibles dans Redis.
Recherche Hybride
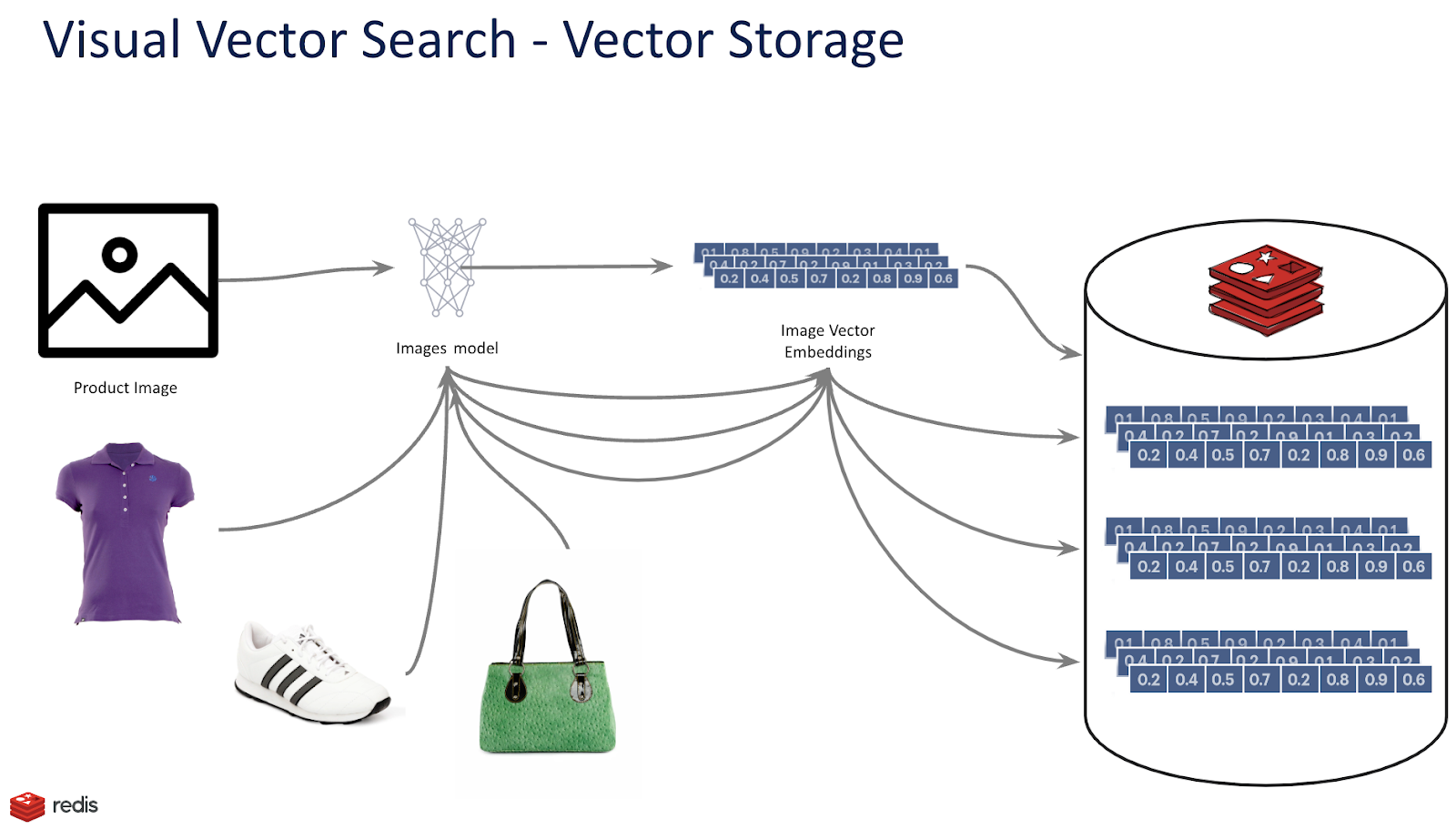
RediSearch expose les capacités de recherche habituelles, combinant les pré-filtres de texte intégral, géographiques et numériques avec la recherche vectorielle K Nearest Neighbors (KNN). Pour cela, vous pouvez utiliser des requêtes de similarité vectorielle dans la commande de requête FT.SEARCH et vous devez spécifier l’option DIALECT 2 ou supérieur pour utiliser une requête de similarité vectorielle. Par exemple, vous pouvez créer une requête qui retourne des produits similaires à un article donné par son image disponible dans les magasins autour de chez vous !
Considérons l’objet produit suivant. Il se compose de l’image du produit, du nom, de l’embedding vectoriel de l’image du produit, du genre et de l’emplacement du magasin où vous pouvez trouver ce produit :
{
"product_id": "8cf52572340c3592e5f0ede116a0206f",
"product_embedding": [3.0499367713928223,0.6722652912139893,1.209347128868103,0.4089492857456207,0.00762720312923193,0.16665008664131165,0.23197419941425323,0.7637760639190674,...],
"product_name": "Numero Uno Men White Casual Shoes",
"product_image": "drive/MyDrive/ColabDrive/products/men/8cf52572340c3592e5f0ede116a0206f.jpg",
"gender": "men",
"price": 18.99,
"location": "50.69098, 3.17655"
}
Pour chaque magasin, plusieurs documents existent selon la structure ci-dessus et représentant chaque produit disponible en magasin. Créons maintenant un index de recherche pour interroger les différents attributs du produit :
from redis.commands.search.field import (
TagField,
VectorField,
TextField,
NumericField,
GeoField
)
from redis.commands.search.indexDefinition import (
IndexDefinition,
IndexType
)
# Function to create a hybrid search index with Image Vector Search + Tag Filtering
def create_hybrid_index(
redis_conn,
vector_field_name: str,
number_of_vectors: int,
index_name:str,
prefix: str,
distance_metric: str='COSINE'
):
# Construct index
try:
redis_client.ft(index_name).info()
print("Existing index found. Dropping and recreating the index", flush=True)
redis_client.ft(index_name).dropindex(delete_documents=False)
except:
print("Creating new index", flush=True)
gender_field = TagField('$.gender', as_name='gender')
name_field = TextField('$.product_name', no_stem=True, as_name='name')
url_field = TextField('$.product_image', no_stem=True, as_name='image')
price_field = NumericField('$.price', as_name='price')
location_field = GeoField('$.location', as_name='location')
image_field = VectorField(f"{vector_field_name}", "FLAT",
{
"TYPE": "FLOAT32",
"DIM": 512,
"DISTANCE_METRIC": distance_metric,
"INITIAL_CAP": number_of_vectors
}, as_name='vector')
redis_conn.ft(index_name).create_index(
fields = [gender_field, name_field, url_field, price_field, location_field, image_field],
definition = IndexDefinition(prefix=[prefix], index_type=IndexType.JSON)
)
Vous pouvez commencer à tester cet index en effectuant quelques recherches en texte intégral de base. D’abord, trouvez tous les produits avec le mot-clé Addidas. Notez que nous faisons volontairement une faute de frappe dans le nom de marque Adidas pour tester la recherche floue. La requête de recherche exécutée est :
query = (
Query('@name:%addidas%').return_fields('id', 'name', 'image', 'price')
)
results = redis_client.ft("product_index").search(query)
Maintenant, nous allons chercher les mêmes produits avec un filtre sur le prix : uniquement les produits qui coûtent moins de ou égal à 50 euros. La requête de recherche exécutée est :
query = (
Query('@name:%Adidas% @price:[0 50]').return_fields('id', 'name', 'image', 'price')
)
results = redis_client.ft("product_index").search(query)
Maintenant, nous pouvons effectuer des recherches hybrides en utilisant la recherche par similarité vectorielle et la recherche standard. Pour cela, nous allons commencer par rechercher tous les produits similaires à une image donnée (une image de produit), et nous allons spécifier une condition de pré-filtrage pour limiter la recherche à une certaine catégorie de produits (par exemple, genre, chaussures…). Pour cela, nous créons une fonction d’aide appelée hybrid_similarity_search pour créer un embedding à partir de l’image de requête et le comparer à d’autres vecteurs ayant le même préfixe selon l’index créé précédemment, en plus du filtrage par l’étiquette de genre.
def hybrid_similarity_search(query_image: str, query_tag: str, k: int, return_fields: tuple, index_name: str = "product_index") -> list:
# create a redis query object
redis_query = (
Query(f"(@gender:{query_tag})=>[KNN {k} @vector $query_vector AS distance]")
.sort_by("distance")
.return_fields(*return_fields)
.paging(0, k)
.dialect(2)
)
# create embedding from query text
query_vector = np.array(generate_image_vector(query_image), dtype=np.float32).tobytes()
# execute the search
results = redis_client.ft(index_name).search(
redis_query, query_params={"query_vector": query_vector}
)
# 2. Create query arguments
query_image = "drive/MyDrive/ColabDrive/products/input/2eca615a43d0098f4bb5fc90004c3678.jpg"
query_tag = "women"
# 3. Perform the hybrid vector similarity search with the given parameters
results = hybrid_similarity_search(query_image, query_tag, k=3, return_fields=('distance', '$.product_id', '$.product_image', '$.gender'))
Le résultat attendu est un dataframe contenant uniquement des articles pour femmes similaires à l’image d’entrée donnée.

De même, la recherche de produits similaires à un produit donné et disponibles dans les magasins à proximité d’un emplacement donné est une requête simple. Pour cela, mettons à jour la fonction d’aide précédente pour effectuer un pré-filtrage par emplacements autour de Paris avec un rayon de 30 km.
def hybrid_similarity_search(query_image: str, location: str, radius: str, k: int, return_fields: tuple, index_name: str = "product_index") -> list:
# create a redis query object
redis_query = (
Query(f"(@location:[{location} {radius}])=>[KNN {k} @vector $query_vector AS distance]")
.sort_by("distance")
.return_fields(*return_fields)
.paging(0, k)
.dialect(2)
)
# create embedding from query text
query_vector = np.array(generate_image_vector(query_image), dtype=np.float32).tobytes()
# execute the search
results = redis_client.ft(index_name).search(
redis_query, query_params={"query_vector": query_vector}
)
# 2. Create query arguments
query_image = "drive/MyDrive/ColabDrive/products/input/2eca615a43d0098f4bb5fc90004c3678.jpg"
paris_coordinates = "48.866667 2.333333"
radius = "30 km"
# 3. Perform the hybrid vector similarity search with the given parameters
results = hybrid_similarity_search(query_image, paris_coordinates, radius, k=3, return_fields=('distance', '$.product_id', '$.product_image', '$.product_name', '$.location'))
L’exemple ci-dessus retourne le même résultat que la requête précédente. Nous spécifions cependant les coordonnées de Paris et le rayon dans lequel nous voulons effectuer la recherche entre le vecteur de l’image donnée et tous les vecteurs de produits déjà stockés dans Redis. Le résultat peut être affiché sur une carte pour une interface plus conviviale.
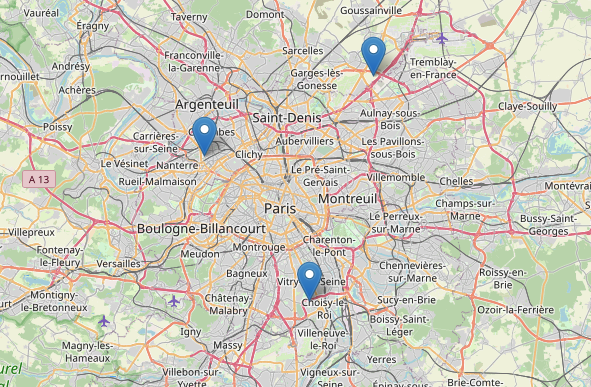
Vous pouvez imaginer les multiples utilisations que vous pouvez débloquer avec une recherche hybride. Par exemple, vous pouvez l’utiliser dans l’industrie du e-commerce, avec des moteurs de recommandation pour permettre des recommandations de produits personnalisées, la vente croisée et la vente incitative. Ces systèmes aident les utilisateurs à découvrir de nouvelles informations pertinentes tout en stimulant l’engagement et la fidélisation des utilisateurs en présentant du contenu ou des services qui correspondent à leurs intérêts, améliorant ainsi les expériences globales des utilisateurs.
Redis combine la puissance de la recherche de données structurées, semi-structurées et non structurées au sein d’un seul moteur de recherche performant. Cela se traduit par des courbes d’apprentissage faibles et une pile technologique plus consolidée au sein de votre organisation, en plus des bien connues performances de Redis inférieures à la milliseconde.

Les instructions ci-dessus sont un bref aperçu pour démontrer les éléments de base de la Recherche par Similarité Vectorielle avec Redis. Vous pouvez l’essayer avec le notebook référencé ici : ![]()
Résumé
Dans cette exploration de la recherche hybride, nous avons plongé dans l’univers captivant de Redis et de RediSearch, découvrant comment ils nous permettent de maîtriser le multivers de la recherche. Nous avons commencé par revisiter la recherche par similarité vectorielle, une technique puissante pour trouver des similitudes entre des vecteurs, et avons vu comment Redis, grâce au module RediSearch, peut être utilisé pour l’implémenter efficacement.
Nous avons ensuite exploré le domaine de la recherche hybride, où la fusion de la recherche par similarité vectorielle avec d’autres paradigmes de recherche ouvre un large éventail de possibilités. Qu’il s’agisse de combiner des pré-filtres de texte intégral, géographiques et numériques avec la recherche vectorielle ou de créer des requêtes dynamiques pour trouver des produits similaires basés sur des images, Redis et RediSearch fournissent les outils pour naviguer dans ce paysage multifacette.
Alors que nous concluons ce voyage, nous nous trouvons à l’intersection de l’innovation et de l’efficacité. Redis et RediSearch offrent une solution polyvalente qui consolide votre pile technologique, simplifie la courbe d’apprentissage et offre des performances inférieures à la milliseconde. Que vous soyez dans le domaine du e-commerce, de la santé, de la finance ou dans tout domaine où l’exploration des données est primordiale, maîtriser la recherche hybride avec Redis est votre clé pour débloquer des insights plus profonds et créer des expériences utilisateur exceptionnelles.
Références
- Searching document data with Redis, JSON, and vector-similarity, Brian Sam-Bodden.
- Documentation VSS, redis.io