
Les moteurs de recommandation ont acquis une immense importance dans le paysage numérique actuel. Face à l’intensification de la concurrence mondiale, les entreprises s’appuient fréquemment sur des systèmes de recommandation pour améliorer l’expérience utilisateur, stimuler l’engagement et augmenter les revenus.
Dans le secteur du e-commerce, les moteurs de recommandation permettent des fonctions clés telles que les recommandations de produits personnalisées, la vente croisée et la vente incitative. En comprenant les préférences et l’historique d’achat des acheteurs, ces systèmes peuvent suggérer des produits et des services alignés avec leurs intérêts, ce qui conduit à une plus grande satisfaction des clients et à des achats répétés.
Dans les secteurs du divertissement et du streaming de contenu, par exemple, les moteurs de recommandation jouent un rôle crucial en suggérant des films, des séries télévisées, de la musique ou des articles pertinents. En analysant le comportement et les préférences d’un utilisateur, des plateformes comme Netflix, Spotify et YouTube fournissent des recommandations personnalisées qui améliorent la satisfaction des utilisateurs et les encouragent à explorer davantage de contenu.
Heureusement, la mise en œuvre d’un moteur de recommandation ne doit pas être compliquée. Avec les capacités vectorielles de CockroachDB, votre entreprise peut mettre en œuvre des systèmes de recommandation complets, pour fournir des recommandations personnalisées parmi des milliards d’options possibles en un rien de temps.
Cet article vous guidera à travers le processus de conception et de construction d’un moteur de recommandation en ligne alimenté par les capacités vectorielles natives de CockroachDB :
-
Il commence par expliquer les fondamentaux des systèmes de recommandation et comment différentes approches, comme le filtrage basé sur le contenu, le filtrage collaboratif et le filtrage hybride, peuvent améliorer l’expérience utilisateur dans des secteurs tels que le e-commerce et le streaming de médias.
-
Vous apprendrez ensuite comment générer et stocker des embeddings d’images et de texte, implémenter une recherche de similarité en temps réel, et construire des requêtes de recommandation scalables à faible latence en utilisant l’architecture SQL distribuée de CockroachDB.
-
Tout au long du parcours, nous explorerons comment le support de CockroachDB pour l’indexation vectorielle (C-SPANN), le partitionnement par préfixe et la forte cohérence en font un choix idéal pour construire des applications IA hautes performances.
Que vous soyez développeur, ingénieur de données ou architecte, vous pouvez adapter ce tutoriel pratique à votre propre cas d’utilisation unique.
Vue d’ensemble des systèmes de recommandation
Qu’est-ce qu’un moteur de recommandation ? Les moteurs de recommandation sont des modèles statistiques qui analysent les données des utilisateurs, telles que l’historique de navigation, le comportement d’achat, les préférences et les données démographiques, pour fournir des recommandations personnalisées. Ces recommandations peuvent prendre la forme de suggestions de produits, de recommandations de contenu ou de services pertinents.
L’importance des moteurs de recommandation réside dans leur capacité à répondre aux préférences individuelles des utilisateurs et à rationaliser les processus de prise de décision. En offrant des suggestions personnalisées, les entreprises peuvent engager efficacement les utilisateurs, les maintenir sur leurs plateformes plus longtemps, et finalement augmenter les taux de conversion et les ventes.
Les moteurs de recommandation ont considérablement évolué depuis leur création au milieu des années 1990. Les premiers systèmes étaient largement basés sur des règles, s’appuyant sur des évaluations explicites des utilisateurs et des associations organisées manuellement pour suggérer du contenu. L’un des premiers exemples notables était le filtrage collaboratif item-à-item d’Amazon, qui a révolutionné les recommandations de produits en analysant les modèles de comportement des utilisateurs à grande échelle.
À mesure que l’utilisation du web et les volumes de données augmentaient, la sophistication de ces systèmes a également grandi, passant d’approches heuristiques à des modèles d’apprentissage automatique capables de capturer des modèles plus profonds dans les préférences des utilisateurs. L’émergence du deep learning a marqué un tournant, permettant l’utilisation de réseaux de neurones et d’embeddings pour représenter les utilisateurs et les articles dans des espaces vectoriels de haute dimension.
Plus récemment, les architectures basées sur les transformers et la recherche vectorielle en temps réel ont encore amélioré la personnalisation et la réactivité des recommandations en ligne. Aujourd’hui, les moteurs de recommandation sont une partie essentielle de presque toutes les plateformes numériques, du e-commerce aux services de streaming, jouant un rôle central dans l’engagement des utilisateurs, la rétention et la génération de revenus.
Il existe plusieurs types de systèmes de recommandation couramment utilisés :
Filtrage basé sur le contenu : Cette approche recommande des articles aux utilisateurs en fonction de leurs préférences et caractéristiques. Elle analyse le contenu et les attributs des articles avec lesquels les utilisateurs ont interagi ou qu’ils ont évalués positivement et suggère des articles similaires. Par exemple, si un utilisateur aime les films d’action dans un système de recommandation de films, le système recommandera d’autres films d’action.
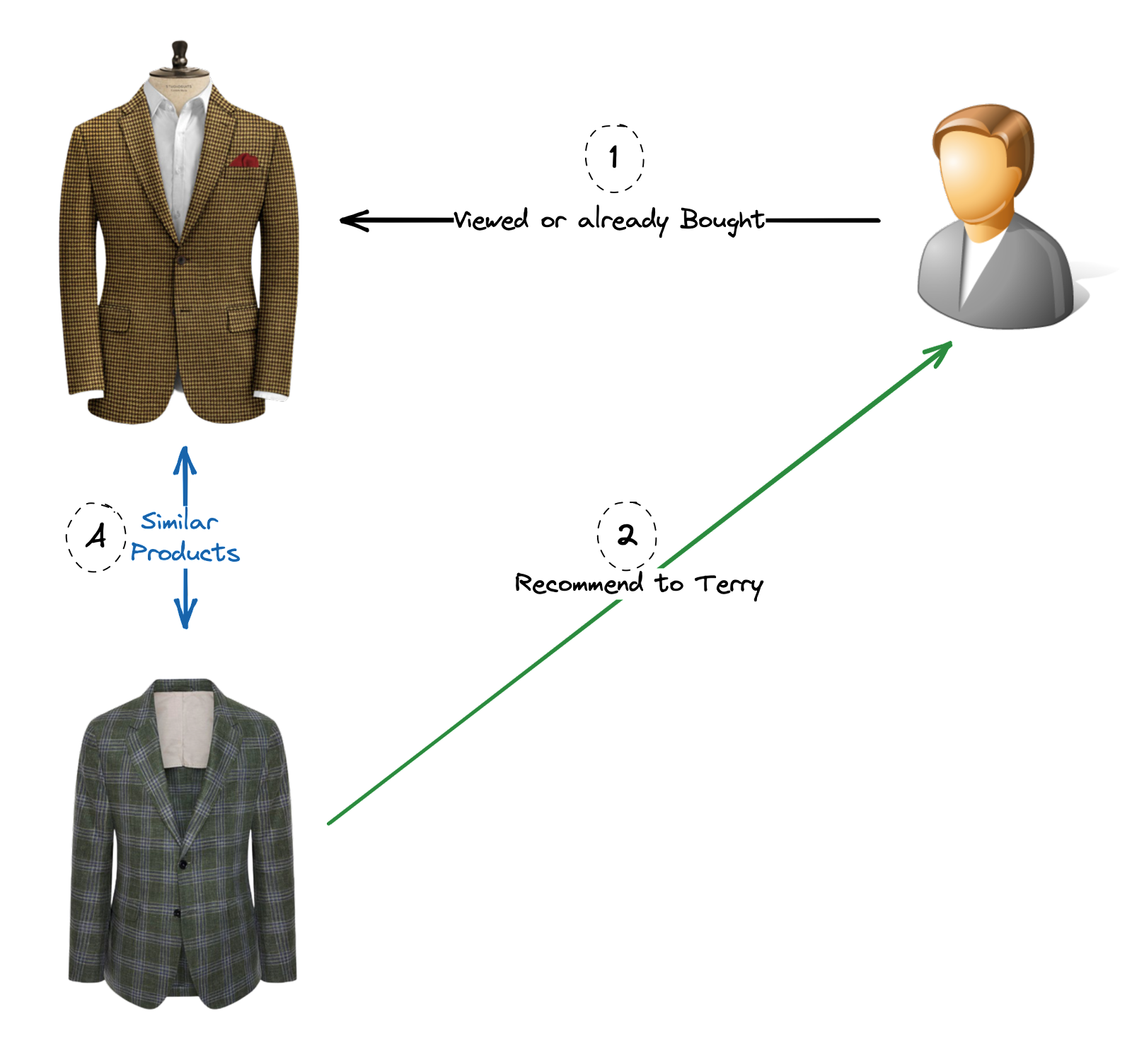
Filtrage basé sur le contenu
Filtrage collaboratif : Cette méthode recommande des articles basés sur les similarités et les modèles trouvés dans le comportement et les préférences de plusieurs utilisateurs. Elle identifie les utilisateurs ayant des goûts similaires et recommande des articles que ces utilisateurs ont aimés ou bien évalués. Le filtrage collaboratif peut être divisé en deux sous-types :
-
Filtrage collaboratif basé sur les utilisateurs : Il identifie les utilisateurs ayant des préférences similaires et recommande des articles appréciés par des utilisateurs aux goûts similaires (Scénarios A & B).
-
Filtrage collaboratif basé sur les articles : Il identifie les articles similaires basés sur le comportement des utilisateurs et recommande des articles similaires à ceux avec lesquels l’utilisateur a précédemment interagi (Scénario C).
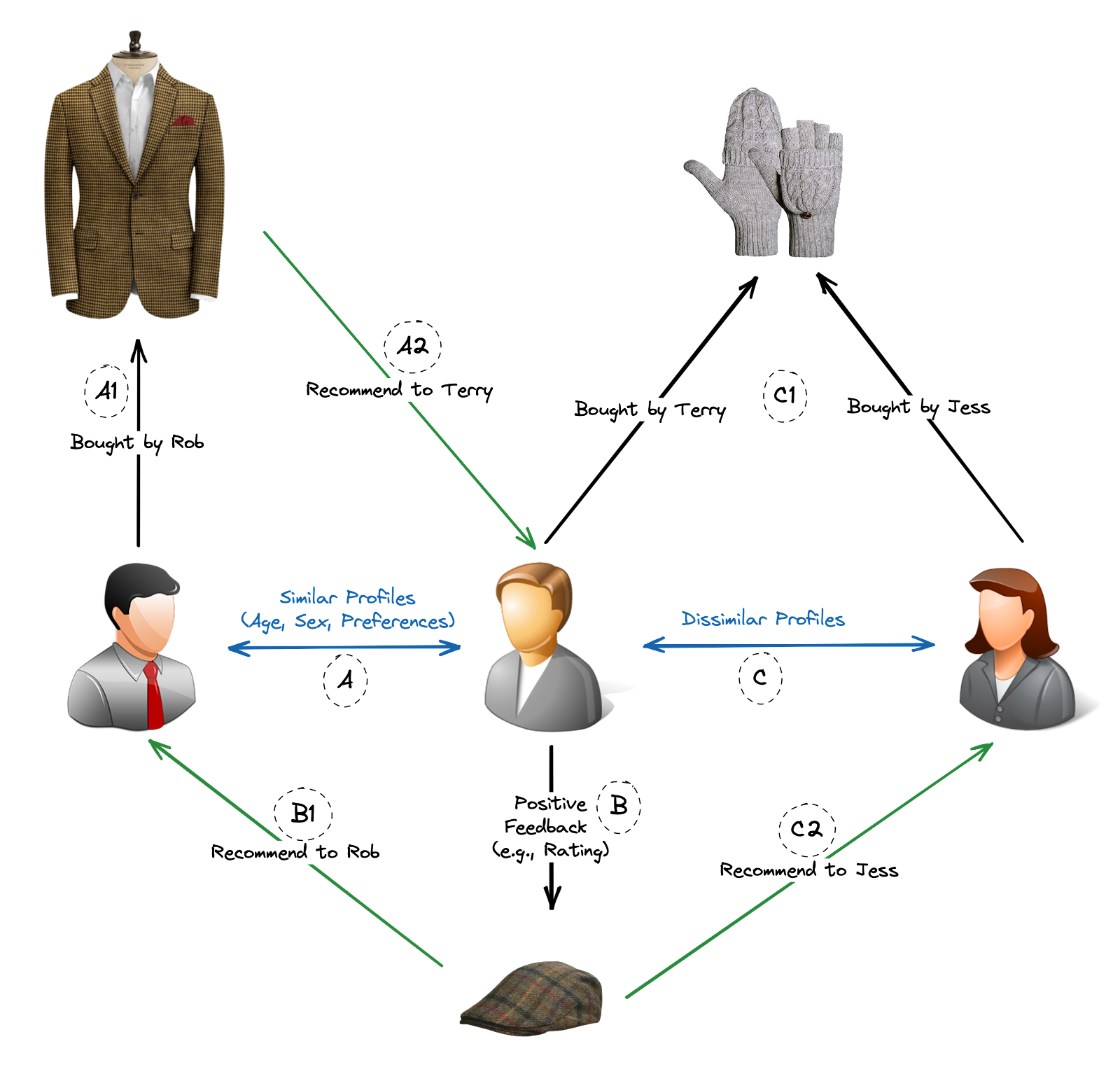
Filtrage collaboratif
Systèmes sensibles au contexte : Ces systèmes prennent en compte des informations contextuelles, comme l’heure, la localisation et le contexte de l’utilisateur, pour fournir des recommandations plus pertinentes. Par exemple, un service de streaming musical pourrait recommander des playlists d’entraînement énergiques le matin et de la musique relaxante le soir. De même, un site de e-commerce suggérera des articles spécifiques lors du Black Friday ou de Noël, différents de ce qu’il pourrait recommander à d’autres périodes de l’année.
Filtrage sensible au contexte
Systèmes de recommandation hybrides : Ces systèmes combinent plusieurs techniques de recommandation pour fournir des recommandations plus précises et diversifiées. Ils exploitent les points forts de différentes approches, comme le filtrage basé sur le contenu et le filtrage collaboratif, pour surmonter leurs limites et offrir des suggestions plus efficaces.
Moteurs de recommandation avec CockroachDB
Contrairement aux moteurs de recommandation hors ligne qui génèrent des recommandations personnalisées basées sur des données historiques, un moteur de recommandation idéal devrait prioriser l’efficacité des ressources, fournir des mises à jour en temps réel (en ligne) hautes performances, et offrir des choix précis et pertinents aux utilisateurs. Par exemple, il peut être inefficace de suggérer à un client un article qu’il a déjà acheté simplement parce que votre système de recommandation n’était pas au courant des dernières actions du client.
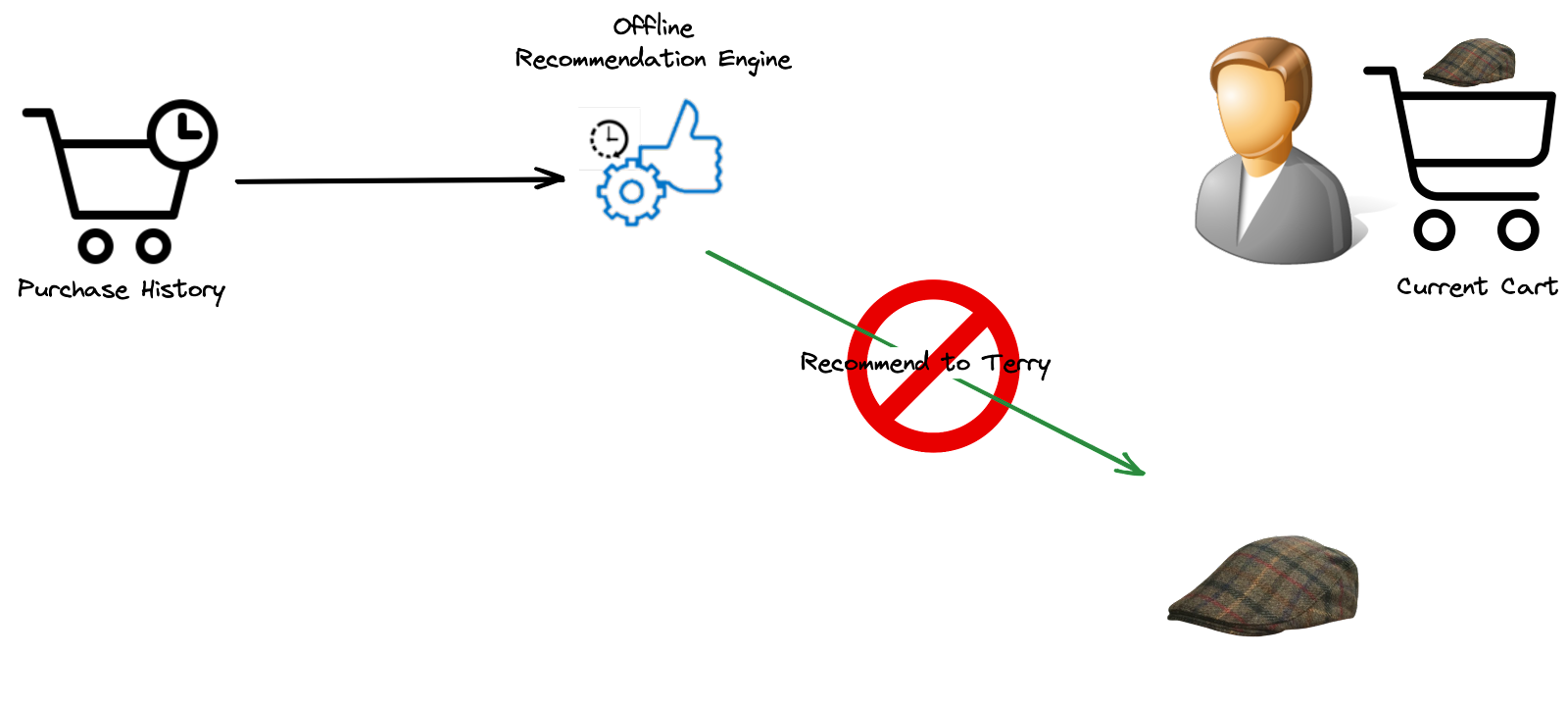
Systèmes de recommandation hors ligne
Les moteurs en ligne doivent réagir aux actions des clients pendant qu’ils naviguent encore sur votre site et recalculer les recommandations en conséquence. Cela donnerait aux clients la sensation d’avoir un assistant commercial dédié, rendant leurs expériences plus personnalisées.

Systèmes de recommandation en ligne
Pour cela, vous avez clairement besoin d’un backend cohérent à faible latence pour mettre en œuvre un tel système, avec deux capacités importantes.
- Premièrement, vous devez présenter les attributs et les préférences des utilisateurs d’une manière spécifique qui permet leur classification en groupes. Ensuite, vous avez besoin d’une représentation performante des produits qui permet le calcul de similarité et l’interrogation avec une très faible latence.
La mise en œuvre de tels systèmes avec la base de données SQL distribuée CockroachDB est une tâche simple. Étant donné la forte cohérence et le niveau d’isolation sérialisable fournis par défaut, CockroachDB expose toujours l’état le plus précis au moteur de recommandation, évitant toute donnée périmée pouvant résulter d’interactions entre des transactions concurrentes.
- Deuxièmement, vous considéreriez les préférences des utilisateurs, les attributs des produits et tout autre paramètre de filtrage comme des vecteurs. Ensuite, grâce aux capacités d’indexation vectorielle fournies par CockroachDB, vos moteurs de recommandation peuvent effectuer des calculs de distance (scores d’affinité) entre ces vecteurs et faire des recommandations basées sur ces scores.
Un vector embedding est une représentation mathématique de quelque chose (comme du texte ou des images) sous forme d’une liste de nombres, où la proximité des nombres signifie la proximité du sens. Ces embeddings sont mappés dans un espace multidimensionnel pour effectuer des calculs de proximité afin de comprendre la relation entre le sens des articles.
Descriptions de produits représentées sous forme de vecteurs
Les représentations vectorielles des données permettent aux algorithmes d’apprentissage automatique de traiter et d’analyser les informations efficacement. Ces algorithmes s’appuient souvent sur des opérations mathématiques effectuées sur des vecteurs, comme les produits scalaires, l’addition de vecteurs et la normalisation, pour calculer des similarités, des distances et des transformations.
Mais surtout, les représentations vectorielles facilitent la comparaison et le clustering des points de données dans un espace multidimensionnel. Les mesures de similarité, comme la similarité cosinus ou la distance euclidienne, peuvent être calculées entre des vecteurs pour déterminer la similarité ou la dissimilarité entre des points de données. Ainsi, votre moteur de recommandation peut tirer parti des vecteurs pour :
-
regrouper et classer les clients selon leurs préférences et attributs (âge, sexe, profession, localisation, revenus…), ce qui peut aider à trouver des similarités entre clients (Filtrage Collaboratif).
-
suggérer des produits similaires basés sur leurs images et descriptions textuelles (Filtrage basé sur le Contenu).

Moteur de recommandation en ligne avec CockroachDB
Dans la section suivante, vous apprendrez comment générer et stocker des embeddings d’images et de texte, implémenter une recherche de similarité en temps réel, et construire des requêtes de recommandation scalables à faible latence en utilisant l’architecture SQL distribuée de CockroachDB.
1 - Création des Vector Embeddings
Pour comprendre comment les vector embeddings sont créés, une brève introduction aux modèles modernes de Deep Learning est utile.
Il est essentiel de convertir les données non structurées en représentations numériques pour les rendre compréhensibles par les modèles d’apprentissage automatique. Autrefois, cette conversion était effectuée manuellement via l’ingénierie de features.
Le Deep Learning a introduit un changement de paradigme dans ce processus. Plutôt que de s’appuyer sur l’ingénierie manuelle, les modèles de Deep Learning, appelés transformers, apprennent de manière autonome les interactions complexes entre les features dans des données complexes. À mesure que les données traversent un transformer, il génère de nouvelles représentations des données d’entrée, chacune avec des formes et des tailles variables. Chaque couche du transformer se concentre sur différents aspects de l’entrée. Cette capacité du Deep Learning à générer automatiquement des représentations de features à partir des entrées constitue le fondement de la création des vector embeddings.
Modèle de réseau de neurones à deux tours - Source : Google Search
Les Vector Embeddings sont créés via un processus d’embedding qui mappe des données discrètes ou catégorielles en représentations vectorielles continues. Le processus de création d’embeddings dépend du contexte spécifique et du type de données. Voici quelques techniques courantes :
Embeddings de texte : utilisent des méthodes comme la Fréquence de Terme-Fréquence Inverse de Document (TF-IDF) pour calculer la fréquence des mots dans un corpus de texte et attribuer des poids à chaque mot en conséquence. Ils peuvent utiliser d’autres algorithmes populaires basés sur les réseaux de neurones comme Word2Vec ou GloVe pour apprendre des embeddings de mots en entraînant des réseaux de neurones sur de grands corpus de texte. Ces algorithmes capturent les relations sémantiques entre les mots basées sur leurs modèles de co-occurrence.
Embeddings d’images : utilisent des Réseaux de Neurones Convolutifs (CNN) comme VGG, ResNet ou Inception, couramment utilisés pour l’extraction de features d’images. Les activations des couches intermédiaires ou la sortie des couches entièrement connectées peuvent servir d’embeddings d’images.
Embeddings de données séquentielles : utilisent des Réseaux de Neurones Récurrents (RNN) : les RNN, comme la Mémoire à Long Court Terme (LSTM) ou l’Unité Récurrente à Porte (GRU), peuvent apprendre des embeddings pour des données séquentielles en capturant les dépendances et les modèles temporels. Ils peuvent également utiliser le modèle Transformer lui-même ou ses variantes comme BERT ou GPT, qui peuvent générer des embeddings contextualisés pour des données séquentielles.
Embeddings d’utilisateurs : L’activité d’un utilisateur sur une marketplace e-commerce ne se limite pas à la simple consultation d’articles. Les utilisateurs peuvent également effectuer des actions telles que faire une recherche, ajouter un article à leur panier, ajouter un article à leur liste de surveillance, etc. Ces actions fournissent des signaux précieux pour la génération de recommandations personnalisées. Vous pouvez utiliser un Réseau de Neurones Récurrent (RNN) ou des Unités Récurrentes à Porte (GRU) pour encoder les informations d’ordre des événements historiques. Pour créer des embeddings d’utilisateurs, vous pouvez tirer parti de l’approche des Réseaux de Neurones à Deux Tours comme celle implémentée par eBay : elle consiste en deux modèles de réseaux de neurones séparés, souvent appelés « tours », qui traitent différents types de données d’entrée en parallèle.
Les deux tours du réseau reçoivent généralement différents types d’informations liées aux interactions utilisateur-article. Par exemple, un tour pourrait traiter des données spécifiques à l’utilisateur, comme des informations démographiques ou des préférences passées, tandis que l’autre tour traite des données spécifiques à l’article, comme des descriptions de produits ou des attributs. Chaque tour apprend indépendamment des représentations ou des features à partir de ses données d’entrée respectives en utilisant plusieurs couches de neurones artificiels interconnectés. La sortie de la couche finale de chaque tour est ensuite combinée ou fusionnée pour générer une représentation conjointe qui capture la relation entre les utilisateurs et les articles. Par souci de simplicité, j’ometterai cette relation utilisateur-article dans le reste de l’article et me concentrerai uniquement sur les embeddings d’images et de texte.
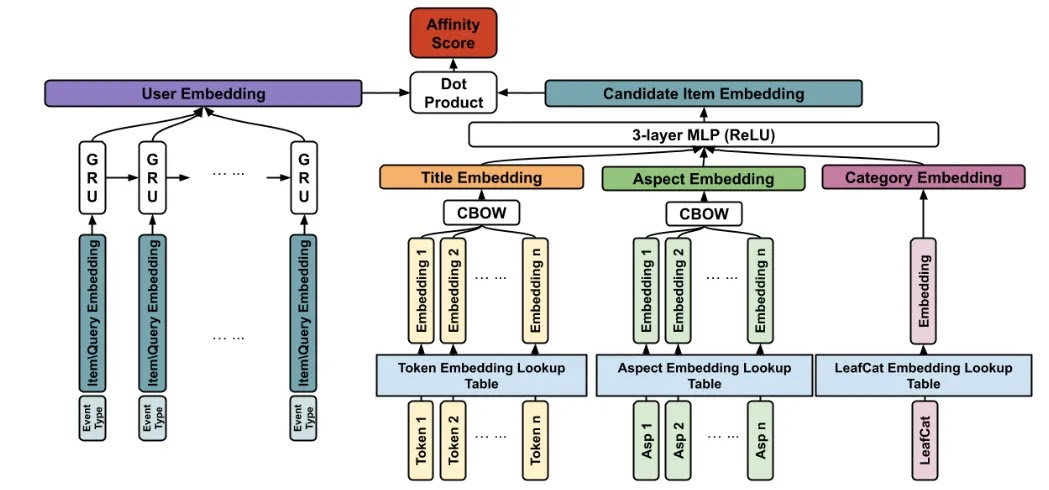
Exemple de l’architecture à deux tours
Dans notre implémentation, nous utiliserons une variante de BERT appelée all-mpnet-base-v2 pour créer des embeddings de données séquentielles pour les descriptions de produits. Pour générer des embeddings d’images de produits, nous utilisons le modèle Img2Vec (une implémentation de Resnet-18). Les deux modèles sont hébergés et exécutables en ligne, sans expertise ni installation requise. Mais d’abord, nous devons créer le schéma de la table avant d’y insérer des données :
CREATE TABLE products (product_id INT PRIMARY KEY, product_description STRING, category STRING NOT NULL, description_vector VECTOR(768), image_vector VECTOR(512));
Ensuite, stockons ces produits et leurs embeddings respectifs dans CockroachDB. Le script Python suivant génère et stocke des vector embeddings pour des produits, en utilisant à la fois des données d’images et de texte. Il utilise des bibliothèques pour le traitement d’images (PIL, img2vec_pytorch), les embeddings de texte (sentence_transformers) et la connexion à la base de données (psycopg2).
Pour les embeddings de texte, la fonction generate_text_vectors utilise un modèle basé sur BERT (all-mpnet-base-v2) pour créer des vector embeddings sémantiques à partir des descriptions de produits. La fonction generate_image_vectors télécharge les images des produits, les redimensionne et utilise un modèle ResNet-18 pour créer des embeddings d’images. La fonction vectorize_products appelle les fonctions précédentes et combine les vecteurs de texte et d’image pour chaque produit dans un dictionnaire. Ensuite, la fonction store_product_vectors stocke les vecteurs de produits dans la table products dans CockroachDB.
import os
import psycopg2
# data prep
import pandas as pd
import numpy as np
# for creating image vector embeddings
import urllib.request
from PIL import Image
from img2vec_pytorch import Img2Vec
# for creating semantic (text-based) vector embeddings
from sentence_transformers import SentenceTransformer
def generate_text_vectors(products):
text_vectors = {}
# Bert variant to create text embeddings
text_model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
# generate text vector
for index, row in products.iterrows():
text_vector = text_model.encode(row["description"])
text_vectors[index] = text_vector.astype(np.float32)
return text_vectors
def generate_image_vectors(products):
img_vectors={}
images=[]
converted=[]
# Resnet-18 to create image embeddings
image_model = Img2Vec()
# generate image vector
for index, row in products.iterrows():
tmp_file = str(index) + ".jpg"
urllib.request.urlretrieve(row["image_url"], tmp_file)
img = Image.open(tmp_file).convert('RGB')
img = img.resize((224, 224))
images.append(img)
converted.append(index)
vec_list = image_model.get_vec(images)
img_vectors = dict(zip(converted, vec_list))
return img_vectors
def load_product_catalog():
# initialize product
dataset = {
'id': [1253, 9976, 3626, 2746, 5735, 9982, 4322, 1978, 1736],
'description': ['Herringbone Brown Classic', 'Herringbone Wool Suit Navy Blue', 'Peaky Blinders Tweed Outfit', 'Cable Knitted Scarf and Bobble Hat', 'ADIDAS Men White Pluto Sports Shoes', 'ADIDAS Unisex White Shoes', 'Nike STAR RUNNER 4', 'Adidas SL 72 Unisex Shoes', 'Adidas Adizero F50 2 M Mens Running Jogging Shoes'],
'category': ['Suits', 'Suits', 'Suits', 'Hats', 'Shoes', 'Shoes', 'Shoes', 'Shoes', 'Shoes'],
'image_url': [
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/donegal-herringbone-tweed-men_s-jacket.jpeg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/Mens-Herringbone-Tweed-Check-3-Piece-Wool-Suit-Navy-Blue.webp',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/Marc-Darcy-Enzo-Mens-Herringbone-Tweed-Check-3-Piece-Suit.jpeg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/Mocara_MaxwellFlat_900x.jpg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/products/men/393e9315126350d97000721f330aa964.jpg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/products/men/6d62ba4de5c73b36d44f6bff05d2457e.jpg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/products/men/7185ef5d96833937481c19a47edac96a.jpg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/products/men/8cf52572340c3592e5f0ede116a0206f.jpg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/products/men/b3d19377041615d8a7cf46b96ef67c4c.jpg'
]
}
# Create DataFrame
products = pd.DataFrame(dataset).set_index('id')
return products
def vectorize_products(catalog):
products = []
img_vectors = generate_image_vectors(catalog)
text_vectors = generate_text_vectors(catalog)
for index, row in catalog.iterrows():
_id = index
text_vector = text_vectors[_id].tolist()
img_vector = img_vectors[_id].tolist()
vector_dict = {
"description_vector": text_vector,
"image_vector": img_vector,
"product_id": _id,
"category": row.category,
"product_description": row.description
}
products.append(vector_dict)
return products
def store_product_vectors(crdb_url, products):
with psycopg2.connect(crdb_url) as conn:
# Open a cursor to perform database operations
with conn.cursor() as cursor:
for product in products:
query = f'''INSERT INTO products (product_id, product_description, category, description_vector, image_vector) VALUES ({product["product_id"]}, '{product["product_description"]}', '{product["category"]}','{product["description_vector"]}', '{product["image_vector"]}')'''
cursor.execute(query)
print(f'''Inserted product: {product["product_id"]}, {product["product_description"]}''')
def create_crdb_url():
host = os.environ.get("CRDB_HOST", "localhost")
port = os.environ.get("CRDB_PORT", 26257)
db = os.environ.get("CRDB_DATABASE", "defaultdb")
username = os.environ.get("CRDB_USERNAME", "root")
url = f'''postgresql://{username}@{host}:{port}/{db}'''
return url
# Create a CockroachDB connection string
crdb_url = create_crdb_url()
# Load a few products
catalog = load_product_catalog()
# Create vector embeddings for products
products = vectorize_products(catalog)
# Store vectors in CockroachDB
store_product_vectors(crdb_url, products)
Le choix de la technique d’embedding dépend du type de données spécifique, de la tâche et des ressources disponibles. Le Huggingface Model Hub contient de nombreux modèles pouvant créer des embeddings pour différents types de données.
2 - Indexation vectorielle
Une fois que vous avez créé des vector embeddings pour vos produits, vous pouvez choisir de les stocker et de les interroger dans une base de données vectorielle comme Pinecone, Milvus, Weaviate ou Qdrant, chacune optimisée pour la recherche de similarité rapide. Bien que ces systèmes privilégient souvent la performance plutôt que la forte cohérence, CockroachDB offre une forte cohérence, un haut niveau d’isolation, une scalabilité horizontale et prend désormais en charge les types de données vectorielles et les requêtes de similarité approximative. Cela en fait une bonne option lorsque des sémantiques transactionnelles sont nécessaires aux côtés des opérations vectorielles.
De plus, le nouveau système d’indexation vectorielle C-SPANN de CockroachDB intègre des idées des publications SPANN et SPFresh de Microsoft Research, ainsi que du projet ScaNN de Google. Il a été conçu pour supporter une recherche sémantique rapide en temps réel à travers des milliards d’éléments (tels que des photos ou des documents) dans un environnement hautement distribué et transactionnel.
Contrairement aux solutions traditionnelles qui s’appuient sur des ensembles de données en mémoire ou des écritures par lots, C-SPANN est conçu pour fonctionner à travers des régions avec une forte cohérence, une faible latence et une scalabilité linéaire. Il prend en charge la possibilité de rechercher immédiatement les nouvelles données, évite la coordination centrale et s’intègre naturellement dans le modèle de stockage clé-valeur distribué de CockroachDB.
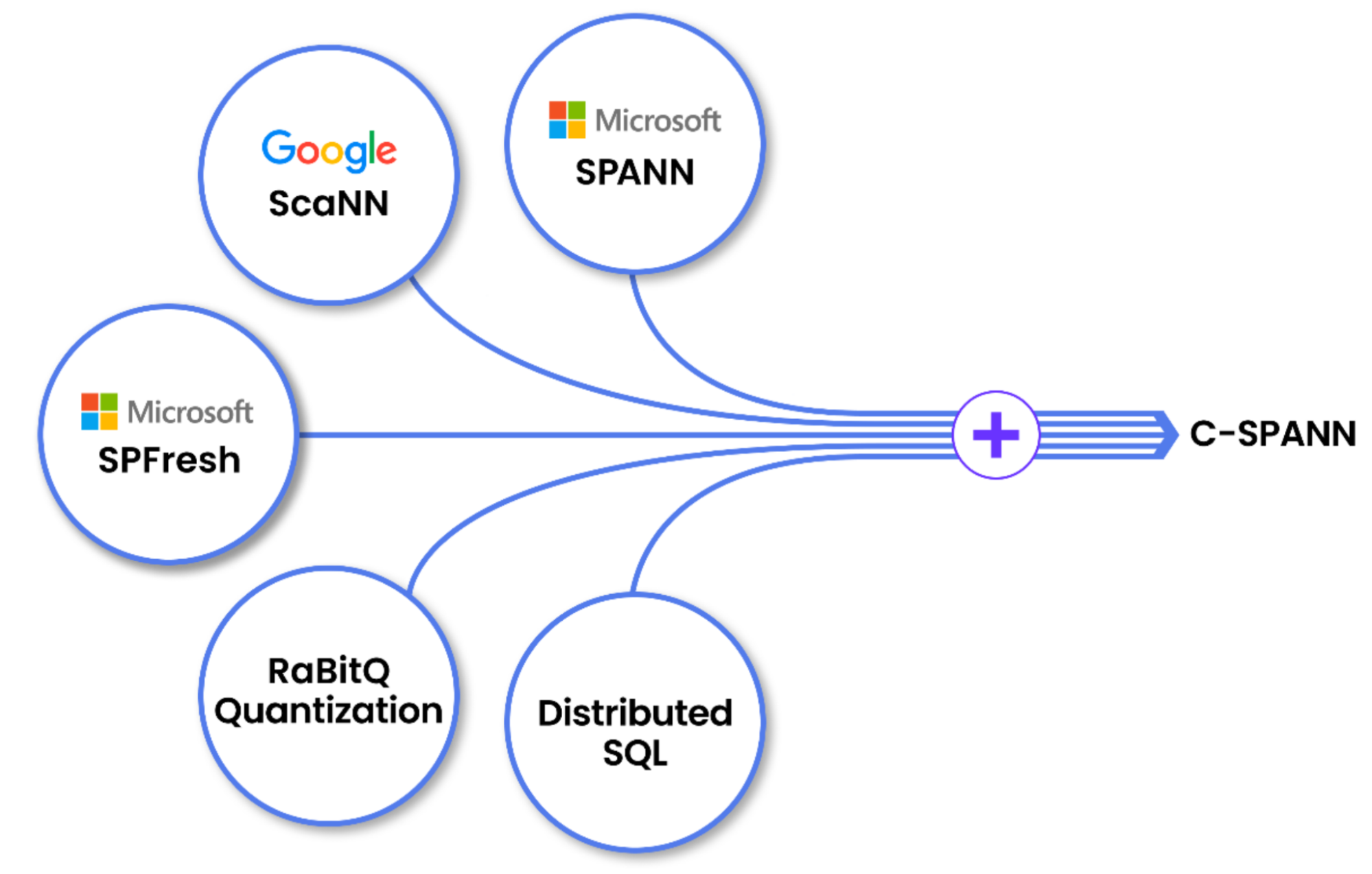
C-SPANN
Pour maintenir des coûts de stockage et de calcul bas, C-SPANN intègre RaBitQ, une technique de quantification qui réduit la taille des vecteurs d’environ 94 %. Les vecteurs quantifiés sont scannés rapidement à l’aide d’instructions optimisées pour SIMD, et une étape de rerankage assure une haute précision en revérifiant les meilleurs candidats par rapport aux vecteurs originaux en précision complète. Le système supporte également l’indexation par utilisateur et multi-région via des colonnes de préfixe, permettant un isolement fin et une localité des données. Cela garantit des expériences de recherche scalables, sécurisées et à faible latence quel que soit le nombre d’utilisateurs ou de régions impliquées.
CockroachDB utilise une métrique de distance pour mesurer la similarité entre deux vecteurs (c’est-à-dire à quel point deux vecteurs sont « proches » ou « éloignés »). Actuellement, seuls les opérateurs <-> Distance Euclidienne (L2), <#> Produit Interne (IP) et <=> Similarité Cosinus sont disponibles dans CockroachDB.
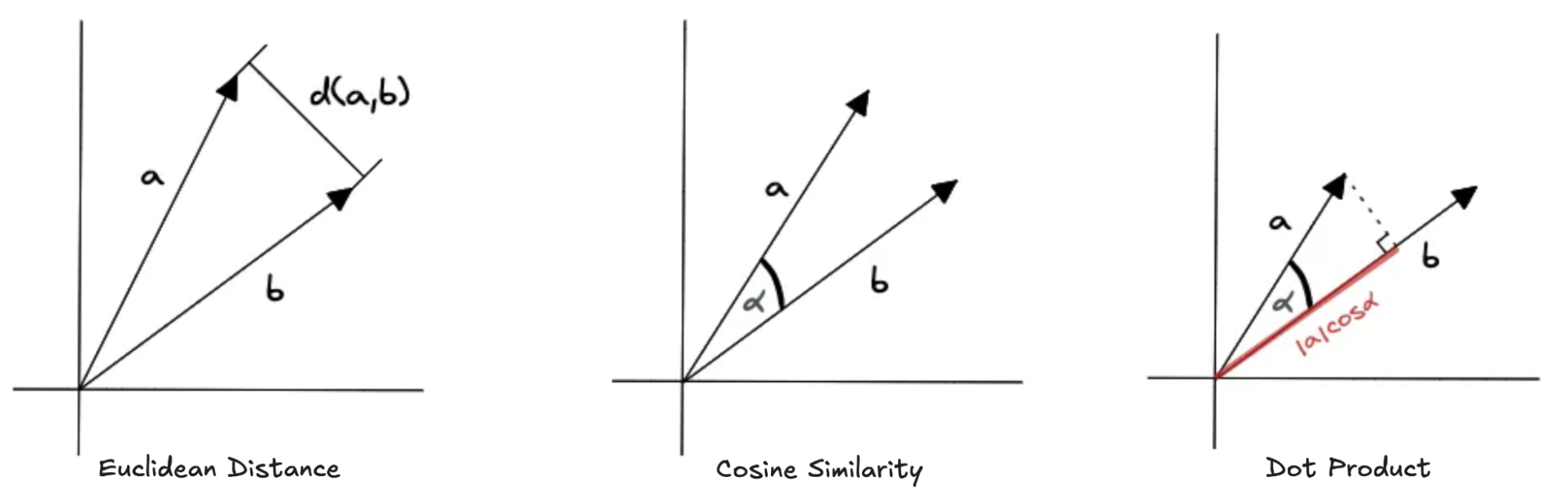
Métriques de distance
Nous avons décrit comment C-SPANN peut regrouper efficacement de grands volumes de vecteurs tout en maintenant l’index à jour grâce à des mises à jour incrémentales en temps réel. Cependant, il existe une nuance importante dans les applications pratiques : les vecteurs appartiennent généralement à des entités distinctes, telles que des utilisateurs, des clients ou une catégorie de produits, et la plupart des requêtes sont destinées à opérer dans le périmètre d’une seule entité. Inclure des vecteurs de propriétaires non pertinents diluera la pertinence dans la recherche vectorielle.
CockroachDB répond à cela élégamment en supportant les colonnes de préfixe dans les index vectoriels. Cette fonctionnalité permet à l’index d’être logiquement partitionné par propriété, ou tout autre critère, assurant à la fois l’isolement et l’efficacité des requêtes. Voici un exemple de création d’un index vectoriel d’images dans CockroachDB basé sur la table products créée précédemment.
CREATE VECTOR INDEX ON products (category, image_vector);
Si vous créez des index vectoriels pour la première fois dans votre cluster, vous devrez définir le paramètre feature.vector_index.enabled :
SET CLUSTER SETTING feature.vector_index.enabled = true;
Après le chargement des vecteurs de produits dans CockroachDB et la création des index vectoriels, le moteur de recommandation peut exécuter toutes sortes de requêtes de recherche par similarité.
3 - Recherche par similarité vectorielle
Au cœur de l’indexation vectorielle de CockroachDB se trouve un arbre K-means hiérarchique qui organise les vecteurs en partitions basées sur leur similarité. Ces partitions sont stockées dans l’architecture basée sur les plages de CockroachDB, permettant une division, une fusion et un équilibrage de charge automatiques. Pour maintenir la précision de l’index au fil du temps, C-SPANN prend en charge les divisions, fusions et réaffectations de partitions en arrière-plan, garantissant que les vecteurs sont toujours situés dans leur cluster le plus pertinent. Cette conception élimine le besoin de reconstructions complètes et coûteuses de l’index, même après des millions de mises à jour incrémentales.
Ce système d’indexation débloque des capacités de recherche avancées comme la recherche des « K » vecteurs les plus similaires, effectuant des recherches à faible latence dans de grands espaces vectoriels allant de dizaines de milliers à des centaines de millions de vecteurs distribués sur plusieurs machines.
Par conséquent, CockroachDB expose la fonctionnalité de recherche habituelle, combinant les pré-filtres de texte intégral, numériques et géographiques avec la recherche de voisins les plus proches (KNN) vectorielle : avec CockroachDB, vous pouvez interroger des produits stockés sous forme de vecteurs tout en pré-filtrant par localisation, prix et description, et choisir les métriques de distance vectorielle pertinentes pour calculer à quel point deux produits sont « similaires » ou « dissimilaires ».
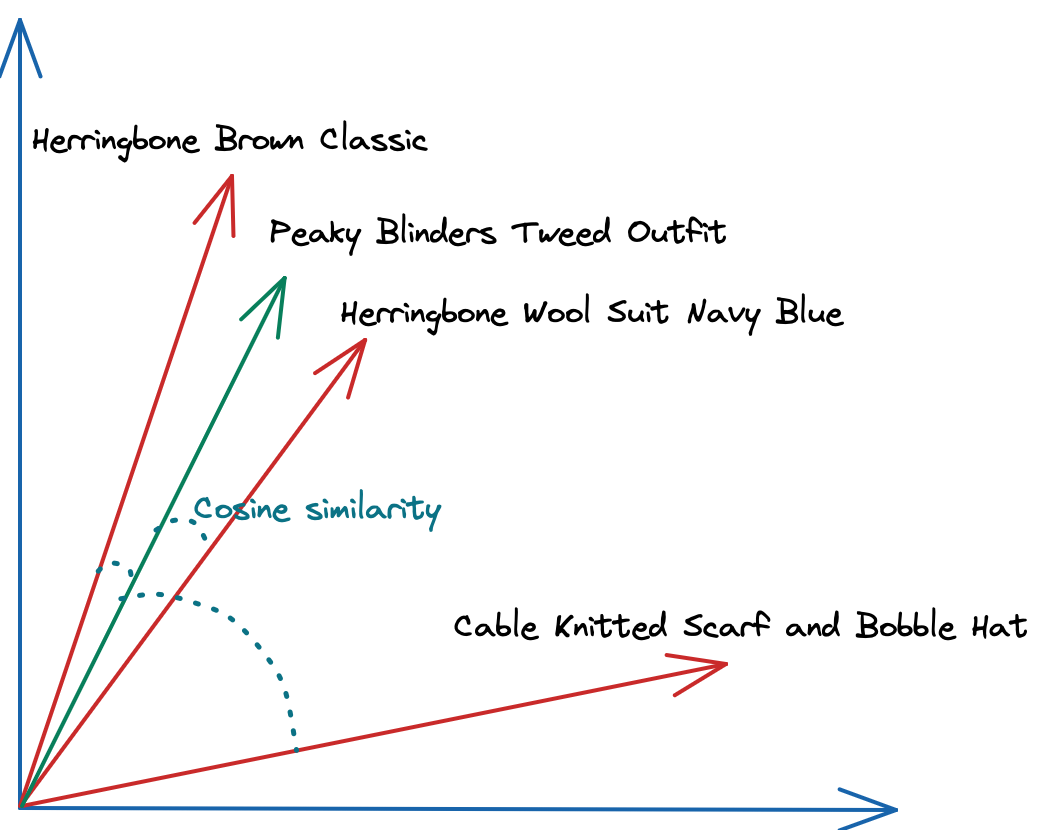
Calcul de la similarité cosinus entre des descriptions de produits
La requête ci-dessous retourne les 10 produits similaires, dont les vecteurs sont stockés dans le champ image_vector, à un vecteur d’image de requête. Vous pouvez également définir un pré-filtre sur sa catégorie, sa fourchette de prix ou son lieu de vente.
SELECT product_id, product_description FROM products WHERE category = $1 ORDER BY (image_vector <-> $2) LIMIT 10;
Par exemple, si vous recherchez un produit avec les emplacements de magasins associés et des images de produits (encodées sous forme de vecteurs) dans une seule table, vous pouvez créer un index secondaire sur la colonne d’emplacement du magasin pour pré-filtrer les données avant d’effectuer une recherche vectorielle.
Cela signifie qu’au lieu de scanner l’ensemble du jeu de données, le système réduit d’abord la recherche aux emplacements pertinents, comme « Casablanca », puis applique la recherche par similarité vectorielle uniquement dans ce sous-ensemble. Une telle approche de recherche hybride améliore considérablement les performances des requêtes et l’efficacité des ressources, facilitant la construction d’applications IA intelligentes et hautes performances à grande échelle en utilisant la syntaxe SQL familière.
Voici un exemple de création d’une requête qui retourne les trois produits les plus similaires (par image) à celui affiché ci-dessous, triés par score de pertinence (distance euclidienne définie dans les index créés précédemment).
def create_query_vector():
query_image_url = "https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/products/2eca615a43d0098f4bb5fc90004c3678.jpg"
# Resnet-18 to create image embeddings
image_model = Img2Vec()
# generate image vector
tmp_file = "query_image.jpg"
urllib.request.urlretrieve(query_image_url, tmp_file)
img = Image.open(tmp_file).convert('RGB')
img = img.resize((224, 224))
vector = image_model.get_vec(img)
query_vector = np.array(vector, dtype=np.float32).tolist()
return query_vector
def fetch_similar_products(crdb_url, category, query_vector, limit=5):
with psycopg2.connect(crdb_url) as conn:
# Open a cursor to perform database operations
with conn.cursor() as cursor:
query = f'''SELECT product_id, product_description
FROM products
WHERE category = '{category}'
ORDER BY image_vector <-> '{query_vector}'
LIMIT {limit}'''
cursor.execute(query)
results = cursor.fetchall()
print("The most similar product are: ")
for row in results:
print(f"The Product ID: {row[0]}, Description: {row[1]}")
query_vector = create_query_vector()
fetch_similar_products(crdb_url, "Shoes", query_vector, limit=3)
Même si l’index contient des milliards de produits, cette requête ne cherchera que dans le sous-ensemble associé à une catégorie de produits spécifique. Les performances d’insertion et de recherche sont proportionnelles au nombre de vecteurs étiquetés dans cette catégorie, pas au volume total de vecteurs dans le système. Cet isolement réduit la contention entre les produits, car les requêtes opèrent sur des partitions d’index et des lignes séparées.
En coulisses, l’index maintient un arbre K-means indépendant pour chaque catégorie. Du point de vue du système, il y a peu de différence entre la gestion d’un milliard de vecteurs dans un seul arbre ou leur distribution à travers un million d’arbres plus petits. Dans les deux cas, les vecteurs sont assignés à des partitions et stockés dans des plages de la couche clé-valeur de CockroachDB. Ces plages sont automatiquement divisées, fusionnées et distribuées à travers les nœuds, permettant une scalabilité quasi-linéaire à mesure que l’utilisation croît.
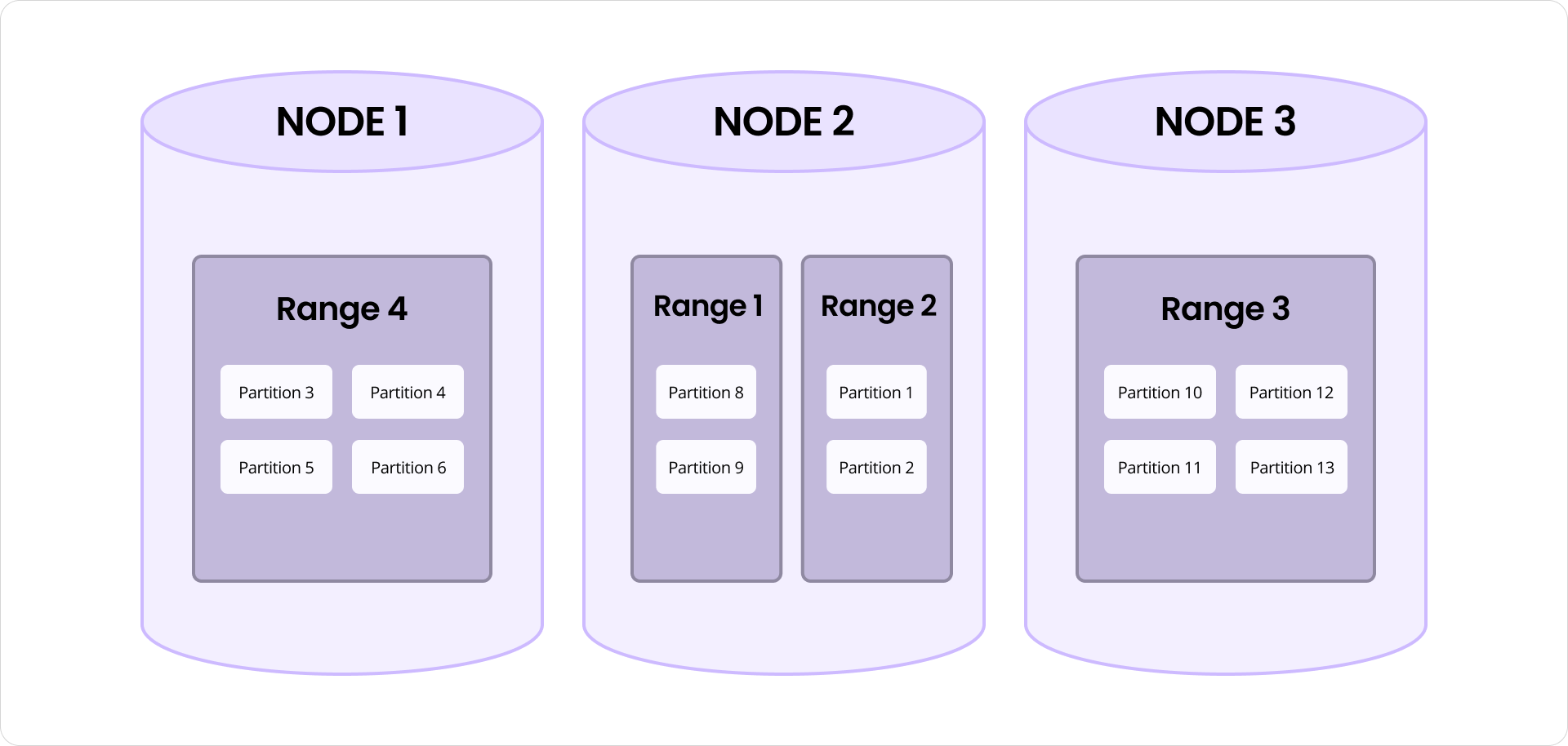
Indexation vectorielle partitionnée
Les instructions ci-dessus constituent un bref aperçu pour démontrer les éléments constitutifs d’un moteur de recommandation en ligne avec CockroachDB. Vous pouvez essayer cela avec le notebook référencé ici (installez Google Colab pour l’ouvrir).
Un moteur de recommandation IA haute performance
CockroachDB offre diverses capacités qui peuvent réduire considérablement la complexité des applications tout en offrant des performances constamment élevées, même à grande échelle.
Avec les capacités vectorielles, CockroachDB a débloqué plusieurs applications IA impactantes basées sur le calcul de similarité et de distance en quasi temps réel avec une haute précision. Les moteurs de recommandation sont un exemple de telles applications.
Si vous souhaitez fournir des recommandations interactives basées sur le contenu, vous voudrez peut-être tirer parti de CockroachDB comme base de données vectorielle et moteur de recherche par similarité. Quelle que soit la complexité que vous souhaitez pour votre moteur de recommandation (collaboratif, basé sur le contenu, contextuel ou même hybride), CockroachDB vous aide à fournir les meilleures recommandations pour une expérience utilisateur réussie.
Ressources
- Documentation de la recherche vectorielle CockroachDB
- C-SPANN : Indexation en temps réel pour des milliards de vecteurs
- Article original : Moteurs de recommandation en ligne avec CockroachDB
- Filtrage collaboratif item-à-item d’Amazon
- Notebook Google Colab
- Sentence Transformers: all-mpnet-base-v2
- Img2Vec : Embeddings d’images avec PyTorch
- SPANN : Recherche ANN à l’échelle du milliard hautement efficace (Microsoft Research)
- SPFresh : Mise à jour incrémentale en place pour la recherche vectorielle à l’échelle du milliard
- ScaNN : Recherche vectorielle efficace par similarité (Google Research)
- La recherche vectorielle rencontre le SQL distribué