
Les moteurs de recommandation ont acquis une importance considérable dans le paysage numérique actuel. À mesure que les secteurs d’activité deviennent de plus en plus concurrentiels, les entreprises s’appuient sur des systèmes de recommandation pour améliorer l’expérience utilisateur, stimuler l’engagement et accroître les revenus.
Dans le secteur du e-commerce, les moteurs de recommandation permettent de proposer des suggestions de produits personnalisées, des ventes croisées et des montées en gamme. En comprenant les préférences et l’historique d’achats de leurs clients, ces systèmes peuvent suggérer des articles correspondant à leurs centres d’intérêt, ce qui se traduit par une plus grande satisfaction client et des achats répétés.
Dans le secteur du divertissement et du streaming de contenu, les moteurs de recommandation jouent un rôle crucial en suggérant des films, des séries, de la musique ou des articles pertinents. En analysant le comportement et les préférences d’un utilisateur, des plateformes comme Netflix, Spotify et YouTube fournissent des recommandations personnalisées qui améliorent la satisfaction des utilisateurs et les incitent à explorer davantage de contenus.
Par ailleurs, les moteurs de recommandation sont devenus indispensables pour améliorer l’expérience utilisateur sur les réseaux sociaux, les sites d’actualités et même dans le secteur de la livraison de repas. Ces systèmes aident les utilisateurs à découvrir des informations nouvelles et pertinentes tout en stimulant leur engagement et leur fidélisation, en leur présentant des contenus ou des services alignés sur leurs intérêts.
Heureusement, la mise en œuvre d’un moteur de recommandation n’a pas à être complexe. Avec Redis, votre entreprise peut déployer un système de recommandation complet en un rien de temps.
Vue d’ensemble des systèmes de recommandation
Les moteurs de recommandation sont des modèles statistiques qui analysent les données des utilisateurs, notamment l’historique de navigation, le comportement d’achat, les préférences et les données démographiques, pour fournir des recommandations personnalisées. Ces recommandations peuvent prendre la forme de suggestions de produits, de recommandations de contenus ou de services pertinents.
L’importance des moteurs de recommandation réside dans leur capacité à répondre aux préférences individuelles des utilisateurs et à simplifier leur prise de décision. En proposant des suggestions sur mesure, les entreprises peuvent fidéliser leurs utilisateurs, les maintenir plus longtemps sur leurs plateformes et, in fine, augmenter les taux de conversion et les ventes.
Il existe plusieurs types de systèmes de recommandation couramment utilisés en pratique :
- Filtrage basé sur le contenu : Cette approche recommande des articles aux utilisateurs en fonction de leurs préférences et des caractéristiques des items. Elle analyse le contenu et les attributs des articles avec lesquels les utilisateurs ont interagi ou qu’ils ont évalués positivement, puis suggère des articles similaires. Par exemple, si un utilisateur apprécie les films d’action dans un système de recommandation cinématographique, le système lui recommandera d’autres films d’action.
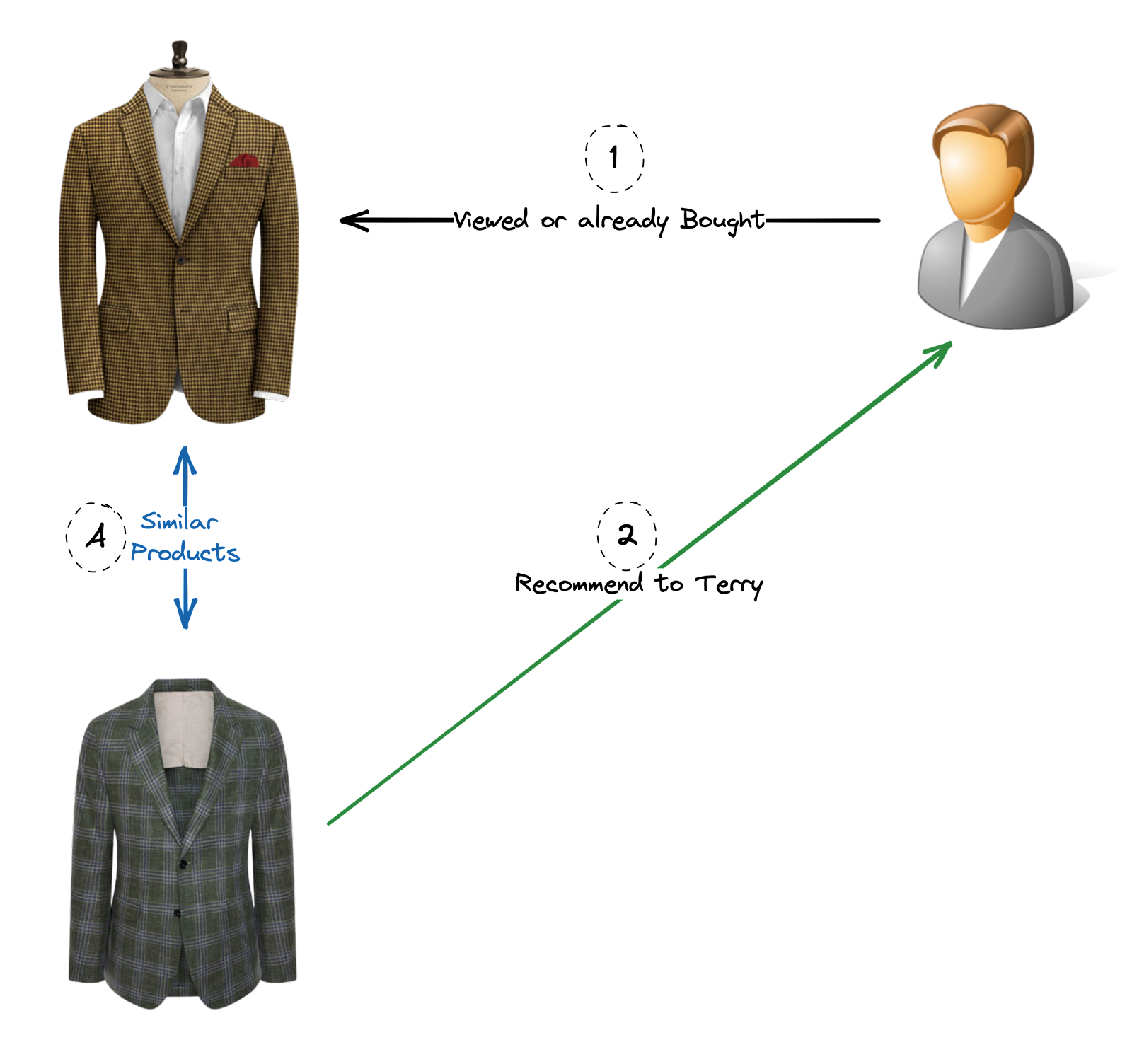
- Filtrage collaboratif : Cette méthode recommande des articles en se basant sur les similitudes et les tendances observées dans les comportements et préférences de plusieurs utilisateurs. Elle identifie les utilisateurs ayant des goûts similaires et recommande les articles que ces utilisateurs ont appréciés ou bien notés. Le filtrage collaboratif se divise en deux sous-types :
- Filtrage collaboratif basé sur les utilisateurs : il identifie les utilisateurs ayant des préférences similaires et recommande les articles appréciés par des utilisateurs au goût analogue (Scénarios A et B).
- Filtrage collaboratif basé sur les items : il identifie les articles similaires en fonction du comportement des utilisateurs et recommande des articles proches de ceux avec lesquels l’utilisateur a déjà interagi (Scénario C).

- Systèmes sensibles au contexte : Ces systèmes prennent en compte des informations contextuelles telles que l’heure, la localisation et la situation de l’utilisateur, pour fournir des recommandations plus pertinentes. Par exemple, un service de streaming musical pourrait suggérer des playlists énergiques pour l’entraînement le matin et de la musique relaxante le soir. De même, un site e-commerce proposera des articles spécifiques lors du Black Friday ou de Noël, différents de ce qu’il pourrait recommander le reste de l’année.

- Systèmes de recommandation hybrides : Ces systèmes combinent plusieurs techniques de recommandation pour fournir des suggestions plus précises et plus diversifiées. Ils exploitent les points forts de différentes approches, comme le filtrage basé sur le contenu et le filtrage collaboratif, pour surmonter leurs limitations respectives et proposer des recommandations plus efficaces.
Moteurs de recommandation avec Redis
Contrairement aux moteurs de recommandation hors ligne qui génèrent des recommandations personnalisées à partir de données historiques, un moteur de recommandation idéal doit privilégier l’efficacité des ressources, offrir des mises à jour en temps réel hautement performantes et proposer des suggestions précises et pertinentes. Il peut, par exemple, s’avérer irritant de suggérer à un client un article qu’il a déjà acheté, simplement parce que votre système de recommandation n’était pas au courant de ses dernières actions.
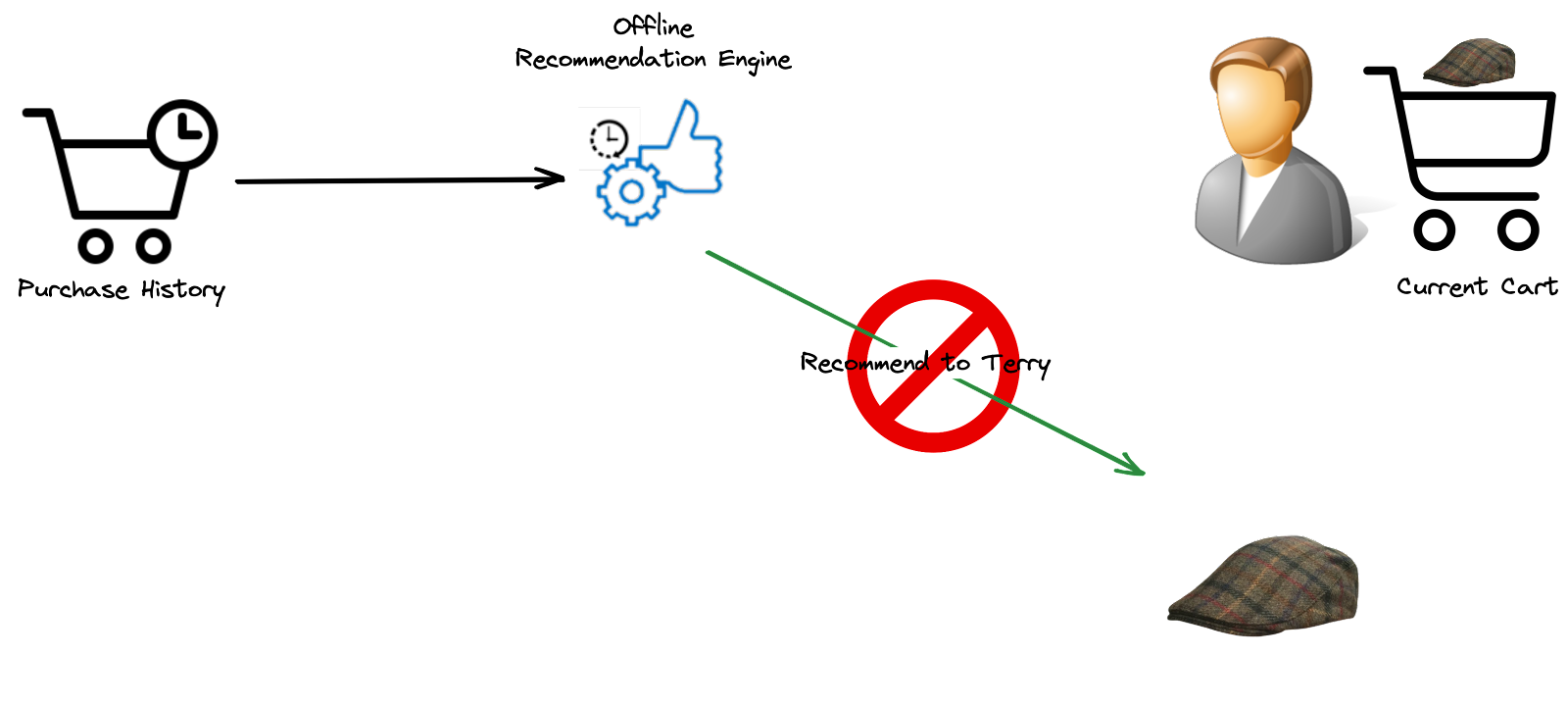
Les moteurs en temps réel réagissent aux actions des clients pendant qu’ils naviguent encore sur votre site et recalculent les recommandations en conséquence. Cela donne aux clients l’impression d’avoir un assistant commercial dédié, rendant leur expérience plus personnalisée.

Il vous faut clairement un backend à faible latence pour mettre en œuvre un tel système en temps réel. Vous devez d’abord représenter les attributs et préférences des utilisateurs d’une manière qui permette leur classification en groupes. Vous avez ensuite besoin d’une représentation performante des produits, qui autorise le calcul de similarité et les requêtes à très faible latence.
La mise en œuvre de tels systèmes avec Redis Enterprise est une tâche simple. Il s’agit d’abord de considérer les préférences des utilisateurs, les attributs des produits et tout autre paramètre de filtrage comme des vecteurs. Ensuite, grâce à la fonctionnalité de recherche par similarité proposée par Redis, vous pouvez effectuer des calculs de distance (scores d’affinité) entre ces vecteurs et formuler des recommandations basées sur ces scores.
Les embeddings vectoriels sont des représentations mathématiques de points de données dans lesquelles chaque dimension du vecteur correspond à une caractéristique ou un attribut spécifique de la donnée. Par exemple, l’image d’un produit peut être représentée comme un vecteur dont chaque élément encode une caractéristique du produit (couleur, forme, taille…). De même, une description textuelle de produit peut être transformée en vecteur dont chaque élément représente la fréquence ou la présence d’un mot ou terme spécifique.

Les représentations vectorielles des données permettent aux algorithmes de machine learning de traiter et d’analyser l’information de manière efficace. Ces algorithmes s’appuient souvent sur des opérations mathématiques appliquées aux vecteurs, comme les produits scalaires, l’addition de vecteurs et la normalisation, pour calculer des similarités, des distances et des transformations.
Mais surtout, les représentations vectorielles facilitent la comparaison et le regroupement de points de données dans un espace multidimensionnel. Des mesures de similarité, telles que la similarité cosinus ou la distance euclidienne, peuvent être calculées entre vecteurs pour déterminer la ressemblance ou la dissemblance entre points de données. Votre moteur de recommandation peut ainsi exploiter les vecteurs pour :
- regrouper et classer les clients en fonction de leurs préférences et attributs (âge, sexe, profession, localisation, revenus…), ce qui aide à trouver des similitudes entre clients (Filtrage collaboratif) ;
- suggérer des produits similaires en se basant sur leurs images et descriptions textuelles (Filtrage basé sur le contenu).

1 - Création des embeddings vectoriels
Pour comprendre comment les embeddings vectoriels sont créés, une brève introduction aux modèles modernes de Deep Learning s’impose.
Il est indispensable de convertir les données non structurées en représentations numériques pour les rendre compréhensibles par les modèles de machine learning. Par le passé, cette conversion était réalisée manuellement via l’ingénierie de features.
Le Deep Learning a introduit un changement de paradigme dans ce processus. Plutôt que de s’appuyer sur une ingénierie manuelle, les modèles de Deep Learning apprennent de manière autonome des interactions de features complexes dans des données élaborées. Au fur et à mesure que les données traversent un modèle de Deep Learning, celui-ci génère de nouvelles représentations des données d’entrée, chacune avec des formes et des tailles variables. Chaque couche du modèle se concentre sur des aspects différents de l’entrée. Cette capacité du Deep Learning à générer automatiquement des représentations de features à partir des entrées constitue le fondement de la création d’embeddings vectoriels.

Les embeddings vectoriels sont créés via un processus d’embedding qui transforme des données discrètes ou catégorielles en représentations vectorielles continues. Le processus de création des embeddings dépend du contexte spécifique et du type de données. Voici quelques techniques courantes :
- Embeddings textuels : utilisent des méthodes comme le TF-IDF (Term Frequency-Inverse Document Frequency) pour calculer la fréquence des mots dans un corpus textuel et leur attribuer des poids. Ils peuvent également faire appel à d’autres algorithmes populaires basés sur des réseaux de neurones, comme Word2Vec ou GloVe, pour apprendre des embeddings de mots en entraînant des réseaux de neurones sur de grands corpus textuels. Ces algorithmes capturent les relations sémantiques entre les mots en se basant sur leurs patterns de co-occurrence.
- Embeddings d’images : utilisent des réseaux de neurones convolutifs (CNN) tels que VGG, ResNet ou Inception, couramment employés pour l’extraction de features d’images. Les activations des couches intermédiaires ou la sortie des couches entièrement connectées peuvent servir d’embeddings d’images.
- Embeddings de données séquentielles : utilisent des réseaux de neurones récurrents (RNN) tels que les LSTM (Long Short-Term Memory) ou les GRU (Gated Recurrent Unit), qui peuvent apprendre des embeddings pour des données séquentielles en capturant des dépendances et des patterns temporels. Ils peuvent également utiliser le modèle Transformer lui-même ou ses variantes comme BERT ou GPT, qui peuvent générer des embeddings contextualisés pour des données séquentielles.
- Embeddings utilisateurs : l’activité d’un utilisateur sur une marketplace e-commerce ne se limite pas à la simple consultation d’articles. Les utilisateurs peuvent également effectuer des actions telles qu’une recherche, l’ajout d’un article au panier ou à une liste de souhaits, etc. Ces actions constituent des signaux précieux pour la génération de recommandations personnalisées. Vous pouvez utiliser un RNN ou des GRU pour encoder l’ordre des événements historiques. Pour plus d’informations sur l’entraînement du modèle, les expériences et la configuration du déploiement, consultez l’article de recherche d’eBay.
Ces exemples illustrent quelques-unes des façons de créer des embeddings. Notre moteur de recommandation utilise une variante de BERT appelée all-mpnet-base-v2 pour créer des embeddings de données séquentielles à partir de descriptions de produits. Pour générer des embeddings d’images de produits, nous utilisons le modèle Img2Vec (une implémentation de Resnet-18). Les deux modèles sont hébergés et exécutables en ligne, sans expertise ni installation requise.
import os
import redis
# data prep
import pandas as pd
import numpy as np
# for creating image vector embeddings
import urllib.request
from PIL import Image
from img2vec_pytorch import Img2Vec
# for creating semantic (text-based) vector embeddings
from sentence_transformers import SentenceTransformer
def generate_text_vectors(products):
text_vectors = {}
# Bert variant to create text embeddings
text_model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
# generate text vector
for index, row in products.iterrows():
text_vector = text_model.encode(row["description"])
text_vectors[index] = text_vector.astype(np.float32)
return text_vectors
def generate_image_vectors(products):
img_vectors={}
images=[]
converted=[]
# Resnet-18 to create image embeddings
image_model = Img2Vec()
# generate image vector
for index, row in products.iterrows():
tmp_file = str(index) + ".jpg"
urllib.request.urlretrieve(row["image_url"], tmp_file)
img = Image.open(tmp_file).convert('RGB')
img = img.resize((224, 224))
images.append(img)
converted.append(index)
vec_list = image_model.get_vec(images)
img_vectors = dict(zip(converted, vec_list))
return img_vectors
def create_product_catalog():
# initialize product
dataset = {
'id': [1253, 9976, 3626, 2746],
'description': ['Herringbone Brown Classic', 'Herringbone Wool Suit Navy Blue', 'Peaky Blinders Tweed Outfit', 'Cable Knitted Scarf and Bobble Hat'],
'image_url': [
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/donegal-herringbone-tweed-men_s-jacket.jpeg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/Mens-Herringbone-Tweed-Check-3-Piece-Wool-Suit-Navy-Blue.webp',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/Marc-Darcy-Enzo-Mens-Herringbone-Tweed-Check-3-Piece-Suit.jpeg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/Mocara_MaxwellFlat_900x.jpg'
]
}
# Create DataFrame
products = pd.DataFrame(dataset).set_index('id')
return products
def create_product_vectors(products):
product_vectors = []
img_vectors = generate_image_vectors(products)
text_vectors = generate_text_vectors(products)
for index, row in products.iterrows():
_id = index
text_vector = text_vectors[_id].tolist()
img_vector = img_vectors[_id].tolist()
vector_dict = {
"text_vector": text_vector,
"img_vector": img_vector,
"product_id": _id
}
product_vectors.append(vector_dict)
return product_vectors
def store_product_vectors(redis_conn, product_vectors):
for product in product_vectors:
product_id = product["product_id"]
key = "product_vector:" + str(product_id)
redis_conn.hset(
key,
mapping={
"product_id": product_id,
# add image and text vectors as blobs
"img_vector": np.array(product["img_vector"], dtype=np.float32).tobytes(),
"text_vector": np.array(product["text_vector"], dtype=np.float32).tobytes()
})
def create_redis_conn():
host = os.environ.get("REDIS_HOST", "localhost")
port = os.environ.get("REDIS_PORT", 6379)
db = os.environ.get("REDIS_DB", 0)
password = os.environ.get("REDIS_PASSWORD", "vss-password")
url =f"redis://:{password}@{host}:{port}/{db}"
redis_conn = redis.from_url(url)
return redis_conn
# Create a Redis connection
redis_conn = create_redis_conn()
# Create a few products
products = create_product_catalog()
# Create vector embeddings for products
product_vectors = create_product_vectors(products)
# Store vectors in Redis
store_product_vectors(redis_conn, product_vectors)
Pour créer des embeddings utilisateurs, vous pouvez tirer parti de l’approche des réseaux de neurones à deux tours (Two-Tower Neural Networks). Elle consiste en deux modèles de réseaux de neurones distincts, souvent appelés « tours », qui traitent en parallèle différents types de données d’entrée.
Les deux tours du réseau reçoivent généralement des types d’informations différents liés aux interactions utilisateur-item. Par exemple, une tour peut traiter des données spécifiques à l’utilisateur, telles que des informations démographiques ou des préférences passées, tandis que l’autre tour traite des données spécifiques à l’item, telles que des descriptions ou des attributs de produits. Chaque tour apprend de manière indépendante des représentations ou features à partir de ses données d’entrée respectives, via plusieurs couches de neurones artificiels interconnectés. La sortie de la couche finale de chaque tour est ensuite combinée ou fusionnée pour générer une représentation conjointe qui capture la relation entre les utilisateurs et les items. Dans la suite de cet article, j’omettrai cette partie.

Le choix de la technique d’embedding dépend du type de données spécifique, de la tâche et des ressources disponibles. Le Huggingface Model Hub contient de nombreux modèles capables de créer des embeddings pour différents types de données.
2 - Indexation des embeddings vectoriels
Une fois vos embeddings créés, vous devez les stocker dans une base de données vectorielle. Diverses technologies prennent en charge le stockage des embeddings vectoriels, notamment Pinecone, Milvus, Weaviate, Vespa, Chroma, Vald, Qdrant, etc. Redis peut également servir de base de données vectorielle. Il gère les vecteurs dans une structure d’index afin de permettre une recherche par similarité intelligente qui équilibre vitesse et qualité de recherche. Redis supporte deux types d’indexation vectorielle :
- FLAT : une approche par force brute qui parcourt tous les vecteurs possibles. Cette indexation est simple et efficace pour les petits jeux de données ou les cas où l’interprétabilité est importante ;
- Hierarchical Navigable Small Worlds (HNSW) : une recherche approximative qui produit des résultats plus rapides avec une précision moindre. Elle est plus adaptée aux tâches complexes nécessitant de capturer des patterns et des relations élaborés, notamment avec de grands jeux de données.
Le choix entre FLAT et HNSW dépend uniquement de votre cas d’usage, des caractéristiques de vos données et de vos exigences.
Les index n’ont besoin d’être créés qu’une seule fois et se réindexeront automatiquement au fur et à mesure que de nouveaux hashes sont stockés dans Redis. Les deux méthodes d’indexation partagent les mêmes paramètres obligatoires : le type, la dimension et la métrique de distance.
Redis Enterprise utilise une métrique de distance pour mesurer la similarité entre deux vecteurs. Choisissez parmi trois métriques populaires (Euclidienne (L2), Produit interne (IP) et Similarité cosinus), utilisées pour calculer à quel point deux vecteurs sont « proches » ou « éloignés ».

Voici un exemple de création d’index image et texte dans Redis à partir des vecteurs créés précédemment.
from redis import redis
from redis.commands.search.field import VectorField
from redis.commands.search.indexDefinition import (
IndexDefinition,
IndexType
)
# Function to create a HNSW search index with Redis/RediSearch
def create_hnsw_index(
redis_conn,
number_of_vectors: int,
prefix: str,
distance_metric: str='COSINE'
):
image_field = VectorField("img_vector",
"HNSW", {
"TYPE": "FLOAT32",
"DIM": 512,
"DISTANCE_METRIC": distance_metric,
"INITIAL_CAP": number_of_vectors
})
text_field = VectorField("text_vector",
"HNSW", {
"TYPE": "FLOAT32",
"DIM": 768,
"DISTANCE_METRIC": distance_metric,
"INITIAL_CAP": number_of_vectors
})
redis_conn.ft('idx').create_index(
fields = [image_field, text_field],
definition = IndexDefinition(prefix=[prefix], index_type=IndexType.HASH)
)
# Create an HNSW search index for the products created earlier.
create_hnsw_index(redis_conn, 4, 'product_vector:')
Une fois les vecteurs chargés dans Redis et les index créés, des requêtes peuvent être formulées et exécutées pour toutes sortes de tâches de recherche basées sur la similarité.
3 - Recherche par similarité vectorielle
La recherche par similarité vectorielle de Redis (VSS) est une nouvelle fonctionnalité construite au-dessus du module RediSearch. Elle permet aux développeurs de stocker et d’indexer des vecteurs et d’effectuer des requêtes dessus aussi facilement que sur n’importe quel autre champ d’un hash ou d’un JSON Redis.
En conséquence, Redis expose les fonctionnalités de recherche habituelles, combinant la recherche en texte intégral, les filtres par tag et numériques avec la recherche vectorielle K plus proches voisins (KNN) : avec Redis VSS, vous pouvez interroger des données vectorielles stockées sous forme de BLOBs dans des hashes Redis et choisir les métriques de distance vectorielle pertinentes pour calculer à quel point deux vecteurs sont « proches » ou « éloignés ».

De plus, il offre des capacités de recherche avancées permettant de trouver les « K » vecteurs les plus similaires, en effectuant des recherches à faible latence dans de grands espaces vectoriels allant de dizaines de milliers à des centaines de millions de vecteurs distribués sur plusieurs machines.
Vous pouvez utiliser des requêtes de similarité vectorielle dans la commande FT.SEARCH. Vous devez spécifier l’option DIALECT 2 ou supérieur pour utiliser une requête de similarité vectorielle. Il existe deux types de requêtes vectorielles : KNN et range :
- Recherche KNN : utile pour trouver les K plus proches voisins d’un vecteur spécifique. La syntaxe des requêtes KNN de similarité vectorielle est
*=>[<vector_similarity_query>]pour exécuter la requête sur l’ensemble d’un champ vectoriel, ou<primary_filter_query>=>[<vector_similarity_query>]pour exécuter la requête de similarité sur le résultat d’une requête de filtrage primaire. Par exemple, la requête suivante retourne les 10 images les plus proches dont le vecteur stocké dans le champ img_vec est le plus proche du vecteur représenté par le blob de 4 octets suivant.
FT.SEARCH idx "*=>[KNN 10 @img_vec $BLOB]" PARAMS 2 BLOB "\x12\xa9\xf5\x6c" DIALECT 2
- Requêtes de range : filtrent les résultats de requête en fonction de la distance entre la valeur d’un champ vectoriel et un vecteur de requête, exprimée selon la métrique de distance du champ vectoriel concerné. La syntaxe d’une requête de range est
@<vector_field>: [VECTOR_RANGE (<radius> | $<radius_attribute>) $<blob_attribute>]. Les requêtes de range peuvent apparaître plusieurs fois dans une requête, à l’instar des clausesNUMERICetGEO, et peuvent notamment faire partie de la<primary_filter_query>dans une recherche hybride KNN. Par exemple, vous pouvez formuler une requête qui retourne des produits similaires à un article donné, disponibles dans des magasins autour de chez vous !
Dans l’exemple ci-dessous, nous retournons le même résultat que la requête précédente, mais en spécifiant que la distance entre le vecteur image stocké dans le champ img_vec et le blob du vecteur de requête spécifié ne doit pas dépasser 0,2 (soit un score de similarité d’au moins 80% selon la DISTANCE_METRIC du champ img_vec).
FT.SEARCH idx "@img_vec:[VECTOR_RANGE 0.2 $BLOB]" PARAMS 3 BLOB "\x12\xa9\xf5\x6c" LIMIT 0 10 DIALECT 2
Voici un exemple de création d’une requête avec redis_py qui retourne les 3 produits les plus similaires (par image) à celui-ci, triés par score de pertinence (similarité cosinus définie dans les index créés précédemment).
import numpy as np
from redis.commands.search.query import Query
# for creating query vector embeddings
import urllib.request
from PIL import Image
from img2vec_pytorch import Img2Vec
# Function to create the query parameter (query_vector)
def create_query_vector():
query_image_url = "https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/test_image.jpg"
# Resnet-18 to create image embeddings
image_model = Img2Vec()
# generate image vector
tmp_file = "query_image.jpg"
urllib.request.urlretrieve(query_image_url, tmp_file)
img = Image.open(tmp_file).convert('RGB')
img = img.resize((224, 224))
vector = image_model.get_vec(img)
query_vector = np.array(vector, dtype=np.float32).tobytes()
return query_vector
# Function to create the search query
def create_query(
return_fields: list,
search_type: str="KNN",
number_of_results: int=3,
vector_field_name: str="img_vector"
):
query_str = f'*=>[{search_type} {number_of_results} @{vector_field_name} $query_vector]'
return Query(query_str)\
.sort_by('__img_vector_score')\
.paging(0, number_of_results)\
.return_fields(*return_fields)\
.dialect(2)
params_dict = {"query_vector" : create_query_vector()}
results = redis_conn.ft('idx').search(create_query(['product_id', '__img_vector_score']), query_params=params_dict)
print(results)
N’hésitez pas à tester cela par vous-même ! Les instructions ci-dessus constituent un aperçu succinct des briques de construction d’un moteur de recommandation en temps réel avec Redis. Je vous recommande deux projets qui exploitent la fonctionnalité VSS de Redis. Le premier est le Fashion Product Finder, implémenté avec redis-om-python.

{kind=link}
Le second est un projet qui utilise la recherche par similarité vectorielle de Redis pour retourner des similarités sur un jeu de données réel Amazon et propose :
- Recherche sémantique : à partir d’une phrase, retrouver les produits dont les mots-clés sont sémantiquement similaires ;
- Recherche visuelle : à partir d’une image de requête, trouver les K produits les plus « visuellement » similaires dans le catalogue.
Résumé
Redis offre des capacités diverses qui peuvent considérablement réduire la complexité applicative tout en délivrant des performances constamment élevées, même à grande échelle. En tant que base de données en mémoire, Redis offre un débit très élevé avec une latence sous la milliseconde, en utilisant le moins de ressources de calcul possible.
Avec la fonctionnalité de recherche par similarité vectorielle, Redis ouvre la voie à plusieurs applications révolutionnaires pour les entreprises, basées sur le calcul de similarité et de distance en temps réel. Les moteurs de recommandation en sont un exemple simple.
Si vous souhaitez fournir des recommandations interactives basées sur le contenu, vous pourriez vouloir tirer parti de Redis en tant que base de données vectorielle et moteur de recherche par similarité. Quelle que soit la complexité souhaitée pour votre moteur de recommandation (collaboratif, basé sur le contenu, contextuel ou même hybride), Redis peut effectuer tous les calculs nécessaires et vous aider à déterminer la meilleure façon de délivrer vos recommandations.
Références
- Vector-Similarity-Search from Basics to Production, Sam Partee.
- VSS documentation, redis.io
- Personalized Embedding-based e-Commerce Recommendations at eBay, eBay (arxiv.org).
- Announcing ScaNN: Efficient Vector Similarity Search, Google Search.