
Dans une vie antérieure, j’ai travaillé sur une application permettant aux utilisateurs de télécharger et de partager des photos avec leurs amis et leur famille. Je suis émerveillé par les progrès technologiques accomplis depuis cette époque. C’est presque magique que l’IA puisse « regarder » un ensemble de photos et « savoir » qu’elles ont été prises lors du premier anniversaire d’un enfant ou lors d’une randonnée en montagne. Des requêtes en langage naturel comme « montre-moi les photos de mon voyage à la Statue de la Liberté » ou même « trouve cette photo où je suis sur le point d’entrer en collision sur le terrain de foot avec un autre joueur » ne sont plus de la science-fiction.
Notre startup de partage de photos n’a jamais atteint des millions d’utilisateurs, mais je suppose que beaucoup d’entre vous qui lisez ceci travaillent sur des systèmes qui l’ont fait. À cette échelle, il est étonnamment facile de se retrouver à gérer des milliards, voire des dizaines de milliards d’éléments générés par les utilisateurs. S’il s’agit d’une application photo, la plupart des utilisateurs auront des centaines ou des milliers de photos. Les utilisateurs avancés ou les organisations pourraient en avoir des dizaines ou des centaines de milliers. Si ce ne sont pas des photos, ce peuvent être des documents, des notes, des vidéos ou de l’audio. Le type de contenu varie, mais les mathématiques sont les mêmes : des millions d’utilisateurs, chacun contribuant des centaines ou des milliers d’éléments, et vous opérez rapidement à l’échelle du milliard.
Même avec seulement quelques centaines d’éléments, les utilisateurs s’attendent à une recherche rapide et précise. S’ils téléchargent quelque chose, ils veulent le trouver immédiatement. S’ils effectuent une recherche, ils veulent des résultats en un clin d’œil. De plus en plus, la recherche par mots-clés de base ne suffit plus. À l’ère de ChatGPT, les utilisateurs s’attendent à une recherche sémantique, avec des résultats basés sur le sens du contenu, pas seulement sur les noms de fichiers, les métadonnées, les mots-clés ou les tags.
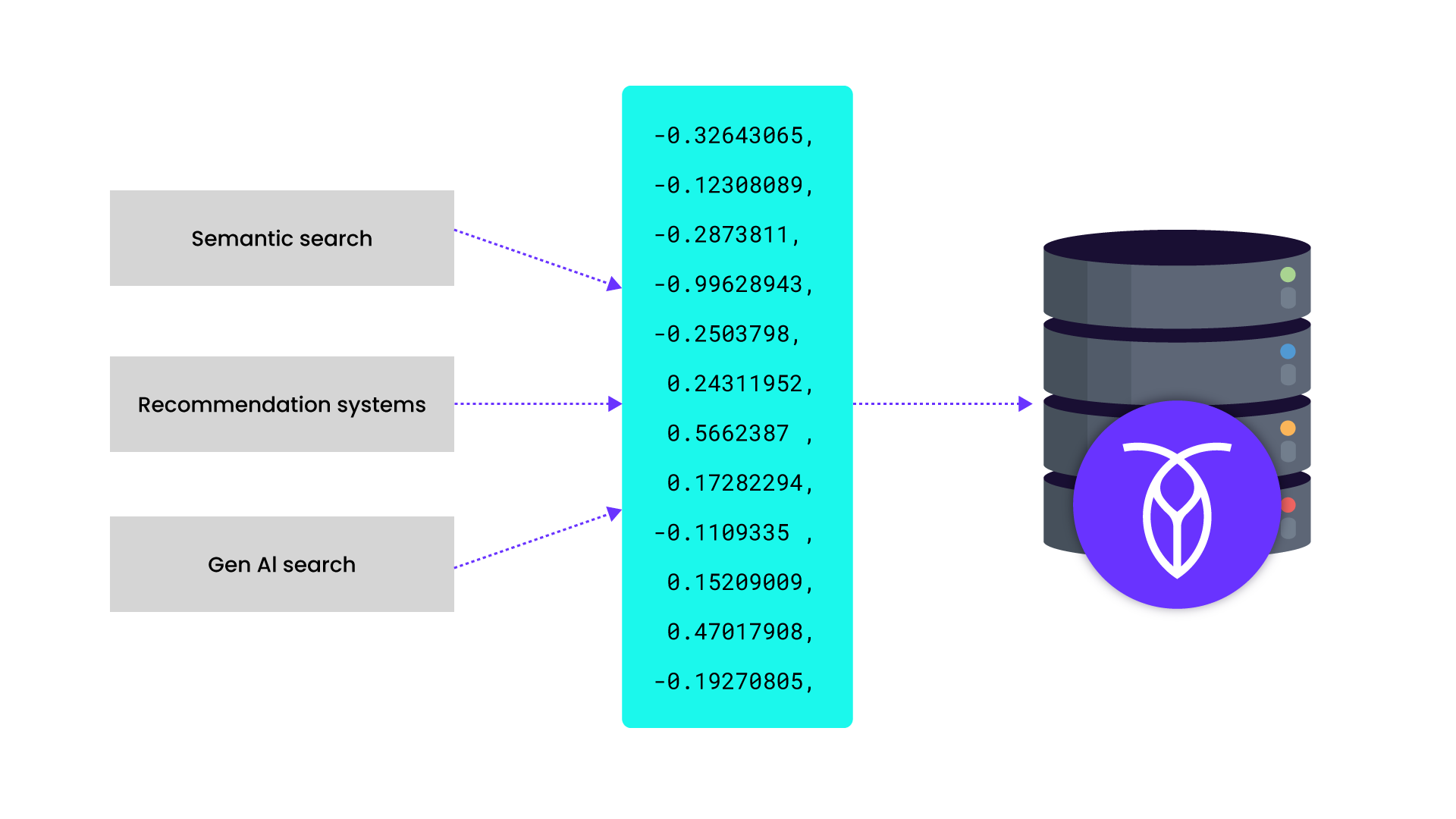
Workflow de recherche vectorielle IA avec CockroachDB
Certaines solutions à ce problème supposent que l’ensemble du jeu de données tient en mémoire sur une seule machine. Ou, au mieux, elles s’appuient sur un SSD local rapide. Beaucoup d’entre elles ne s’attendent pas à ce que vos données soient distribuées entre des régions, ou à ce qu’elles changent constamment, ou à ce qu’elles fassent partie d’un système transactionnel où la cohérence et la fraîcheur des données comptent vraiment. Elles viennent souvent avec des limitations importantes, comme la nécessité de regrouper les écritures, de retourner des résultats périmés, ou de nécessiter du matériel spécialisé pour fonctionner correctement.
CockroachDB a été construit avec un ensemble d’hypothèses différentes. En tant que base de données distribuée, elle s’attend à ce que les données vivent sur plusieurs machines, pouvant s’étendre sur des zones de disponibilité ou même des régions. Elle est conçue pour évoluer linéairement, de sorte que l’ajout de machines conduit à un débit proportionnellement plus élevé. Et en tant que base de données SQL transactionnelle, elle privilégie le retour de données fraîches et le support des mises à jour en temps réel. Tout cela doit être résilient aux pannes de machines, de disques et de réseau.
Lisez la suite pour découvrir comment nous avons combiné des recherches académiques récentes avec une ingénierie pratique pour résoudre le problème de la recherche sémantique à une échelle massive, avec des résultats frais en temps réel, en tirant parti de l’architecture distribuée unique de CockroachDB.
Incorporer le sens dans des vecteurs
Pour commencer, il est important de comprendre comment les systèmes peuvent analyser des photos ou chercher dans des documents par leur sens. Des entreprises comme OpenAI proposent des modèles d’embedding qui convertissent une image, un document ou tout autre média en une longue liste de nombres à virgule flottante, un vecteur, qui capture son sens. Si deux photos ou documents sont similaires, par exemple deux photos de plage, ils seront mappés vers des vecteurs proches les uns des autres dans un espace de haute dimension.
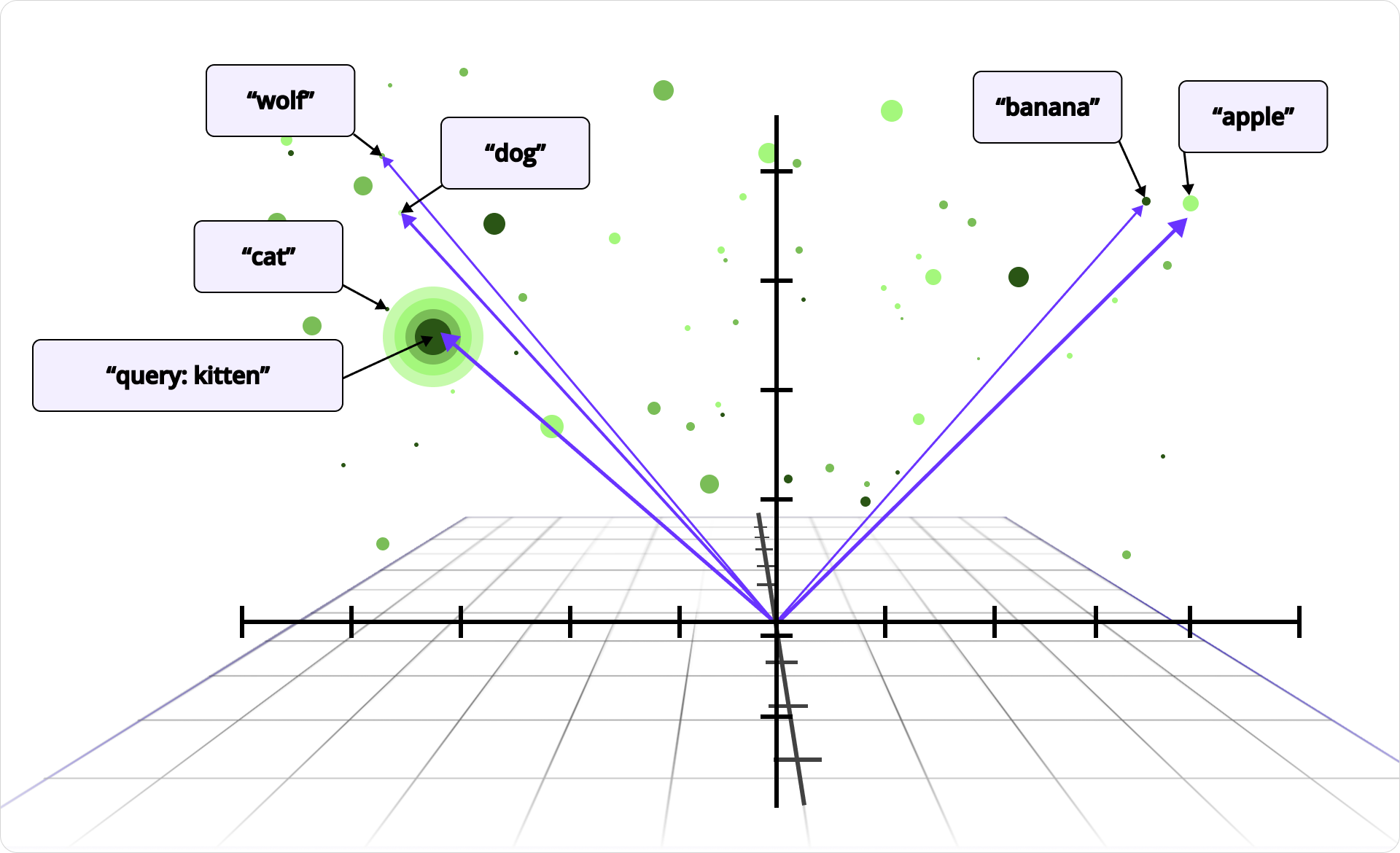
Exemple d’espace vectoriel
Incorporer le sens dans des vecteurs réduit des problèmes complexes comme la reconnaissance d’images et la recherche sémantique à un problème plus simple : trouver des vecteurs proches. Ces modèles sont construits sur les mêmes techniques de deep learning qui alimentent des systèmes comme ChatGPT, de grands réseaux de neurones entraînés pour capturer le sens et le contexte à travers de nombreux types de données.
Cela fonctionne même entre différents types de médias. Les modèles multimodaux intègrent du texte et des images dans le même espace vectoriel. Ainsi, le mot « plage » et une vraie photo de plage finissent dans la même région. Lorsqu’un utilisateur tape « plage », nous pouvons intégrer cette requête dans un vecteur et rechercher des vecteurs de photos proches. Les correspondances les plus proches sont très probablement liées à la plage.
Comment le sens est indexé
Illustration de la sortie des modèles d’embedding
Les vecteurs d’embedding ont souvent des centaines ou des milliers de dimensions qui leur permettent de représenter des sens complexes. Mais cela les rend aussi difficiles à chercher. Réfléchissez-y : les photos de plage doivent-elles venir avant ou après les photos de nourriture ? Qu’en est-il des photos de nourriture à la plage ? Il n’y a pas d’ordre naturel pour les vecteurs multidimensionnels, comme il y en a pour les nombres ou les chaînes de caractères. Cela signifie que les index traditionnels ne s’appliquent pas.
Au lieu de chercher des correspondances exactes, les requêtes sémantiques ont besoin de trouver des vecteurs proches dans un espace multidimensionnel. À petite échelle, la recherche par force brute est souvent suffisante : vous pouvez scanner le jeu de données, calculer les distances et retourner les correspondances les plus proches. Mais à mesure que le nombre de vecteurs croît vers des dizaines de milliers et au-delà, cette approche devient trop lente pour être pratique.
Les index vectoriels résolvent ce problème en trouvant efficacement les voisins les plus proches approximatifs. Ces index échangent une petite quantité de précision contre un grand gain en performance. S’ils ne garantissent pas que les vecteurs les plus proches exacts seront retournés, les résultats sont suffisamment proches pour être utiles, et les gains de performance rendent la recherche en temps réel possible à grande échelle.
Adapter les algorithmes d’indexation vectorielle au SQL distribué
Même avec un bon algorithme d’indexation vectorielle, l’intégrer dans une base de données SQL distribuée comme CockroachDB n’est pas simple. Pour supporter la scalabilité élastique, la tolérance aux pannes et la disponibilité multi-région, tout algorithme d’indexation doit suivre un ensemble de règles architecturales :
-
Pas de coordinateur central. Tout nœud du cluster doit pouvoir servir les lectures et les écritures. L’index ne peut pas s’appuyer sur un leader unique pour coordonner les requêtes ou les mises à jour.
-
Pas de grandes structures en mémoire. L’état de l’index doit vivre dans un stockage persistant. Nous ne pouvons pas supposer que chaque nœud dispose de gigaoctets de RAM disponibles pour mettre en cache des vecteurs, et nous voulons éviter de longs temps de démarrage passés à construire de grandes structures en mémoire. C’est particulièrement important pour les déploiements Serverless.
-
Nombre minimal de sauts réseau. Les allers-retours entre nœuds sont coûteux. Les index qui nécessitent une traversée séquentielle entre les nœuds peuvent accumuler de la latence rapidement et rendre les performances imprévisibles.
-
Disposition compatible avec le partitionnement. Les données d’index doivent se mapper naturellement aux plages clé-valeur de CockroachDB pour pouvoir être divisées, fusionnées et rééquilibrées comme n’importe quelle autre donnée.
-
Pas de points chauds. À mesure que les insertions et les requêtes de vecteurs s’intensifient, l’index doit éviter de concentrer le trafic sur un seul nœud ou une seule plage. La charge doit être équilibrée à travers le cluster.
-
Mises à jour incrémentales. L’index doit gérer les insertions et les suppressions en temps réel, sans bloquer les requêtes, nécessiter de grandes reconstructions, ou nuire à la qualité de la recherche.
Ces contraintes ont éliminé de nombreuses approches courantes. Nous avions besoin de quelque chose qui s’intègre parfaitement dans le modèle d’exécution de CockroachDB et exploite la puissance de son architecture distribuée. C’est là qu’intervient C-SPANN.
Présentation de C-SPANN
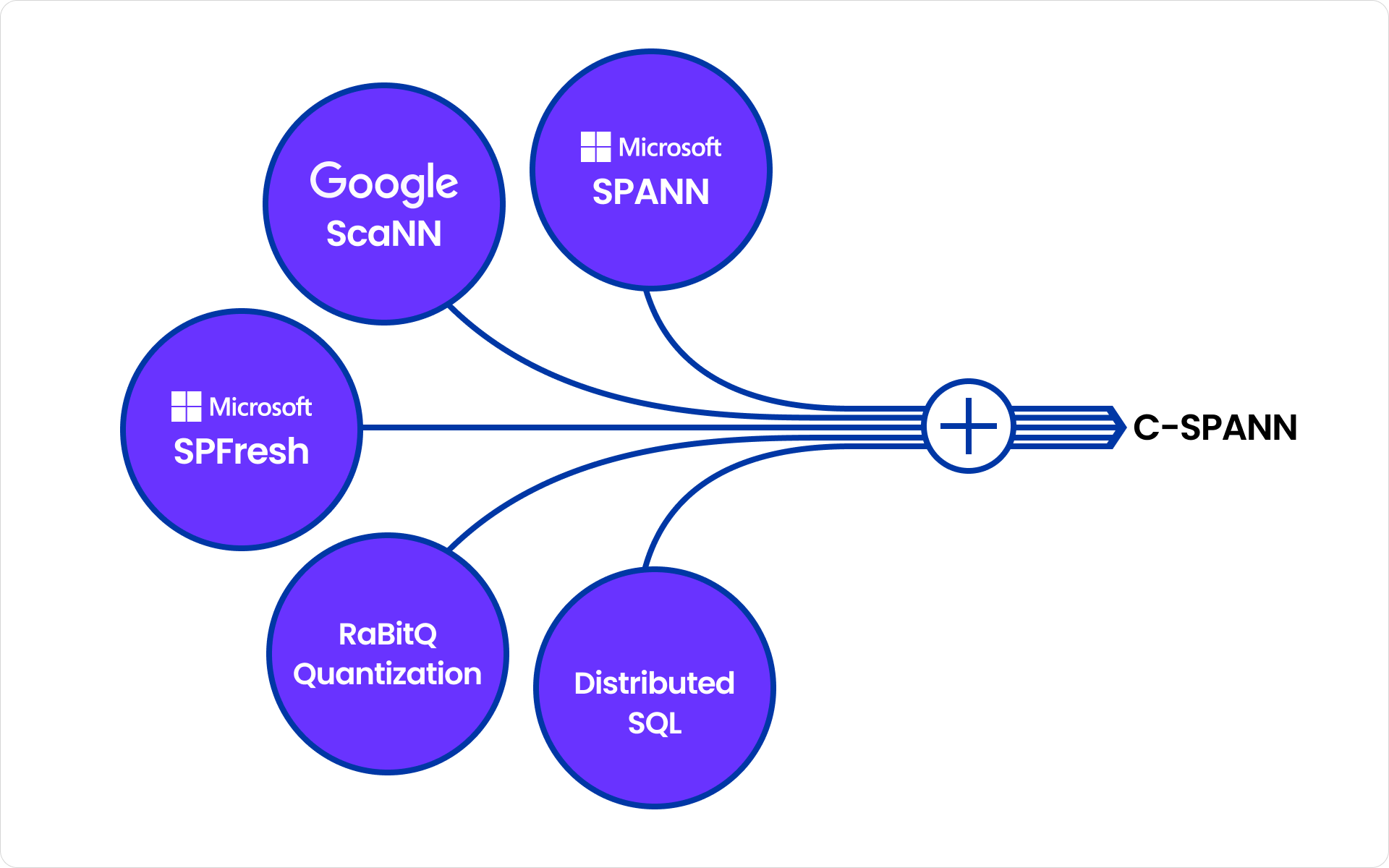
Recherches avant CockroachDB C-SPANN
C-SPANN, abréviation de CockroachDB SPANN, est un algorithme d’indexation vectorielle qui intègre des idées des publications SPANN et SPFresh de Microsoft Research, ainsi que du projet ScaNN de Google.
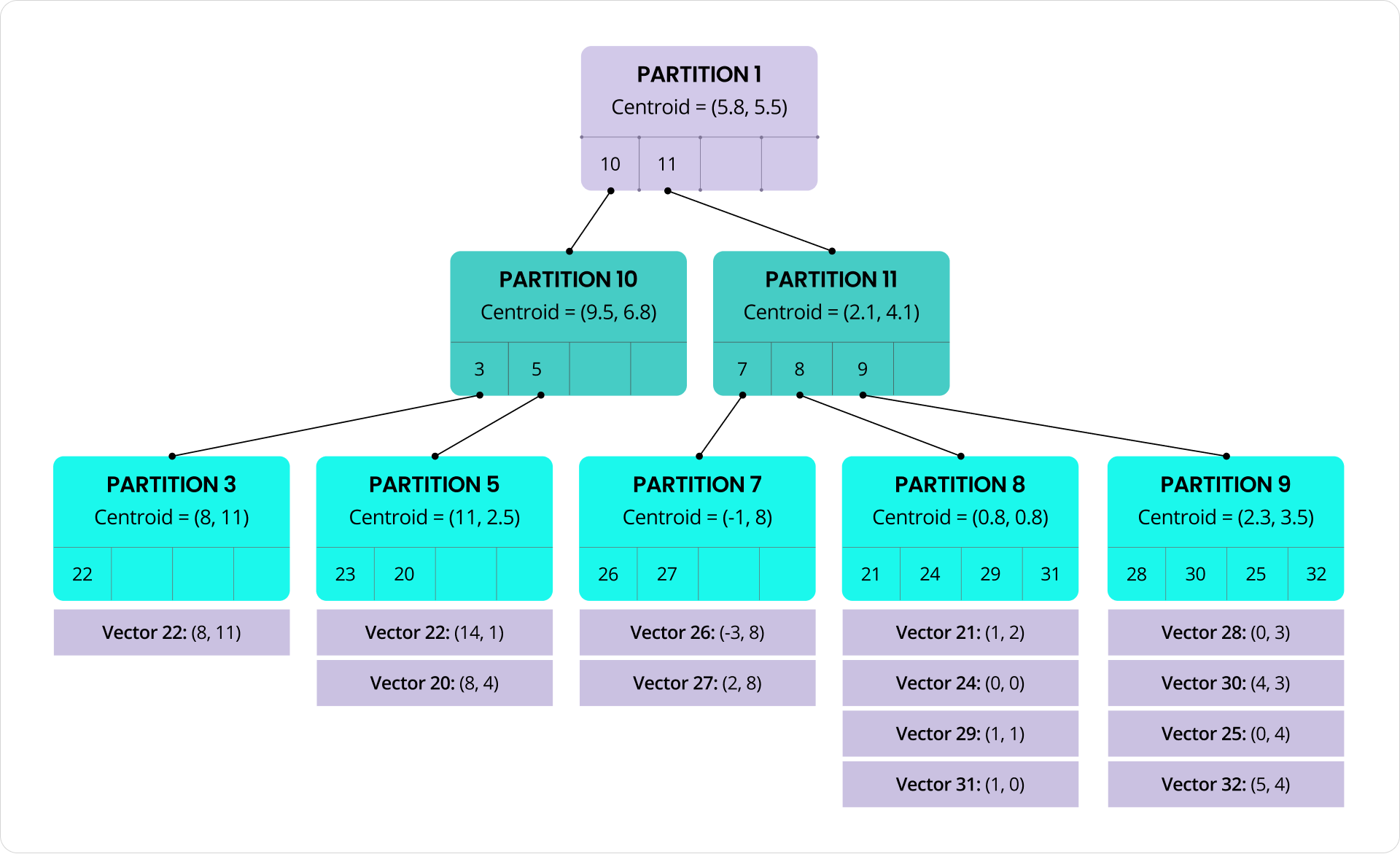
Arbre K-means alimentant l’indexation vectorielle C-SPANN de CockroachDB
Au cœur de C-SPANN se trouve un arbre K-means hiérarchique. Les vecteurs sont regroupés en partitions basées sur leur similarité, chaque partition contenant entre des dizaines et des centaines de vecteurs. Chaque partition possède un centroïde, qui est la moyenne des vecteurs qu’elle contient, représentant leur « centre de masse ». Ces centroïdes sont récursivement regroupés en partitions de niveau supérieur, formant un arbre qui réduit efficacement l’espace de recherche.
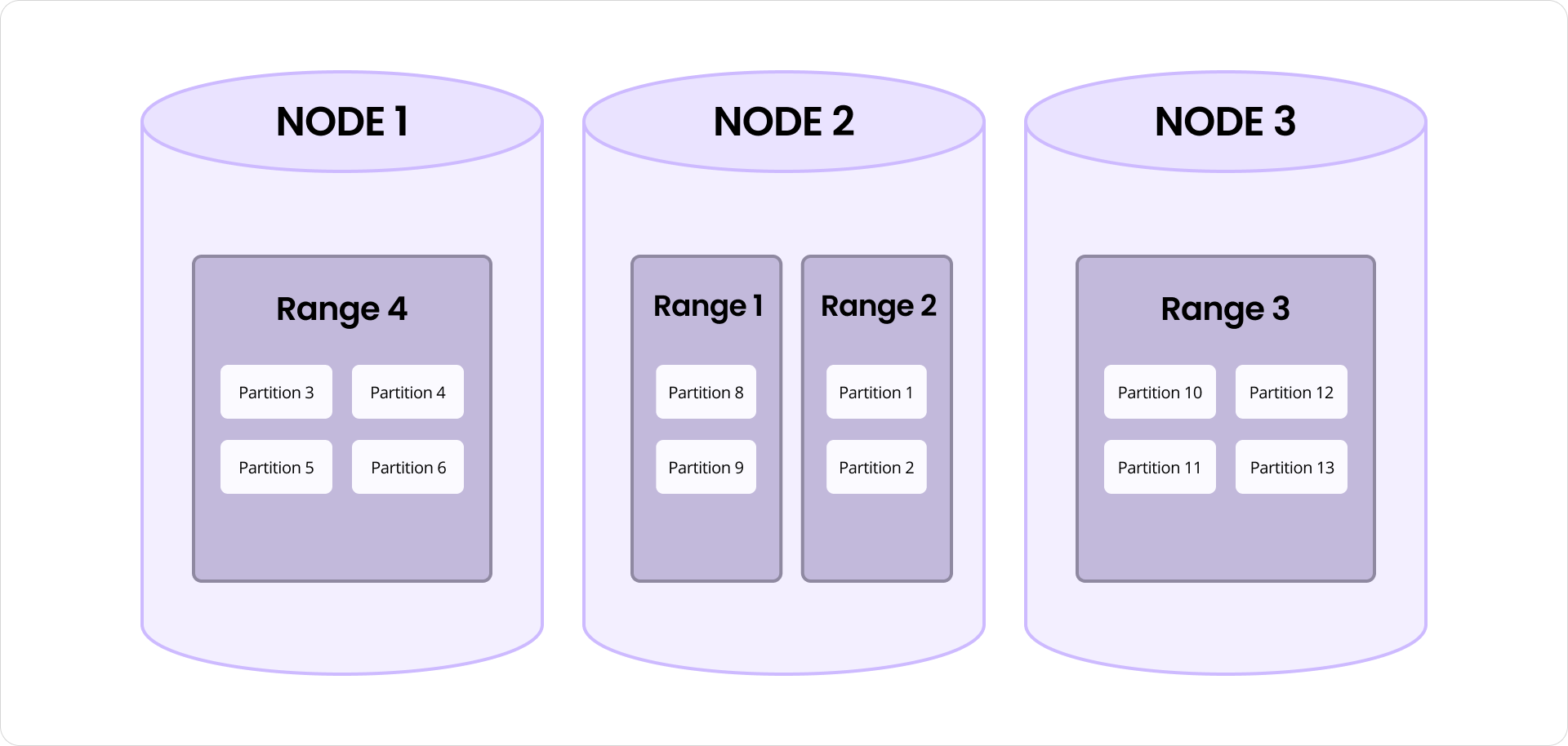
Partitions mappées sur les nœuds CockroachDB
Chaque partition est stockée comme une unité autonome dans la couche clé-valeur de CockroachDB, rendant l’index naturellement compatible avec le partitionnement. Les données de partition sont disposées comme un ensemble contigu de lignes clé-valeur dans une plage CockroachDB. À mesure que les partitions sont ajoutées, supprimées ou grandissent en taille, les plages sous-jacentes peuvent être automatiquement divisées, fusionnées et rééquilibrées par la base de données, tout comme n’importe quelle autre donnée de table.
Au moment d’une requête, la recherche commence à la racine de l’arbre. Nous comparons le vecteur de requête aux centroïdes à ce niveau, puis descendons dans les partitions avec les correspondances les plus proches. Ce processus se répète à chaque niveau jusqu’à ce que nous atteignions les feuilles, où nous scanons un petit nombre de vecteurs candidats. Les partitions à chaque niveau peuvent être traitées en parallèle, contribuant à réduire la latence. Et parce que les vecteurs dans une partition sont regroupés ensemble et sont similaires par conception, nous pouvons tirer parti des instructions CPU SIMD pour scanner efficacement des blocs de vecteurs.
Comme le facteur de ramification de l’arbre est généralement d’environ 100, la structure reste large et peu profonde. Cela maintient le nombre de niveaux (et donc le nombre d’allers-retours réseau) petit et prévisible, même à grande échelle. Un index avec 1 million de vecteurs nécessite seulement 3 niveaux ; même un index avec 10 milliards de vecteurs n’en nécessite que 5. Pour réduire encore davantage les allers-retours, la partition racine peut être mise en cache en mémoire.
C-SPANN évite également la coordination centrale. Tout nœud peut servir des requêtes ou gérer des insertions et des mises à jour. La structure de l’index vit dans un stockage persistant, il n’est donc pas nécessaire d’avoir de grands caches de vecteurs en mémoire ni de structures de données personnalisées qui doivent être reconstruites au démarrage. Les lignes de partition sont plutôt mises en cache automatiquement par le cache de blocs de la couche de stockage, tout comme n’importe quelle autre donnée de table. Cela permet aux recherches d’éviter des lectures répétées sur disque, sans nécessiter de RAM supplémentaire ni de logique de mise en cache vectorielle spécialisée.
Regardez cette démonstration de l’évangéliste technique Rob Reid pour voir l’indexation vectorielle en action :
Maintenir un index sain
À mesure que de nouveaux vecteurs sont insérés dans l’index, ils se dispersent naturellement à travers les partitions, qui sont elles-mêmes distribuées à travers le cluster. Il n’y a pas de plage ou de nœud unique qui absorbe une part disproportionnée du trafic d’écriture, ce qui contribue à prévenir la formation de points chauds. Mais avec le temps, certaines partitions deviendront trop grandes et devront être divisées.
Les divisions se produisent automatiquement en arrière-plan pour réduire l’impact sur les transactions au premier plan. Lorsqu’une division est déclenchée, les vecteurs dans la partition d’origine sont divisés en deux groupes à peu près égaux en utilisant une variante équilibrée de l’algorithme K-means. Chaque groupe devient une nouvelle partition plus étroitement regroupée avec son propre centroïde. L’arbre est mis à jour pour refléter ce changement, et les futures insertions sont acheminées vers les nouvelles partitions en fonction de leur proximité avec ces nouveaux centroïdes. Voici un exemple où la partition 4 est remplacée par les partitions 5 et 6 au niveau feuille de l’arbre :
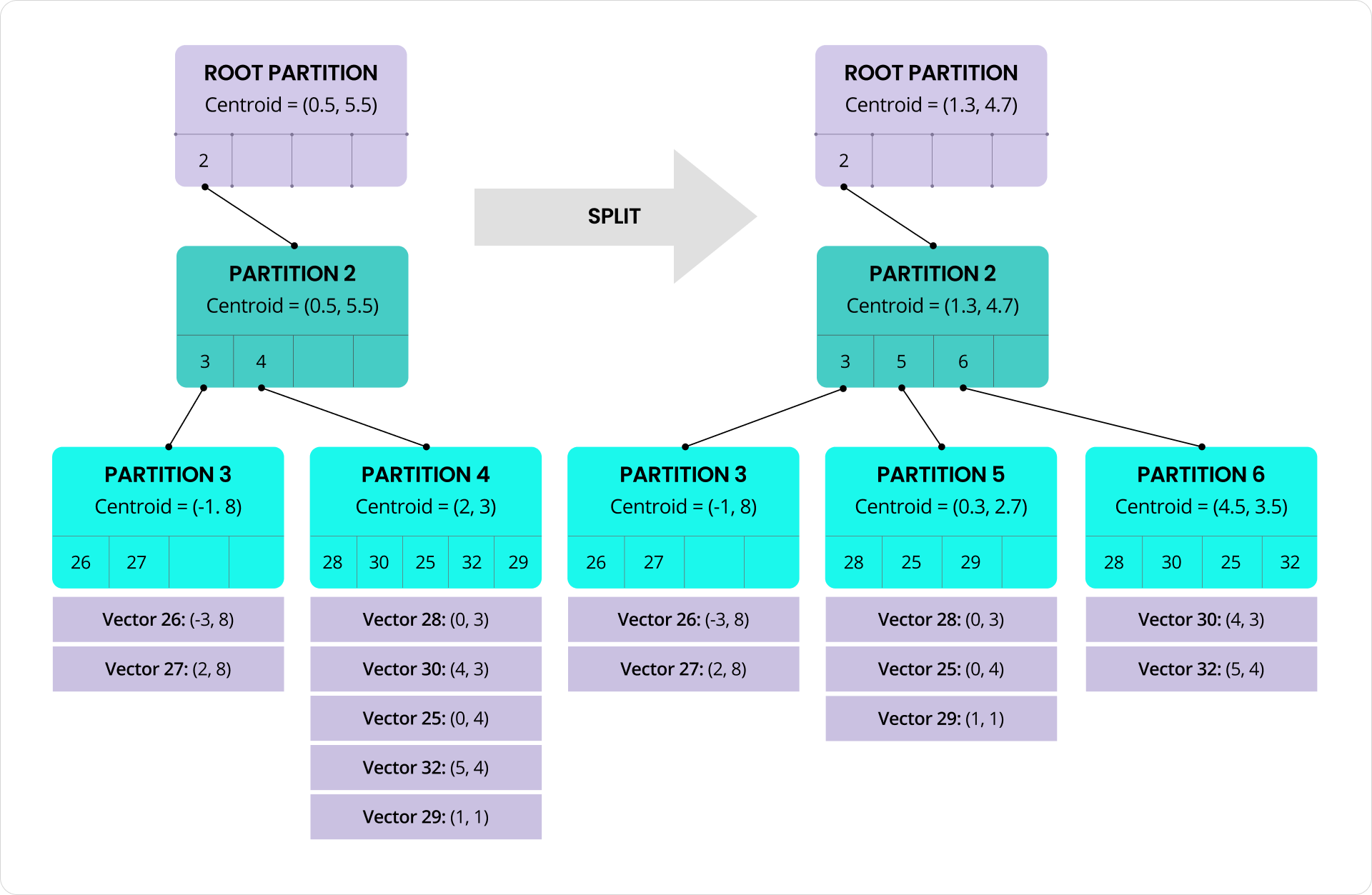
Exemple de remplacement de partition dans C-SPANN
Il convient également de noter que les divisions de partitions sont distinctes des divisions de plages de CockroachDB, bien que les deux fonctionnent ensemble pour garantir la scalabilité et des performances constantes. Une partition est une unité logique au sein de l’index qui regroupe des vecteurs similaires. Une plage est une unité physique de stockage dans la couche clé-valeur. La division d’une partition améliore l’efficacité de la recherche en maintenant un regroupement étroit des vecteurs. La division d’une plage aide à équilibrer le stockage des données et les accès à travers le cluster. Ensemble, ces mécanismes réduisent les points chauds et aident à répartir plus uniformément la charge des requêtes et des insertions. Lorsque des nœuds sont ajoutés au système, les plages contenant des partitions d’index sont automatiquement distribuées sur les nouveaux nœuds, permettant à la charge de travail totale de s’étendre avec le cluster à des taux quasi-linéaires.
Il y a une subtilité à noter : certains vecteurs peuvent ne plus être dans la « bonne » partition après une division. Un vecteur dans la partition en cours de division peut être plus proche du centroïde d’une partition voisine que de l’un des deux nouveaux centroïdes. De même, un vecteur dans une partition voisine peut maintenant être plus proche de l’un des nouveaux centroïdes. Dans les deux cas, les vecteurs doivent être relocalisés vers la partition dont le centroïde est le plus proche. Pour voir comment cela peut se produire, considérez ces clusters rouge et bleu (les centroïdes sont marqués d’un X) :
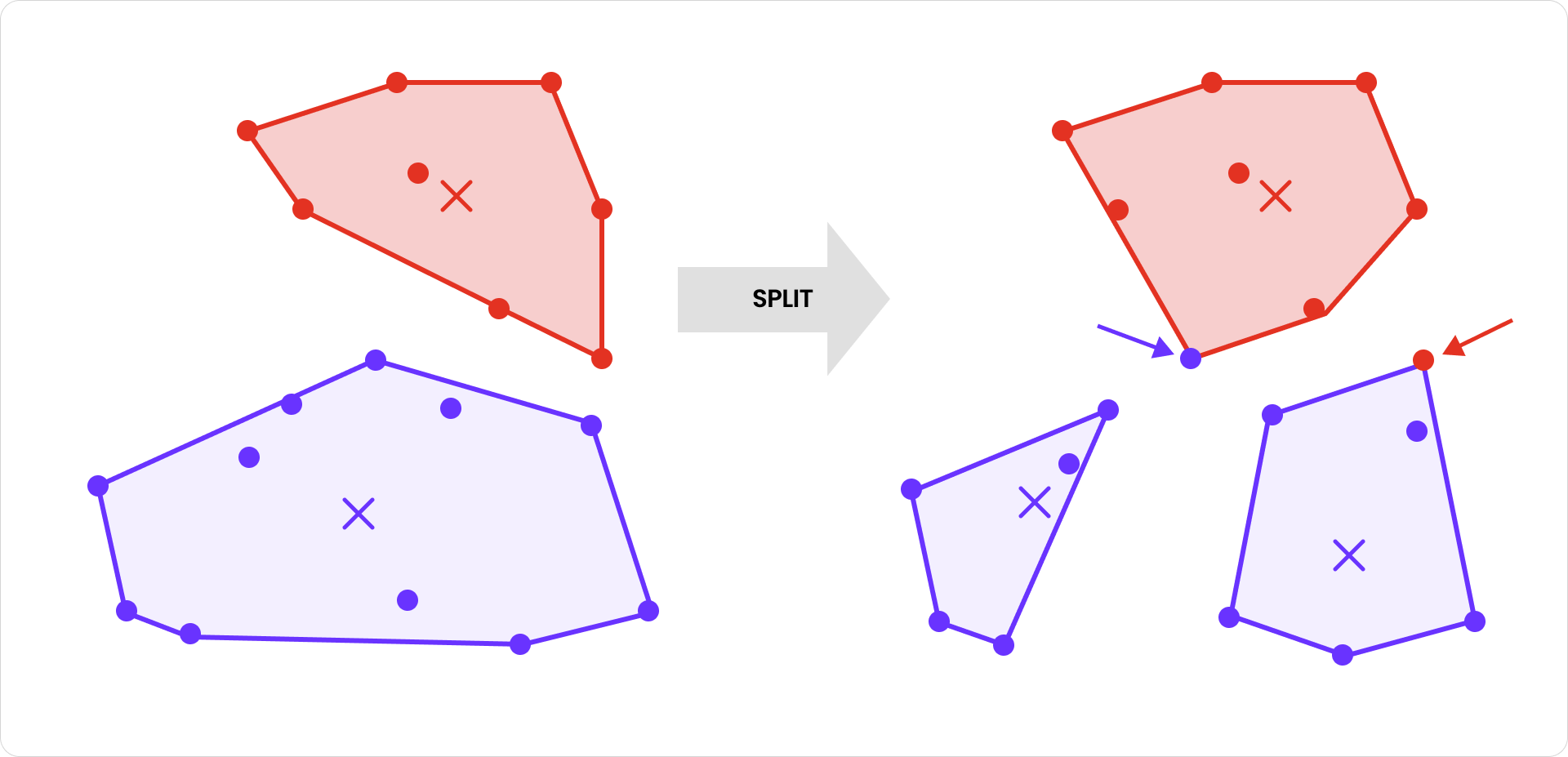
Division de partition et relocalisation de vecteurs
Après la division du cluster bleu, l’un de ses vecteurs est réaffecté au cluster rouge parce qu’il est maintenant plus proche du centroïde rouge que de l’un ou l’autre des nouveaux centroïdes bleus. De même, l’un des vecteurs rouges est réaffecté au cluster bleu de droite pour la même raison. La relocalisation des vecteurs basée sur la proximité mise à jour est introduite dans la publication SPFresh (dans le cadre de l’assurance d’une « affectation à la partition la plus proche ») et joue un rôle clé dans le maintien d’une haute précision du clustering après les divisions.
Tandis que les divisions garantissent que les partitions ne deviennent pas trop grandes, les fusions garantissent qu’elles ne deviennent pas trop petites. Si des vecteurs sont supprimés ou déplacés de telle sorte qu’une partition tombe en dessous de la taille minimale, un processus d’arrière-plan la fusionne. Ses vecteurs sont réaffectés aux partitions voisines, et la partition d’origine est supprimée de l’arbre.
Ensemble, les divisions, fusions et réaffectations de partitions sont très efficaces pour préserver la précision de l’index, même après de nombreux cycles d’insertions, de mises à jour et de suppressions de vecteurs. En fait, l’approche fonctionne si bien qu’il n’y a pas beaucoup à gagner à reconstruire l’index après l’ajout de nouvelles données. Vous pouvez commencer avec une table vide, insérer des millions de vecteurs, et obtenir quand même une haute précision. L’index s’adapte rapidement et dynamiquement au fur et à mesure que les données évoluent, se maintenant équilibré et efficace dans le temps.
Réduire la taille de l’index de 94 %
Les vecteurs en précision complète sont coûteux. Les embeddings OpenAI, par exemple, utilisent 1 536 dimensions avec des flottants 2 octets, ce qui représente environ 3 Ko par vecteur. Multipliez par des millions de vecteurs, et la taille de l’index s’accumule rapidement. Le stockage est un coût, mais souvent la dépense plus grande est le CPU et la mémoire nécessaires pour charger et scanner les vecteurs complets lors des recherches dans l’index.
Pour réduire cette surcharge, C-SPANN utilise une technique appelée quantification pour compresser les vecteurs stockés dans l’index. Au lieu de stocker des vecteurs complets, il stocke des représentations binaires compactes qui approximent les originaux. Lors d’une recherche, les distances sont calculées en utilisant ces formes quantifiées, qui sont à la fois plus petites et plus rapides à scanner.
Bien qu’il existe de nombreux algorithmes de quantification, nous en utilisons un appelé RaBitQ, qui réduit chaque dimension du vecteur à un seul bit. Il stocke ces bits avec quelques valeurs précalculées par vecteur, atteignant une réduction d’environ 94 % de la taille pour les cas courants. Dans l’exemple des embeddings OpenAI, cela réduit un vecteur d’environ 3 Ko à seulement environ 200 octets.
Cette approche s’intègre naturellement avec l’arbre K-means : chaque vecteur est quantifié par rapport au centroïde de la partition à laquelle il appartient, permettant un regroupement plus étroit et une meilleure précision. Parce que la quantification est locale à chaque partition, les divisions et fusions nécessitent seulement de re-quantifier les vecteurs dans la partition affectée. Cela permet à l’index d’évoluer de manière incrémentale et locale, sans coordination centralisée ni ré-entraînement global.
Bien que je ne rentre pas dans tous les détails, je veux vous montrer à quel point l’algorithme de base RaBitQ est beau et simple. Chaque vecteur de données est d’abord « mélangé » avec une transformation orthogonale aléatoire, ce qui répartit plus uniformément tout biais des données entre les dimensions tout en préservant les angles et les distances. Il est ensuite centré sur la moyenne par rapport au centroïde de la partition et normalisé à une longueur unitaire. Enfin, chaque dimension est convertie en un bit : zéro si la valeur est inférieure à zéro, un sinon.
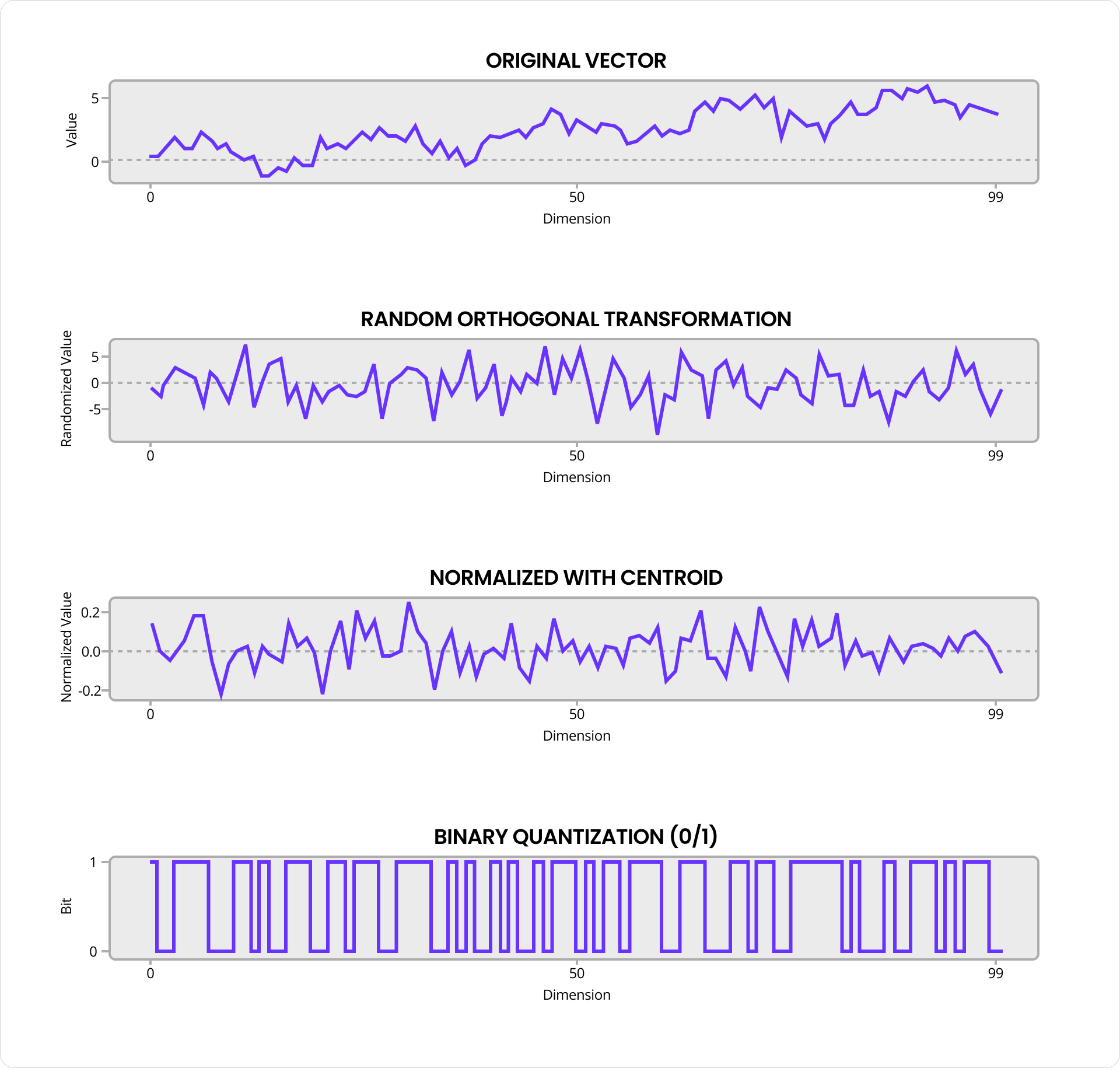
Quantification RaBitQ dans C-SPANN
Le résultat est une chaîne de bits qui capture l’essence du vecteur original sous une forme hautement compressée. Ces bits sont stockés avec le produit scalaire entre les vecteurs quantifié et original, ainsi que la distance exacte du vecteur original par rapport au centroïde. Remarquablement, cela suffit pour estimer les distances avec une précision raisonnable. Pour rendre les comparaisons de distances à la fois rapides et compactes, RaBitQ utilise une méthode de quantification différente pour le vecteur de requête qui attribue 4 bits par dimension et est optimisée pour les instructions SIMD.
Comme la quantification est avec perte, ces estimations de distances ne sont qu’approximatives. Pour corriger cela, C-SPANN inclut une étape de rerankage. Nous scannons les vecteurs quantifiés pour construire un ensemble de candidats, puis récupérons les vecteurs complets originaux de la table pour recalculer les distances exactes. En récupérant plus de vecteurs candidats que nécessaire, nous pouvons compenser l’erreur de quantification. RaBitQ fournit des bornes d’erreur qui aident à déterminer combien de vecteurs supplémentaires sont nécessaires pour trouver les vrais voisins les plus proches avec une haute probabilité.
Le résultat est le meilleur des deux mondes : des scans rapides et compacts avec des résultats précis.
Un index pour chaque utilisateur
J’ai expliqué comment C-SPANN peut regrouper un grand nombre de vecteurs et maintenir l’index à jour avec des mises à jour incrémentales en temps réel. Mais il y a un autre aspect important de l’histoire. Dans la plupart des applications réelles, ces vecteurs appartiennent à quelqu’un, qu’il s’agisse d’un utilisateur, d’un client, d’un locataire ou de tout autre propriétaire. Et la plupart des requêtes sont limitées à un seul propriétaire. En fait, inclure des vecteurs d’autres propriétaires pourrait être un problème de sécurité.
Les index vectoriels de CockroachDB gèrent cela proprement en supportant les colonnes de préfixe, qui permettent à l’index d’être partitionné par propriété (ou par n’importe quoi d’autre). Voici un exemple simple :
CREATE TABLE photos (
id UUID PRIMARY KEY,
user_id UUID,
embedding VECTOR(1536),
VECTOR INDEX (user_id, embedding)
);
Dans ce cas, l’index vectoriel est partitionné par la colonne user_id en tête. Cela signifie que les embeddings de photos sont indexés et recherchés par utilisateur. Voici une requête qui trouve les 10 photos les plus proches pour un utilisateur donné, en utilisant la syntaxe compatible pgvector :
SELECT id
FROM photos
WHERE user_id = $1
ORDER BY embedding <-> $2
LIMIT 10
Même si l’index contient des milliards de photos, cette requête ne cherchera que dans le sous-ensemble appartenant à un utilisateur. Les performances pour les insertions et les recherches sont proportionnelles au nombre de vecteurs appartenant à cet utilisateur, pas au nombre total de vecteurs dans le système. La contention entre les utilisateurs est minimisée, car les requêtes ne touchent pas les mêmes partitions d’index ni les mêmes lignes.
En coulisses, l’index maintient un arbre K-means séparé pour chaque utilisateur distinct. Du point de vue du système, il n’y a pas beaucoup de différence entre 1 milliard de vecteurs arrangés dans un seul arbre ou le même nombre réparti sur un million d’arbres plus petits. Les vecteurs sont toujours assignés à des partitions et regroupés dans des plages dans la couche clé-valeur de CockroachDB. Ces plages sont automatiquement divisées, fusionnées et distribuées entre les nœuds, tout comme n’importe quelle autre donnée, permettant une scalabilité quasi-linéaire à mesure que l’utilisation croît.
Des utilisateurs dans chaque région
Les colonnes de préfixe deviennent encore plus puissantes lorsqu’elles sont utilisées avec les fonctionnalités multi-région de CockroachDB. Par exemple, vous pouvez utiliser une table REGIONAL BY ROW pour stocker les données de chaque utilisateur dans sa région d’origine, ce qui réduit la latence et aide à satisfaire les exigences de domiciliation des données.
Cette instruction ajoute automatiquement une colonne crdb_region à la table, qui est incluse dans l’index vectoriel aux côtés de user_id et embedding. Cela garantit que les lignes de la table et de l’index sont co-localisées dans la région spécifiée par la valeur crdb_region de chaque ligne. Les photos d’un utilisateur en Europe seront stockées en Europe, avec un accès local rapide depuis cette région. Les photos d’un utilisateur aux États-Unis seront stockées aux États-Unis, avec un accès tout aussi faible en latence. La combinaison de crdb_region et user_id comme colonnes de préfixe partitionne l’index à la fois par localisation et par propriété, le rendant efficace, sécurisé et conscient de la localité par défaut.