
Aujourd’hui, l’information est générée et consommée à une échelle sans précédent. À chaque clic, glissement d’écran et transaction, des quantités massives de données sont collectées, prêtes à être exploitées pour produire des insights, éclairer la prise de décision et stimuler l’innovation. De nos jours, plus de 80 % des données générées par les organisations sont non structurées, et ce type de données ne fera que croître dans les décennies à venir.
Les données non structurées sont de haute dimension et bruitées, ce qui les rend plus difficiles à analyser et à interpréter pour les bases de données traditionnelles avec leurs méthodes conventionnelles.
Plongée dans la GenAI
Bienvenue dans le monde de l’IA Générative (GenAI), une technologie révolutionnaire qui a transformé la façon dont nous stockons, interrogeons et analysons les données. Derrière la magie de la GenAI se cache une pile technologique profonde, des structures de données et des innovations mathématiques.
L’un des composants les plus fondamentaux, et pourtant souvent négligé, est l’utilisation des vector embeddings. Ces représentations de haute dimension permettent aux modèles GenAI de comprendre, d’organiser et de générer du contenu pertinent. Pour donner du sens à ces embeddings à grande échelle, nous avons besoin de systèmes spécialisés tels que les bases de données vectorielles. Ces bases de données ne sont pas simplement une évolution de leurs prédécesseurs ; elles représentent un bond extraordinaire dans la gestion des données.
Ceci est le premier d’une série d’articles que je rédige pour vous emmener dans un voyage au cœur des bases de données vectorielles. En tant qu’Architecte Senior de Solutions Partenaires chez Cockroach Labs, j’ingénie régulièrement des déploiements de bases de données distribuées au sein d’écosystèmes de données variés. J’aime partager ce que j’ai appris en chemin, comme dans ma série d’articles Mainframe to Distributed SQL.
Tout au long de cette série, nous explorerons le domaine de la GenAI, ses principes fondamentaux, ses applications, et comment l’infrastructure résiliente offerte par CockroachDB représente un ajout passionnant à ce domaine.
Cet article explore le parcours allant de l’IA générative aux vector embeddings, à la recherche vectorielle et à l’architecture sous-jacente qui alimente tout cela. Nous décomposerons des concepts complexes comme la recherche vectorielle, les modèles d’embedding et la cohérence des données, en montrant comment ils résolvent des problèmes concrets en matière de recherche, de classification et de recommandations.
Que vous soyez un passionné de données, un chef d’entreprise cherchant un avantage concurrentiel, ou un développeur curieux à propos de la prochaine frontière du stockage et de la récupération de données, cet article est votre porte d’entrée pour comprendre la puissance et le potentiel de CockroachDB en tant que base de données vectorielle.
Qu’est-ce que l’IA Générative ?
L’IA Générative représente une classe d’algorithmes d’intelligence artificielle capables de créer du contenu original (textes, images, musique, code ou même vidéos). Contrairement aux systèmes d’IA traditionnels qui effectuent des prédictions basées sur des sorties fixes et/ou peuvent seulement analyser ou classer des données existantes, les modèles génératifs peuvent produire de nouvelles sorties contextuellement pertinentes à partir de requêtes et d’entrées.
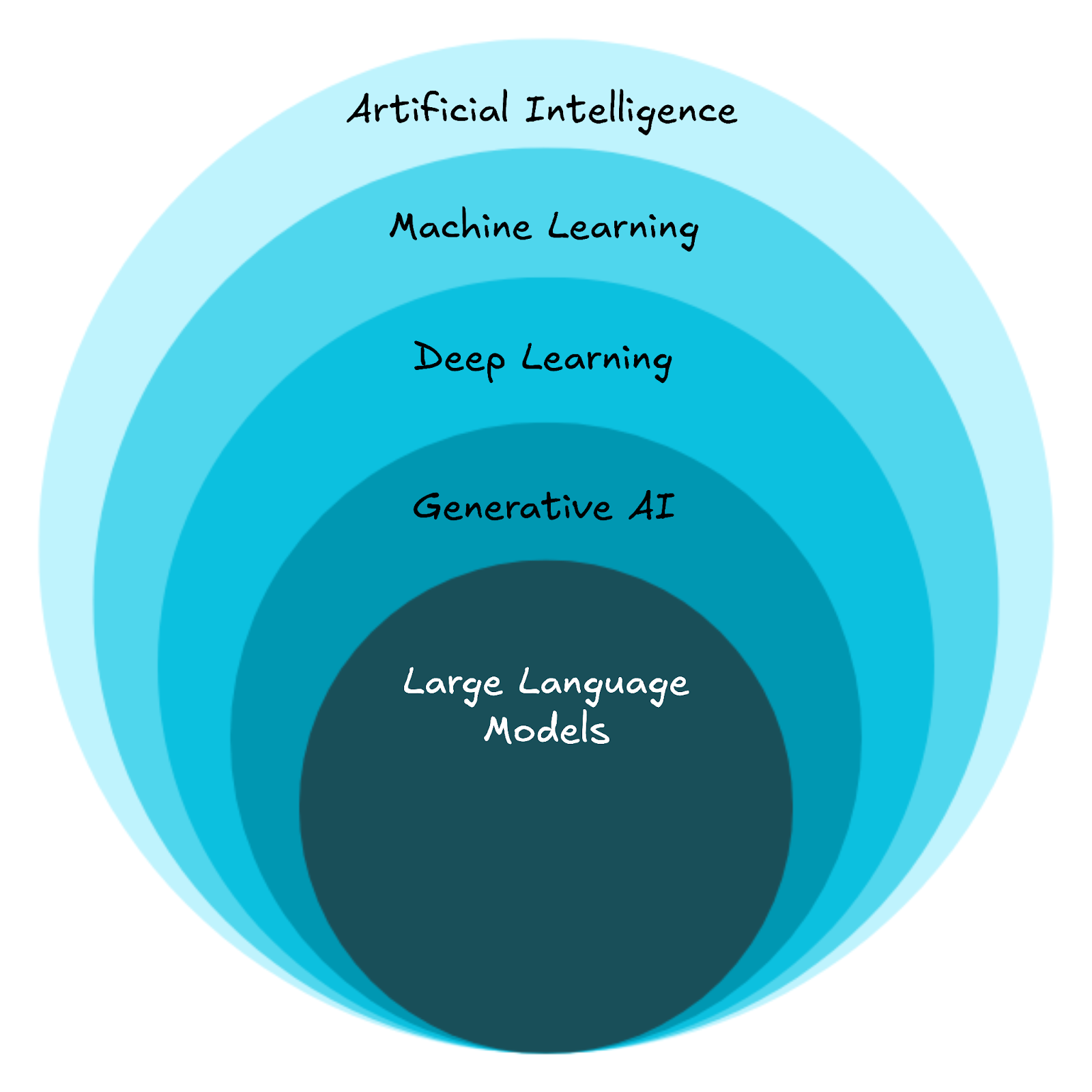
Taxonomie de l’IA
Ces systèmes apprennent les distributions de probabilité sous-jacentes des données sur lesquelles ils sont entraînés, puis génèrent de nouveaux exemples ressemblant aux données originales sans les copier directement. La partie « générative » provient de l’échantillonnage de ces distributions apprises pour produire de nouvelles sorties. Cette capacité à « créer » plutôt qu’à « reconnaître » représente une avancée significative dans le domaine de l’IA.
Ce processus n’est pas aléatoire : il est guidé par des représentations mathématiques des données appelées Vector Embeddings, et par un ensemble de techniques de récupération appelées Vector Similarity (VecSim).
Vector Embeddings
Les modèles d’IA générative ne « comprennent » pas le langage comme le font les humains. Pour comprendre le texte humain (aussi appelé langage naturel), les Grands Modèles de Langage (LLMs) sont des modèles de Traitement du Langage Naturel (NLP) conçus pour comprendre et générer du langage naturel de manière avancée. Ces modèles reposent généralement sur des réseaux de neurones. Ils peuvent traiter de grandes quantités de données textuelles pour effectuer diverses tâches, telles que la traduction automatique, la génération de texte, l’analyse de sentiment, la compréhension de texte, la réponse aux questions, et bien plus encore.
Cependant, les LLMs ont besoin d’un moyen de représenter, naviguer et chercher dans ces textes. C’est là qu’intervient le concept de Vecteur. Les vecteurs sont des représentations mathématiques de points de données où chaque dimension du vecteur (embeddings) correspond à une caractéristique ou un attribut spécifique de la donnée, afin de déterminer les relations et de générer des continuations plausibles des requêtes.
Pensez aux vector embeddings comme à des coordonnées GPS pour le sens. Tout comme le GPS aide à localiser un endroit physique, les embeddings aident à localiser le sens d’un contenu dans un espace multidimensionnel, permettant la comparaison de similarité, le clustering et la récupération.
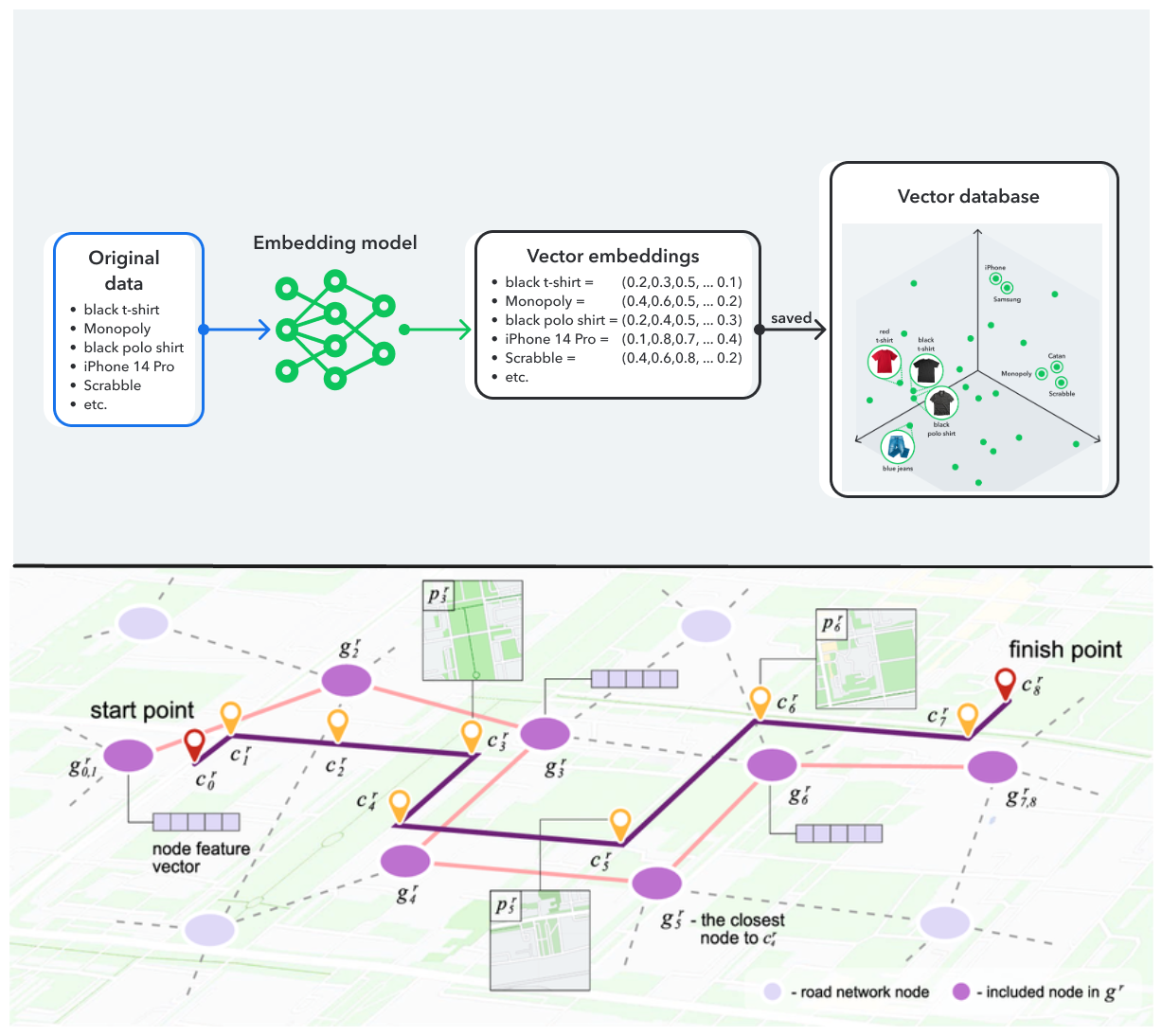
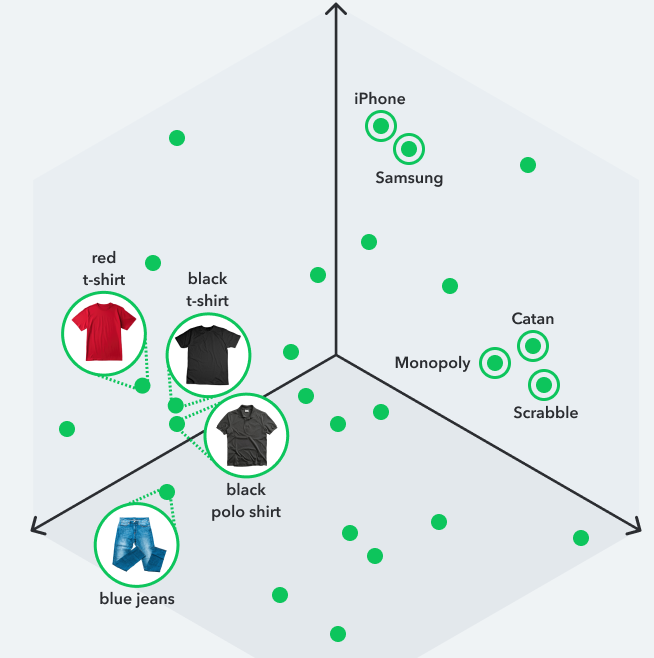
Les vector embeddings comme coordonnées GPS pour le sens
En apprentissage automatique et en traitement du langage naturel, le texte, les images ou d’autres données non structurées peuvent être représentés sous forme de vector embeddings, chaque embedding capturant un attribut de ces données. Par exemple, l’image d’un produit peut être représentée comme un vecteur, où chaque embedding représente une caractéristique spécifique de ce produit (marque, couleur, forme, taille…, etc.).
Les vecteurs représentent efficacement des données brutes non structurées qui peuvent être de haute dimension et éparses (par exemple, les langues naturelles, les images, l’audio…). Les vector embeddings résolvent un problème fondamental en IA : comment représenter des données non numériques (comme du texte ou des images) sous une forme que les algorithmes peuvent traiter mathématiquement. Cette transformation permet de :
- Capturer la sémantique - Le sens et les nuances des données sont préservés
- Effectuer des calculs - Nous pouvons mesurer des similarités, effectuer des additions ou soustractions conceptuelles
- Réduire la dimensionnalité - Des concepts complexes sont représentés de manière compacte et efficace
Grâce aux avancées du deep learning, des fournisseurs de modèles tels qu’OpenAI, Anthropic, HuggingFace, Cohere, et d’autres data scientists à travers le monde ont développé des modèles, appelés transformers, capables de transformer presque toute « entité » de données en sa représentation vectorielle. Ensuite, à l’aide d’approches mathématiques, ces représentations sont comparées dans un espace de recherche vectorielle pour mesurer à quel point deux éléments de données sont proches.

Transformation des données non structurées en Vector Embeddings
Recherche par similarité vectorielle
La recherche vectorielle, également connue sous le nom de « recherche par similarité », trouve les éléments d’un ensemble de données les plus proches d’une requête en se basant sur leurs embeddings.
Les métriques de similarité vectorielle permettent de mesurer la similarité ou la dissimilarité entre des points de données. Contrairement à la recherche par mots-clés, qui repose sur des correspondances exactes, la recherche vectorielle capture les relations sémantiques entre les points de données. Les mots ou phrases ayant des significations similaires (sémantiques) sont représentés comme des vecteurs proches les uns des autres dans l’espace d’embedding. Cela permet aux modèles de comprendre et de raisonner sur le sens des mots et du texte, et résout les problèmes suivants :
- Ambiguïté dans les requêtes : les utilisateurs n’ont pas besoin de termes précis ; la recherche vectorielle comprend l’intention.
- Données multimodales : elle traite du texte, des images ou de l’audio en comparant des embeddings entre différents formats.
- Scalabilité : elle traite efficacement de grands ensembles de données, comme des catalogues e-commerce ou des bibliothèques multimédias.
Distance (similarité) entre vecteurs dans un espace de recherche vectorielle
ChatGPT : comment ça fonctionne
En fait, lorsque vous soumettez une requête à un LLM (considérons une requête ChatGPT), elle est d’abord décomposée en tokens (unités plus petites que les mots, souvent des sous-mots). Chaque token est ensuite converti en un vecteur d’embedding initial. Cette couche initiale d’embeddings capture des informations lexicales de base.
Les architectures Transformer qui sous-tendent ces modèles utilisent des mécanismes d’attention pour enrichir ces embeddings initiaux avec des informations contextuelles. À chaque couche du réseau de neurones, les embeddings sont affinés pour incorporer davantage de contexte, reflétant une compréhension sémantique plus profonde et créant ce que nous appelons des « embeddings contextuels ». La couche finale produit de nouveaux embeddings, qui sont décodés en mots ou en actions.
Lors de la génération de texte, le LLM utilise les embeddings contextuels des tokens précédents pour prédire le token suivant le plus probable. Ce processus se déroule en :
- Transformant l’embedding contextuel en une distribution de probabilité sur le vocabulaire
- Échantillonnant cette distribution pour sélectionner le token suivant
- Calculant un nouvel embedding pour ce token
- Répétant le processus pour générer une séquence cohérente
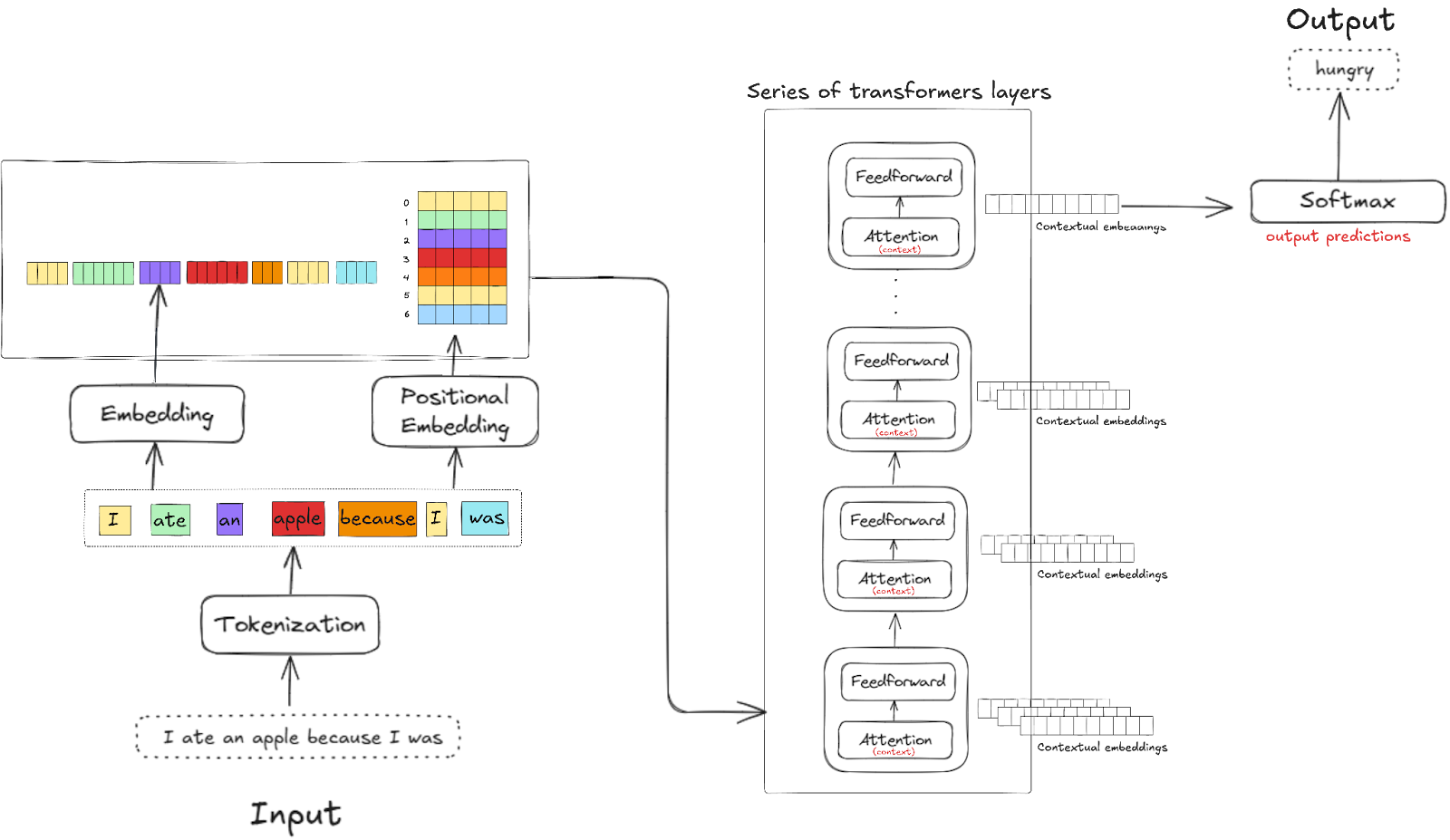
Comment fonctionnent les LLMs ?
Cette utilisation intelligente des embeddings permet aux LLMs de produire du texte qui maintient la cohérence, respecte les règles grammaticales et reste pertinent par rapport au contexte. Elle permet des cas d’usage puissants comme la recherche sémantique et la classification, où il est essentiel de trouver non seulement des correspondances exactes, mais aussi du contenu conceptuellement similaire. En s’appuyant sur la similarité vectorielle, les systèmes peuvent comprendre et récupérer des informations pertinentes même lorsque les formulations ou structures exactes diffèrent.
La recherche par similarité vectorielle alimente également des applications comme les moteurs de recommandation, permettant des recommandations personnalisées basées sur une similarité profonde avec les intérêts passés d’un utilisateur. Cela offre des expériences personnalisées et contextuellement adaptées, au-delà de simples filtres ou règles (par exemple, Netflix suggérant des émissions).
Elle peut également aider à catégoriser du contenu, détecter des spams, analyser des sentiments, récupérer des images (trouver des photos visuellement similaires), et cartographier les données dans un espace où les éléments similaires se regroupent naturellement, même sans étiquettes. VSS s’appuie sur des métriques de distance comme la similarité cosinus ou la distance euclidienne pour comparer les embeddings et déterminer leur degré de similarité.
Les systèmes GenAI utilisent la recherche par similarité vectorielle (VSS) comme colonne vertébrale mathématique pour récupérer du contenu basé sur la similarité sémantique plutôt que sur la correspondance exacte des données : lorsqu’un utilisateur saisit une requête, elle est convertie en un embedding. Le système trouve alors les vecteurs les plus similaires, et donc les résultats les plus pertinents, depuis un Feature Store ou, couramment, une base de données vectorielle.
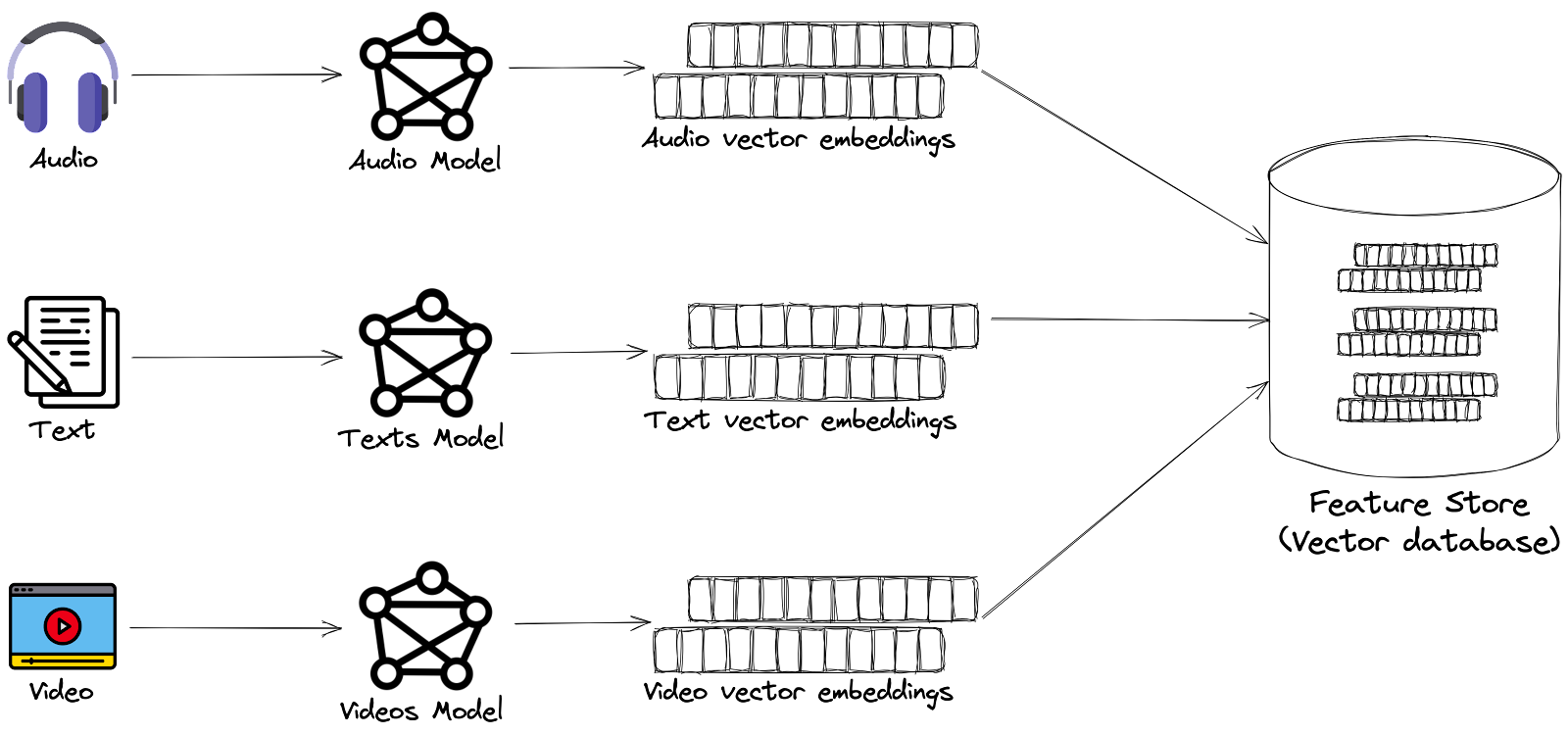
Bases de données vectorielles
Stockage et récupération des Embeddings
Pourquoi les bases de données vectorielles sont-elles importantes ?
Les bases de données vectorielles sont conçues pour stocker des données non structurées sous forme de vecteurs et pour gérer un grand volume de vector embeddings. Elles utilisent des techniques d’indexation spécialisées, comme la recherche approchée du plus proche voisin (ANN), pour trouver rapidement les vecteurs stockés similaires à un vecteur de requête. Par exemple, dans un système de recommandation, une base de données vectorielle peut récupérer en quelques millisecondes les produits dont les embeddings sont les plus proches du profil d’un utilisateur, même parmi des millions d’articles.
Les bases de données vectorielles doivent également prendre en charge la recherche hybride, combinant la similarité vectorielle avec des filtres traditionnels, pour plus de flexibilité. Imaginez que vous cherchez un produit spécifique par son image via une recherche par similarité vectorielle, mais que vous souhaitez enrichir votre recherche en ajoutant d’autres paramètres comme votre localisation actuelle ou une fourchette de prix.
Sans bases de données vectorielles, la gestion des embeddings serait lente et gourmande en ressources, limitant la scalabilité des systèmes GenAI. Leur capacité à stocker, indexer et récupérer efficacement les embeddings les rend indispensables pour les workflows d’IA modernes.
Défis des bases de données OLTP dans le traitement des vector embeddings
La recherche vectorielle, autrefois une capacité de niche confinée aux bases de données vectorielles spécialisées, devient rapidement une fonctionnalité de base dans les bases de données traditionnelles. À mesure que l’utilisation des embeddings se développe dans des applications comme la recherche sémantique, les moteurs de recommandation et les insights pilotés par l’IA, de plus en plus de développeurs et d’organisations attendent de leurs bases de données traditionnelles qu’elles prennent directement en charge des opérations telles que la recherche du plus proche voisin, la recherche hybride et la similarité cosinus.
Cependant, stocker et récupérer efficacement les embeddings est essentiel pour les bases de données traditionnelles. Cela nécessite souvent des contournements, comme la sérialisation des vecteurs en blobs, ce qui complique la récupération. Les applications d’IA de niveau entreprise gèrent des vecteurs de haute dimension, contenant souvent des centaines ou des milliers de dimensions, ce qui les rend difficiles à gérer à grande échelle. Ce volume pose des défis considérables tels que :
- Le stockage efficace de grandes quantités de vecteurs de haute dimension
- La récupération rapide des plus proches voisins
- La mise à jour continue des collections de vecteurs
De plus, les bases de données de Traitement Transactionnel En Ligne (OLTP), comme Oracle ou SQL Server, présentent des limitations significatives en termes de scalabilité pour les milliards de vecteurs nécessaires dans les applications d’IA modernes, ce qui en fait le pire choix pour les charges de travail IA. En effet, à mesure que les ensembles de données grandissent, la scalabilité dynamique devient essentielle pour maintenir les performances sans réarchitecturer le système GenAI.
Un autre problème clé est la gestion des métadonnées, où les systèmes doivent associer les vecteurs à des métadonnées riches pour permettre la recherche hybride et le filtrage avancé. De plus, les index vectoriels peuvent être gourmands en mémoire, entraînant une consommation élevée de ressources. Des mises à jour fréquentes, comme l’ajout de nouveaux vecteurs, peuvent également déclencher des reconstructions ou des maintenances coûteuses de l’index, impactant la latence et la disponibilité.
Le rôle critique de la cohérence des données dans la GenAI
La cohérence des données est le fondement d’une IA fiable, particulièrement pour la GenAI. Des données incohérentes (des embeddings non correspondants, des vecteurs obsolètes ou des entrées corrompues) peuvent conduire à de mauvaises performances du modèle, générant des sorties non pertinentes ou incorrectes.
Pour les LLMs, la cohérence garantit l’alignement entre les données d’entraînement et d’inférence. Si les embeddings utilisés pendant l’entraînement diffèrent de ceux lors de l’inférence (par exemple, en raison d’erreurs de prétraitement), le modèle peut mal interpréter les entrées, réduisant sa précision. Dans les systèmes de recommandation, des embeddings incohérents des utilisateurs ou des articles peuvent entraîner des suggestions non pertinentes, érodant la confiance.
Les applications GenAI impliquent souvent des données en temps réel, comme les interactions des utilisateurs ou le contenu en direct. Les bases de données vectorielles doivent maintenir la cohérence lors des mises à jour pour garantir que les embeddings reflètent les informations les plus récentes. Par exemple, dans un système de recommandation d’actualités, le fait de ne pas mettre à jour les embeddings des articles rapidement pourrait conduire à des suggestions obsolètes.
La cohérence est également importante pour la GenAI multimodale, où les embeddings de texte, d’images et d’audio doivent s’aligner. Des pipelines de données incohérents peuvent provoquer des incompatibilités, comme associer une image à la mauvaise légende. Une gouvernance robuste des données, des embeddings versionnés et des mises à jour atomiques dans les bases de données vectorielles aident à atténuer ces risques, garantissant que la GenAI livre des résultats fiables et de haute qualité.
CockroachDB comme base de données vectorielle
Intégrer CockroachDB dans votre pile technologique est un choix stratégique pour moderniser les systèmes legacy et se préparer aux exigences des applications pilotées par l’IA. Avec son type de données Vector natif, sa forte cohérence et un SLA de 99,999 % dans son offre cloud, CockroachDB offre les performances et la disponibilité requises pour les charges de travail nouvelle génération d’aujourd’hui.
Pour répondre à cette demande, l’implémentation de la recherche vectorielle de CockroachDB utilise la même interface que celle de pgvector pour PostgreSQL et vise à être compatible avec son API. Cette évolution élimine le besoin de bases de données vectorielles séparées dans de nombreux cas d’utilisation, permettant aux équipes d’exploiter des outils familiers tout en ajoutant des capacités natives à l’IA, brouillant ainsi les frontières entre les systèmes OLTP classiques et l’infrastructure IA moderne.
De plus, la scalabilité horizontale illimitée de CockroachDB vous permet de stocker et d’interroger des centaines de millions, voire des milliards de vector embeddings sans sacrifier les performances ou la fiabilité, essentielles pour les applications GenAI en temps réel. Ces requêtes rapides sont rendues possibles grâce à notre implémentation de Cockroach-SPANN, un algorithme d’indexation vectorielle distribuée développé en interne qui a été rendu disponible dans la v25.2. À mesure que votre empreinte de données s’étend, CockroachDB évolue automatiquement, éliminant le besoin de partitionnement manuel ou de reconfiguration complexe tout en garantissant des performances fluides et une simplicité opérationnelle.
Au-delà de la résilience et des capacités de domiciliation des données de CockroachDB, son architecture distribuée permet des opérations SQL natives puissantes sur les données vectorielles, apportant une profondeur analytique à vos applications d’IA générative.
Par exemple, si vous stockez des articles avec les emplacements de magasins associés et des images de produits (encodées sous forme de vecteurs) dans une seule table, vous pouvez créer un index secondaire sur la colonne d’emplacement du magasin pour pré-filtrer les données avant d’effectuer une recherche vectorielle. Cela signifie qu’au lieu de scanner l’ensemble du jeu de données, le système réduit d’abord la recherche aux emplacements pertinents, comme « Casablanca », puis applique la recherche par similarité vectorielle uniquement dans ce sous-ensemble. Cette approche de recherche hybride améliore considérablement les performances des requêtes et l’efficacité des ressources, facilitant la construction d’applications IA intelligentes et hautes performances à grande échelle en utilisant la syntaxe SQL familière.
En tant que base de données distribuée hautement résiliente, CockroachDB offre les fondations techniques pour stocker, indexer et interroger les vector embeddings. Elle permet aux développeurs de stocker des vecteurs aussi facilement que des données relationnelles structurées. Ensuite, les capacités de recherche vectorielle offrent des fonctionnalités d’indexation et de recherche avancées nécessaires pour effectuer des recherches à faible latence à grande échelle, allant typiquement de dizaines de milliers à des centaines de millions de vecteurs distribués à travers un cluster de machines.
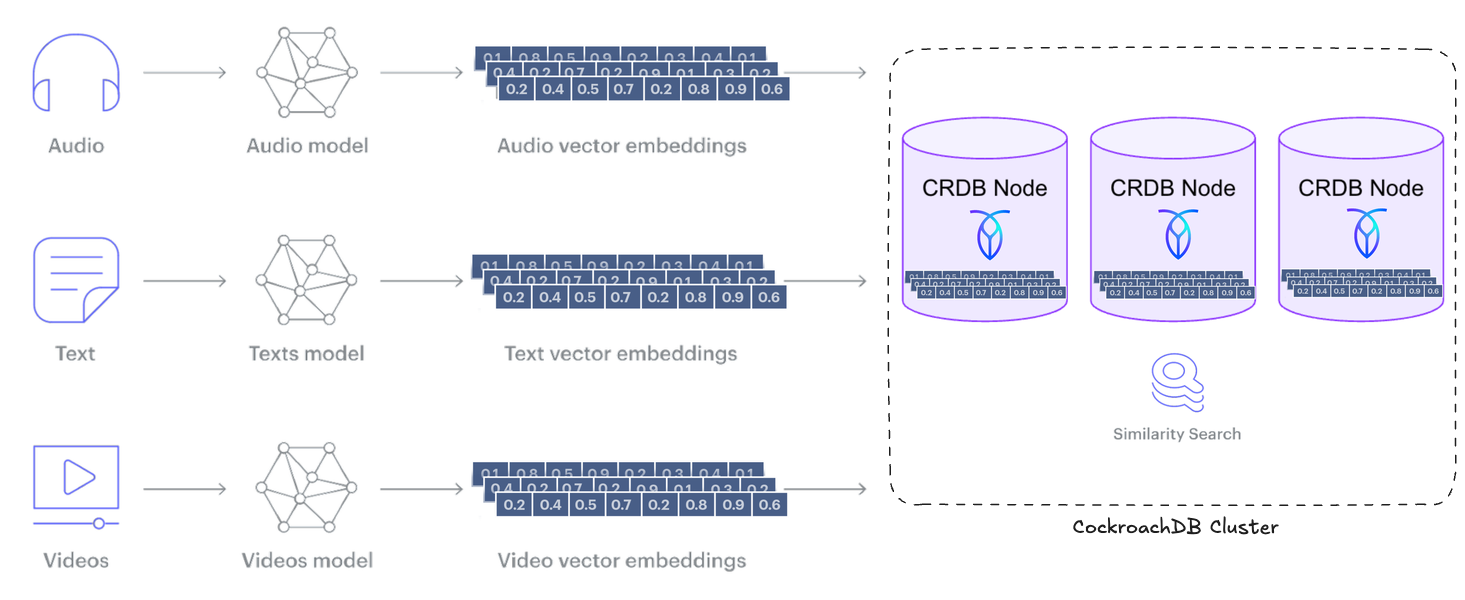
CockroachDB comme base de données vectorielle
Comment fonctionne la recherche par similarité sémantique ?
Prenons l’exemple suivant. Il illustre comment la recherche par similarité sémantique fonctionne dans le contexte des Grands Modèles de Langage (LLMs). Voici trois phrases différentes que nous souhaitons représenter dans un espace de recherche vectorielle, chacune étant transformée en un vector embedding en utilisant la bibliothèque sentence_transformers (de HuggingFace) :
That is a happy girlThat is a very happy personI love dogs
Des bibliothèques comme sentence_transformers de HuggingFace fournissent des modèles faciles à utiliser pour des tâches comme la recherche par similarité sémantique, la recherche visuelle et bien d’autres. Pour créer des embeddings avec ces modèles, seules quelques lignes de Python sont nécessaires :
from sentence_transformers import SentenceTransformer
# 1. Load a pretrained Sentence Transformer model.
# This model encodes text into a vector of 384 dimensions.
model = SentenceTransformer("all-MiniLM-L6-v2")
# The sentences to encode
sentences = [
"That is a happy girl",
"That is a very happy person",
"I love dogs"
]
# 2. Calculate embeddings by calling model.encode()
vectors = model.encode(sentences).astype(np.float32)
Nous devons d’abord créer le schéma de la table avant d’y insérer des données :
CREATE TABLE sentences IF NOT EXISTS (
text String,
text_vector VECTOR(384)
);
Ensuite, stockons ces phrases et leurs embeddings respectifs dans CockroachDB :
import psycopg2
# Connect to CRDB
with psycopg2.connect(crdb_cluster_endpoint) as conn:
# Open a cursor to perform database operations
with conn.cursor() as cursor:
data = [(sentence, vector) for sentence, vector in zip(sentences, vectors)]
for d in data:
cursor.execute("INSERT INTO sentences (text, text_vector) VALUES (%s, %s)", d)
# Make the changes to the database persistent
conn.commit()
Le graphique ci-dessous met en évidence la position de ces exemples de phrases dans un espace de recherche vectorielle à 2 dimensions les unes par rapport aux autres. Cela est utile pour évaluer visuellement à quel point nos embeddings représentent efficacement le sens sémantique du texte.
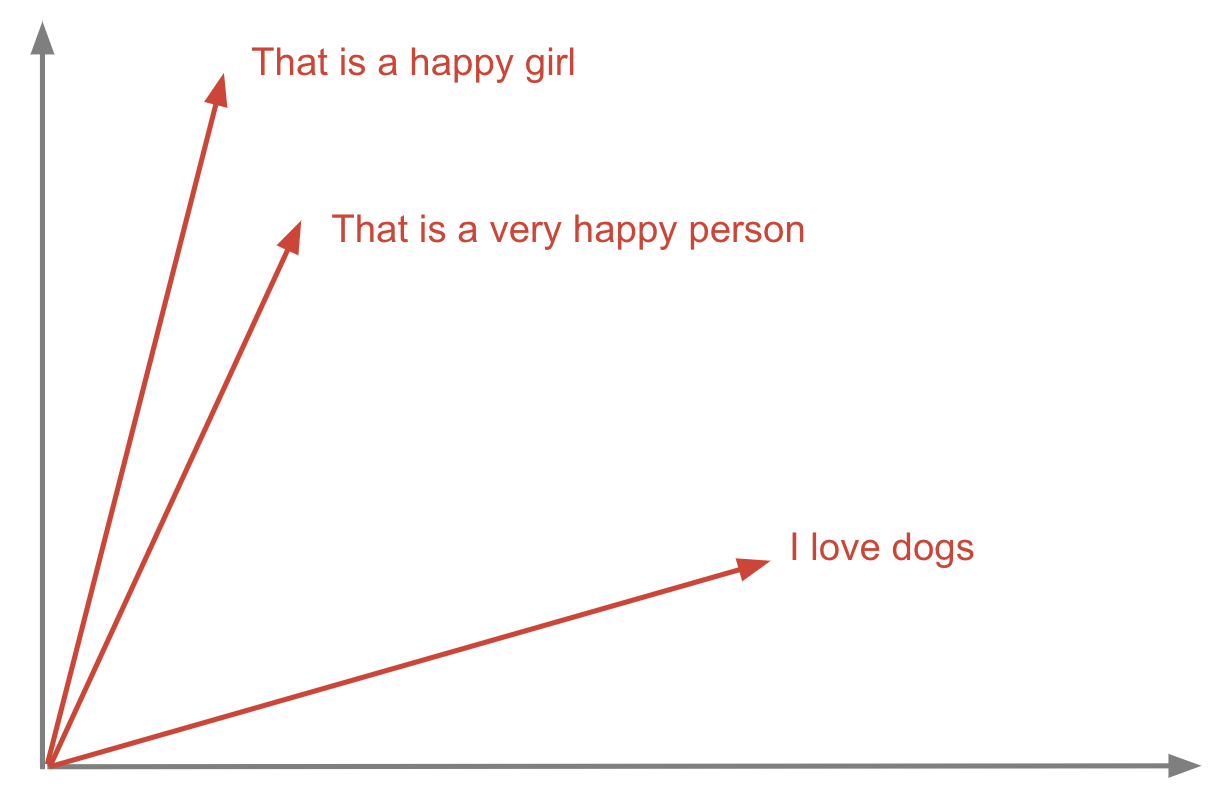
Phrases représentées sous forme de vecteurs
Supposons que nous voulions comparer les trois phrases ci-dessus avec une nouvelle : That is a happy boy. Nous devons utiliser le même modèle que pour les phrases précédentes, puis créer le vector embedding pour la phrase de requête.
# create the vector embedding for the query sentence
query_sentence = "That is a happy boy"
query_vector = model.encode(query_sentence).astype(np.float32)
Une fois les vecteurs chargés dans CockroachDB, des requêtes peuvent être formulées et exécutées pour toutes sortes de tâches de recherche basées sur la similarité. Pour cela, vous devez utiliser des métriques de distance qui fournissent un moyen fiable et mesurable de calculer la similarité ou la dissimilarité entre deux vecteurs.
Il existe de nombreuses métriques de distance que vous pouvez choisir selon votre cas d’utilisation, mais actuellement, seuls les opérateurs <-> Distance Euclidienne (L2), <#> Produit Interne (IP) et <=> Similarité Cosinus sont disponibles dans CockroachDB.
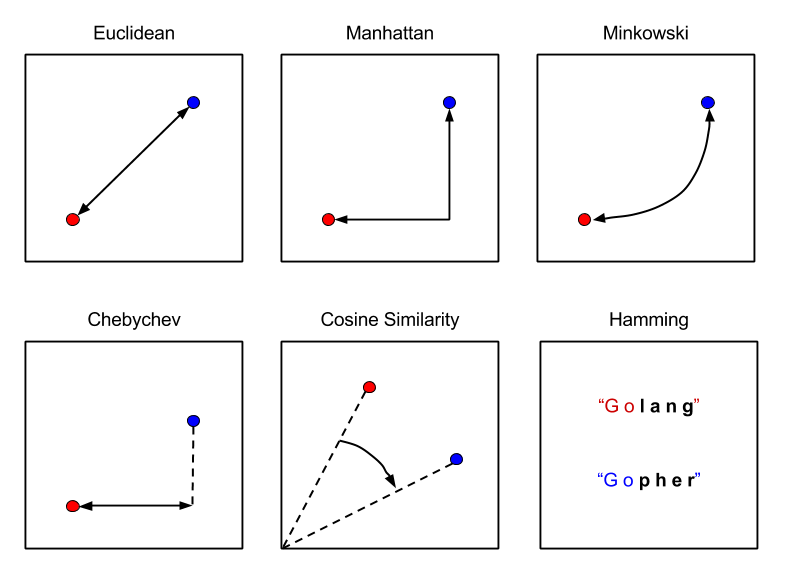
Métriques de distance
Voici une requête qui retourne les phrases les plus similaires à la nouvelle (That is a happy boy), triées par distance (similarité cosinus) :
# Connect to an existing database
with psycopg2.connect(crdb_url) as conn:
# Open a cursor to perform database operations
with conn.cursor() as cursor:
# Query the database and obtain data as Python objects.
cursor.execute('SELECT text, 1 - (text_vector <=> ' + query_vector + ') AS cosine_similarity FROM sentences ORDER BY cosine_similarity DESC')
Examinons cette requête :
SELECT text, 1 - (text_vector <=> query_vector) AS cosine_similarity FROM sentences ORDER BY cosine_similarity DESC;
Dans cette requête, nous demandons au moteur de recherche vectorielle de CockroachDB de calculer la similarité cosinus entre le vecteur de requête et chacun des vecteurs déjà stockés dans la table sentences, afin de déterminer à quel point les phrases se ressemblent.
La phrase That is a happy boy est la phrase la plus similaire à That is a happy girl (76 % de similarité) et That is a very happy person (70 % de similarité), mais très éloignée de I love dogs (seulement 24 %).
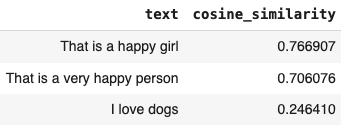
Résultats de la similarité cosinus
En effectuant ce calcul entre notre vecteur de requête et les trois autres vecteurs du graphique ci-dessus, nous pouvons déterminer à quel point les phrases sont sémantiquement similaires les unes aux autres.
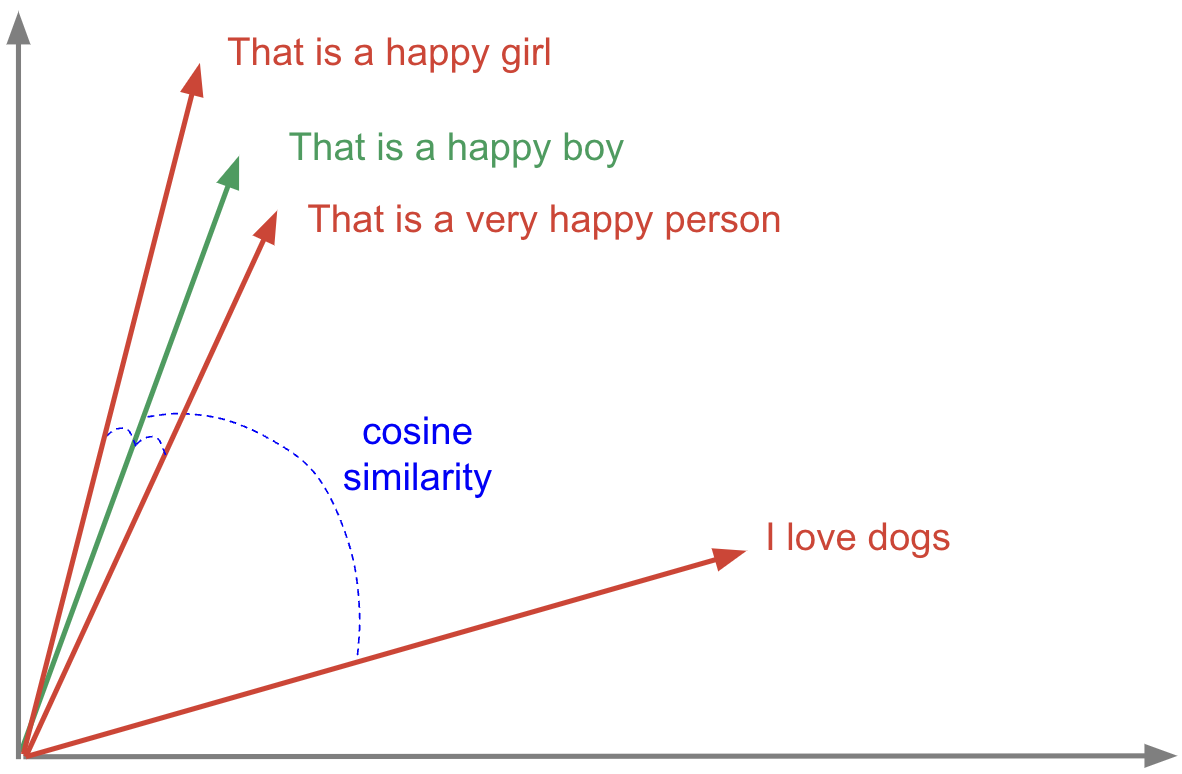
Calcul de la distance (similarité) entre les vecteurs
Les instructions ci-dessus constituent un bref aperçu de la façon d’utiliser et de récupérer des vector embeddings et démontrent les éléments constitutifs de la recherche par similarité vectorielle avec CockroachDB. Vous pouvez essayer cela avec le notebook référencé ici (installez Google Colab pour l’ouvrir).
Le support de l’API pgvector par CockroachDB permet une intégration fluide avec des frameworks d’IA populaires comme LangChain, Bedrock et Hugging Face, facilitant l’incorporation de données en temps réel dans vos workflows d’apprentissage automatique. Cette compatibilité transparente positionne CockroachDB comme un backend puissant pour les systèmes de Génération Augmentée par Récupération (RAG), fournissant des données fraîches, scalables et cohérentes pour enrichir le contenu généré par l’IA, le tout dans la même base de données que vous utilisez déjà pour vos données relationnelles et transactionnelles.
Chez Cockroach Labs, nous avons également activement développé le support de l’indexation vectorielle native dans la dernière version de CockroachDB, la v25.2. Cette amélioration permet à la base de données de réduire efficacement l’espace de recherche lors des requêtes de similarité, accélérant considérablement les temps d’exécution et réduisant la surcharge de calcul.
Avec l’indexation vectorielle, CockroachDB améliore encore les performances des charges de travail IA et d’apprentissage automatique, renforçant sa position en tant que solution puissante et scalable pour gérer des applications IA à grande échelle et intensives en données. Restez donc à l’écoute pour les prochains articles de cette série ! Nous plongerons plus profondément dans les capacités avancées de CockroachDB comme base de données vectorielle.