
Vous êtes arrivé à la dernière étape du parcours de données : le service des données pour les cas d’usage en aval. Maintenant que les données ont été ingérées, stockées et traitées en structures cohérentes et précieuses, il est temps d’en tirer de la valeur.
Le service des données est la partie la plus enthousiasmante du cycle de vie des données. C’est là que la magie opère : l’étape de service concerne les données en action. Mais quelle est l’utilisation productive des données ? Pour répondre à cette question, vous devez considérer deux éléments : quel est le cas d’usage, et qui est l’utilisateur ?
Dans cet article, vous découvrirez différentes façons de servir les données : vous préparerez les données pour l’analyse statistique et la visualisation. Ce sont les domaines les plus traditionnels du service des données, où les parties prenantes métier obtiennent de la visibilité et des insights à partir des données brutes collectées.
Ensuite, vous verrez comment servir les données pour le machine learning. En effet, pour éviter le célèbre adage « Garbage in, Garbage out », il est impossible de démarrer le machine learning sans des données de haute qualité correctement préparées. Tout au long du parcours de données, les ingénieurs de données travaillent en collaboration avec les data scientists et les ingénieurs ML pour acquérir, transformer et livrer les données nécessaires à l’entraînement des modèles.
Enfin, vous verrez comment servir les données via un Reverse ETL. Le Reverse ETL consiste à renvoyer les données traitées vers les systèmes sources. Cela est devenu de plus en plus important à mesure que les organisations cherchent à utiliser leurs données de manière plus significative et percutante. En déplaçant les données traitées vers les systèmes opérationnels, les organisations peuvent permettre une prise de décision basée sur les données au moment de l’action. Cela permet aux entreprises de réagir aux conditions changeantes et de prendre des décisions plus éclairées en temps réel.
Analytique
L’analytique est au cœur de la plupart des démarches data. Elle consiste à interpréter et à tirer des insights des données traitées afin de prendre des décisions éclairées ou de faire des prédictions sur les tendances futures. Les outils de visualisation des données peuvent être utilisés ici pour aider à visualiser les données de manière plus significative.
Identifier le cas d’usage final est la première étape avant de servir les données à des fins analytiques. Le cas d’usage final détermine le type d’analytique requis, comme les tendances historiques, la détection automatique d’anomalies (par exemple, la détection de fraude) ou les notifications et rapports en temps réel sur une application mobile. Ces différents cas d’usage illustrent les distinctions entre l’analytique métier (communément appelée Business Intelligence ou BI), l’analytique opérationnelle et l’analytique embarquée, chacune ayant des exigences et des objectifs de service spécifiques.
1 - Analytique Métier
L’analytique métier exploite à la fois les données historiques et actuelles pour formuler des décisions stratégiques et pratiques. Ces décisions tiennent souvent compte des tendances à plus long terme et nécessitent une combinaison d’analyses statistiques, d’analyses de tendances et de connaissances du domaine. En essence, l’analyse métier est une fusion de science et d’art, où le jugement humain et l’expertise jouent un rôle essentiel aux côtés des techniques analytiques. L’analytique métier peut être organisée en six catégories :
- Analyse Descriptive : Cette analyse répond à la question « Que s’est-il passé ? ». L’analyse descriptive fournit une compréhension de ce qui s’est produit dans le passé. Elle consiste à résumer les données pour décrire ce qui se passe dans l’ensemble de données, en utilisant des fonctions d’agrégation (c’est-à-dire des comptages, des moyennes, des fréquences…). Elle ne tente pas d’expliquer pourquoi les choses se sont produites ni de déterminer les relations de cause à effet ; son but est simplement de donner un aperçu concis.
- Analyse Exploratoire des Données (EDA) : se concentre sur l’exploration et la compréhension d’un ensemble de données en utilisant des visualisations telles que des histogrammes, des boîtes à moustaches, des nuages de points, etc., pour découvrir des modèles et des relations entre les variables qui peuvent ne pas être immédiatement évidents à partir des seules statistiques descriptives.
- Analyse Diagnostique : Cette analyse répond à la question « Pourquoi cela s’est-il produit ? ». L’analyse diagnostique vise à découvrir la cause profonde derrière un phénomène observé. Grâce à ce type d’analyse, vous pouvez identifier et répondre aux anomalies dans vos données. Lors d’une analyse diagnostique, vous pouvez employer plusieurs techniques différentes, telles que la probabilité, la régression, le filtrage et l’analyse de séries temporelles.
- Analyse Inférentielle : L’analyse inférentielle est une technique statistique qui utilise les données d’un petit échantillon pour faire des inférences sur la population plus large. Elle repose sur le théorème central limite, qui stipule que, étant donné suffisamment d’échantillons de variables aléatoires, leur distribution tendra vers la normale. Elle peut estimer des paramètres dans la population sous-jacente avec une incertitude associée ou une mesure d’écart type. Pour garantir l’exactitude, il est important que votre schéma d’échantillonnage représente avec précision la population cible afin de ne pas introduire de biais dans vos résultats.
- Analyse Prédictive : Cette analyse répond à la question « Que va-t-il probablement se passer à l’avenir ? ». L’analyse prédictive utilise des techniques statistiques telles que les modèles de régression et les algorithmes de machine learning pour prédire des événements ou des résultats futurs en fonction des modèles et tendances passés (historiques) ou actuels dans l’ensemble de données analysé. Cela permet aux organisations de planifier à l’avance et de prendre des décisions éclairées basées sur leurs prévisions ; par exemple, si les ventes sont prévues en baisse pendant les mois d’été en raison de facteurs saisonniers, elles peuvent choisir de lancer des campagnes promotionnelles ou d’ajuster leurs dépenses en conséquence. Elle peut également aider à identifier les risques potentiels associés à certaines décisions ou actions d’une organisation avant qu’ils ne se produisent, afin que des mesures appropriées puissent être prises de manière proactive plutôt que réactive après que quelque chose a déjà mal tourné.
- Analyse Prescriptive : Cette analyse répond à la question « Quelle est la meilleure ligne de conduite ? ». L’analyse prescriptive va encore plus loin que l’analyse prédictive en recommandant comment agir au mieux sur ces prédictions. Elle examine ce qui s’est passé, pourquoi, et ce qui pourrait se passer pour déterminer ce qui devrait être fait ensuite. En combinant les insights obtenus grâce aux autres types d’analyses (listées ci-dessus) avec des méthodes de modélisation avancées telles que l’intelligence artificielle (IA) et les algorithmes d’optimisation, l’analyse prescriptive aide les organisations à prendre des décisions mieux éclairées sur leurs opérations tout en minimisant leur exposition aux risques.
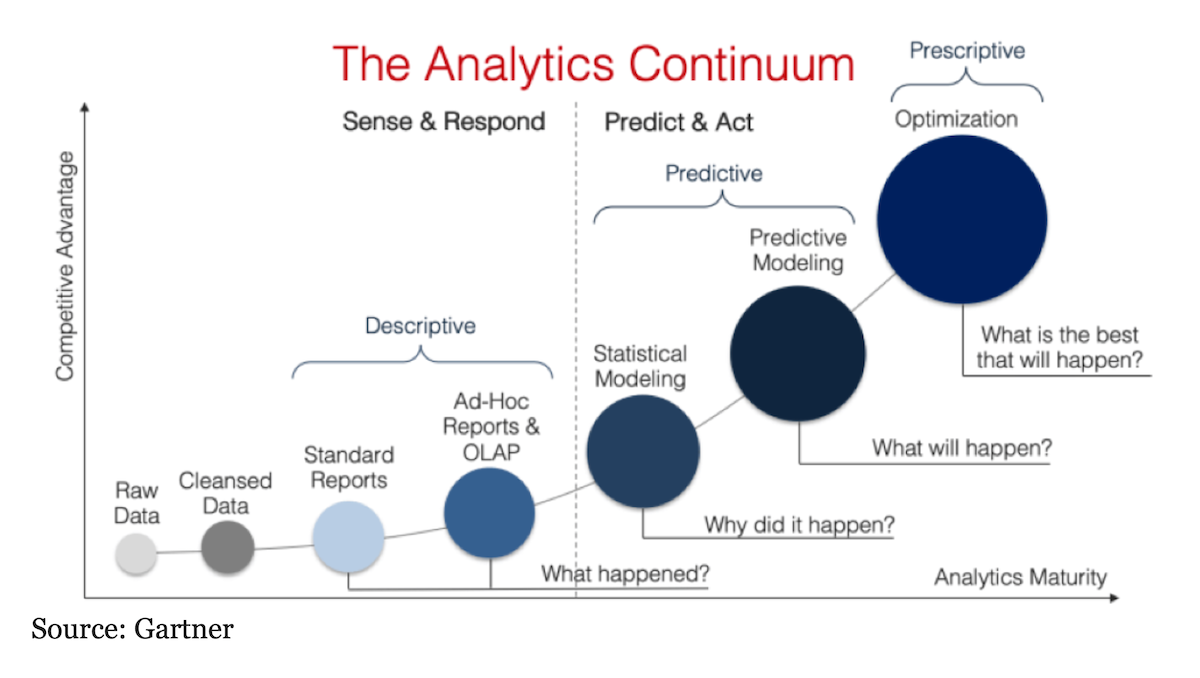
Les différents types d’analytique des données seront détaillés de manière approfondie dans la deuxième partie de ce blog (Analytics 101).
Une fois que les données traitées ont traversé ces analyses, les résultats (insights) peuvent être partagés avec les parties prenantes ou d’autres parties intéressées. Cela peut se faire via des rapports, des présentations ou des tableaux de bord, selon le type d’information à partager et à qui elle est destinée. Les données traitées et/ou les insights peuvent également être partagés « tels quels » à des fins ultérieures, telles que les feature stores pour les algorithmes de machine learning, la monétisation des données, les API, etc.
L’analytique métier implique généralement trois grands domaines : les tableaux de bord, les rapports et l’analyse ad hoc. Les analystes métier peuvent se concentrer sur un ou plusieurs de ces domaines, et les ingénieurs de données doivent comprendre les différences et les outils associés. De plus, en comprenant les activités des analystes, les ingénieurs de données peuvent mieux servir les données pour répondre à leurs besoins.

Les tableaux de bord fournissent un aperçu concis des performances d’une organisation par rapport à des indicateurs clés, tels que les ventes et la fidélisation des clients. Ces indicateurs sont présentés sous forme de visualisations, de statistiques résumées ou d’un seul chiffre. Pensez à un tableau de bord comme celui que l’on trouve dans une voiture, qui donne aux conducteurs un affichage rapide et facile à lire des informations critiques pendant la conduite. De même, les tableaux de bord analytiques fournissent aux dirigeants d’entreprise un aperçu de l’état actuel de leurs organisations, leur permettant de prendre les bonnes décisions de manière éclairée.
2 - Analytique Opérationnelle
L’analytique opérationnelle diffère de l’analytique métier principalement en termes de temporalité. L’analytique métier adopte une vision à plus long terme du problème analysé. Bien que les mises à jour à la seconde près puissent être utiles, elles ne sont pas critiques pour la qualité ou le résultat global de l’analyse. En revanche, l’analytique opérationnelle repose fortement sur les mises à jour en temps réel, car elles peuvent être déterminantes pour résoudre rapidement les problèmes au fur et à mesure qu’ils surviennent. La détection de fraude en temps réel est un exemple d’analytique opérationnelle. De nombreuses organisations financières veulent savoir comment leurs systèmes de sécurité fonctionnent ; si des activités frauduleuses se produisent, elles souhaitent en être notifiées immédiatement.

Cependant, la distinction entre l’analytique métier et l’analytique opérationnelle est devenue de plus en plus floue à mesure que les données en streaming et les technologies à faible latence deviennent plus répandues. Par conséquent, l’application de méthodologies opérationnelles aux défis de l’analytique métier devient de plus en plus courante. Par exemple, un détaillant en ligne peut utiliser l’analytique en temps réel pour surveiller les performances du site web le Black Friday tout en suivant les ventes, les revenus et l’efficacité des campagnes publicitaires. Cette approche permet aux entreprises de réagir rapidement aux changements de comportement des consommateurs et aux conditions du marché, conduisant à une prise de décision plus agile et à de meilleurs résultats.
À moyen terme, le temps réel sera probablement la norme. Les produits data de la prochaine décennie seront vraisemblablement axés en priorité sur le streaming, capables d’intégrer de manière transparente les données historiques.
3 - Analytique Embarquée
Contrairement à l’analytique métier et opérationnelle qui cible principalement l’usage interne, il existe une tendance croissante vers l’analytique externe ou embarquée. Les entreprises tirent parti de l’abondance des données disponibles pour offrir aux utilisateurs finaux des applications de données qui intègrent l’analytique dans l’interface de l’application. Ces applications de données deviennent de plus en plus populaires auprès des utilisateurs qui s’attendent à ce que les entreprises utilisent les données pour fournir des insights précieux. Par exemple, les applications de maison intelligente (domotique) qui affichent la température, la luminosité, la qualité de l’air et la consommation d’énergie en temps réel permettent aux utilisateurs d’adapter et de personnaliser leur environnement de vie.

L’utilisation de l’analytique embarquée se développe rapidement, et je peux m’attendre, grâce à l’IoT, à ce que ces applications de données deviennent encore plus répandues dans les années à venir. En tant qu’ingénieur de données, votre rôle peut ne pas impliquer le développement du front end de ces analytiques embarquées, car cela est généralement pris en charge par les développeurs d’applications. Cependant, puisque vous êtes responsable des données qui soutiennent l’analytique embarquée, il est essentiel de bien comprendre les exigences en matière de vélocité et de latence1 spécifiques à ces applications.
Machine Learning
Le deuxième domaine majeur du service des données est le machine learning (ML). Comme le ML devient de plus en plus répandu, je suppose que vous êtes au moins familier avec le concept. Avec l’émergence du ML engineering en tant que domaine parallèle à l’ingénierie des données, vous vous demandez peut-être où les ingénieurs de données s’inscrivent dans ce tableau. Bien qu’un ingénieur de données n’ait pas besoin d’une compréhension approfondie du machine learning (ML), avoir une compréhension de base du fonctionnement du ML classique et des fondamentaux du deep learning peut être extrêmement utile : la différence entre l’apprentissage supervisé, non supervisé et semi-supervisé, la différence entre les techniques de classification et de régression, les diverses techniques de traitement des données de séries temporelles (analyse et prévision de séries temporelles), comment encoder les données catégorielles et les embeddings pour différents types de données, la différence entre l’apprentissage batch (hors ligne) et en ligne (temps réel)…
Les frontières entre le machine learning, la data science et l’ingénierie des données varient considérablement selon les organisations. Par exemple, dans certaines organisations, les ingénieurs ML prennent en charge le traitement des données pour les applications ML juste après la collecte des données, ou peuvent même former un parcours de données distinct parallèle à celui qui gère l’analytique.
Mais pour être aligné avec l’état de l’art actuel, le rôle principal des ingénieurs de données ici est de fournir aux data scientists et aux ingénieurs ML les données dont ils ont besoin pour faire leur travail. Voici quelques façons courantes de servir ces données :
1. L’échange de fichiers est une façon assez courante de servir les données. Les données traitées sont transformées et générées sous forme de fichiers à consommer directement par les utilisateurs finaux. Par exemple, une unité métier pourrait recevoir des données de facturation d’une entreprise partenaire sous forme d’une collection de CSV (données structurées). Un data scientist pourrait charger un fichier texte (données non structurées) de messages clients pour analyser les sentiments des réclamations. 2. Les bases de données sont un composant essentiel du service des données pour l’analytique et le ML. Cette discussion se concentrera implicitement sur le service des données à partir de bases de données OLAP (par exemple, les entrepôts de données et les data marts). Le principal avantage du service des données via une base de données est qu’une base de données impose de l’ordre et de la structure sur les données via des schemas. Ainsi, un contrat de données peut être établi entre les ingénieurs de données et les data scientists sur les exigences prédéfinies (forme et contenu) des données servies.
Plusieurs bases de données peuvent jouer le rôle de feature stores. Un feature store est un référentiel centralisé spécifiquement conçu pour gérer, stocker et partager les features utilisées dans les modèles de machine learning. En machine learning, les features sont les variables d’entrée ou les prédicteurs utilisés pour entraîner les modèles à faire des prédictions ou des classifications. Le feature store permet aux data scientists et aux ingénieurs de stocker, découvrir, partager et réutiliser des features entre différents modèles et applications, améliorant la collaboration et la productivité. En outre, il vise à réduire la charge opérationnelle pour les ingénieurs ML en maintenant l’historique et les versions des features, en soutenant le partage des features entre les équipes, et en fournissant des capacités opérationnelles et d’orchestration de base, telles que le backfilling.
Une autre façon de servir les données pour le machine learning est via les bases de données vectorielles. Une base de données vectorielle est un type de feature store qui stocke les données sous forme de vecteurs ou de représentations mathématiques de points de données. Les algorithmes de machine learning permettent cette transformation de données non structurées en représentations numériques (vecteurs) qui capturent le sens et le contexte, bénéficiant des avancées en traitement du langage naturel et en vision par ordinateur.

La recherche de similarité vectorielle (Vector Similarity Search - VSS) est une fonctionnalité clé d’une base de données vectorielle. Il s’agit du processus de recherche de points de données similaires à un vecteur de requête donné dans une base de données vectorielle. Les utilisations populaires du VSS incluent les systèmes de recommandation, la recherche d’images et de vidéos, la détection de contenu explicite dans les images et les vidéos, la détection d’anomalies, et plus récemment, le traitement du langage naturel (comme ChatGPT). Par exemple, si vous construisez un système de recommandation, vous pouvez utiliser le VSS pour trouver (et suggérer) des produits similaires à un produit pour lequel un utilisateur a précédemment manifesté de l’intérêt.
3. Les moteurs de virtualisation des données : tout moteur de requête/traitement prenant en charge les tables externes peut servir de moteur de virtualisation des données. La virtualisation des données est étroitement liée aux requêtes fédérées, dans lesquelles les données sont extraites de plusieurs sources, telles que les data lakes, les SGBDR et les entrepôts de données, sans être stockées en interne. La fédération devient de plus en plus populaire à mesure que les moteurs de virtualisation de requêtes distribués gagnent en reconnaissance comme moyens de servir des requêtes sans avoir à centraliser les données dans un système OLAP. Au lieu de cela, vous pouvez effectuer des requêtes sur pratiquement n’importe quoi. Le principal avantage des requêtes fédérées est l’accès en lecture seule aux systèmes sources, ce qui est idéal lorsque vous ne souhaitez pas servir des fichiers, des accès à des bases de données ou des dumps de données. L’utilisateur final ne lit que la version des données à laquelle il est censé accéder et rien de plus.
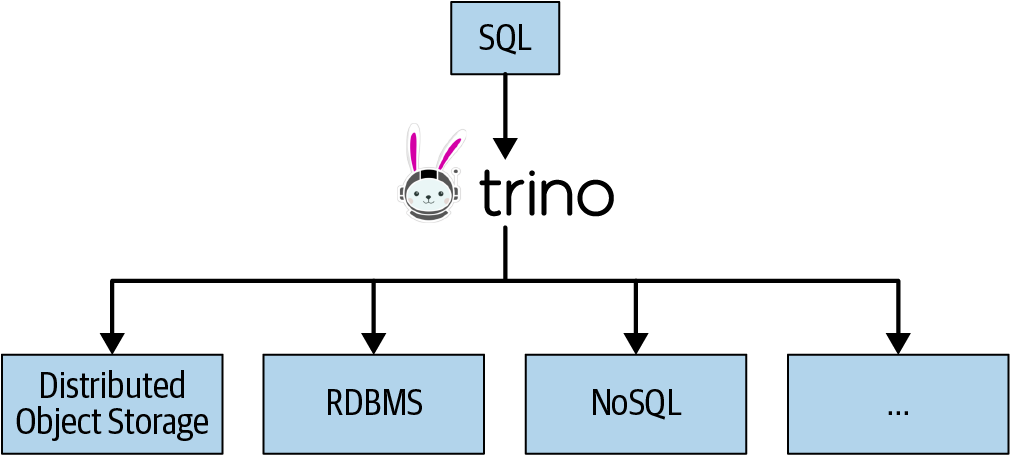
4. La couche sémantique est une couche d’abstraction qui se situe entre les utilisateurs finaux et les sources de données sous-jacentes. Elle fournit une vue simplifiée et orientée métier des données, protégeant les utilisateurs de la complexité des structures et technologies de données sous-jacentes.
La couche sémantique agit comme un pont entre les sources de données et les utilisateurs finaux, leur permettant d’interagir avec les données en utilisant un vocabulaire métier commun plutôt que d’avoir à comprendre les détails techniques des données. De plus, elle traduit les concepts et la terminologie métier en requêtes pouvant être exécutées contre les sources de données, offrant une expérience utilisateur cohérente et intuitive.
La couche sémantique comprend généralement des modèles de données, des règles métier, des calculs et des métadonnées qui décrivent les données et leurs relations. Elle peut également inclure des contrôles de sécurité et d’accès, permettant aux administrateurs de gérer les permissions des utilisateurs et l’accès aux données. La forme la plus courante de couches sémantiques est les data marts, mais vous pouvez également utiliser des vues matérialisées et des requêtes fédérées comme couche sémantique.
Reverse ETL
De nos jours, le Reverse ETL est un terme populaire qui désigne le processus de chargement des données d’une base de données OLAP vers un système source. Cependant, les ingénieurs de données expérimentés ont peut-être déjà effectué des tâches similaires dans le passé. Par conséquent, le Reverse ETL a gagné en importance à la fin des années 2010 et au début des années 2020 et est désormais considéré comme une responsabilité formelle de l’ingénierie des données.
Par exemple, un ingénieur de données peut extraire des données clients et de commandes d’un CRM et les stocker dans un entrepôt de données pour les utiliser dans l’entraînement d’un modèle de scoring des prospects. Les résultats du modèle sont ensuite stockés dans l’entrepôt de données. L’équipe commerciale de l’entreprise souhaite utiliser ces prospects scorés pour augmenter les ventes et a donc besoin d’y accéder. Utiliser le Reverse ETL et charger les prospects scorés dans le CRM est l’approche la plus simple pour ce produit data. Le Reverse ETL prend les données traitées du côté sortant du parcours de données et les renvoie vers les systèmes sources.

Activités Sous-jacentes du Service des Données
Dans un parcours de données, les activités sous-jacentes se terminent avec le service des données. Le service des données est votre dernière chance de mettre vos données en excellent état avant qu’elles ne parviennent aux utilisateurs finaux. Par conséquent, les ingénieurs de données doivent aborder soigneusement les activités suivantes :
- Sécurité : Les principes de sécurité restent inchangés, que l’on partage des données avec des individus ou des systèmes. Il est courant d’observer un partage indiscriminé des données sans tenir compte des contrôles d’accès ni de l’utilisation prévue des données. De telles actions peuvent entraîner des conséquences désastreuses, notamment des violations de données, entraînant de lourdes amendes, une publicité négative et des pertes d’emploi. Il est crucial de prendre au sérieux les mesures de sécurité, en particulier durant cette étape du cycle de vie, car le service présente la surface de sécurité la plus significative parmi toutes les étapes. Dans la plupart des cas, le service des données est limité à un accès en lecture seule, sauf lorsque des individus ou des processus doivent modifier des informations dans le système interrogé. Pour assurer une bonne gestion des données, il est conseillé de fournir un accès en lecture seule à des bases de données et des ensembles de données spécifiques, à moins que le rôle d’un utilisateur ne nécessite des privilèges avancés tels que l’accès en écriture ou en mise à jour. Cela peut être réalisé en regroupant les utilisateurs avec des rôles IAM particuliers, tels que les analystes ou les data scientists, ou en créant des rôles IAM personnalisés si nécessaire. Les comptes et rôles de service doivent être configurés de manière similaire pour les systèmes. De plus, il est important de limiter l’accès aux champs, lignes, colonnes et cellules d’un ensemble de données, le cas échéant, pour les utilisateurs et les systèmes. Les contrôles d’accès doivent être aussi précis que possible, et l’accès doit être révoqué dès qu’il n’est plus nécessaire. Assurez-vous que les utilisateurs ne peuvent accéder qu’à leurs données et à rien de plus.
- Gestion des données : À l’étape du service, vous êtes principalement concerné par la garantie que les personnes peuvent accéder à des données de haute qualité et fiables. Il est conseillé d’inclure à la fois des couches sémantique et de métriques2 dans votre couche de service et d’employer une modélisation rigoureuse des données qui traduit fidèlement la logique et les définitions métier. Ce faisant, vous établirez une source unique de vérité pour toutes les finalités de service, y compris l’analytique, le machine learning, le Reverse ETL et autres. Cette approche améliorera la cohérence, l’exactitude et la fiabilité de vos données, améliorant ainsi vos capacités globales de gestion des données et de prise de décision.
- DataOps : implique la surveillance des différentes étapes impliquées dans la gestion des données, notamment la qualité des données, la gouvernance et la sécurité. Il opérationnalise la gestion des données pour garantir des performances et une fiabilité optimales. Parmi les aspects cruciaux à surveiller dans DataOps figurent la santé des données et les temps d’arrêt, ainsi que la latence des systèmes servant les données, tels que les tableaux de bord et les bases de données. De plus, surveiller la qualité des données, la sécurité et les accès aux systèmes, ainsi que les versions des données et des modèles servis est essentiel. Il est également nécessaire de suivre le temps de disponibilité pour atteindre l’objectif de niveau de service (SLO) souhaité pour votre système de gestion des données. En surveillant étroitement ces facteurs, vous pouvez assurer les performances et la fiabilité optimales de votre système de gestion des données.
- Orchestration : Le service des données est la dernière étape du parcours de données, et c’est un domaine très complexe en raison de sa position en aval dans le cycle de vie. Il implique la coordination des flux de données entre plusieurs équipes, et donc, l’orchestration joue un rôle crucial dans l’automatisation et l’organisation du travail complexe. Cependant, l’orchestration n’est pas seulement un moyen d’organiser des tâches complexes, mais aussi un moyen d’assurer la livraison fluide et ponctuelle des données aux consommateurs. Pour ce faire, il est nécessaire de coordonner les différentes étapes du cycle de vie de l’ingénierie des données pour s’assurer que les données sont disponibles pour les consommateurs au moment promis. Ce faisant, vous pouvez vous assurer que votre système de gestion des données fonctionne efficacement et répond aux besoins de votre organisation.
Résumé
L’étape de service concerne les données en action. Mais quelle est l’utilisation productive des données ? Pour répondre à cette question, vous devez considérer deux éléments : quel est le cas d’usage, et qui est l’utilisateur ?
Le cas d’usage des données va bien au-delà de la consultation de rapports et de tableaux de bord. Des données de haute qualité et à fort impact attireront naturellement de nombreux cas d’usage intéressants. Mais en cherchant des cas d’usage, demandez-vous toujours : « Quelle action ces données déclencheront-elles, et qui effectuera cette action ? » avec la question de suivi appropriée : « Cette action peut-elle être automatisée ? » Dans la mesure du possible, privilégiez les cas d’usage offrant le retour sur investissement le plus élevé. Les ingénieurs de données aiment se concentrer sur les détails d’implémentation technique des systèmes qu’ils construisent en ignorant la question fondamentale de la finalité. Les ingénieurs veulent faire ce qu’ils font le mieux : concevoir des systèmes. Lorsque les ingénieurs reconnaissent la nécessité de se concentrer sur la valeur et les cas d’usage, ils deviennent beaucoup plus précieux et efficaces dans leurs rôles.
Le parcours de données se conclut logiquement à l’étape du service, et comme tous les cycles de vie, il existe une boucle de rétroaction qui se produit. Par conséquent, il est essentiel de considérer l’étape de service comme une opportunité d’apprendre ce qui fonctionne bien et ce qui peut être amélioré. Les retours des parties prenantes sont essentiels, et il est important de ne pas s’offenser lorsque des problèmes sont soulevés, car ils le seront inévitablement. Utilisez plutôt ces retours de manière constructive pour identifier les domaines d’amélioration dans ce que vous avez construit. Ce faisant, vous pouvez continuellement améliorer la qualité et l’efficacité de vos plateformes et produits data.
Maintenant que nous avons traversé le parcours de données, vous savez comment concevoir, architecturer, construire, maintenir et améliorer vos produits data. Dans la prochaine série de ce blog, j’attirerai votre attention sur quelques plateformes de données bien connues, où nous effectuerons des exercices pratiques pour ingérer, stocker, traiter et servir des données.
Références
- Reis, J. and Housley, M. Fundamentals of data engineering: Plan and build robust data systems. O’Reilly Media (2022).
- Dehghani, Z. Data Mesh: Delivering Data-Driven Value at Scale. O’Reilly Media (2022).
1. La latence devient la nouvelle panne.
2. Une couche de métriques est un outil pour maintenir et calculer la logique métier. (conceptuellement, ce concept est extrêmement similaire à la couche sémantique). Cette couche peut résider dans un outil BI ou dans un logiciel qui génère des requêtes de transformation. Un exemple concret est Data Build Tool (dbt).