
Jusqu’à cette étape, les données ont principalement été déplacées d’un endroit à un autre ou stockées. Dans cet article, vous apprendrez comment les rendre utiles. Le traitement des données consiste à transformer les données brutes en insights précieux grâce à des techniques d’analyse comme les algorithmes de machine learning ou les modèles statistiques selon le type de problème à résoudre dans le contexte d’une organisation.
Le traitement des données est au cœur de toute architecture de données, et nous avons vu dans les derniers articles que le choix de la bonne architecture de données doit être une priorité absolue pour de nombreuses organisations. L’objectif ici est non seulement l’exactitude, mais aussi l’efficacité, car cette étape nécessite une puissance de calcul significative qui pourrait devenir coûteuse au fil du temps sans stratégies d’optimisation appropriées.
Dans cet article, nous aborderons le traitement des données avec les différentes étapes qui le composent. Nous verrons qu’au fur et à mesure que les données progressent dans ces étapes, elles gagnent en valeur et peuvent offrir de meilleurs insights pour la prise de décision.
1 - Préparation des données
Une fois les données collectées, elles entrent dans l’étape de préparation des données. La préparation des données, souvent appelée « pré-traitement », est l’étape à laquelle les données brutes sont nettoyées et organisées pour les étapes suivantes du traitement des données. Pendant la préparation, les données brutes sont soigneusement vérifiées pour détecter les erreurs. Cette étape vise à découvrir et éliminer les mauvaises données (données redondantes, incomplètes ou incorrectes) et à créer des données de haute qualité pour une meilleure prise de décision data-driven.
76 % des data scientists disent que la préparation des données est la pire partie de leur travail, mais une tâche obligatoire à effectuer soigneusement. En effet, des décisions métier efficaces et précises ne peuvent être prises qu’avec des données propres.
La préparation des données aide à détecter les erreurs et à déclencher des alertes sur la qualité des données avant le traitement. Une fois les données déplacées de leur source d’origine, ces erreurs deviennent plus difficiles à comprendre et à corriger. La préparation des données permet également de produire des données de première qualité. En conséquence, les données de première qualité peuvent être traitées et analysées plus rapidement et efficacement, conduisant à des décisions métier précises.
Découverte des données
Le processus de préparation des données commence par la recherche des bonnes données. Qu’elles soient ajoutées ad hoc ou proviennent d’un catalogue de données existant, les données doivent être rassemblées, leurs attributs découverts et partagés dans un catalogue de données. La première étape de la préparation des données est donc la découverte des données (ou catalogage des données).
Selon Gartner, Augmented Data Catalogs 2019 : « Un catalogue de données crée et maintient un inventaire des actifs de données grâce à la découverte, la description et l’organisation des ensembles de données distribués. Le catalogue de données fournit un contexte pour permettre aux gestionnaires de données, aux analystes de données/métier, aux ingénieurs de données, aux data scientists et aux autres consommateurs de données de trouver et de comprendre les ensembles de données pertinents pour extraire de la valeur métier. Les catalogues de données augmentés par machine learning modernes automatisent diverses tâches fastidieuses impliquées dans le catalogage des données, notamment la découverte de métadonnées, l’ingestion, la traduction, l’enrichissement et la création de relations sémantiques entre les métadonnées. »
Les données sont un actif précieux, mais leur plein potentiel ne peut être libéré que lorsque les utilisateurs sont capables de les comprendre et de les transformer en informations significatives. À l’ère du big data, les organisations ne peuvent pas se permettre de laisser leurs utilisateurs métier dépendre des professionnels IT ou des analystes de données pour comprendre de grands volumes de données générées. Le catalogue de données sert de source unique d’informations fiables qui donne aux utilisateurs un aperçu de tous les actifs organisationnels disponibles.
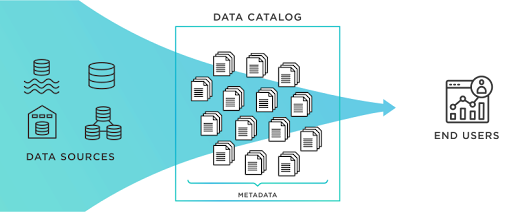 Catalogue de données.
Catalogue de données.
Nettoyage des données
En informatique, l’expression « Garbage In, Garbage Out » (ordures en entrée, ordures en sortie) indique que la qualité d’un résultat dépend de ses entrées. Malgré ce concept simple mais évident largement accepté, de nombreuses équipes de données modernes éprouvent encore des difficultés avec la qualité de leurs données sources, entraînant des défaillances dans les pipelines. De plus, les problèmes de qualité des données causent de la frustration chez les consommateurs de données.
Le nettoyage des données (également appelé épuration ou scrubbing des données) est un composant critique du processus de préparation, car il élimine les informations défectueuses et comble les lacunes. Cela comprend l’élimination des détails inutiles, la suppression des doublons et des données corrompues/mal formatées, la correction des valeurs aberrantes, le remplissage des champs vides avec des valeurs appropriées et le masquage des entrées confidentielles.
Pour établir un processus de nettoyage des données réussi, votre organisation doit commencer par définir les techniques utilisées pour chaque type de données. Voici les étapes (non exhaustives) à suivre :
- Supprimer les observations en double ou non pertinentes : pour supprimer les observations indésirables d’un jeu de données, il faut d’abord identifier et éliminer toute observation en double ou non pertinente. Cela peut être fait en examinant les données pour détecter des similitudes entre les enregistrements pouvant indiquer une duplication et en filtrant les observations qui ne s’inscrivent pas dans le problème spécifique analysé.
- Corriger les erreurs structurelles : les erreurs structurelles se produisent lorsque les données sont mesurées ou transférées et que des conventions de nommage étranges, des fautes de frappe ou des majuscules incorrectes sont remarquées. Ces incohérences peuvent conduire à des catégories ou des classes mal étiquetées.
- Filtrer les valeurs aberrantes indésirables : parfois, une seule observation peut se démarquer du reste des données et ne pas sembler correspondre à ce qui est analysé. Si une raison acceptable justifie son élimination, cela peut améliorer la précision de vos résultats.
- Gérer les données manquantes : les données manquantes ne peuvent pas être ignorées, car de nombreux algorithmes ne les accepteront pas. Pour y remédier, il existe quelques solutions potentielles, mais aucune n’est parfaite. Une option est de supprimer les observations contenant des valeurs manquantes, mais cela peut conduire à une perte d’information. Une autre approche consiste à combler les lacunes avec des hypothèses basées sur d’autres entrées.
- Les contrats de données peuvent également offrir une réponse pratique pour nettoyer et aligner les données selon des accords spécifiques bien avant qu’elles ne soient consommées.
Dans le tableau ci-dessous, vous trouverez les problèmes de qualité des données les plus fréquents, avec quelques exemples et comment les traiter.
| Problème de qualité | Description | Exemples | Solutions |
|---|---|---|---|
| Données manquantes | Raison des valeurs manquantes : 1. Information non collectée à la source, 2. Attribut non applicable à tous les cas. |
Champs vides. | Les solutions dépendent de la quantité de données manquantes, des attributs concernés et de la catégorie de données manquantes : - Supprimer les observations avec des données manquantes (supprimer les lignes) ; - Remplir les données manquantes (mode pour les données catégorielles, moyenne ou médiane pour les valeurs numériques) ; - Ignorer l’attribut avec des données manquantes (supprimer les colonnes). |
| Valeurs aberrantes | Objets de données ayant des caractéristiques considérablement différentes de la plupart des autres objets du jeu de données. | Avoir des millions alors que la plupart des valeurs sont inférieures à 10. | Les solutions dépendent de la nature de la valeur aberrante : - Une erreur de mesure ou de saisie de données. Corriger l’erreur si possible. Si vous ne pouvez pas la corriger, supprimer l’observation ; - Ne faisant pas partie de la population étudiée, vous pouvez légitimement supprimer la valeur aberrante ; - Une partie naturelle de la population étudiée, vous ne devez pas la supprimer. |
| Bruit | Désigne la modification des valeurs originales avec des informations supplémentaires sans signification. | Plusieurs lignes remplies par des valeurs par défaut. | Supprimer le bruit. |
| Données contaminées | Toutes les données existent mais dans le mauvais champ ou sont inexactes. | Numéro de téléphone dans le champ Nom. | Contrats de données (enforcement du schema). |
| Données incohérentes | Discordances dans la même information à travers le jeu de données. | - Même personne avec plusieurs orthographes du nom ; - Discordances dans l’unité de mesure (Euros et Dollars dans le même champ). |
Contrats de données (enforcement de la sémantique). |
| Données invalides | Les données existent mais sont hors contexte. | Unités d’inventaire disponibles affichant une valeur négative. | Contrats de données (enforcement de la sémantique). |
| Données dupliquées | Raison des doublons : fusion de données de sources hétérogènes. | La même personne présente dans plusieurs lignes. | Supprimer les doublons. |
| Problèmes de type | Les données existent mais avec le mauvais type de données. | Dates ou nombres dans des champs de type chaîne. | Contrats de données (enforcement du schema). |
| Problèmes structurels | La structure des données n’est pas celle attendue. | - 10 champs attendus mais seulement 3 reçus ; - Un ordre de structure spécifique attendu mais un ordre différent reçu. |
Contrats de données (enforcement du schema). |
À la fin du processus de nettoyage des données, vous devriez être en mesure de répondre à ces questions dans le cadre d’une validation de base :
- Les données ont-elles du sens ?
- Les données respectent-elles les règles appropriées pour leur champ ?
- Prouvent-elles ou réfutent-elles votre théorie de travail, ou apportent-elles un insight à la lumière ?
- Pouvez-vous trouver des tendances dans les données pour vous aider à formuler votre prochaine théorie ?
- Si non, est-ce dû à un problème de qualité des données ?
De fausses conclusions dues à des données incorrectes ou « sales » peuvent conduire à une mauvaise stratégie métier et à une mauvaise prise de décision. Avant d’en arriver là, il est important de créer une culture de la qualité des données dans votre organisation.
Une fois préparées, les données peuvent être stockées ou transférées vers une zone de stockage de confiance (dans un stockage multi-niveaux), ouvrant la voie au traitement et à l’analyse.
Contrat de données et SLA
Les contrats de données sont des accords pilotés par les SLA entre tous les acteurs de la chaîne de valeur des données. Ils peuvent impliquer les producteurs de données qui possèdent les données et les ingénieurs de données qui mettent en œuvre les pipelines de données. Ils peuvent impliquer les ingénieurs de données et les data scientists qui nécessitent un format spécifique avec un nombre spécifique de caractéristiques, ou simplement entre les consommateurs de données qui comprennent comment fonctionne l’activité et les acteurs en amont impliqués dans le parcours de données. L’objectif de ces contrats est de générer des données bien modélisées, de haute qualité, fiables et en temps réel.
Au lieu que les équipes de données acceptent passivement des dumps de données provenant de systèmes de production qui n’ont jamais été conçus pour l’analytique ou le machine learning, les consommateurs de données peuvent concevoir des contrats qui reflètent la nature sémantique du monde composé d’entités, d’événements, d’attributs et des relations entre chaque objet de données.
Les contrats de données sont un changement culturel vers la collaboration centrée sur les données, et leur mise en œuvre doit répondre à des exigences de base spécifiques pour être efficace. Celles-ci incluent l’enforcement des contrats au niveau du producteur, les rendre publics avec un versioning pour la gestion des changements, couvrir à la fois les schémas et la sémantique (y compris les descriptions, les contraintes de valeur, etc.).
Les contrats de données doivent contenir le schéma des données produites et ses différentes versions. Ainsi, les consommateurs doivent être capables de détecter et de réagir aux changements de schema et de traiter les données avec l’ancien schema. Le contrat doit également contenir la sémantique : par exemple, quelle entité un point de données donné représente.
De plus, les contrats de données doivent contenir les métadonnées de niveau d’accord (SLA) : est-il destiné à une utilisation en production ? Avec quel retard les données peuvent-elles arriver ? Combien de valeurs manquantes peuvent être attendues pour des champs spécifiques dans une période donnée ?…

Les schémas, la sémantique, le SLA et d’autres métadonnées (par ex., celles utilisées pour la lignée des données) sont enregistrés par les sources de données dans un registre central de contrats de données. Une fois les données reçues par un moteur de traitement d’événements, il les valide par rapport aux paramètres définis dans le contrat de données.
Les données qui ne respectent pas les exigences du contrat sont envoyées vers une file de lettres mortes (Dead Letter Queue) pour alerte et récupération : les consommateurs et les producteurs sont tous deux alertés pour tout non-respect du SLA, et les données invalidées peuvent être retraitées avec une logique de récupération. Les données qui respectent le contrat sont transmises à la couche de service.
2 - Formatage des données
Les données nettoyées sont ensuite saisies dans leur destination (peut-être un CRM comme Salesforce ou un data warehouse comme Redshift) et doivent être formatées dans un format qu’il peut comprendre et qui est efficace à traiter. Le formatage des données est la première étape à laquelle les données nettoyées prennent la forme d’informations utilisables.
Dans le traitement des données, il existe divers formats de fichiers pour stocker les jeux de données. Chaque format a ses propres avantages et inconvénients selon les cas d’usage pour lesquels il est prévu. Par exemple, les fichiers CSV sont faciles à comprendre mais manquent de formalisme ; JSON est préféré dans la communication web tandis que XML peut également être utilisé ; AVRO et Protocol Buffers fonctionnent bien avec le traitement en streaming ; ORC et Parquet offrent de meilleures performances dans les tâches analytiques grâce aux capacités de stockage en colonnes.
Considérations de formatage
De nombreuses considérations doivent être prises en compte pour choisir un format de données et la technologie sous-jacente pour son stockage (format de fichier). Les principales caractéristiques retenues pour la comparaison sont :
- Encodage : alors que les fichiers binaires et texte contiennent tous deux des données stockées sous forme de bits, les bits dans les fichiers texte représentent des caractères (code ASCII), tandis que les bits dans les fichiers binaires représentent des données personnalisées. Les encodages textuels sont avantageux car ils peuvent être lus et modifiés par l’utilisateur final avec un éditeur de texte. D’autre part, les encodages binaires nécessitent des outils ou bibliothèques spécialisés, mais leur sérialisation des données est optimisée pour de meilleures performances lors du traitement.
- Type de données : certains formats ne permettent pas la déclaration de plusieurs types de données. Ces types sont divisés en deux catégories : scalaire et complexe. Les valeurs scalaires contiennent une seule valeur, telle que des entiers, des booléens, des chaînes ou des nulls, tandis que les valeurs complexes consistent en des combinaisons de scalaires (par ex., des tableaux et des objets).
- Enforcement du schema : le schema stocke la définition de chaque attribut et ses types. À moins que vos données ne soient immuables, vous devrez considérer l’évolution du schema pour déterminer si la structure de vos données change au fil du temps.
- Stockage en lignes vs. en colonnes : dans le stockage en lignes, les données sont organisées et stockées en lignes. Cette architecture facilite l’ajout rapide de nouveaux enregistrements et l’accès simultané à une ligne entière de données. Elle est couramment utilisée pour les systèmes OLTP. Inversement, le stockage en colonnes est le plus utile lors de l’exécution de requêtes analytiques nécessitant seulement un sous-ensemble de colonnes examinées sur de grands ensembles de données (OLAP).
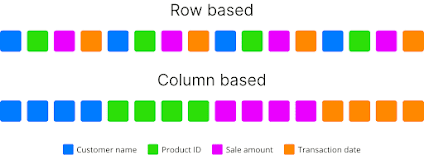 Regroupement des enregistrements par propriétés.
Regroupement des enregistrements par propriétés.
- Divisible (Splittable) : dans un système distribué comme Hadoop HDFS, il est essentiel d’avoir un fichier pouvant être décomposé en plusieurs parties. Cela permet de distribuer le traitement des données dans le système parmi ces morceaux, permettant ainsi de faire évoluer le traitement à l’infini.
- Compression des données : la compression peut réduire la taille des jeux de données stockés et ainsi diminuer les opérations d’E/S en lecture et accélérer les transferts de fichiers sur les réseaux.
- Vélocité des données : le traitement par lots implique la lecture, l’analyse et la transformation simultanées de plusieurs enregistrements. En revanche, le traitement en flux traite en temps réel les enregistrements entrants au fur et à mesure de leur arrivée.
- Écosystème et intégration : il est conseillé de se conformer aux conventions et usages d’un écosystème lors du choix entre plusieurs options. Par exemple, Parquet doit être utilisé sur les plateformes Cloudera, tandis qu’ORC avec Hive est préféré pour les plateformes Hortonworks.
Formats de fichiers
1- Fichiers plats délimités (CSV, TSV)
Les valeurs séparées par des virgules (CSV) et les valeurs séparées par des tabulations (TSV) sont des formats de fichiers texte qui utilisent des sauts de ligne pour séparer les enregistrements et une ligne d’en-tête optionnelle. En conséquence, ils peuvent être facilement modifiés manuellement, ce qui les rend très compréhensibles d’un point de vue humain. Malheureusement, ni CSV ni TSV ne prend en charge l’évolution du schema.
Les fichiers CSV et TSV sont répandus pour le stockage et le transfert de données. Ils ont d’excellents taux de compression, sont faciles à lire et prennent en charge le traitement par lots et en streaming. Cependant, ni CSV ni TSV ne prennent en charge les valeurs nulles, qui sont traitées de la même façon que les valeurs vides.
2- JSON (JavaScript Object Notation)
JSON est un format textuel pouvant stocker des données sous diverses formes, telles que des chaînes, des entiers, des booléens, des tableaux, des paires clé-valeur d’objets et des structures de données imbriquées. Il est léger, lisible par l’homme et par la machine, ce qui en fait un choix idéal pour les applications web. JSON est compressible et prend en charge le traitement par lots et en streaming. Il stocke les métadonnées avec les données et permet l’évolution du schema. Cependant, il manque d’indexation comme de nombreux autres formats texte.
3- XML (Extensible Markup Language)
XML est un langage de balisage créé par le W3C qui permet aux humains et aux machines de lire des documents encodés. Il permet aux utilisateurs de créer des langages complexes ou simples et d’établir des formats de fichiers standard pour l’échange de données entre applications. XML est un format de fichier verbeux qui prend en charge le traitement par lots et en streaming, stocke les métadonnées avec les données et permet l’évolution du schema. Il présente des inconvénients tels que ne pas être divisible et une syntaxe redondante entraînant des coûts de stockage et de transport plus élevés.
4- AVRO
Apache Avro est un framework de sérialisation de données développé dans le cadre du projet Hadoop d’Apache. Il utilise un stockage basé sur les lignes pour sérialiser les données, en stockant le schema au format JSON, ce qui le rend facile à lire et interpréter pour n’importe quel programme. De plus, les données sont stockées sous forme binaire, ce qui les rend compactes et efficaces. Avro est divisible, compressible et prend en charge l’évolution du schema. En raison de son utilisation répandue dans de nombreuses applications telles que Kafka ou Spark, Avro reste l’un des formats les plus populaires pour l’échange d’informations entre systèmes.
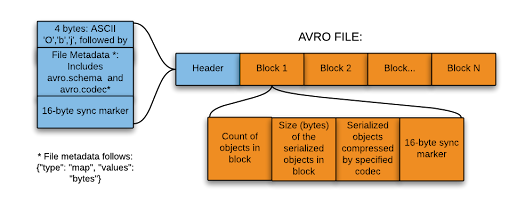 Structure du format AVRO.
Structure du format AVRO.
5- ProtoBuf (Protocol Buffers)
Protobuf (abréviation de Protocol Buffers) est un format de sérialisation de données binaire développé par Google en 2008. Il est utilisé pour encoder efficacement des données structurées de manière extensible et neutre au niveau du langage, ce qui le rend idéal pour des applications telles que la communication réseau ou le stockage des paramètres de configuration. Le format Protocol Buffers (Protobuf) présente des avantages tels qu’être entièrement typé et prendre en charge l’évolution du schema et le traitement par lots/streaming, mais il ne prend pas en charge Map Reduce ni la compression.
 Encodage de messages avec Protocol Buffers.
Encodage de messages avec Protocol Buffers.
6- ORC (Optimized Row Columnar)
Le format ORC (abréviation d’Optimized Row Columnar) a été développé par Hortonworks en partenariat avec Facebook. C’est un système de stockage de données orienté colonne. ORC est un format de fichier hautement compressible qui réduit la taille des données de 75 %. Il est plus efficace pour les requêtes OLAP que OLTP et est principalement utilisé pour le traitement par lots.
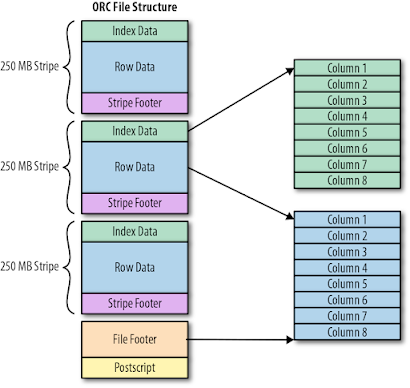 Structure du format ORC.
Structure du format ORC.
7- Parquet
Parquet est un format de fichier open-source conçu pour l’écosystème Hadoop. Il a été créé en collaboration entre Twitter et Cloudera pour fournir un stockage efficace des données analytiques de manière orientée colonne. Parquet offre des schémas de compression et d’encodage avancés qui lui permettent de gérer des données complexes rapidement et efficacement lors du traitement de grands volumes d’informations. Parquet présente des avantages tels qu’être divisible, permettant une meilleure compression et l’évolution du schema grâce à l’organisation par colonnes, et ayant une haute efficacité pour les charges de travail OLAP.
Databricks a récemment créé un nouveau format de fichier appelé Delta qui utilise des fichiers Parquet versionnés pour stocker des données. En plus des versions, Delta contient également un journal de transactions pour suivre tous les commits effectués sur la table afin de fournir des transactions ACID et d’exploiter la fonctionnalité de voyage dans le temps.
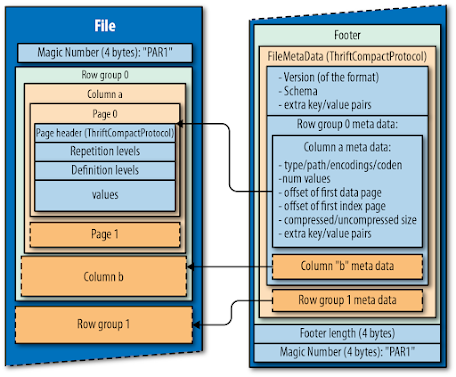 Structure du format Parquet.
Structure du format Parquet.
La sélection du format de fichier doit être basée sur le type de requête et les cas d’usage associés. Voici un tableau récapitulatif des formats de données par rapport aux considérations sélectionnées :
| Attribut\Format | CSV | JSON | XML | AVRO | Protocol Buffers | Parquet | ORC |
|---|---|---|---|---|---|---|---|
| Encodage | Texte | Texte | Texte | métadonnées en JSON, données en binaire | Binaire | Binaire | Binaire |
| Type de données | Non | Oui | Non | Oui | Oui | Oui | Oui |
| Enforcement du schema | Non | externe pour validation | externe pour validation | Oui | Oui | Oui | Oui |
| Évolution du schema | Non | Oui | Oui | Oui | Oui | Oui | Non |
| Type de stockage | En lignes | En lignes | En lignes | En lignes | En lignes | En colonnes | En colonnes |
| OLAP/OLTP | OLTP | OLTP | OLTP | OLTP | OLTP | OLAP | OLAP |
| Divisible | Oui (forme simple) | Oui (JSON lines) | Non | Oui | Non | Oui | Oui |
| Compression des données | Oui | Oui | Oui | Oui | Non | Oui | Oui |
| Vélocité des données | Batch & Stream | Batch & Stream | Batch | Batch & Stream | Batch & Stream | Batch | Batch |
| Écosystèmes | Très populaire | API et web | Entreprise | Big Data et Streaming | RPC et Kubernetes | Big Data et BI | Big Data et BI |
3 - Transformation des données
Les organisations génèrent de vastes quantités de données quotidiennement, mais celles-ci ne sont utiles que si elles peuvent les utiliser pour obtenir des insights et promouvoir la croissance métier. La transformation des données consiste à convertir et à structurer les données d’une forme vers une forme utilisable, soutenant les processus décisionnels. La transformation des données est utilisée lorsque les données doivent être modifiées pour correspondre au format et à la structure du système cible. Cela peut avoir lieu dans ce qu’on appelle les pipelines de données.
![]() Transformation des données.
Transformation des données.
Après la préparation des données (appelée pré-traitement), un pipeline de transformation des données commence par une phase de mapping. Cela implique d’analyser comment les champs individuels seront modifiés, joints ou agrégés pour comprendre les changements nécessaires. Trois approches peuvent être suivies :
- Outils centrés sur le code : bibliothèques d’analyse et de manipulation construites sur des langages de programmation à usage général (Scala, Java ou Python).
- Outils centrés sur les requêtes : utilisent un langage de requête comme SQL pour gérer et manipuler les jeux de données.
- Outils hybrides : implémentent SQL sur des langages de programmation à usage général. C’est le cas de certaines bibliothèques comme Apache Spark ou Apache Kafka qui fournissent un dialecte SQL appelé KSQL.
La transformation des données est une partie critique du parcours de données. Ce processus peut effectuer des tâches constructives telles que l’ajout ou la copie d’enregistrements et de champs, des actions destructives comme le filtrage et la suppression de valeurs spécifiques, des ajustements esthétiques pour standardiser les valeurs, ou des changements structurels incluant le renommage de colonnes, leur déplacement et leur fusion. La transformation des données peut être utilisée pour :
- Filtrage : sélectionne un sous-ensemble de votre jeu de données (colonnes spécifiques) nécessitant une transformation, une visualisation ou une analyse.

- Enrichissement : complète les lacunes de base du jeu de données. Ce processus améliore les informations existantes en complétant les données incomplètes ou manquantes avec un contexte pertinent.

- Division (Splitting) : où une seule colonne est divisée en plusieurs ;

- Fusion (Merging) : où plusieurs colonnes sont fusionnées en une seule ;

- Suppression de parties des données ;

- Jointure (Joining) de données provenant de différentes sources. Une jointure de données consiste à combiner deux jeux de données côte à côte. Au moins une colonne de chaque jeu de données doit être identique. Cela diffère d’une union qui empile les jeux de données les uns sur les autres ;

Il existe neuf types de jointures : interne, externe, externe gauche, externe droite, anti-externe, anti-gauche, anti-droite et jointure croisée :
- Une jointure interne prend les lignes de données où les deux jeux ont des champs en commun.
- Une jointure externe conserve toutes les données des deux jeux. Les lignes sans correspondance seront remplies avec des valeurs NULL.
- La jointure externe gauche combine deux jeux de données en prenant toutes les lignes partagées et les lignes restantes du jeu de gauche.
- La jointure externe droite combine deux jeux de données en prenant toutes les lignes partagées et les lignes restantes du jeu de droite.
- Une jointure anti-externe exclut les lignes communes entre les jeux.
- Une jointure anti-gauche exclut les lignes communes et les lignes supplémentaires du jeu de données de droite.
- Une jointure anti-droite est la même que l’anti-gauche mais ne conserve que les lignes du jeu de données de droite.
- Jointure croisée : retourne le produit cartésien des deux tables.
- Jointure réflexive (Self-join) : jointure d’une table avec elle-même, généralement en utilisant un alias pour la même table.

- Agrégation : fournit des résumés ou des statistiques sur les données tels que des moyennes et des sommes.
- Dérivation : qui consiste en des calculs inter-colonnes. Un champ dérivé est une colonne dont la valeur est dérivée de la valeur d’une ou plusieurs colonnes.

- Pivotement (Pivoting) : qui consiste à convertir les valeurs de colonnes en lignes et vice versa. Vous pouvez utiliser les opérateurs relationnels PIVOT et UNPIVOT pour changer une expression de table en une autre table.

- Tri (Sorting) : ordonnancement et indexation des données pour améliorer les performances de recherche.

- Mise à l’échelle (Scaling) : normalisation et standardisation qui permettent de comparer différents chiffres en les mettant sur une échelle cohérente. La mise à l’échelle des caractéristiques est une étape essentielle du pré-traitement des données pour le machine learning.
La normalisation ou mise à l’échelle Min-Max est utilisée pour transformer les caractéristiques sur une échelle similaire. Par exemple, cela met à l’échelle la plage vers [0, 1] ou parfois [-1, 1]. La normalisation est utile lorsqu’il n’y a pas de valeurs aberrantes.
La standardisation ou normalisation par score-Z transforme les caractéristiques en soustrayant la moyenne et en divisant par l’écart type. Ceci est souvent appelé un score-Z. La standardisation peut être utile dans les cas où les données suivent une distribution gaussienne.

- Normalisation de la structure est le processus d’organisation des données dans une structure logique pouvant être utilisée pour améliorer les performances et réduire la redondance.
- Dénormalisation est le processus inverse de la normalisation, où le schema normalisé est converti en un schema avec des informations redondantes. Les données dénormalisées contiennent souvent des valeurs dupliquées qui augmentent les besoins de stockage mais accélèrent les requêtes.

La normalisation de la structure est utilisée dans les systèmes OLTP pour rendre les opérations d’insertion, de suppression et de mise à jour plus rapides. En revanche, la dénormalisation est utilisée dans les systèmes OLAP pour optimiser la vitesse de recherche et d’analyse.
- Vectorisation : qui aide à convertir les données non numériques en tableaux de nombres souvent utilisés pour les applications de machine learning ;
- Et bien plus encore…
4 - Modélisation des données
La modélisation des données est une pratique qui existe depuis des décennies sous une forme ou une autre. La modélisation des données est devenue démodée au début et au milieu des années 2010 : l’essor des data lakes 1.0, du NoSQL et des plateformes big data a permis aux ingénieurs de contourner la modélisation traditionnelle des données. Cependant, l’absence de modélisation rigoureuse des données a créé des data swamps. De nos jours, nous ne parlons plus de « big data » ; nous préférons plutôt le terme « données utiles » et le retour progressif vers une modélisation rigoureuse des données (par ex., data lakehouse).
Un modèle de données dépeint la relation entre les données et le monde réel. Il définit la manière optimale de structurer et de standardiser les données pour refléter avec précision les processus, définitions, flux de travail et logique de votre organisation. Le continuum de la modélisation des données comprend trois modèles de données principaux : conceptuel, logique et physique.
- Modèle conceptuel : un modèle de données qui représente des concepts et des relations à haut niveau dans un mode simplifié (diagrammes ER). Il fournit une vue d’ensemble (logique métier et règles) des données et de leurs relations avec les processus métier de l’organisation.
- Modèle logique : un modèle de données logique est un type de modèle de données qui fournit une représentation détaillée des données et de leurs relations avec les processus métier d’une organisation. Il se concentre sur la structure des données, y compris les tables, les colonnes, les clés et les index, tout en évitant les détails techniques d’implémentation.
- Modèle physique : définit la façon dont le modèle logique sera implémenté dans une technologie de stockage de données.

Vous devriez généralement chercher à modéliser vos données au grain le plus fin possible. À partir de là, il est facile d’agréger ce jeu de données très granulaire. Malheureusement, l’inverse n’est pas vrai et il est généralement impossible de restaurer des détails qui ont été agrégés.
La pratique de la normalisation dans la modélisation des données consiste à mettre en œuvre un contrôle strict sur les relations des tables et des colonnes au sein d’une base de données pour éliminer la redondance des données et garantir l’intégrité référentielle. Ce concept a été initialement introduit par Edgar Codd dans les années 1970 à travers l’introduction des formes normales :
- Première forme normale (1NF) : la table doit avoir une clé primaire, et chaque colonne doit contenir des valeurs atomiques (c’est-à-dire indivisibles) ;
- Deuxième forme normale (2NF) : la table doit déjà être en première forme normale, et tous les attributs non clés doivent dépendre entièrement de la clé primaire ;
- Troisième forme normale (3NF) : la table doit déjà être en deuxième forme normale, et tous les attributs non clés doivent dépendre uniquement de la clé primaire et non d’autres attributs non clés.
Il existe également des formes normales supplémentaires au-delà de la 3NF :
- Forme normale de Boyce-Codd (BCNF) : également connue sous le nom de 3.5NF, cette forme normale est une extension de la 3NF.
- Quatrième forme normale (4NF) : une table est en 4NF si elle n’a pas de dépendances multi-valuées.
- Cinquième forme normale (5NF) : également connue sous le nom de forme normale Projet-Jointure (PJNF), cette forme normale traite le problème des dépendances de jointure.

Lors de la description de la modélisation des données pour les data lakes ou les data warehouses, vous devez supposer que les données brutes prennent de nombreuses formes (par ex., structurées et semi-structurées). Vous rencontrerez probablement les méthodes célèbres suivantes : Kimball, Inmon et Data Vault.
Modélisation des données d’Inmon
Inmon définit un data warehouse : « Un data warehouse est une collection de données orientée sujet, intégrée, non volatile et variable dans le temps, en appui aux décisions de la direction. »
Les quatre caractéristiques critiques d’un data warehouse peuvent être décrites comme suit :
- Orienté sujet : le data warehouse se concentre sur un domaine sujet spécifique, comme les ventes ou la comptabilité ;
- Intégré : les données provenant de sources disparates sont consolidées et normalisées ;
- Non volatile : les données restent inchangées après leur stockage dans un data warehouse ;
- Variable dans le temps : différentes plages de temps peuvent être interrogées.
Le data warehouse représente une « source unique de vérité », qui soutient les exigences d’information de l’ensemble de l’activité. Les données sont présentées pour les rapports et l’analyse en aval via des data marts spécifiques aux métiers et aux départements.
Schéma en étoile de Kimball
Une option populaire pour modéliser les données dans un data mart est un schéma en étoile (Kimball). Créé par Ralph Kimball au début des années 1990, cette approche se concentre moins sur la normalisation et, dans certains cas, accepte la dénormalisation.
Contrairement à l’approche d’Inmon consistant à intégrer les données de toute l’entreprise dans le data warehouse, le modèle Kimball est ascendant et favorise la modélisation et le service des analyses directement au sein du data warehouse.
Dans l’approche de Kimball, les données sont modélisées avec deux types généraux de tables : les faits et les dimensions. Vous pouvez considérer une table de faits comme une table de chiffres et les tables de dimensions comme des données qualitatives référençant un fait.
- Les tables de faits contiennent des données factuelles, quantitatives et liées aux événements. Les données dans une table de faits sont immuables car les faits se rapportent à des événements. Les tables de faits doivent être au grain le plus fin possible.
- Les tables de dimensions fournissent les données de référence, les attributs et le contexte relationnel pour les événements stockés dans les tables de faits. Les dimensions sont dénormalisées1, avec la possibilité de données dupliquées.
- Les dimensions à évolution lente (SCD) désignent des types spécifiques de tables de dimensions généralement utilisées pour suivre les changements dans les dimensions au fil du temps. Il existe sept types de SCD :
- Type 0 : ce type de SCD ne suit pas les changements d’une dimension du tout.
- SCD Type 1 : cette approche écrase les données existantes par les nouvelles données.
- SCD Type 2 : ce type crée un nouvel enregistrement à chaque modification d’une dimension.
- SCD Type 3 : cette approche ajoute une nouvelle colonne à un enregistrement existant pour suivre un changement dans une dimension.
- SCD Type 4 : écrase les enregistrements de dimension existants, comme le SCD Type 1, mais maintient simultanément une table historique.
- SCD Type 5 : cette approche combine les SCD de type 1 et de type 2.
- SCD Type 6 : ce type combine les SCD de type 2 et de type 3.
- SCD Type 7 : une approche relativement nouvelle qui combine les SCD de type 1 et de type 2 avec l’ajout d’une colonne « Indicateur courant » dans la table de dimensions.
- Le schéma en étoile représente le modèle de données de l’activité. Contrairement aux approches fortement normalisées, le schéma en étoile est une table de faits entourée des dimensions nécessaires, résultant en moins de jointures et améliorant les performances des requêtes.

Data Vault
Tandis que Kimball et Inmon se concentrent sur la structure de la logique métier dans le data warehouse, le Data Vault offre une approche différente de la modélisation des données. Créé dans les années 1990 par Dan Linstedt, la méthodologie Data Vault sépare les aspects structurels des données d’un système source de ses attributs.
Un modèle Data Vault est composé de trois tables principales : les hubs, les liens et les satellites. En bref, un hub stocke les clés métier, un lien maintient les relations entre les clés métier, et un satellite représente les attributs et le contexte d’une clé métier.
- Les hubs : un hub est l’entité centrale d’un Data Vault qui conserve un enregistrement de toutes les clés métier uniques chargées dans le Data Vault. Un hub contient toujours les champs standard suivants :
- Clé de hachage : la clé primaire utilisée pour joindre les données entre les systèmes.
- Date de chargement : la date à laquelle les données ont été chargées dans le hub.
- Source d’enregistrement : la source à partir de laquelle l’enregistrement unique a été obtenu.
- Clé(s) métier : la clé utilisée pour identifier un enregistrement unique.
Note : Il est important de noter qu’un hub est en insertion uniquement, et les données ne sont pas modifiées dans un hub. Une fois les données chargées dans un hub, elles sont permanentes.
- Les tables de liens suivent les relations des clés métier entre les hubs. Les tables de liens connectent les hubs, idéalement au grain le plus bas possible. Comme les tables de liens connectent des données de divers hubs, elles sont de type plusieurs-à-plusieurs.
- Les satellites : nous avons décrit les relations entre les hubs et les liens qui impliquent des clés, des dates de chargement et des sources d’enregistrement. Comment comprenez-vous ce que ces relations signifient ? Les satellites sont des attributs descriptifs qui donnent du sens et du contexte aux hubs. Les satellites peuvent se connecter à des hubs ou à des liens.

Contrairement aux autres techniques de modélisation des données, la logique métier est créée et interprétée dans un Data Vault lorsque les données de ces tables sont interrogées. Le modèle Data Vault peut également être utilisé avec d’autres techniques de modélisation des données. Par exemple, il n’est pas rare qu’un Data Vault soit la zone d’atterrissage pour les données analytiques, puis modélisé séparément dans un data warehouse, généralement en utilisant un schéma en étoile.
5 - Lignée des données
Suivre les relations entre et au sein des jeux de données est de plus en plus important au fur et à mesure que des sources de données sont ajoutées, modifiées ou mises à jour. La lignée fournit une traçabilité pour comprendre d’où viennent les champs et les jeux de données, ainsi qu’une piste d’audit pour suivre quand les changements ont été effectués, pourquoi ils ont été faits et par qui.

Le suivi de la lignée des données est essentiel pour s’assurer que les décisions stratégiques sont basées sur des informations précises. Sans cela, vérifier la source et la transformation des données peut être coûteux et chronophage.
Voici quelques techniques courantes utilisées pour effectuer la lignée des données sur des jeux de données stratégiques :
Lignée basée sur les patterns
Cette technique utilise les métadonnées pour tracer la lignée des données sans analyser l’implémentation du pipeline. Elle recherche des patterns dans les tables, les colonnes et les rapports métier en comparant des noms et valeurs similaires entre les jeux de données.
Lignée par étiquetage des données
Cette technique repose sur les étiquettes que les moteurs de transformation ajoutent aux données traitées. En suivant ces étiquettes du début à la fin, il est possible de découvrir des informations de lignée sur les données.
Lignée autonome
Certaines organisations ont un environnement de données unique qui fournit le stockage, la logique de traitement et la gestion des données maîtres (MDM) pour un contrôle central sur les métadonnées. Ce système autonome peut intrinsèquement fournir la lignée sans avoir besoin d’outils externes.
Lignée par analyse syntaxique (rétro-ingénierie)
C’est la forme la plus avancée de lignée. Elle lit automatiquement la logique utilisée pour traiter les données afin de retracer la transformation des données de bout en bout. Cela nécessite une bonne compréhension des langages de programmation ou des outils utilisés tout au long du cycle de vie des données.
Lignée via les contrats de données
Comme vu dans la section sur le nettoyage des données, les contrats de données contiennent des informations sur le schema et la sémantique, le versioning et les accords SLA entre les producteurs et les consommateurs. De plus, les contrats de données peuvent également contenir des informations détaillées sur la lignée, comme les étiquettes, les propriétaires de données, les sources de données, les consommateurs prévus, etc.
Activités transversales du traitement des données
Dans l’étape de traitement, vos données mutent et se transforment en quelque chose d’utile pour l’activité. Parce qu’il y a de nombreuses parties mobiles, les activités transversales sont particulièrement critiques à cette étape.
- Sécurité : l’accès à des colonnes, des lignes et des cellules spécifiques au sein d’un jeu de données doit également être contrôlé. Il est crucial d’être attentif aux vecteurs d’attaque potentiels contre votre base de données lors des requêtes. Vous devez surveiller et contrôler étroitement les privilèges de lecture/écriture dans la base de données.
- Gestion des données : pour garantir l’exactitude des données lors des transformations, il est crucial de s’assurer que les données utilisées sont exemptes de défauts et représentent la vérité terrain. La mise en œuvre de la gestion des données maîtres (MDM) dans votre entreprise peut être une option viable pour atteindre cet objectif.
- DataOps : les requêtes et les transformations nécessitent une surveillance et des alertes dans deux domaines clés : les données et les systèmes. Les changements ou anomalies dans ces domaines doivent être rapidement détectés et traités.
- Orchestration : les équipes de données gèrent souvent leurs pipelines de transformation à l’aide de simples planifications basées sur le temps (par ex., des tâches cron). Cela fonctionne raisonnablement bien au début, mais devient un cauchemar à mesure que les workflows deviennent plus complexes. Utilisez plutôt l’orchestration pour gérer des pipelines complexes en utilisant une approche basée sur les dépendances.
- Architecture de données : comme je l’ai souligné dans Data 101 - partie 3, une bonne architecture de données doit principalement répondre aux exigences métier avec un ensemble d’éléments de construction largement réutilisables. Vous pouvez évaluer votre architecture selon les six piliers du AWS Well-Architected Framework (WAF).
Résumé
Les transformations sont un aspect crucial des pipelines de données, car elles se trouvent au cœur du processus. Cependant, il est essentiel de toujours garder à l’esprit l’objectif de ces transformations. Dans ce processus, les données sont converties et structurées d’une forme particulière vers une forme utilisable qui ajoute de la valeur et un retour sur investissement (ROI) à l’activité.
Dans cet article, nous avons vu plus de détails sur le traitement des données et ce qu’il comprend. L’étape de traitement des données commence par le nettoyage des données (pré-traitement), qui rend les données fiables, et se termine par la modélisation des données qui dépeint la relation entre les données et le monde réel. Un vaste univers d’outils, de solutions et de principes est mis en œuvre entre ces deux étapes pour obtenir des insights et soutenir les processus décisionnels.
Références
- H. W. Inmon, Building the Data Warehouse (Hoboken: Wiley, 2005).
- Ackerman H., King J., Operationalizing the Data Lake (O’Reilly Media 2019).
- Daniel Linstedt and Michael Olschimke, Building a Scalable Data Warehouse with Data Vault 2.0 (Morgan Kaufmann).
- “Data Vault 2.0 Modeling Basics”, Kent Graziano (Snowflake).
- “Data Warehouse: The Choice of Inmon versus Kimball”, Ian Abramson.
- “What is Data Lineage?”, Imperva Blog.
- “Introduction to Secure Data Sharing”, Snowflake docs.
- “Qu’est-ce que Data as a Service (DaaS) ?”, Tibco.
- “Augmented Data Catalogs: Now an Enterprise Must-Have for Data and Analytics Leaders”, Ehtisham Zaidi, and Guido De Simoni (Gartner).
- “Data preparation – its applications and how it works”, Talend Resources.
- “Cleaning Big Data: Most Time-Consuming, Least Enjoyable Data Science Task, Survey Says”, Gil Press (Forbes).
- “The Rise of Data Contracts And Why Your Data Pipelines Don’t Scale”, Chad Sanderson.
- “Comparison of different file formats in Big Data”, Aida NGOM (Adatlas).
- Vous pouvez préserver la normalisation des dimensions avec le « Snowflaking ». Le principe du snowflaking est la normalisation des tables de dimensions en supprimant les attributs à faible cardinalité et en formant des tables séparées. La structure résultante ressemble à un flocon de neige avec la table de faits au milieu.