
« Data & Redis » est une nouvelle série qui présente Redis en tant que plateforme de données temps réel. À travers cette série, vous apprendrez à collecter, stocker, traiter, analyser et exposer des données en temps réel à l’aide d’un large éventail d’outils fournis par Redis.
Redis est un datastore open source en mémoire, utilisé comme base de données, cache, moteur de streaming et broker de messages. Il prend en charge diverses structures de données telles que les chaînes, les hashes, les listes, les ensembles, les ensembles triés avec des requêtes de plage, les bitmaps, les hyperloglogs, les index géospatiaux et les streams. De plus, Redis offre une latence inférieure à la milliseconde avec un débit très élevé : jusqu’à 200 millions d’opérations par seconde à une échelle inférieure à la milliseconde, ce qui en fait le choix évident pour les cas d’usage temps réel.
Dans les derniers articles, j’ai expliqué que l’architecture de données est un composant clé de toute stratégie data. Il n’est donc pas surprenant que choisir la bonne architecture de données devrait être une priorité absolue pour de nombreuses organisations. Les architectures de données peuvent être classées selon la vélocité des données, et les plus populaires dans cette catégorie sont Lambda et Kappa.
Dans ce premier article, j’illustrerai comment Redis peut implémenter chacune de ces architectures grâce à la myriade d’outils et de fonctionnalités qu’il fournit. Une implémentation détaillée de chaque étape du cycle de vie des données sera publiée dans de futurs articles.
Qu’est-ce qu’une « bonne » architecture de données ?
On reconnaît une « bonne » architecture en observant la pire. Les mauvaises architectures de données sont fortement couplées, rigides, trop centralisées et utilisent les mauvais outils pour le travail, ce qui nuit au développement et à la gestion du changement. Une bonne architecture de données doit avant tout répondre aux besoins métier avec un ensemble de blocs de construction largement réutilisables, tout en respectant des bonnes pratiques bien définies (principes) et en effectuant des arbitrages appropriés. Nous nous inspirons des principes d’une « bonne » architecture de données issus de plusieurs sources, notamment le AWS Well-Architected Framework. Il se compose de six piliers :
- Efficacité des performances : la capacité d’un système à s’adapter aux changements de charge.
- Fiabilité : la capacité d’un système à se remettre des défaillances et à continuer à fonctionner.
- Optimisation des coûts : gérer les coûts pour maximiser la valeur délivrée.
- Sécurité : protéger les applications et les données contre les menaces.
- Excellence opérationnelle : les processus opérationnels qui maintiennent un système en production.
- Durabilité : minimiser les impacts environnementaux liés à l’exécution des charges de travail du système.
Dans la deuxième partie de cet article, j’évaluerai les architectures de données implémentées avec Redis au regard de ces principes.
Parce que l’architecture de données est une discipline abstraite, il est utile de raisonner par catégories d’architecture. La section suivante présente des exemples emblématiques d’architectures de données reconnues aujourd’hui. Bien que cet ensemble d’exemples ne soit pas exhaustif, l’intention est de vous exposer à certains des schémas d’architecture de données les plus courants et de donner un aperçu de l’analyse des compromis nécessaires lors de la conception d’une bonne architecture pour votre cas d’usage.
Architecture de données Lambda avec Redis
Le terme « Lambda » est dérivé du calcul lambda (λ) qui décrit une fonction s’exécutant en calcul distribué sur plusieurs nœuds en parallèle. L’architecture de données Lambda a été conçue pour fournir un système scalable, tolérant aux pannes et flexible pour traiter de grandes quantités de données, et permet un accès aux méthodes de traitement par lots et de traitement de flux de manière hybride. Elle a été développée en 2011 par Nathan Marz, le créateur d’Apache Storm, comme solution aux défis du traitement de données temps réel à grande échelle.
L’architecture Lambda est une architecture idéale lorsque vous avez une variété de charges de travail et de vélocités de données. Elle peut gérer de grands volumes de données et fournir des résultats de requêtes à faible latence, ce qui la rend adaptée aux applications d’analytique temps réel telles que les tableaux de bord et le reporting. En outre, cette architecture est utile pour le traitement par lots (par exemple, nettoyage, transformation ou agrégation de données), pour les tâches de traitement de flux (par exemple, gestion d’événements, recommandation temps réel, détection d’anomalies ou prévention de la fraude), et pour la construction de référentiels centralisés appelés « data lakes » pour stocker des informations structurées/non structurées.
La caractéristique essentielle de l’architecture Lambda est qu’elle utilise deux systèmes de traitement distincts pour gérer différents types de charges de travail. Le premier est un système de traitement par lots, qui traite les données en grands lots et stocke les résultats dans un datastore centralisé (par exemple, un entrepôt de données ou un data lake). Le second système est un système de traitement de flux, qui traite les données en temps réel à mesure qu’elles arrivent et stocke les résultats dans un datastore distribué.

Dans le diagramme ci-dessus, vous pouvez voir les principaux composants de l’architecture Lambda implémentée avec Redis. Elle comprend la couche d’ingestion, la couche batch, la couche de vitesse (ou couche de flux) et la couche de service.
-
Couche d’ingestion : Dans cette couche, les données brutes sont extraites d’une ou plusieurs sources de données, répliquées, puis ingérées dans un support de stockage d’atterrissage, par exemple une base de données Redis. Selon le volume et la vélocité des données, vous choisirez l’ingestion par lots ou l’ingestion en flux (les différences sont largement discutées ici). Redis propose différents outils permettant les deux types d’ingestion :
Premièrement, Redis Input/Output Tools (RIOT) collecte et transfère des données vers et depuis Redis en mode batch. Il se compose de plusieurs modules capables d’ingérer des données depuis des fichiers (via RIOT-File) ou depuis des bases de données relationnelles (via RIOT-DB) et de les intégrer dans Redis.
Redis Data Integration (RDI) est un produit qui aide à ingérer et exporter des données en quasi temps réel. RDI permet de mettre en miroir plusieurs types de bases de données vers Redis en utilisant le concept de Capture de Changements de Données (CDC). Le CDC surveille en permanence les journaux de transactions de la base de données et collecte les données modifiées dans Redis Enterprise sans interférer avec la charge de travail de la base de données. Il collecte et intègre également des flux d’événements provenant d’autres sources de données comme Kafka ou des brokers MQTT.
Les applications temps réel ou génératrices de flux peuvent également envoyer leur flux de données directement vers Redis en utilisant Redis Streams. Redis Streams est un système de streaming d’événements offrant jusqu’à 500 fois le débit d’Apache Kafka à une échelle inférieure à la milliseconde.
-
Couche batch : La couche de traitement par lots est conçue pour gérer de grands volumes de données historiques et stocker les résultats dans un datastore centralisé, tel qu’une base de données Redis. En fait, Redis est un datastore en mémoire, donc conserver un volume élevé de données (Big Data) peut être très coûteux. Cependant, Redis Enterprise permet la création de bases de données Redis on Flash (RoF) qui étendent la capacité mémoire avec des disques SSD, vous permettant de stocker beaucoup plus de données avec moins de ressources, réduisant ainsi les coûts de stockage globaux.
De plus, la couche batch utilise des frameworks comme Apache Spark pour un traitement efficace de l’information, lui permettant de fournir une vue complète de toutes les données disponibles. La bibliothèque Spark-Redis fournit un accès à toutes les structures de données de Redis depuis Spark sous forme de RDDs. Elle prend également en charge la lecture et l’écriture avec les DataFrames et la syntaxe Spark SQL.
-
Couche de vitesse : La couche de vitesse est conçue pour gérer des flux de données à volume élevé et fournir des vues d’informations à jour en utilisant des moteurs de traitement d’événements, tels que Redis Gears. Cette couche traite les données temps réel entrantes (par exemple, depuis Redis Data Integration) et conserve les résultats dans une file de messages comme Redis Streams ou une autre structure de données Redis spécifique requise par les consommateurs en aval (par exemple, JSON, Time Series, Bloom…). Dans cette couche, RediSearch peut être utilisé pour indexer, interroger et effectuer une recherche plein texte sur les datasets Redis. Il permet également des requêtes multi-champs, l’agrégation, la correspondance exacte de phrases, le filtrage numérique, le filtrage géographique et la recherche sémantique par similarité vectorielle en complément des requêtes textuelles.
-
Couche de service : La couche de service de l’architecture Lambda est essentielle pour fournir aux utilisateurs un accès cohérent et transparent aux données, indépendamment du système de traitement sous-jacent. De plus, elle joue un rôle important dans l’activation d’applications temps réel comme les tableaux de bord et les analyses nécessitant un accès rapide aux informations actuelles. Vous pouvez utiliser ici Redis Smart Cache, qui exploite les capacités de cache de Redis, pour mettre en cache les résultats de requêtes lentes et répétées et éviter des appels coûteux vers des systèmes backend plus lents (par exemple, bases de données, systèmes de fichiers distribués…), améliorant ainsi leurs temps de réponse.
Comme la plupart des bases de données NoSQL du marché, Redis ne vous permet pas d’interroger et d’inspecter les données avec le Langage de Requête Structuré (SQL). À la place, Redis fournit un ensemble de commandes et un langage de requête pour récupérer les structures de données natives (clé/valeur, hashes, ensembles…) et effectuer des requêtes multi-champs. Cependant, vos analystes métier sont habitués au standard de l’industrie, SQL. De nombreux outils puissants s’appuient sur SQL pour l’analytique, la création de tableaux de bord, le reporting enrichi et d’autres travaux d’intelligence métier, mais malheureusement, ils ne prennent pas en charge les commandes Redis nativement. C’est là qu’intervient Redis SQL pour permettre la fédération de requêtes au-dessus de RediSearch.
Redis SQL se présente sous deux formes : un connecteur Trino pour accéder aux données Redis depuis des applications compatibles JDBC comme Tableau et un pilote ODBC qui donne accès aux applications compatibles ODBC telles que Power BI ou même Microsoft Excel. Enfin, vous pouvez utiliser Redis comme base de données vectorielle qui stocke des vecteurs de caractéristiques et permet aux applications comme ChatGPT de les récupérer simultanément avec une faible latence.
Si les architectures Lambda offrent de nombreux avantages, comme la scalabilité, la tolérance aux pannes et la flexibilité pour gérer une large gamme de charges de travail (lots et flux), elles comportent également des inconvénients que les organisations doivent prendre en compte avant de décider de les adopter ou non. En effet, l’architecture Lambda est un système complexe qui utilise plusieurs piles technologiques pour traiter et stocker les données. De plus, la logique sous-jacente est dupliquée dans les couches batch et de vitesse pour chaque étape. Par conséquent, elle peut être difficile à configurer et à maintenir, surtout pour les organisations disposant de ressources limitées. Cependant, utiliser Redis comme pile unique pour les deux couches peut aider à réduire la complexité rencontrée dans les architectures Lambda.
Architecture de données Kappa avec Redis
En 2014, alors qu’il travaillait encore chez LinkedIn, Jay Kreps a lancé une discussion dans laquelle il soulignait certains inconvénients de l’architecture Lambda. Cette discussion a conduit la communauté Big Data vers une autre alternative utilisant moins de ressources de code.
L’idée principale derrière cela est qu’une seule pile technologique peut être utilisée pour le traitement de données temps réel et par lots. Cette architecture a été appelée Kappa. L’architecture Kappa tire son nom de la lettre grecque « Kappa » (ϰ), utilisée en mathématiques pour représenter une « boucle » ou un « cycle ». Le nom reflète l’accent mis par l’architecture sur le traitement ou le retraitement continu des données plutôt qu’une approche basée sur les lots. En son cœur, elle repose sur une architecture de streaming : les données entrantes sont d’abord stockées dans un journal de streaming d’événements, puis traitées en continu par un moteur de traitement de flux, comme Kafka, soit en temps réel, soit ingérées dans une autre base de données analytique ou application métier en utilisant divers paradigmes de communication tels que le temps réel, le quasi temps réel, le batch, le micro-batch et la requête-réponse.
L’architecture Kappa est conçue pour fournir un système scalable, tolérant aux pannes et flexible pour traiter de grandes quantités de données en temps réel. Elle est considérée comme une alternative plus simple à l’architecture Lambda car elle utilise une seule pile technologique pour gérer les charges de travail temps réel et historiques, traitant tout comme des flux. La principale motivation pour inventer l’architecture Kappa était d’éviter la maintenance de deux bases de code distinctes (pipelines) pour les couches batch et de vitesse. Cela lui permet de fournir un pipeline de traitement de données plus rationalisé et simplifié tout en offrant un accès rapide et fiable aux résultats des requêtes.

L’exigence la plus importante pour Kappa était le retraitement des données, rendant visibles les effets des changements de données sur les résultats. Par conséquent, l’architecture Kappa avec Redis est composée de seulement deux couches : la couche de flux et la couche de service. La couche de service de Kappa est assez similaire à celle de Lambda.
La couche de traitement de flux collecte, traite et stocke les données en streaming live. Cette approche élimine le besoin de systèmes de traitement par lots en utilisant un moteur de traitement de flux avancé tel que Redis Gears, Apache Flink, ou Apache Spark Streaming pour gérer des volumes élevés de flux de données et fournir un accès rapide et fiable aux résultats des requêtes. La couche de traitement de flux est divisée en deux composants : le composant d’ingestion, qui collecte les données de diverses sources, et le composant de traitement, qui traite ces données entrantes en temps réel.
- Composant d’ingestion : Cette couche collecte les données entrantes de diverses sources, telles que les journaux, les transactions de bases de données, les capteurs et les APIs. Les données sont ingérées en temps réel via Apache Kafka ou Redis Streams et stockées dans Redis pour traitement.
- Composant de traitement : Le composant de traitement de l’architecture Kappa est responsable de la gestion des flux de données à volume élevé et de la fourniture d’un accès rapide et fiable aux résultats des requêtes. Il utilise des moteurs de traitement d’événements comme Redis Gears pour traiter les données entrantes en temps réel. De plus, plusieurs intégrations Redis existent pour d’autres moteurs de traitement d’événements comme Apache Flink (Flink Redis Sink), Apache Spark Streaming (Spark-Redis), ou Apache Kafka (connecteurs Redis Kafka).
De nos jours, les données temps réel surpassent les données lentes. C’est vrai pour presque tous les cas d’usage. Néanmoins, l’architecture Kappa ne peut pas être considérée comme un substitut à l’architecture Lambda. Au contraire, elle doit être vue comme une alternative à utiliser dans les circonstances où la performance active de la couche batch n’est pas nécessaire pour respecter le niveau de qualité de service standard.
L’un des exemples les plus connus tirant parti de l’architecture Kappa avec Redis est l’architecture IoT. L’Internet des Objets (IoT) est un réseau de dispositifs physiques, de véhicules, d’appareils électroménagers et d’autres objets (alias, « choses ») équipés de capteurs, de logiciels et de connectivité qui leur permettent de collecter et d’échanger des données. Ces appareils peuvent être n’importe quoi, des appareils électroménagers intelligents aux machines industrielles en passant par les dispositifs médicaux, et ils sont tous connectés à Internet. Comme vous pouvez l’imaginer, ce type d’architecture peut générer des millions d’opérations par seconde et nécessite de les traiter avec une très faible latence. Cela fait de Redis le choix idéal pour un tel scénario.
Les données collectées par les appareils IoT peuvent être utilisées à diverses fins, comme la surveillance et le contrôle à distance des appareils, l’optimisation des processus, l’amélioration de l’efficacité et de la productivité, et l’activation de nouveaux services et modèles d’affaires. Les données IoT sont générées par des appareils qui collectent des données périodiquement ou en continu depuis l’environnement environnant et les transmettent à une destination.

Un producteur d’événements est un appareil dans cette architecture, qui n’est utile que si vous pouvez récupérer ses données. Ainsi, une passerelle IoT est un composant critique qui collecte et achemine de manière sécurisée les données des appareils vers les destinations appropriées sur internet. Les passerelles IoT fonctionnent comme des brokers d’événements et utilisent des standards et protocoles comme MQTT1 et OPC UA2 pour communiquer sur Internet. À partir de là, les événements et mesures peuvent s’écouler vers une architecture d’ingestion d’événements avec tous les défis qu’elle apporte, comme les données en retard, les disparités de structure et de schéma des données, la corruption des données et l’interruption de connexion.
Les exigences de stockage et de traitement pour un système IoT varieront considérablement selon les exigences de latence des appareils IoT. Par exemple, si des capteurs distants collectent des données scientifiques qui seront analysées ultérieurement, le stockage et le traitement par lots peuvent être suffisants. À l’inverse, si un backend système analyse constamment des données dans une solution de surveillance domestique ou d’automatisation, des réponses quasi temps réel peuvent être nécessaires.
Une architecture Kappa avec Redis serait plus adaptée dans un tel cas. Avec Redis Streams et les différents modules Redis (time-series, RediSearch…), vous pouvez répondre à ces exigences car il est conçu pour supporter un débit élevé et une latence inférieure à la milliseconde à grande échelle. De plus, Redis Data Integration dispose de connecteurs spécifiques pour MQTT et OPC UA. Ces connecteurs permettent d’obtenir des événements des passerelles IoT (par exemple, des brokers MQTT) dans Redis via Redis Streams.
Comme pour les architectures précédentes, Redis Smart Cache et Redis SQL fonctionnent comme des accélérateurs pour fournir aux utilisateurs un accès cohérent et transparent aux données IoT. Ils jouent des rôles essentiels dans l’activation d’applications temps réel comme les tableaux de bord et les analyses nécessitant un accès rapide aux informations actuelles.
Dans l’Industrie 4.0, les communications machine à machine permettent l’automatisation et la surveillance pilotée par les données qui peuvent, par exemple, identifier de manière autonome des défauts et des vulnérabilités. De grands volumes de données doivent être traités en quasi temps réel pour tous ces scénarios et rendus disponibles dans le monde entier à travers les usines et les entreprises. En utilisant Redis Enterprise, vous pouvez tirer parti d’une architecture Active-Active pour distribuer votre architecture IoT sur plusieurs centres de données via des clusters et des nœuds indépendants et géographiquement distribués. La topologie géo-distribuée Active-Active est réalisée en implémentant des CRDTs (types de données répliquées sans conflit) dans Redis Enterprise en utilisant une base de données globale s’étendant sur plusieurs clusters tout en maintenant une faible latence au sein de chaque région.
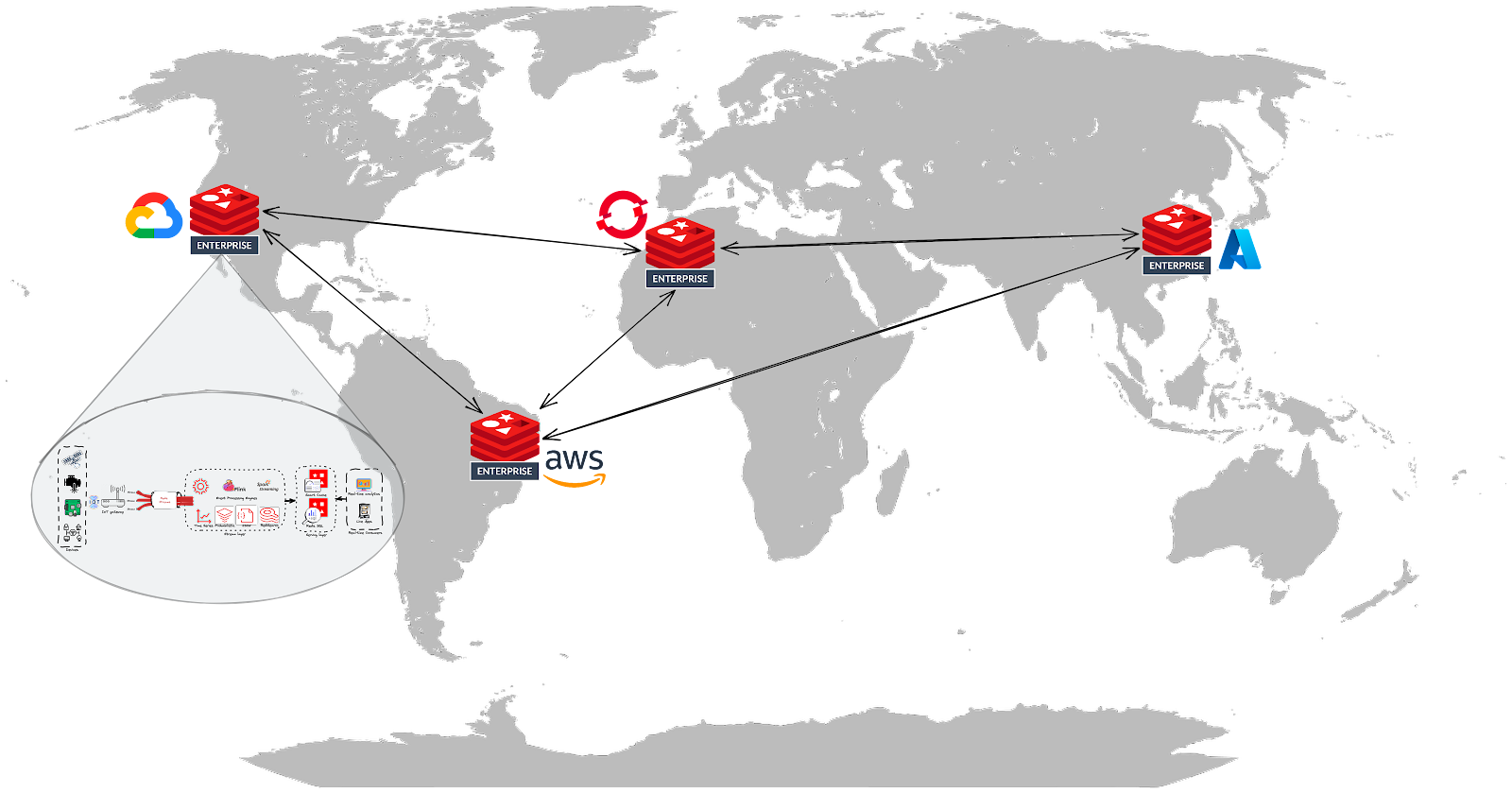
L’exigence essentielle ici est l’intégration de divers systèmes, tels que les appareils périphériques et IoT, indépendamment de l’infrastructure sous-jacente (edge, sur site, conteneurisée, ainsi que le cloud public, multi-cloud et hybride). Pour cela, Redis prend en charge plusieurs options de déploiement :
- RedisEdge : une base de données multi-modèles conçue spécifiquement pour les conditions exigeantes à la périphérie de l’Internet des Objets (IoT). Elle peut ingérer des millions d’écritures par seconde avec une latence inférieure à la milliseconde et une empreinte minimale (moins de 5 Mo), ce qui lui permet de résider facilement dans des environnements de calcul contraints. De plus, elle peut fonctionner sur divers appareils et capteurs périphériques allant du matériel ARM32 à x64 ;
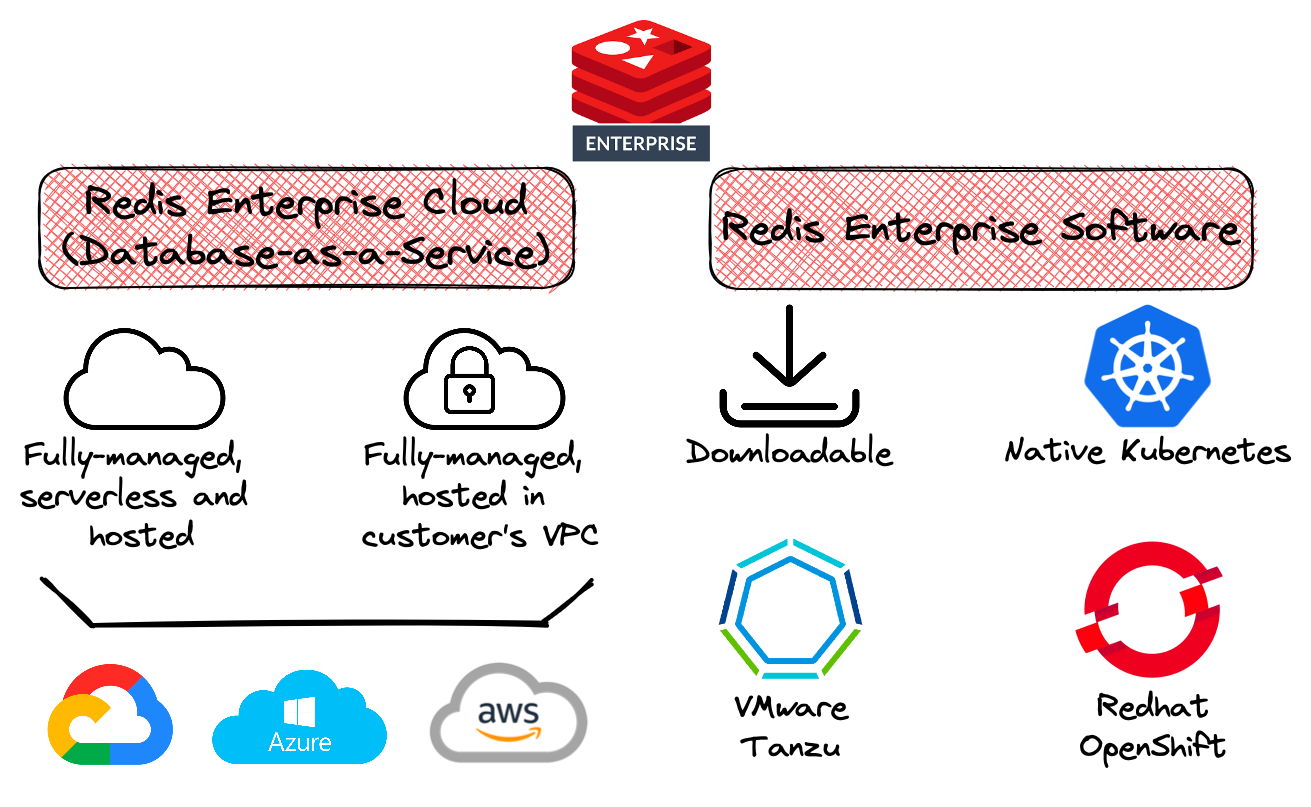
- Redis Enterprise Software (RS) : la distribution sur site de Redis Enterprise qui peut être déployée dans :
- Des environnements cloud IaaS - Amazon Web Services (AWS), Google Cloud et Microsoft Azure ;
- Des serveurs bare-metal dans un centre de données privé ;
- Des machines virtuelles (VMs), des pods Kubernetes, etc.
- Redis Enterprise Cloud (RC) : le service cloud entièrement géré basé sur Redis Enterprise et fourni sous forme de Database-as-a-Service (DBaaS).
Bien que le concept d’appareils IoT remonte à plusieurs décennies, l’adoption généralisée des smartphones a créé en une nuit une multitude d’appareils IoT. Depuis lors, diverses nouvelles catégories d’appareils IoT ont émergé, notamment les thermostats intelligents, les systèmes de divertissement automobile, les téléviseurs intelligents et les enceintes connectées. L’IoT peut révolutionner de nombreuses industries, notamment la santé, la fabrication, le transport et l’énergie. Il est passé d’un concept futuriste à un domaine majeur de l’ingénierie des données. Il est attendu qu’il devienne l’un des principaux moyens de génération et de consommation des données.
Les architectures de données avec Redis : sont-elles de « bonnes » architectures ?
Comme évoqué précédemment, le cadre AWS Well-Architected est conçu pour aider les architectes cloud à créer des architectures sécurisées, fiables, hautement performantes, rentables et durables. Ce système se compose de six piliers clés : excellence opérationnelle, sécurité, fiabilité, efficacité des performances, optimisation des coûts et durabilité, offrant aux clients un moyen cohérent d’évaluer et d’implémenter des architectures scalables. Je me suis inspiré des principes d’une « bonne » architecture de données issus du cadre AWS Well-Architected et j’ai évalué si Redis peut créer de « bonnes » architectures de données ou non.
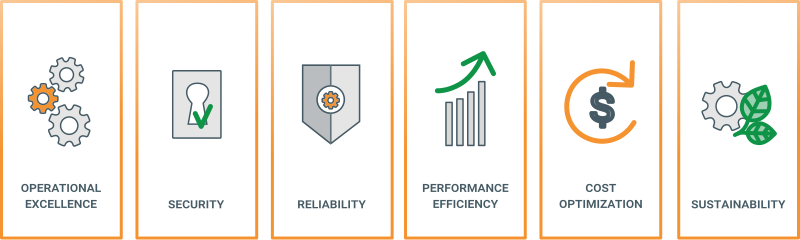
1. L’efficacité des performances représente la capacité d’un système à s’adapter aux changements de charge. Le principal défi que l’on peut observer avec de nombreuses architectures de données est la complexité opérationnelle lors du déploiement et de la gestion de leurs outils et solutions techniques. Bien souvent, il est difficile d’anticiper et de gérer les pics de demande de ces plateformes, ce qui entraîne un gaspillage d’argent sur des ressources sous-utilisées, déjà sur-provisionnées en raison d’un processus de scaling déficient. Avec Redis, l’unité de stockage principale est le shard, et il peut être mis à l’échelle verticalement et horizontalement pour former un cluster, répondant ainsi aux pics de demande de votre plateforme. De plus, tous les composants de Redis Enterprise offrent une scalabilité linéaire, ce qui en fait un bon choix pour les charges de travail à débit élevé avec une latence inférieure à la milliseconde.

2. La fiabilité : « La fiabilité est la condition préalable à la confiance. »3 Ce mantra est valable en architecture de données, surtout lorsque les utilisateurs finaux recherchent une prise de décision temps réel. La fiabilité représente la capacité d’un système à se remettre des défaillances et à continuer à fonctionner comme prévu. Le principal défi en matière de fiabilité d’une plateforme de données est la difficulté à respecter les SLAs requis. Les temps d’arrêt ou les temps de réponse lents peuvent entraîner des pertes de revenus, une réputation entachée et une perte de clients. Avec Redis Enterprise, votre architecture de données bénéficiera de l’architecture répliquée (intra-nœud, inter-nœuds, anti-affinité…) et des mécanismes de basculement implémentés dans Redis Enterprise, en plus de capacités avancées comme les réplications active-passive et active-active, qui offrent jusqu’à 99,999% de SLA de disponibilité (environ 5 minutes d’arrêt par an).
3. L’optimisation des coûts représente la gestion des coûts pour maximiser la valeur délivrée. Redis Enterprise implémente une architecture « shared-nothing » qui permet à diverses instances Redis de fonctionner à l’intérieur d’un nœud sans aucune connaissance les unes des autres et donc isolées pour éviter qu’elles ne s’affectent mutuellement. Par conséquent, Redis Enterprise offre une suppression du problème de voisin bruyant, minimisant la consommation CPU des applications inactives. De plus, un autre avantage de cette multi-location est la possibilité de partager les capacités d’infrastructure entre plusieurs bases de données, réduisant ainsi le Coût Total de Possession (TCO) de votre plateforme de données (réduction de 30% à 70% des coûts).
Un autre levier qui optimise le coût de votre architecture de données est le tiering des données. Comme vous le savez, Redis est un datastore en mémoire, et l’utilisation de la mémoire (RAM) pour stocker des volumes significatifs de données est très coûteuse. Cependant, Redis Enterprise vous permet d’optimiser vos coûts en effectuant du tiering de données : en conservant uniquement les données chaudes (fréquemment accédées) et les clés en mémoire, et en plaçant les données froides/tièdes (moins fréquemment accédées) sur un disque flash (par exemple, un disque SSD ou un stockage NVMe). Cela peut réduire le coût jusqu’à 80% tout en préservant un débit élevé et une faible latence.
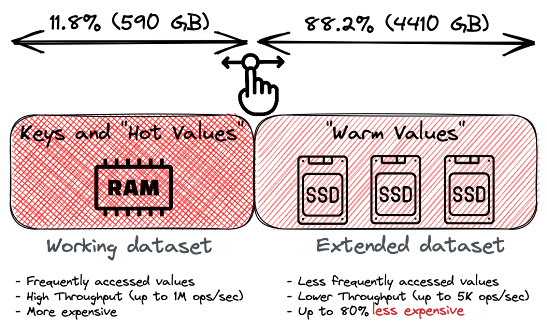 Tiering de données Redis.
Tiering de données Redis.
4. La sécurité représente la protection de la plateforme de données contre les menaces. Bien que la sécurité soit souvent perçue comme un frein au travail des ingénieurs données, ils doivent reconnaître qu’elle est en réalité un facteur essentiel. En implémentant des mesures de sécurité robustes (chiffrement, TLS mutuel, CA de confiance…) pour les données au repos et en mouvement, ainsi qu’un contrôle d’accès granulaire aux données, une architecture de données utilisant Redis peut permettre un partage et une consommation plus larges des données au sein d’une entreprise, conduisant à une augmentation significative de la valeur des données. De plus, le principe du moindre privilège est implémenté via des Listes de Contrôle d’Accès (ACL) et un Contrôle d’Accès Basé sur les Rôles (RBAC), ce qui signifie que l’accès aux données n’est accordé proportionnellement qu’à ceux qui en ont besoin.
5. L’excellence opérationnelle est la capacité à maintenir un système en production de manière optimale. Premièrement, Redis Enterprise fournit de multiples intégrations pour permettre la surveillance opérationnelle de votre plateforme de données, de l’infrastructure sous-jacente et des accès aux données (piste d’audit). Ainsi, vous pouvez obtenir de la visibilité et prendre les mesures appropriées.
6. La durabilité tend à minimiser l’empreinte environnementale de votre plateforme de données. Redis Enterprise prend en charge plusieurs options de déploiement qui vous permettent de choisir les technologies et configurations de stockage qui soutiennent le mieux la valeur métier de vos données (multi-cloud, cloud hybride). De plus, des fonctionnalités comme la multi-location et le tiering de données peuvent réduire l’infrastructure provisionnée nécessaire pour supporter votre plateforme de données et les ressources nécessaires pour l’utiliser. Par conséquent, l’utilisation de Redis contribue à réduire l’empreinte environnementale de votre plateforme de données.
Résumé
Dans cet article, je présente Redis en tant que plateforme de données temps réel qui fournit une implémentation pour les architectures de données les plus populaires grâce à la myriade d’outils et de fonctionnalités qu’il fournit. Mais d’abord, j’ai expliqué comment les données rapides surpassent les données lentes et comment Redis, en tant que datastore en mémoire, est bien adapté à cet objectif.
Ensuite, l’article survole quelques cas d’usage de Redis, comme l’implémentation d’un moteur de recommandation temps réel, la gestion de l’analytique temps réel, la construction d’une application conversationnelle (comme chatGPT), et la réponse aux exigences de l’Industrie 4.0 avec une architecture IoT. Dans les articles suivants, j’entrerai dans des explications détaillées sur la façon dont Redis peut être utilisé dans chacun de ces scénarios et pour chaque étape du parcours des données.
Globalement, cet article fournit un aperçu complet de la manière dont Redis peut être utilisé comme plateforme de données temps réel et des diverses architectures de données qui peuvent être implémentées avec Redis. J’ai ensuite évalué ces architectures au regard du cadre AWS Well-Architected pour déterminer si celles-ci constituent de « bonnes » architectures de données. Le résultat de cette évaluation fournit des informations précieuses pour construire des plateformes de données bien architecturées.
Références
- Akidau T. et al., The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Proceedings of the VLDB Endowment, vol. 8 (2015), pp. 1792-1803.
- Reis, J. and Housley M. Fundamentals of data engineering: Plan and build robust data systems. O’Reilly Media (2022).
- “Lambda vs. Kappa Architecture. A Guide to Choosing the Right Data Processing Architecture for Your Needs”, Dorota Owczarek.
- “A brief introduction to two data processing architectures: Lambda and Kappa for Big Data”, Iman Samizadeh, Ph.D.
- “What Is Lambda Architecture?”, Hazelcast Glosary.
- “What Is the Kappa Architecture?”, Hazelcast Glosary.
- “Kappa Architecture is Mainstream Replacing Lambda”, Kai Waehner.
- “Data processing architectures – Lambda and Kappa”, Julien Forgeat.
1. Le protocole MQTT (Message Queuing Telemetry Transport) est un protocole de messagerie standard OASIS pour l’Internet des Objets (IoT), construit au-dessus de TCP/IP pour les appareils contraints et les réseaux peu fiables. Il est conçu comme un transport de messagerie publication/abonnement extrêmement léger, idéal pour connecter des appareils distants avec une empreinte de code réduite et une bande passante réseau minimale. MQTT est aujourd’hui le standard de la messagerie IoT, en particulier pour l’Industrie 4.0.
2. OPC Unified Architecture (OPC UA) est également un protocole de communication machine à machine utilisé pour l’automatisation industrielle et développé par la Fondation OPC.
3. Wolfgang Schäuble - juriste, homme politique et homme d’État allemand dont la carrière politique s’étend sur plus de cinq décennies.