
« Data & Redis » est une série qui présente Redis en tant que plateforme de données temps réel. À travers cette série, vous apprendrez à collecter, stocker, traiter, analyser et exposer des données en temps réel à l’aide d’un large éventail d’outils fournis par Redis. Redis est un datastore open source en mémoire, utilisé comme base de données, cache, moteur de streaming et broker de messages. Il prend en charge diverses structures de données telles que les chaînes, les hashes, les listes, les ensembles, les ensembles triés avec des requêtes de plage, les bitmaps, les hyperloglogs, les index géospatiaux et les streams. De plus, Redis offre une latence inférieure à la milliseconde avec un débit très élevé : jusqu’à 200 millions d’opérations par seconde à une échelle inférieure à la milliseconde, ce qui en fait le choix évident pour les cas d’usage temps réel.
Dans cet article, j’illustrerai l’ingestion et l’intégration de données à l’aide de Redis et de la myriade d’outils qu’il fournit. Comme vous l’avez vu précédemment, l’ingestion de données est la première étape du cycle de vie des données. C’est là que les données sont collectées depuis diverses sources internes comme les bases de données, les CRM, les ERP, les systèmes legacy, et des sources externes telles que les enquêtes et les fournisseurs tiers. Il s’agit d’une étape importante car elle garantit le bon fonctionnement des étapes suivantes dans le cycle de vie des données.
Dans cette étape, les données brutes sont extraites d’une ou plusieurs sources de données, répliquées, puis ingérées dans un support de stockage d’atterrissage, Redis par exemple. Nous avons vu que la plupart des outils d’ingestion peuvent gérer un volume élevé de données avec une large gamme de formats (structurés, non structurés…), mais ils diffèrent dans la manière dont ils gèrent la vélocité des données. On distingue généralement trois catégories principales d’outils d’ingestion de données : l’ingestion par lots, l’ingestion temps réel ou en flux, et l’ingestion hybride. Avec Redis, nous verrons les différents outils d’ingestion de données qui forment l’écosystème Redis et comment ils peuvent répondre aux différentes catégories d’ingestion de données.
Prérequis
1 - Créer une base de données Redis
Vous devez installer et configurer quelques éléments pour cet article. D’abord, vous devez préparer le support de stockage d’atterrissage, qui peut être un Redis open source (OSS) ou un cluster Redis Enterprise. Ce support de stockage sera l’infrastructure cible pour les données acquises dans cette étape. Vous pouvez installer Redis OSS en suivant les instructions ici, ou vous pouvez utiliser ce projet pour créer un cluster Redis Enterprise dans le fournisseur cloud de votre choix.
Une fois le cluster Redis Enterprise créé, vous devez créer une base de données cible qui contiendra les données ingérées. Redis Enterprise Software vous permet de créer et distribuer des bases de données sur un cluster de nœuds. Pour créer une nouvelle base de données, suivez les instructions ici. Pour la suite de l’article, nous supposons que pour RIOT, vous utilisez une base de données avec le point de terminaison : redis-12000.cluster.redis-ingest.demo.redislabs.com:12000. Pour Redis Data Integration, vous avez besoin de deux bases de données : la base de données de configuration exposée sur redis-13000.cluster.redis-ingest.demo.redislabs.com:13000 et la base de données cible sur : redis-14000.cluster.redis-ingest.demo.redislabs.com:14000
2 - Installer les outils RIOT
Installons maintenant l’outil RIOT-File.
RIOT-File peut être installé de différentes manières selon votre environnement et vos préférences. Si vous souhaitez l’installer sur MacOS, vous pouvez utiliser Homebrew avec la commande :
brew install redis-developer/tap/riot-file
Vous pouvez également télécharger la dernière version, la décompresser et la copier à l’emplacement souhaité. Lancez ensuite le script bin/riot-file.
Ou vous pouvez simplement exécuter la dernière image docker :
docker run fieldengineering/riot-file [OPTIONS] [COMMAND]
Vous devez ensuite installer l’outil RIOT-DB via Homebrew sur MacOS :
brew install redis-developer/tap/riot-db
Ou en exécutant la dernière image docker :
docker run fieldengineering/riot-db [OPTIONS] [COMMAND]
3 - Installer Redis Data Integration (RDI)
Pour la deuxième partie de cet article, vous devrez installer Redis Data Integration (RDI). L’installation de Redis Data Integration se fait via le CLI RDI. Le CLI doit avoir un accès réseau à l’API du cluster Redis Enterprise (port 9443 par défaut). Vous devez d’abord télécharger le package hors ligne RDI :
UBUNTU20.04
wget https://qa-onprem.s3.amazonaws.com/redis-di/latest/redis-di-offline-ubuntu20.04-latest.tar.gz -O /tmp/redis-di-offline.tar.gz
UBUNTU18.04
wget https://qa-onprem.s3.amazonaws.com/redis-di/latest/redis-di-offline-ubuntu18.04-latest.tar.gz -O /tmp/redis-di-offline.tar.gz
RHEL8
wget https://qa-onprem.s3.amazonaws.com/redis-di/latest/redis-di-offline-rhel8-latest.tar.gz -O /tmp/redis-di-offline.tar.gz
RHEL7
wget https://qa-onprem.s3.amazonaws.com/redis-di/latest/redis-di-offline-rhel7-latest.tar.gz -O /tmp/redis-di-offline.tar.gz
Copiez et décompressez ensuite le fichier redis-di-offline.tar.gz téléchargé dans le nœud maître de votre cluster Redis sous le répertoire /tmp :
tar xvf /tmp/redis-di-offline.tar.gz -C /tmp
Basculez l’utilisateur courant vers l’utilisateur avec lequel le cluster a été créé (généralement redislabs ou ubuntu). Installez RedisGears sur le cluster. S’il est manquant, suivez ce guide pour l’installer.
curl -s https://redismodules.s3.amazonaws.com/redisgears/redisgears.Linux-ubuntu20.04-x86_64.1.2.5.zip -o /tmp/redis-gears.zip
curl -v -k -s -u "<REDIS_CLUSTER_USER>:<REDIS_CLUSTER_PASSWORD>" -F "module=@/tmp/redis-gears.zip" https://<REDIS_CLUSTER_HOST>:9443/v2/modules
Installez ensuite le CLI RDI en décompressant redis-di.tar.gz dans le répertoire /usr/local/bin/ :
sudo tar xvf /tmp/redis-di-offline/redis-di-cli/redis-di.tar.gz -C /usr/local/bin/
Exécutez la commande create pour configurer une nouvelle instance de base de données Redis Data Integration au sein d’un cluster Redis Enterprise existant. Cette base de données est différente de la base de données cible qui contient les données transformées. La base de données RDI est un petit datastore qui ne contient que des configurations et des statistiques sur les données traitées. Créons-en une et exposons-la sur le port 13000 :
redis-di create --silent --cluster-host <CLUSTER_HOST> --cluster-user <CLUSTER_USER> --cluster-password <CLUSTER_PASSWORD> --rdi-port <RDI_PORT> --rdi-password <RDI_PASSWORD> --rdi-memory 512
Enfin, exécutez la commande scaffold pour générer les fichiers de configuration pour Redis Data Integration et le connecteur Debezium Redis Sink :
redis-di scaffold --db-type <cassandra|mysql|oracle|postgresql|sqlserver> --dir <PATH_TO_DIR>
Dans cet article, nous allons capturer une base de données SQL Server, choisissez donc (sqlserver). Les fichiers suivants seront créés dans le répertoire fourni :
├── debezium
│ └── application.properties
├── jobs
│ └── README.md
└── config.yaml
config.yaml- fichier de configuration Redis Data Integration (définitions de la base de données cible, de l’applier, etc.)debezium/application.properties- fichier de configuration du serveur Debeziumjobs- jobs de transformation des données, lire ici
Pour utiliser Debezium comme conteneur docker, téléchargez l’image Debezium :
wget https://qa-onprem.s3.amazonaws.com/redis-di/debezium/debezium_server_2.1.1.Final_offline.tar.gz -O /tmp/debezium_server.tar.gz
et chargez-la en tant qu’image docker. Assurez-vous que vous avez déjà docker installé sur votre machine.
docker load < /tmp/debezium_server.tar.gz
Taguez ensuite l’image :
docker tag debezium/server:2.1.1.Final_offline debezium/server:2.1.1.Final
docker tag debezium/server:2.1.1.Final_offline debezium/server:latest
Pour le déploiement non conteneurisé, vous devez installer Java 11 ou Java 17. Téléchargez ensuite Debezium Server 2.1.1.Final depuis ici.
Décompressez Debezium Server :
tar xvfz debezium-server-dist-2.1.1.Final.tar.gz
Copiez le fichier application.properties généré par scaffold (créé par la commande scaffold) dans le répertoire debezium-server/conf extrait. Vérifiez que vous avez configuré ce fichier selon ces instructions.
Si vous utilisez Oracle comme base de données source, notez que Debezium Server n’inclut pas le pilote JDBC Oracle. Vous devez le télécharger et le placer dans le répertoire debezium-server/lib :
cd debezium-server/lib
wget https://repo1.maven.org/maven2/com/oracle/database/jdbc/ojdbc8/21.1.0.0/ojdbc8-21.1.0.0.jar
Démarrez ensuite Debezium Server depuis le répertoire debezium-server :
./run.sh
Ingestion par lots avec RIOT
L’ingestion par lots est le processus de collecte et de transfert de données par lots selon des intervalles planifiés. Redis Input/Output Tools (RIOT) est une série d’utilitaires conçus pour vous aider à faire entrer et sortir des données de Redis en mode batch. Il se compose de plusieurs modules capables d’ingérer des données depuis des fichiers (RIOT-File) ou des bases de données relationnelles vers Redis (RIOT-DB). Il peut également migrer des données depuis/vers Redis (RIOT-Redis). RIOT prend en charge Redis open source (OSS) et Redis Enterprise en déploiement standalone ou en cluster.
L’outil RIOT lit un nombre fixe d’enregistrements (chunks batch), les traite et les écrit en une fois. Le cycle se répète ensuite jusqu’à ce qu’il n’y ait plus de données sur la source. La taille de batch par défaut est de 50, ce qui signifie qu’une étape d’exécution lit 50 éléments à la fois depuis la source, les traite, et les écrit enfin vers la cible. Si la cible est Redis, l’écriture se fait en une seule commande pipeline pour minimiser le nombre d’allers-retours vers le serveur. Vous pouvez modifier la taille de batch (et donc la taille du pipeline) en utilisant l’option --batch. La taille de batch optimale pour le débit dépend de quelques facteurs, comme la taille des enregistrements et les types de commandes (voir ici pour plus de détails).
RIOT peut implémenter des processeurs pour effectuer des transformations personnalisées sur les données ingérées et appliquer des filtres basés sur des expressions régulières avant d’écrire les données dans le support de stockage d’atterrissage.
Il est possible de paralléliser le traitement en utilisant plusieurs threads avec l’option --threads. Dans cette configuration, chaque chunk d’éléments est lu, traité et écrit dans un thread d’exécution séparé. Cela diffère du partitionnement, où plusieurs lecteurs liraient des éléments (voir Redis Data Integration). Ici, un seul lecteur est accédé depuis plusieurs threads.

1 - Ingestion de fichiers plats avec RIOT-File
RIOT-File fournit des commandes pour lire depuis des fichiers et écrire vers Redis. Il prend en charge divers formats de fichiers plats délimités : CSV, TSV, PSV, ou des fichiers à largeur fixe. RIOT-File peut également importer des fichiers aux formats JSON ou XML.
Pour ingérer des données depuis des fichiers plats vers une base de données Redis, vous devez exécuter la commande d’import :
riot-file -h <host> -p <port> import FILE... [REDIS COMMAND...]
La commande d’import lit depuis des fichiers et écrit vers Redis. Les chemins des fichiers peuvent être absolus ou sous forme d’URL. De plus, les chemins peuvent inclure des motifs avec des caractères génériques (par exemple, file_*.csv). En utilisant l’URL objet, vous pouvez également ingérer des objets depuis AWS S3 ou le service de stockage GCP.
RIOT-File tentera de déterminer le type de fichier à partir de son extension (par exemple, .csv ou .json), mais vous pouvez le spécifier explicitement en utilisant l’option --filetype.
Pour les formats de fichiers plats (délimités et à longueur fixe), vous pouvez utiliser l’option --header pour extraire automatiquement les noms des champs depuis la première ligne du fichier. Sinon, vous pouvez spécifier les noms des champs en utilisant l’option –fields.
Le caractère délimiteur par défaut est une virgule (,). Cependant, il peut être personnalisé en utilisant l’option --delimiter.
Considérons ce fichier CSV :
| AirportID | Name | City | Country | IATA | ICAO | Latitude | Longitude | Altitude | Timezone | DST | Tz | Type | Source |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Goroka Airport | Goroka | Papua New Guinea | GKA | AYGA | -6.081689834590001 | 145.391998291 | 5282 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 2 | Madang Airport | Madang | Papua New Guinea | MAG | AYMD | -5.20707988739 | 145.789001465 | 20 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 3 | Mount Hagen Kagamuga Airport | Mount Hagen | Papua New Guinea | HGU | AYMH | -5.826789855957031 | 144.29600524902344 | 5388 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 4 | Nadzab Airport | Nadzab | Papua New Guinea | LAE | AYNZ | -6.569803 | 146.725977 | 239 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 5 | Port Moresby Jacksons International Airport | Port Moresby | Papua New Guinea | POM | AYPY | -9.443380355834961 | 147.22000122070312 | 146 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 6 | Wewak International Airport | Wewak | Papua New Guinea | WWK | AYWK | -3.58383011818 | 143.669006348 | 19 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
La commande suivante importe ce fichier CSV dans Redis en tant qu’objet JSON avec airport comme préfixe de clé et AirportID comme clé primaire.
riot-file -h redis-12000.cluster.redis-ingest.demo.redislabs.com -p 12000 import https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/airport.csv --header json.set --keyspace airport --keys AirportID

Vous pouvez observer que le fichier CSV contient des coordonnées géographiques (longitudes et latitudes). Vous pouvez ainsi tirer parti des index géospatiaux Redis qui vous permettent de stocker des coordonnées et d’effectuer des recherches. Cette structure de données est utile pour trouver des points proches dans un rayon ou une boîte englobante donnés. Par exemple, cette commande importe le fichier CSV dans un geo set nommé airportgeo avec AirportID comme membre :
riot-file -h redis-12000.cluster.redis-ingest.demo.redislabs.com -p 12000 import https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/airport.csv --header geoadd --keyspace airportgeo --members AirportID --lon Longitude --lat Latitude
Vous pouvez utiliser une expression régulière pour extraire des motifs depuis les champs source et ne conserver que les enregistrements correspondant à une expression booléenne SpEL. Par exemple, ce filtre ne conservera que les aéroports canadiens. C’est-à-dire où le champ Country correspond à Canada.
riot-file -h redis-12000.cluster.redis-ingest.demo.redislabs.com -p 12000 import https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/airport.csv --header --filter "Country matches 'Canada'" hset --keyspace airport:canada --keys AirportID

Vous pouvez également effectuer des transformations lors de l’ingestion de données avec RIOT. Cette fonctionnalité vous permet de créer/mettre à jour/supprimer des champs en utilisant le Spring Expression Language (SpEL). Par exemple, vous pouvez ajouter un nouveau champ avec field1='foo', standardiser les valeurs d’un champ pour convertir la température de Fahrenheit en Celsius temp=(temp-32)*5/9, fusionner deux champs en un seul et supprimer les anciens champs name=remove(first).concat(remove(last)), ou simplement supprimer les champs que vous n’utiliserez pas (par exemple, field2=null).
Le processeur de transformation expose également des fonctions et des variables accessibles avec le préfixe #, comme l’analyseur de dates #date, obtenir le numéro de séquence de l’élément généré avec #index, et vous pouvez invoquer des commandes Redis en utilisant #redis.
2 - Ingestion de tables relationnelles avec RIOT-DB
RIOT-DB inclut plusieurs pilotes JDBC pour lire depuis les SGBDR les plus courants (Oracle, IBM DB2, SQL Server, MySQL, PostgreSQL et SQLite). De plus, RIOT-DB est extensible ; il peut lire depuis d’autres bases de données en ajoutant leurs pilotes JDBC correspondants dans le répertoire lib de l’outil.
Pour ingérer des données depuis des bases de données relationnelles vers une base de données Redis, vous devez exécuter la commande d’import :
riot-db -h <host> -p <port> import --url <jdbc url> SQL [REDIS COMMAND...]
La commande d’import lit depuis les tables SGBDR en utilisant des requêtes SQL et écrit vers Redis. L’option --url spécifie la chaîne de connexion JDBC à la base de données source, et la requête SQL définit la table et la condition de filtrage côté source. Vous pouvez également utiliser des fonctions d’agrégation SQL pour traiter et retourner des champs transformés. Vous pouvez également utiliser les processeurs RIOT (similaires à RIOT-File) pour effectuer des transformations et la logique de filtrage côté RIOT.
Considérons une base de données MySQL contenant trois tables, une pour les continents, une autre pour les pays du monde, et la dernière contenant les devises.
En supposant que le point de terminaison de la base de données est riot-db.cpqlgenz3kvv.eu-west-3.rds.amazonaws.com:3306, la commande suivante importe la table des pays dans Redis en tant que hashes en utilisant country comme préfixe de clé et code comme clé primaire.
riot-db -h redis-12000.cluster.redis-ingest.demo.redislabs.com -p 12000 import "SELECT * FROM countries" --url "jdbc:mysql://riot-db.cpqlgenz3kvv.eu-west-3.rds.amazonaws.com:3306/geography" --username admin --password riot-password hset --keyspace country --keys code

Le principal avantage d’utiliser des requêtes SQL dans le chargement est la possibilité de créer des structures personnalisées qui joignent plusieurs tables et filtrent selon un champ spécifique. Par exemple, la commande suivante importe uniquement les pays africains avec le nom complet de la devise de chaque pays. Le résultat est ingéré dans Redis en tant qu’objets JSON en utilisant africa comme préfixe de clé et code comme clé primaire.
riot-db -h redis-12000.cluster.redis-ingest.demo.redislabs.com -p 12000 import "SELECT countries.code, countries.name, countries.capital, continents.continent_name, currencies.currency_name FROM countries JOIN continents on countries.continent_code = continents.continent_code JOIN currencies on countries.currency = currencies.currency_code WHERE continents.continent_name like 'Africa'" --url "jdbc:mysql://riot-db.cpqlgenz3kvv.eu-west-3.rds.amazonaws.com:3306/geography" --username admin --password riot-password json.set --keyspace africa --keys code

Ingestion en flux avec Redis Data Integration (RDI)
L’ingestion temps réel ou en flux est essentielle pour permettre aux organisations de répondre rapidement aux nouvelles informations dans des cas d’usage sensibles au temps, tels que le trading boursier ou la surveillance de capteurs. L’acquisition de données temps réel est vitale lors de la prise de décisions opérationnelles rapides ou de l’action sur des informations fraîches.
Redis Data Integration (RDI) est un produit qui aide les utilisateurs de Redis Enterprise à ingérer et exporter des données en quasi temps réel afin que Redis devienne partie intégrante de leur fabric de données sans efforts d’intégration supplémentaires. RDI peut mettre en miroir plusieurs types de bases de données vers Redis en utilisant le concept de Capture de Changements de Données (CDC). Le CDC surveille en permanence les journaux de transactions de la base de données et déplace les données modifiées en tant que flux sans interférer avec la charge de travail de la base de données. Redis Data Integration est un outil d’ingestion de données qui collecte la liste des événements qui ont modifié les données d’un système OLTP sur une période donnée et les écrit dans Redis Enterprise.
Dans les systèmes OLTP (Traitement de Transactions en Ligne), les données sont accédées et modifiées simultanément par plusieurs transactions, et la base de données passe d’un état cohérent à un autre. Un système OLTP affiche toujours le dernier état de vos données, facilitant les charges de travail qui nécessitent des garanties de cohérence des données en quasi temps réel. Tous ces états de base de données sont conservés dans le journal de transactions (alias journal de rétablissement ou Write-Ahead Log), qui stocke les modifications basées sur les lignes.
Par conséquent, pour capturer les changements dans une base de données relationnelle, il suffit de scanner le journal de transactions et d’en extraire les événements de changement. Historiquement, chaque SGBDR utilisait sa propre méthode de décodage du journal de transactions sous-jacent :
- Oracle propose GoldenGate (LogMiner)
- SQL Server propose la prise en charge intégrée du CDC
- PostgreSQL avec son Write-Ahead Log (WAL)
- MySQL, qui expose un journal binaire (BinLog) pouvant être capturé par diverses solutions tierces, comme LinkedIn’s DataBus.
Mais il y a un nouvel outil ici ! Debezium est un nouveau projet open source développé par RedHat, qui offre des connecteurs pour Oracle, MySQL, PostgreSQL, et même MongoDB. Debezium fournit un connecteur Sink Redis qui alimente Redis Data Integration (RDI). Parce qu’il n’extrait pas seulement les événements CDC mais peut les propager vers RedisStreams1, qui sert de colonne vertébrale pour tous les messages devant être échangés entre les différentes étapes de l’architecture de données.

Avec Redis Data Integration (RDI), les données sont extraites de la base de données source à l’aide de connecteurs Debezium. Les données sont ensuite chargées dans une instance de base de données Redis qui conserve les données dans RedisStreams aux côtés des métadonnées requises. Les données peuvent ensuite être transformées à l’aide de recettes RedisGears ou d’Apache Spark via le connecteur Spark-Redis.
Redis Data Integration (RDI) peut être considéré comme un outil d’ingestion de données hybride car il effectue une synchronisation initiale - où un snapshot de l’ensemble de la base de données ou d’un sous-ensemble de tables sélectionnées est utilisé comme référence. Ensuite, toutes les données sont ingérées en tant que chunk batch streamé vers Redis Data Integration, puis transformées et écrites dans la base de données Redis cible. Il effectue ensuite la capture en direct - où les changements de données qui se produisent après le snapshot de référence sont capturés et streamés vers Redis Data Integration, où ils sont transformés et écrits dans la cible.
Considérons une base de données SQL Server FO (Finance & Opérations) qui contient une table de grand livre général. Un grand livre général représente le système d’enregistrement des données financières d’une entreprise, avec des enregistrements de comptes débiteurs et créditeurs. Il fournit un enregistrement de chaque transaction financière qui se produit au cours de la vie d’une entreprise en exploitation et contient des informations sur les comptes nécessaires pour préparer les états financiers de l’entreprise.
| ID | JOURNALNUM | SPLTRMAGSUM | AMOUNTMSTSECOND | TAXREFID | DIMENSION6_ | SPL_JOBNUMBER | SPL_JOBDATE | JOURNALIZESEQNUM | CREATEDTRANSACTIONID | DEL_CREATEDTIME | DIMENSION | QTY | POSTING | OPERATIONSTAX | DIMENSION4_ | REASONREFRECID | DIMENSION2_ | DATAAREAID | CREATEDBY | SPL_LEDGERACCMIRRORING_TR | TRANSTYPE | DOCUMENTDATE | TRANSDATE | MODIFIEDBY | CREDITING | SPL_BALANCINGID | BONDBATCHTRANS_RU | RECID | MODIFIEDDATETIME | AMOUNTCUR | CURRENCYCODE | RECVERSION | CORRECT | ACCOUNTNUM | AMOUNTMST | CREATEDDATETIME | PERIODCODE | ALLOCATELEVEL | FURTHERPOSTINGTYPE | DIMENSION5_ | VOUCHER | DIMENSION3_ | ACKNOWLEDGEMENTDATE | EUROTRIANGULATION |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | GJN0055555 | 0 | 0.000000000000 | 0 | 8385 | NULL | 1900-01-01 00:00:00.0000000 | 0 | 5664245147 | 48243 | NL03PC301 | 0.000000000000 | 31 | 0 | x | 0 | x | nl03 | ronal | 0 | 15 | 1900-01-01 00:00:00.0000000 | 2020-11-02 00:00:00.0000000 | ronal | 1 | 0 | 0 | 5733875370 | 2020-11-03 12:24:03.0000000 | -1.773.990.000.000.000 | EUR | 1 | 0 | 240100 | -1.773.990.000.000.000 | 2020-11-03 12:24:03.0000000 | 1 | 0 | 0 | x | RPM000134685 | x | 2020-11-02 00:00:00.0000000 | 0 |
| 2 | GJN0154431 | 0 | 0.000000000000 | 0 | 90000211 | SSHAS639739 | 1900-01-01 00:00:00.0000000 | 0 | 5664300488 | 50808 | IT08PC330 | 0.000000000000 | 14 | 0 | MARI | 0 | 34230 | IT08 | arian | 0 | 0 | 2020-11-30 00:00:00.0000000 | 2020-11-30 00:00:00.0000000 | arian | 0 | 0 | 0 | 5734845976 | 2020-12-02 13:06:48.0000000 | 521.550.000.000.000 | EUR | 1 | 0 | 732000 | 521.550.000.000.000 | 2020-12-02 13:06:48.0000000 | 1 | 0 | 0 | GENCAR | GOI20000050977 | MISC | 2020-11-30 00:00:00.0000000 | 0 |
| 3 | GJN0055690 | 0 | 0.000000000000 | 0 | NLNEVATRHGV | NULL | 1900-01-01 00:00:00.0000000 | 0 | 5664258998 | 38650 | NL03PC301 | 0.000000000000 | 41 | 0 | x | 0 | x | nl03 | vanja | 0 | 15 | 1900-01-01 00:00:00.0000000 | 2020-11-13 00:00:00.0000000 | vanja | 0 | 0 | 0 | 5734092101 | 2020-11-11 09:44:10.0000000 | 2.667.090.000.000.000 | EUR | 1 | 0 | 260100 | 2.667.090.000.000.000 | 2020-11-11 09:44:10.0000000 | 1 | 0 | 0 | x | PPM000086183 | x | 2020-11-13 00:00:00.0000000 | 0 |
| 4 | GJN0152885 | 0 | 0.000000000000 | 1 | ITPOGRPML | SNGBS235260 | 2020-09-21 00:00:00.0000000 | 0 | 5664261485 | 42195 | IT08PC330 | 0.000000000000 | 14 | 0 | MARI | 0 | 34230 | it08 | gius1 | 0 | 0 | 2020-11-11 00:00:00.0000000 | 2020-11-11 00:00:00.0000000 | gius1 | 1 | 0 | 0 | 5734121975 | 2020-11-12 10:43:15.0000000 | -188.550.000.000.000 | EUR | 1 | 0 | 801100 | -188.550.000.000.000 | 2020-11-12 10:43:15.0000000 | 1 | 0 | 0 | GENCAR | RTI20000049694 | MISC | 2020-11-11 00:00:00.0000000 | 0 |
| 5 | GJN0152220 | 0 | 0.000000000000 | 0 | ITESAOTEFLR | SHKGA176733 | 1900-01-01 00:00:00.0000000 | 0 | 5664242642 | 18523 | IT08PC331 | 0.000000000000 | 14 | 0 | x | 0 | x | it08 | arian | 0 | 0 | 1900-01-01 00:00:00.0000000 | 2020-11-01 00:00:00.0000000 | arian | 1 | 0 | 0 | 5733849435 | 2020-11-03 04:08:43.0000000 | -56.690.000.000.000 | EUR | 1 | 0 | 245000 | -56.690.000.000.000 | 2020-11-03 04:08:43.0000000 | 1 | 0 | 0 | x | GOI20000037656 | x | 2020-11-01 00:00:00.0000000 | 0 |
Nous allons configurer Debezium et Redis-DI pour capturer et collecter tout changement dans cette table de grand livre général. Cela signifie que chaque nouvelle transaction ou mise à jour d’une ancienne transaction sera capturée et identifiée en quasi temps réel. Ce scénario est souvent utilisé pour les organisations qui ont besoin de prendre des décisions opérationnelles basées sur des observations fraîches. Nous supposons que le point de terminaison de la base de données source est : rdi-db.cpqlgenz3kvv.eu-west-3.rds.amazonaws.com:1433
1 - Configuration de SQL Server
Pour utiliser le connecteur Debezium SQL Server, il est recommandé d’avoir un utilisateur dédié avec les permissions minimales requises dans SQL Server pour contrôler le rayon d’impact. Pour cela, vous devez exécuter le script T-SQL ci-dessous :
USE master
GO
CREATE LOGIN dbzuser WITH PASSWORD = 'dbz-password'
GO
USE FO
GO
CREATE USER dbzuser FOR LOGIN dbzuser
GO
Et accorder les permissions requises au nouvel utilisateur
USE FO
GO
EXEC sp_addrolemember N'db_datareader', N'dbzuser'
GO
Vous devez ensuite activer la Capture de Changements de Données (CDC) pour la base de données et chaque table que vous souhaitez capturer.
EXEC msdb.dbo.rds_cdc_enable_db 'FO'
GO
Exécutez ce script T-SQL pour chaque table de la base de données et substituez le nom de la table dans @source_name :
USE FO
GO
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'GeneralLedger',
@role_name = N'db_cdc',
@supports_net_changes = 0
GO
Enfin, l’utilisateur Debezium créé précédemment (dbzuser) a besoin d’accéder aux données de changement capturées, il doit donc être ajouté au rôle créé à l’étape précédente
USE FO
GO
EXEC sp_addrolemember N'db_cdc', N'dbzuser'
GO
Vous pouvez vérifier l’accès en exécutant ce script T-SQL en tant qu’utilisateur dbzuser :
USE FO
GO
EXEC sys.sp_cdc_help_change_data_capture
GO
2 - Configuration de Redis-DI
La commande scaffold de RDI a également généré un fichier appelé config.yaml. Ce fichier contient les détails de connexion de l’instance Redis cible et les paramètres de l’applier. C’est donc maintenant au tour de Redis-DI d’être configuré.
Dans le fichier de configuration Redis Data Integration config.yaml, vous devez mettre à jour les détails de connexion/cible pour correspondre aux paramètres de la base de données cible.
connections:
target:
host: redis-14000.cluster.redis-ingest.demo.redislabs.com
port: 14000
user: default
password: rdi-password

Exécutez la commande deploy pour déployer la configuration locale vers la base de données RDI distante :
redis-di deploy --rdi-host redis-13000.cluster.redis-ingest.demo.redislabs.com --rdi-port 13000 --rdi-password rdi-password
3 - Configuration du serveur Debezium
Il est maintenant temps de configurer le serveur Debezium, installé comme décrit dans les prérequis. Dans le fichier de configuration application.properties, vous devez définir le préfixe :
debezium.source.topic.prefix=dna-demo
Et le nom de votre ou vos bases de données.
debezium.source.database.names=FO
Ce préfixe sera utilisé dans le nom de clé des objets créés dans la base de données Redis-DI. Le nom de clé est créé sous la forme data:<topic.prefix>.<database.names>.<schema>.<table_name>
Vous devez configurer le nom d’hôte et le port de votre base de données SQL Server.
debezium.source.database.hostname=rdi-db.cpqlgenz3kvv.eu-west-3.rds.amazonaws.com
debezium.source.database.port=1433
Et le nom d’utilisateur et le mot de passe de l’utilisateur Debezium (dbzuser).
debezium.source.database.user=dbzuser
debezium.source.database.password=dbz-password
Vous devez configurer le point de terminaison de votre base de données de configuration Redis-DI et le mot de passe.
debezium.sink.redis.address=redis-13000.cluster.redis-ingest.demo.redislabs.com:13000
debezium.sink.redis.password=rdi-password
Toutes les autres entrées du fichier créé par la commande scaffold de RDI peuvent être laissées à leurs valeurs par défaut.

Changez de répertoire vers votre dossier de configuration Redis Data Integration créé par la commande scaffold, puis exécutez :
docker run -d --name debezium --network=host --restart always -v $PWD/debezium:/debezium/conf --log-driver local --log-opt max-size=100m --log-opt max-file=4 --log-opt mode=non-blocking debezium/server:2.1.1.Final
Consultez le journal du serveur Debezium :
docker logs debezium --follow
Lorsque le serveur Debezium démarre sans erreurs, Redis Data Integration reçoit des données via RedisStreams. Les enregistrements contenant des données de la base de données FO et de la table GeneralLedger sont écrits dans un stream avec une clé reflétant le nom de la table data:dna-demo:FO.dbo.GeneralLedger. Cela permet une interface simple dans Redis Data Integration et maintient l’ordre des changements, tel qu’observé par Debezium.
Voici le snapshot de l’intégralité de la table GeneralLedger utilisé comme référence. L’ensemble de la table est ingéré en tant que chunk batch streamé vers Redis Data Integration, puis transformé et écrit dans la base de données Redis cible.
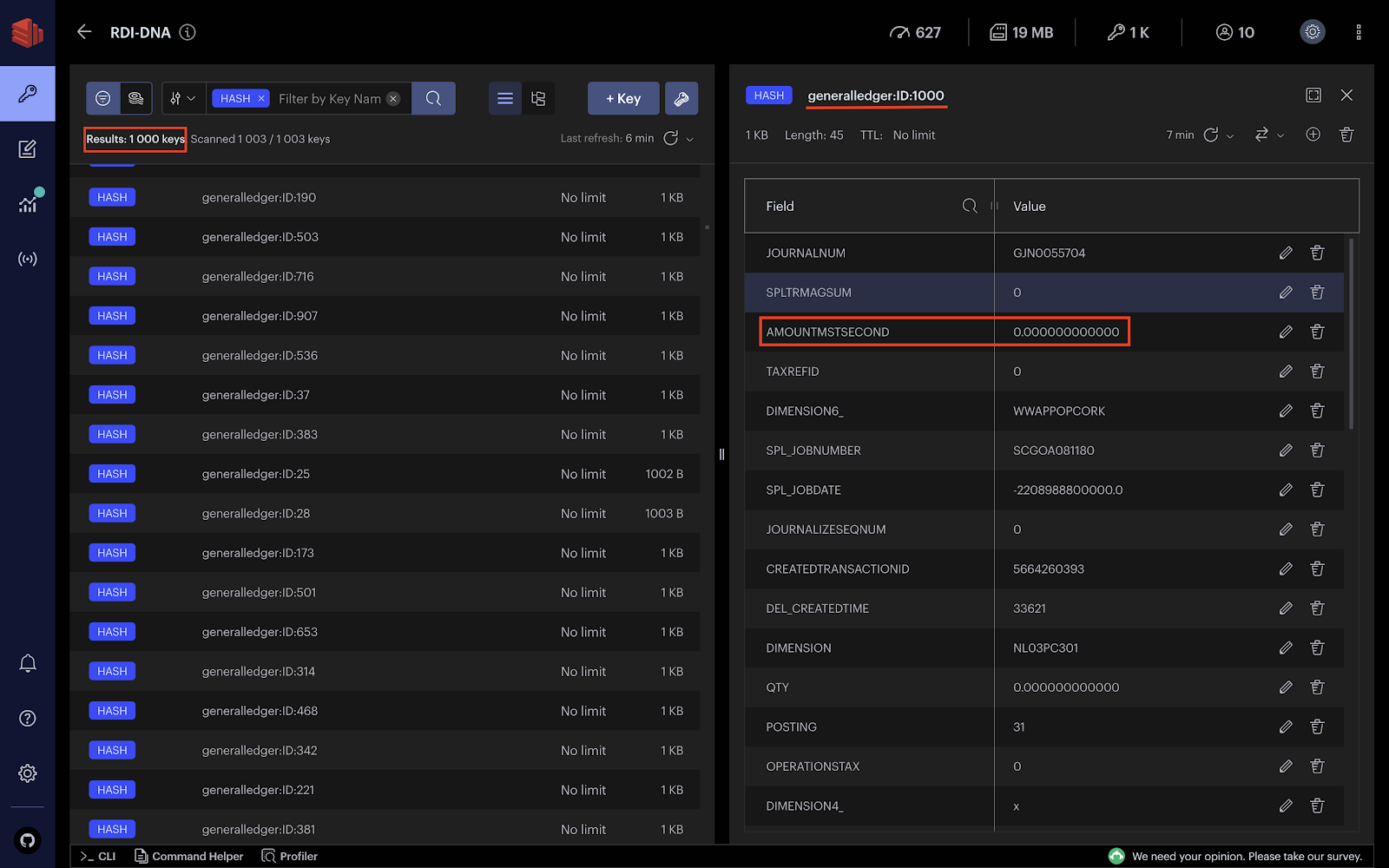
Ajoutons deux transactions au grand livre général et voyons comment le CDC capture les événements à la volée. La requête suivante insère deux transactions dans GeneralLedger :
INSERT INTO dbo.GeneralLedger (JOURNALNUM, SPLTRMAGSUM, AMOUNTMSTSECOND, TAXREFID, DIMENSION6_, SPL_JOBNUMBER, SPL_JOBDATE, JOURNALIZESEQNUM, CREATEDTRANSACTIONID, DEL_CREATEDTIME, DIMENSION, QTY, POSTING, OPERATIONSTAX, DIMENSION4_, REASONREFRECID, DIMENSION2_, DATAAREAID, CREATEDBY, SPL_LEDGERACCMIRRORING_TR, TRANSTYPE, DOCUMENTDATE, TRANSDATE, MODIFIEDBY, CREDITING, SPL_BALANCINGID, BONDBATCHTRANS_RU, RECID, MODIFIEDDATETIME, AMOUNTCUR, CURRENCYCODE, RECVERSION, CORRECT, ACCOUNTNUM, AMOUNTMST, CREATEDDATETIME, PERIODCODE, ALLOCATELEVEL, FURTHERPOSTINGTYPE, DIMENSION5_, VOUCHER, DIMENSION3_, ACKNOWLEDGEMENTDATE, EUROTRIANGULATION) VALUES ('GJN0055897','0','0.000000000000','1','NLANCOMOE','SHKGS177192','1900-01-01 00:00:00.0000000','0','5664282519','34568','NL03PC301','0.000000000000','14','0','MARI','0','34200','nl03','arie.','0','0','2020-11-18 00:00:00.0000000','2020-11-24 00:00:00.0000000','arie.','0','0','0','5734386059','2020-11-25 08:36:08.0000000','1.410.000.000.000.000','EUR','1','0','701100','1.410.000.000.000.000','2020-11-25 08:36:08.0000000','1','0','0','GENCAR','PII000866194','MISC','2020-11-24 00:00:00.0000000','0');
INSERT INTO dbo.GeneralLedger (JOURNALNUM, SPLTRMAGSUM, AMOUNTMSTSECOND, TAXREFID, DIMENSION6_, SPL_JOBNUMBER, SPL_JOBDATE, JOURNALIZESEQNUM, CREATEDTRANSACTIONID, DEL_CREATEDTIME, DIMENSION, QTY, POSTING, OPERATIONSTAX, DIMENSION4_, REASONREFRECID, DIMENSION2_, DATAAREAID, CREATEDBY, SPL_LEDGERACCMIRRORING_TR, TRANSTYPE, DOCUMENTDATE, TRANSDATE, MODIFIEDBY, CREDITING, SPL_BALANCINGID, BONDBATCHTRANS_RU, RECID, MODIFIEDDATETIME, AMOUNTCUR, CURRENCYCODE, RECVERSION, CORRECT, ACCOUNTNUM, AMOUNTMST, CREATEDDATETIME, PERIODCODE, ALLOCATELEVEL, FURTHERPOSTINGTYPE, DIMENSION5_, VOUCHER, DIMENSION3_, ACKNOWLEDGEMENTDATE, EUROTRIANGULATION) VALUES ('GJN0055516','0','0.000000000000','0','NLMEINARN','SRTMS096263','1900-01-01 00:00:00.0000000','0','5664241334','36867','NL03PC301','0.000000000000','14','0','x','0','x','nl03','coos.','0','0','1900-01-01 00:00:00.0000000','2020-11-01 00:00:00.0000000','coos.','1','0','0','5733724085','2020-11-02 09:14:27.0000000','-358.050.000.000.000','EUR','1','0','245000','-358.050.000.000.000','2020-11-02 09:14:27.0000000','1','0','0','x','GOI001629867','x','2020-11-01 00:00:00.0000000','0');

Vous pouvez observer que Debezium a capturé les deux insertions et les a envoyées au stream data:dna-demo:FO.dbo.GeneralLedger. RedisGears, le moteur de traitement de données de Redis, lit les entrées du stream et crée des hashes ou des objets JSON pour chaque ligne capturée.
Le flux de travail est assez simple. Dans les SGBDR, le journal de transactions suit toute commande DLM reçue sur la base de données. Debezium écoute et capture les changements dans le journal de transactions et déclenche des événements vers un système de streaming d’événements tel que RedisStreams. Ensuite, RedisGears est notifié pour consommer ces événements et les traduire en structures de données Redis (par exemple, des Hashes ou JSON).

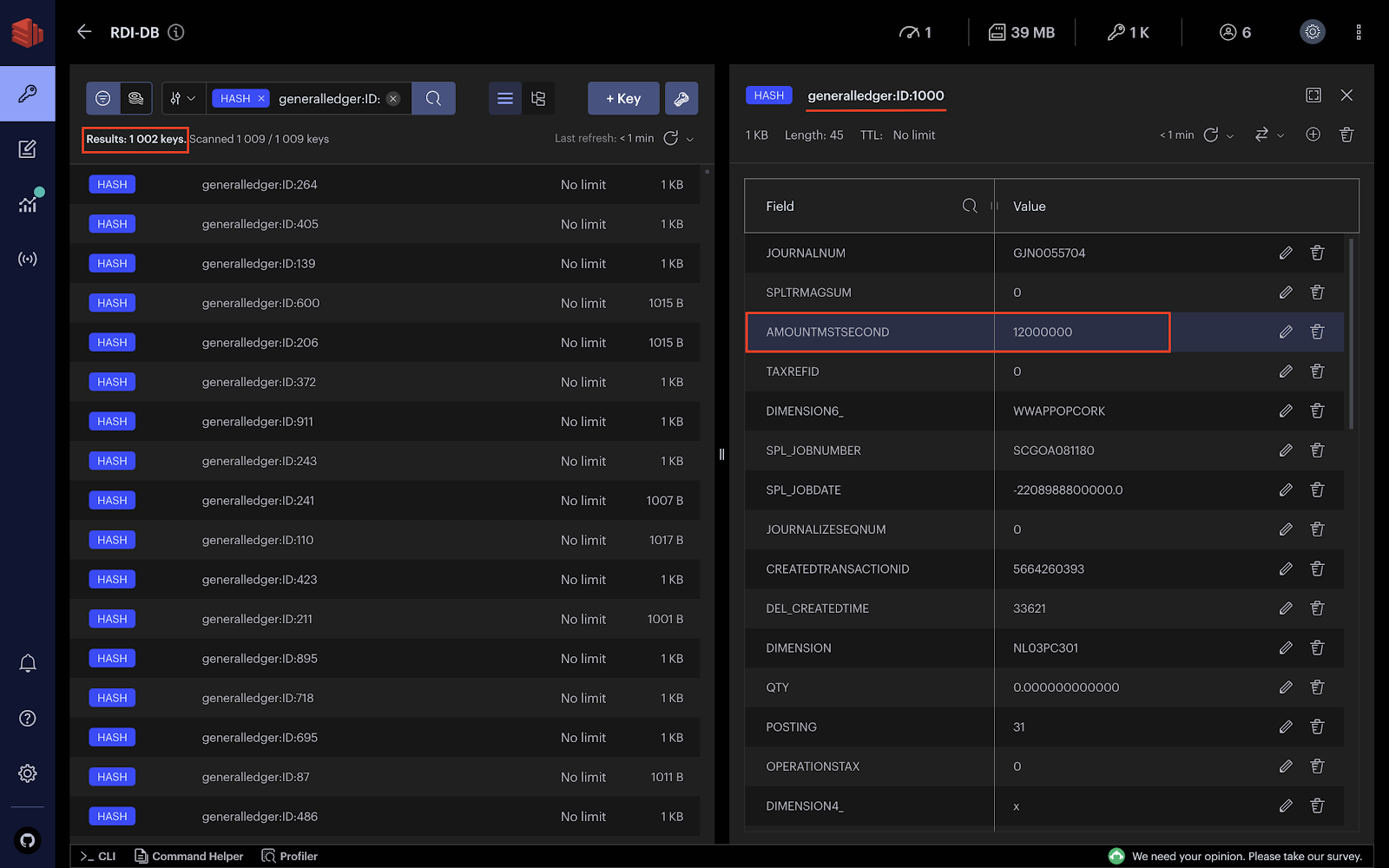
Allons plus loin et mettons à jour un champ spécifique pour une ligne particulière dans la table GeneralLedger. Par exemple, la requête suivante met à jour le champ AMOUNTMSTSECOND de la table GeneralLedger pour la transaction ayant l’ID égal à 1000.
UPDATE dbo.GeneralLedger SET AMOUNTMSTSECOND = '12000000' WHERE ID = 1000;
Lorsque vous exécutez la requête, le hash generalledger:ID:1000 doit être mis à jour en conséquence. Vous devriez également observer que vous avez 1002 clés puisque nous avons déjà inséré deux transactions.
Les jobs Data Integration (RDI), de streaming et de chargement initial peuvent être partitionnés pour une scalabilité linéaire sur un ou plusieurs nœuds de cluster. Par exemple, les flux de données au niveau table peuvent être divisés en plusieurs shards où ils peuvent être transformés et écrits vers la cible en parallèle tout en maintenant l’ordre des mises à jour au niveau table. Les jobs RDI mettent à jour leur point de contrôle à chaque événement de données modifiées validé dans un périmètre transactionnel. Lorsqu’une défaillance de nœud ou une partition réseau se produit, un job bascule vers un autre nœud et reprend la réplication à partir du dernier point de contrôle validé de manière transparente. Les données ne seront pas perdues et l’ordre sera maintenu.
Redis Data Integration est hautement disponible. Au niveau du feeder, le serveur Debezium peut être déployé en utilisant Kubernetes ou Pacemaker pour le basculement entre des instances sans état pendant que l’état est sécurisé dans Redis. Au niveau du plan de données et de contrôle, RDI tire parti des mécanismes de haute disponibilité de Redis Enterprise (réplica de shard, configurations au niveau cluster, etc.)
Enfin, Redis Data Integration (RDI) permet aux utilisateurs de transformer leurs données au-delà de la traduction par défaut des types source vers les types Redis. Les transformations sont sans code. Vous pouvez décrire votre transformation de données dans un ensemble de fichiers YAML lisibles par l’homme, un par table source. Chaque job décrit la logique de transformation à effectuer sur les données d’une seule source. La source est généralement une table ou une collection de base de données et est spécifiée comme le nom complet de cette table/collection. Le job peut inclure une logique de filtrage pour ignorer les données qui correspondent à une condition. D’autres étapes logiques dans le job transformeront les données dans la sortie souhaitée à stocker dans Redis (en tant que Hash ou JSON). Nous plongerons en profondeur dans les capacités de traitement de données Redis dans un futur article.
Résumé
Tout parcours de données commence par l’ingestion de données, que ce soit pour des données historiques pouvant être ingérées et traitées en mode batch ou des données temps réel devant être collectées et transformées à la volée. Redis Enterprise et l’ensemble des outils qu’il fournit peuvent vous aider à construire ces deux types d’architectures de données.
Effectuer l’ingestion de données avec les outils Redis peut être avantageux car cela bénéficie de la faible latence et du débit élevé de Redis. Redis possède une architecture cloud-native et shared-nothing qui permet à tout nœud de fonctionner de manière autonome ou en tant que membre d’un cluster. Sa conception légère et agnostique vis-à-vis des plateformes nécessite une infrastructure minimale et évite les dépendances complexes sur des plateformes tierces.
Dans de nombreux cas d’usage, les données historiques ou référentielles supposées être traitées trop tard (avec des batchs déclenchés) peuvent être ingérées avec RIOT. Ne vous méprenez pas. Les données batch ne sont pas mauvaises. Plusieurs cas d’usage, comme le reporting historique et l’entraînement de modèles (machine learning), fonctionnent très bien avec cette approche.
Cependant, lorsque vous pensez à votre secteur, aux besoins de votre organisation et aux problèmes que vous résolvez, les données temps réel peuvent être votre choix. En fin de compte, les données temps réel surpassent les données lentes pour des cas d’usage spécifiques où vous avez besoin de prendre des décisions opérationnelles rapides. Cette affirmation est toujours vraie. Que ce soit pour augmenter les revenus, réduire les coûts, réduire les risques ou améliorer l’expérience client. Pour cela, Redis Data Integration (RDI) offre, avec l’aide de Debezium, un socle technique pour capturer et traiter les données dès leur création dans la source.
Références
- Redis Data Integration (RDI), Guide du développeur
- Redis Input/Output Tools (RIOT), RIOT DB - Documentation
- Redis Input/Output Tools (RIOT), RIOT File - Documentation
1. RedisStreams offre jusqu’à 500 fois le débit d’Apache Kafka à une échelle inférieure à la milliseconde.