
Le stockage de données désigne la façon dont les données sont conservées une fois qu’elles ont été acquises. Le stockage s’étend sur l’ensemble du parcours des données, se produisant souvent en plusieurs endroits dans un pipeline de données, avec des systèmes de stockage qui se croisent avec les systèmes sources, l’ingestion, la transformation et le service. À bien des égards, la façon dont les données sont stockées a un impact sur leur utilisation à toutes les étapes du parcours des données. Dans cet article, je vais approfondir le stockage de données avec Redis.
Redis est un serveur de structures de données open source en mémoire. En son cœur, Redis fournit une collection de types de données natifs qui répondent à un large éventail de cas d’usage : base de données principale, cache, moteur de streaming et broker de messages. De plus, Redis offre une latence inférieure à la milliseconde avec un débit très élevé : jusqu’à 200 millions d’opérations par seconde à une échelle inférieure à la milliseconde, ce qui en fait le choix évident pour les cas d’usage en temps réel.
Dans cet article, j’expliquerai pourquoi Redis est si rapide lorsque vous stockez et récupérez des données ? Vous découvrirez qu’en plus de sa capacité à stocker des données efficacement en mémoire, il est livré avec une gamme de structures de données performantes telles que les chaînes, les hashes, les listes, les ensembles, les ensembles triés avec des requêtes de plage, les bitmaps, les hyperloglogs, les index géospatiaux et les streams… Toutes implémentées avec la plus faible complexité computationnelle (notation big O).
En plus de ces structures de données natives, plusieurs extensions (appelées modules) fournissent des structures de données supplémentaires comme JSON, Graph, TimeSeries et des structures de données probabilistes (Bloom).
Pourquoi Redis est-il si rapide ?
Faisons un rappel des niveaux d’abstraction de stockage introduits dans la série Data 101. Le « stockage » signifie différentes choses pour différents utilisateurs. Par exemple, quand on parle de stockage, certaines personnes pensent à la façon dont les données sont stockées physiquement ; d’autres se concentrent sur le matériau brut qui contient les systèmes de stockage, tandis que d’autres encore pensent au système ou à la technologie de stockage pertinent pour leur cas d’usage. Tous ces niveaux sont des attributs importants du stockage, mais ils se concentrent sur différents niveaux d’abstraction.
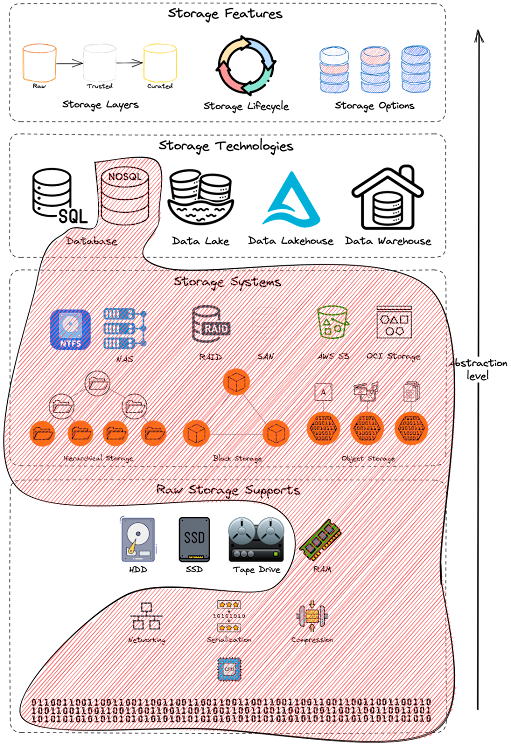 Abstractions de stockage - Périmètre Redis.
Abstractions de stockage - Périmètre Redis.
Pour atteindre des performances maximales, Redis fonctionne en mémoire. Les données sont stockées et manipulées directement en RAM sans persistance sur disque. La mémoire est rapide et permet à Redis d’avoir des performances très prévisibles. Les jeux de données composés de 10 000 ou 40 millions de clés auront des performances similaires. Ce support de stockage brut fournit un accès plus rapide aux données (au moins 1 000 fois plus rapide que l’accès disque). L’accès pur en mémoire offre un débit élevé en lecture et en écriture et une faible latence. Le compromis est que le jeu de données ne peut pas être plus grand que la mémoire.
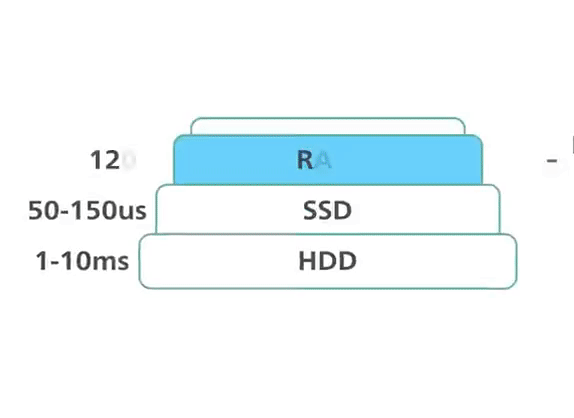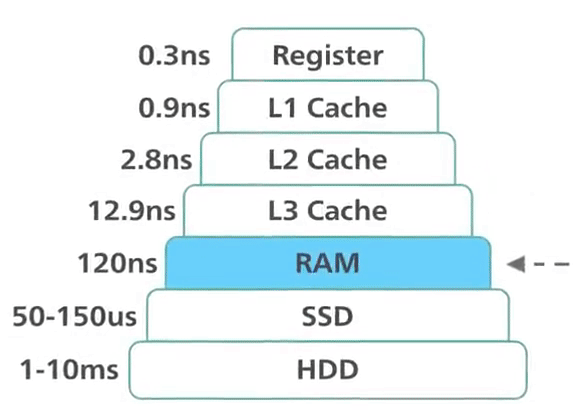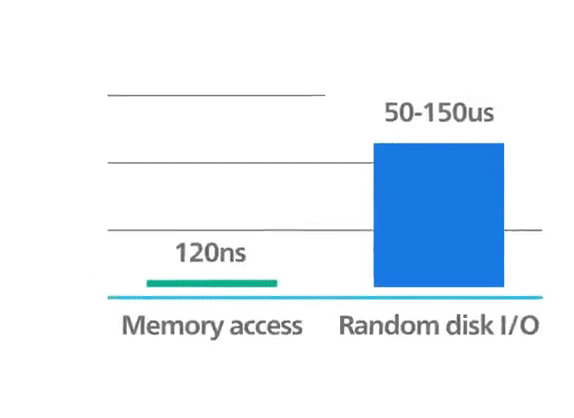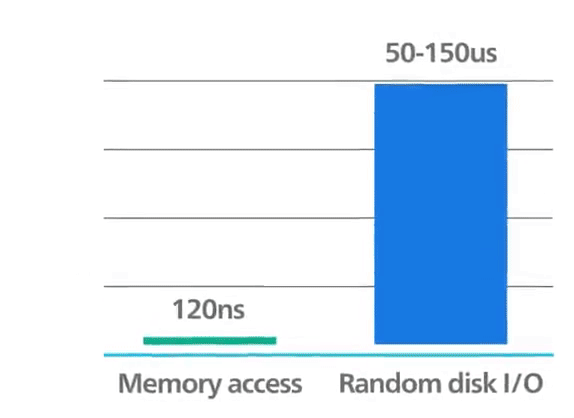 Redis : performances en mémoire ©ByteByteGo.
Redis : performances en mémoire ©ByteByteGo.
Une autre raison des hautes performances de Redis est un peu contre-intuitive. Une instance Redis est principalement mono-thread. Les applications multi-threads nécessitent des verrous ou d’autres mécanismes de synchronisation. Elles sont notoirement difficiles à raisonner. Dans de nombreuses applications, la complexité ajoutée est source de bugs et sacrifie la stabilité, rendant difficile la justification du gain de performance. Dans le cas de Redis, le chemin de code mono-thread est facile à comprendre.
Cependant, cela peut devenir problématique lorsqu’il s’agit de gérer simultanément des milliers de requêtes entrantes et de réponses sortantes avec une base de code mono-thread. Le temps de traitement dans Redis est principalement gaspillé en attente d’E/S réseau ; des goulots d’étranglement peuvent donc apparaître.
C’est là que le multiplexage d’E/S entre en jeu. Avec le multiplexage d’E/S, le système d’exploitation permet à un seul thread d’attendre simultanément sur de nombreuses connexions socket et ne renvoie que les sockets lisibles.

Un inconvénient de cette conception mono-thread est qu’elle n’exploite pas tous les cœurs CPU disponibles dans un nœud. Cependant, il n’est pas rare que les charges de travail modernes aient plusieurs instances Redis s’exécutant sur un seul serveur pour utiliser davantage de cœurs CPU. C’est pourquoi Redis Enterprise fournit une architecture symétrique « share-nothing » pour séparer complètement le chemin des données et le chemin de contrôle et de gestion, permettant à plusieurs instances Redis d’être hébergées dans le même nœud. Il permet également à un proxy multi-thread sans état de masquer la complexité du cluster, améliorant la sécurité (SSL, authentification, protection DDoS) et améliorant les performances (sans TCP, gestion des connexions et pipelining).
Enfin, la troisième raison pour laquelle Redis est rapide réside dans les structures de données natives fournies par Redis. Du point de vue du code, les structures de données en mémoire sont beaucoup plus faciles à implémenter que leurs homologues sur disque. Cela maintient le code simple et contribue à la stabilité à toute épreuve de Redis. De plus, comme Redis est une base de données en mémoire, il pourrait exploiter plusieurs structures de données efficaces de bas niveau sans se soucier de les persister efficacement sur disque : liste chaînée, liste à saut et table de hachage en sont quelques exemples. Je vais approfondir chaque structure de données et le niveau de complexité qu’elle offre.

Les cas d’usage les plus courants de Redis
Dans cette section, nous allons découvrir la polyvalence de Redis en discutant des principaux cas d’usage qui ont été éprouvés en production dans diverses entreprises et à diverses échelles.
1 - Mise en cache (Caching)
Redis est un datastore de structures de données en mémoire, et son utilisation la plus courante est la mise en cache d’objets pour accélérer les applications. Il exploite la mémoire disponible sur les serveurs d’applications pour stocker les données fréquemment demandées. Ainsi, il permet de retourner rapidement les données fréquemment consultées. Cela réduit la charge de la base de données et améliore le temps de réponse de l’application. À cet effet, il prend en charge des structures de données comme les chaînes, les hashes, les listes, les ensembles et les ensembles triés. Plusieurs patterns existent pour la mise en cache :
- Cache-Aside (Chargement paresseux) : Le plus courant est le Cache-aside ou chargement paresseux. Avec cette stratégie, l’application regarde d’abord dans le cache pour récupérer les données. Si les données ne sont pas trouvées (cache miss), l’application récupère alors directement les données depuis le datastore opérationnel. Les données ne sont chargées dans le cache que lorsque c’est nécessaire (d’où le chargement paresseux). Les applications à forte lecture peuvent grandement bénéficier de l’implémentation d’une approche cache-aside.
- Write-Behind : Dans cette stratégie, les données sont d’abord écrites dans le cache, puis mises à jour de manière asynchrone dans le datastore opérationnel. Cette approche améliore les performances d’écriture et simplifie le développement d’application car le développeur n’écrit qu’à un seul endroit (Redis).
- Write-Through : La stratégie de cache Write-Through est similaire à l’approche write-behind, car le cache se situe entre l’application et le datastore opérationnel, sauf que les mises à jour sont effectuées de manière synchrone. Le pattern write-through favorise la cohérence des données entre le cache et le datastore, car l’écriture est effectuée sur le thread principal du serveur. RedisGears et Redis Data Integration (RDI) offrent à la fois des capacités write-through et write-behind.
- Read-Through (Réplique en lecture) : Dans un environnement où vous disposez d’une grande quantité de données historiques (par exemple, un mainframe) ou d’une exigence selon laquelle chaque écriture doit être enregistrée dans un datastore opérationnel, les connecteurs Redis Data Integration (RDI) peuvent capturer des modifications individuelles de données et propager des copies exactes sans perturber les opérations en cours avec une cohérence en quasi temps réel. Le CDC, couplé à la capacité de Redis Enterprise à utiliser plusieurs modèles de données, peut vous donner des informations précieuses sur des données précédemment verrouillées.

2 - Stockage de sessions (Session Store)
Un autre cas d’usage courant est d’utiliser Redis comme stockage de sessions pour partager les données de session entre des serveurs sans état. Lorsqu’un utilisateur se connecte à une application web, les données de session sont stockées dans Redis, avec un identifiant de session unique renvoyé au client sous forme de cookie. Lorsque l’utilisateur effectue une requête vers l’application, l’identifiant de session est inclus dans la requête, et le serveur web sans état récupère les données de session depuis Redis en utilisant cet identifiant. Les stockages de sessions sont derrière le panier d’achat que vous trouvez sur les sites de commerce électronique.

3 - Verrou distribué (Distributed Lock)
Les verrous distribués sont utilisés lorsque plusieurs nœuds d’une application doivent coordonner l’accès à une ressource partagée. Redis est utilisé comme verrou distribué avec ses commandes atomiques comme SETNX (SET if Not eXists). Il permet à un appelant de définir une clé uniquement si elle n’existe pas déjà. Voici comment cela fonctionne à haut niveau :
Client 1 essaie d’acquérir le verrou en définissant une clé avec une valeur unique et un délai d’expiration en utilisant la commande SETNX : SETNX lock "1234abcd" EX 3
- Si la clé n’était pas déjà définie, la commande
SETNXrenvoie 1, indiquant que le verrou a été acquis par Client 1.- Client 1 termine son travail ;
- et libère le verrou en supprimant la clé.
- Si la clé était déjà définie, la commande
SETNXrenvoie 0, indiquant qu’un autre client détient déjà le verrou.- Dans ce cas, Client 1 attend et réessaie l’opération
SETNXjusqu’à ce que l’autre client libère le verrou.
- Dans ce cas, Client 1 attend et réessaie l’opération
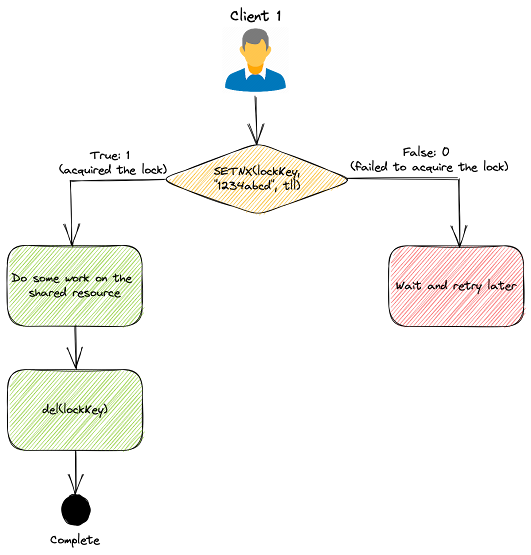 Exemple d’implémentation d’un verrou distribué.
Exemple d’implémentation d’un verrou distribué.
Cette implémentation simple peut être suffisante pour de nombreux cas d’usage, mais elle n’est pas complètement tolérante aux pannes. Pour une utilisation en production, de nombreuses bibliothèques clientes Redis fournissent des implémentations de verrous distribués de haute qualité prêtes à l’emploi.
4 - Limiteur de débit / Compteur (Rate Limiter / Counter)
Les chaînes Redis offrent des capacités de manipulation d’entiers avec des commandes comme INCR et INCRBY. Ces commandes vous aident à implémenter des compteurs, par exemple. L’utilisation la plus courante des compteurs Redis est les limiteurs de débit. Vous pouvez en implémenter un en utilisant les commandes d’incrément de chaînes sur certains compteurs et en définissant des délais d’expiration sur ces compteurs. Un algorithme de limitation de débit très basique fonctionne ainsi :
- L’IP de la requête ou l’ID utilisateur est utilisé comme clé pour chaque requête entrante.
- Le nombre de requêtes pour la clé est incrémenté à l’aide de la commande
INCRdans Redis. - Le compte actuel est comparé à la limite de débit autorisée.
- La requête est traitée si le compte est dans la limite de débit.
- La requête est rejetée si le compte dépasse la limite de débit.
- Les clés sont configurées pour expirer après une fenêtre de temps spécifique, par exemple une minute, pour réinitialiser les comptes pour la prochaine fenêtre de temps.

Des limiteurs de débit plus sophistiqués comme l’algorithme du seau percé peuvent également être implémentés avec Redis. Vous pouvez également implémenter de tels compteurs en utilisant la structure de données HyperLogLog.
5 - Classement / Tableau de scores de jeu (Ranking / Gaming Leaderboard)
Redis est une façon délicieuse d’implémenter divers tableaux de scores de jeu pour la plupart des jeux qui ne sont pas à très grande échelle. Les ensembles triés (Sorted Sets) sont la structure de données fondamentale qui rend cela possible. Un ensemble trié est une collection d’éléments uniques, chacun associé à un score. Les éléments sont triés par score. Cela permet une récupération rapide des éléments par score en temps logarithmique.
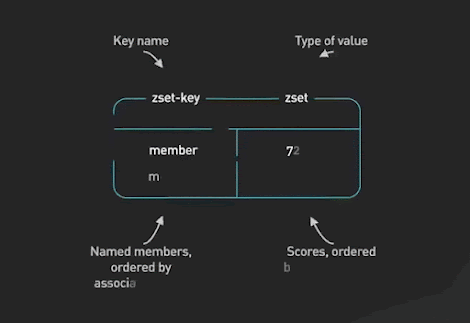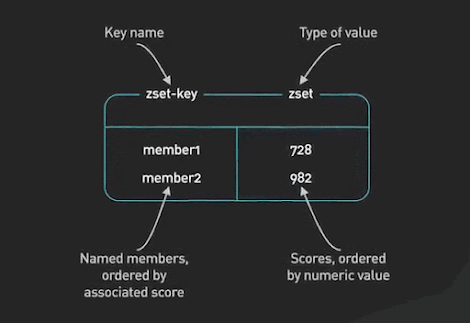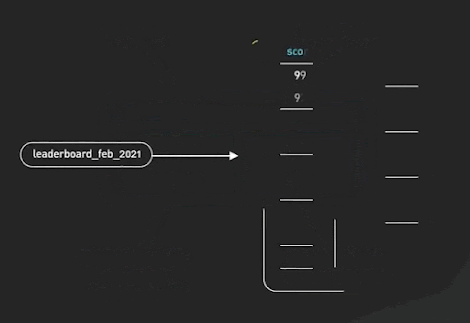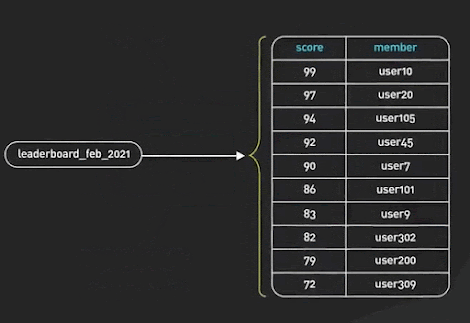 SortedSets Redis ©ByteByteGo.
SortedSets Redis ©ByteByteGo.
6 - File de messages (Message Queue)
Lorsque vous avez besoin de stocker et de traiter une série indéterminée d’événements/messages, vous pouvez envisager Redis. En fait, les listes Redis (listes chaînées de valeurs de chaînes) sont fréquemment utilisées pour implémenter des listes, des piles, des files LIFO et des files FIFO. De plus, Redis utilise également les listes pour implémenter des architectures de messagerie Pub/Sub.
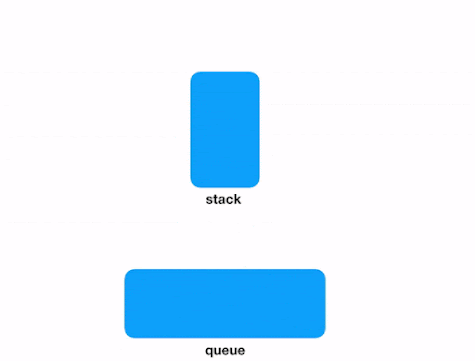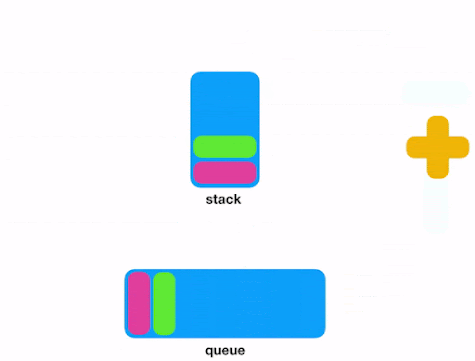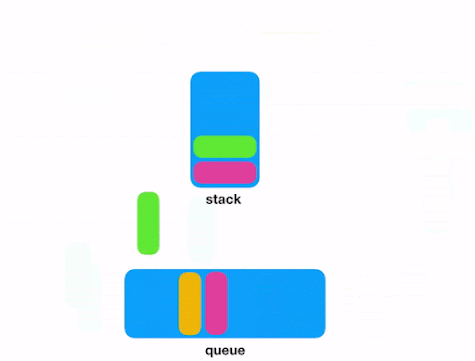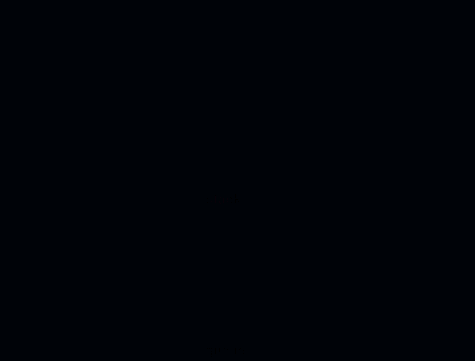 Push et Pop dans/depuis les listes Redis.
Push et Pop dans/depuis les listes Redis.
Dans le paradigme éditeurs/abonnés (Pub/Sub), les émetteurs (éditeurs) ne sont pas programmés pour envoyer leurs messages à des destinataires spécifiques (abonnés). Au lieu de cela, les messages publiés sont caractérisés dans des canaux sans connaissance des abonnés qu’il pourrait y avoir. De même, les abonnés expriment leur intérêt pour un ou plusieurs canaux et ne reçoivent que les messages qui les intéressent sans savoir quels éditeurs existent. Ce découplage des éditeurs et des abonnés permet la communication entre différents composants ou systèmes de manière faiblement couplée, permettant une plus grande évolutivité et une topologie réseau plus dynamique.
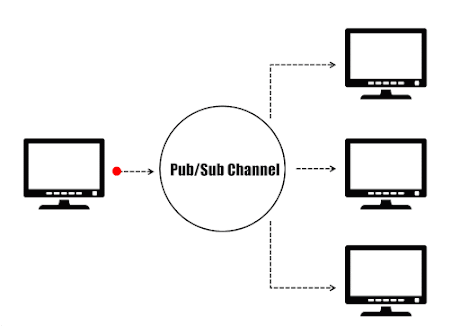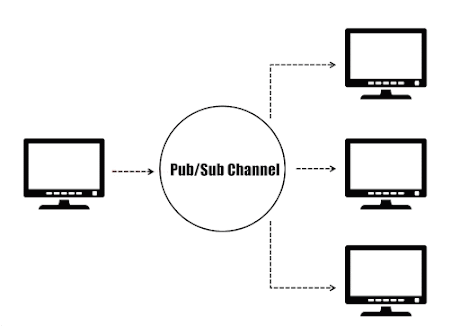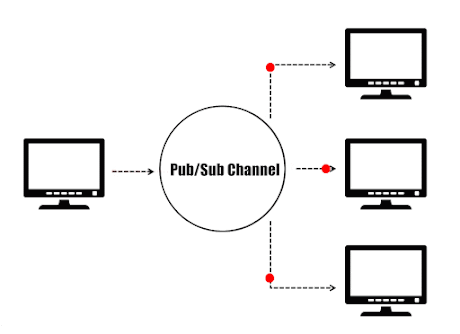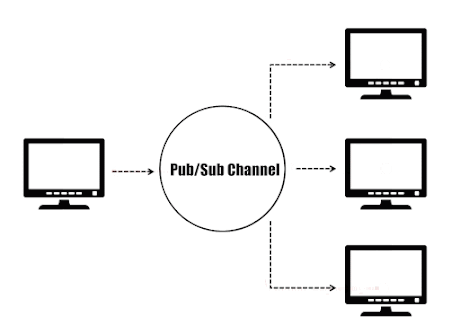 Paradigme Éditeur/Abonné.
Paradigme Éditeur/Abonné.
Redis fournit également une structure de données spécifique, appelée Redis Streams, qui agit comme un journal en ajout uniquement. Vous pouvez utiliser les streams pour enregistrer et diffuser simultanément des événements en temps réel. Voici quelques exemples de cas d’usage de Redis Streams :
- Sourcing d’événements (par exemple, suivi des actions des utilisateurs, des clics, etc.)
- Surveillance des capteurs (par exemple, lectures depuis des appareils sur le terrain)
- Notifications (par exemple, stocker un enregistrement des notifications de chaque utilisateur dans un stream séparé)

7 - Réseaux sociaux (Social Networking)
Nous vivons dans un monde connecté, et comprendre la plupart des relations nécessite le traitement de riches ensembles de connexions pour comprendre ce qui se passe réellement. Les réseaux de médias sociaux sont des graphes dans lesquels les relations sont stockées nativement aux côtés des éléments de données (les nœuds) dans un format beaucoup plus flexible. C’est là qu’intervient RedisGraph.

RedisGraph est une base de données graphe construite sur Redis. Cette base de données graphe utilise GraphBlas sous le capot pour sa représentation de graphe en matrice d’adjacence creuse. Elle adopte le modèle de graphe de propriétés et présente les caractéristiques suivantes :
- Les nœuds (sommets) et les relations (arêtes) peuvent avoir des attributs ;
- Les nœuds peuvent avoir plusieurs étiquettes ;
- Les relations ont un type de relation ;
- Les graphes représentés sous forme de matrices d’adjacence creuses ;
- OpenCypher avec des extensions propriétaires comme langage de requête ;
- Les requêtes sont traduites en expressions d’algèbre linéaire.
Tout dans le système est optimisé pour parcourir rapidement les données, avec des millions de connexions par seconde. RedisGraph peut également être utilisé pour des moteurs de recommandation afin de trouver rapidement des connexions entre vos clients et leurs préférences.
8 - Recherche en texte intégral (Full-Text Search)
La recherche en texte intégral consiste à rechercher du contenu textuel dans des documents textuels étendus et à retourner des résultats contenant tout ou partie des mots de la requête. Bien que les bases de données traditionnelles soient excellentes pour le stockage et la récupération de données générales (correspondance exacte), effectuer des recherches en texte intégral a été difficile. C’est pourquoi Redis a créé le module RedisJSON pour stocker nativement des documents JSON. Ce module a permis à Redis de stocker, mettre à jour et récupérer tout ou partie des valeurs JSON dans une base de données Redis, comme tout autre type de données Redis.
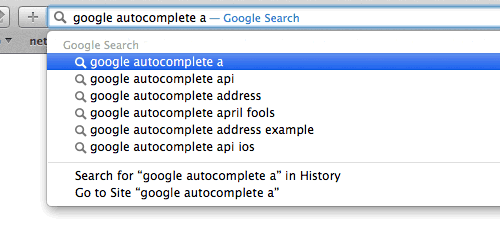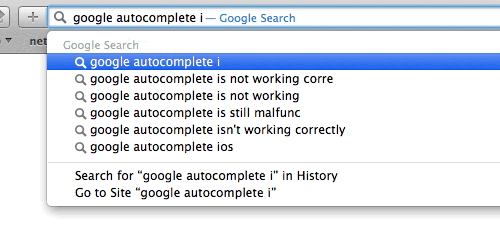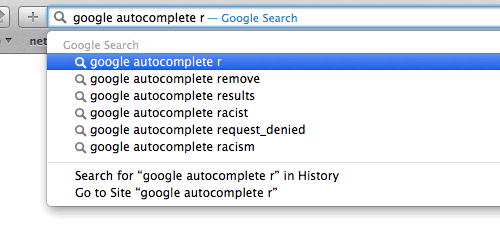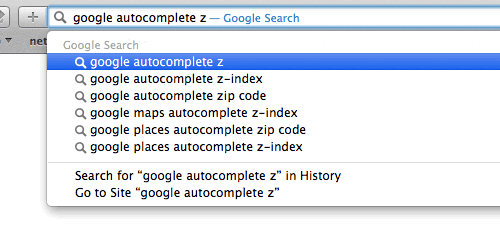 Moteur de recherche Google - Autocomplétion.
Moteur de recherche Google - Autocomplétion.
RedisJSON fonctionne parfaitement avec le module RediSearch pour créer des index secondaires et interroger des documents JSON. De plus, RediSearch permet des requêtes multi-champs, l’agrégation, la correspondance de phrases exactes, le filtrage numérique, le filtrage géographique et la recherche sémantique par similarité sur les requêtes textuelles.
9 - Recherche par similarité (Similarity Search)
Un autre avantage de l’utilisation de RediSearch est la fonctionnalité de recherche par similarité qu’il offre. La recherche par similarité permet de trouver des points de données similaires à une caractéristique de requête donnée dans une base de données. Les cas d’usage les plus populaires sont la Recherche par Similarité Vectorielle (VSS) pour les systèmes de recommandation, la recherche d’images et de vidéos, le traitement du langage naturel et la détection d’anomalies. Par exemple, si vous créez un système de recommandation, vous pouvez utiliser la VSS pour trouver (et suggérer) des produits similaires à un produit pour lequel un utilisateur a précédemment montré de l’intérêt ou qui ressemble à un autre produit que vous avez déjà acheté.

Elle est également utilisée pour entraîner de grands modèles de langues qui utilisent des algorithmes d’apprentissage automatique pour traiter et comprendre les langues naturelles. Par exemple, OpenAI a exploité Redis comme base de données vectorielle pour stocker des embeddings et effectuer des calculs de similarité vectorielle afin de trouver des sujets, des objets et des contenus similaires pour chatGPT.
Structures de données Redis
Dans cette section, je vais rapidement passer en revue les structures de données natives qui vous aident à répondre aux cas d’usage présentés ci-dessus.
1 - Chaînes (Strings)
Les chaînes Redis stockent des séquences d’octets, notamment du texte, des objets sérialisés et des tableaux binaires. En tant que telles, les chaînes sont le type de données Redis le plus basique. Elles sont souvent utilisées pour la mise en cache, mais prennent également en charge des fonctionnalités supplémentaires qui vous permettent d’implémenter des compteurs atomiques ou des verrous et d’effectuer des opérations bit à bit. Les chaînes combinées avec TTL et une politique d’éviction sont la structure préférée lors de l’implémentation d’un cache.
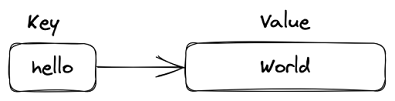 Une chaîne Redis.
Une chaîne Redis.
La plupart des opérations sur les chaînes ont une complexité algorithmique de O(1), ce qui signifie qu’elles sont très efficaces. Cependant, faites attention aux commandes SUBSTR, GETRANGE et SETRANGE, qui peuvent être O(n). Ces commandes d’accès aléatoire aux chaînes peuvent causer des problèmes de performance lors du traitement de grandes chaînes. Une seule chaîne Redis peut avoir une taille maximale de 512 Mo par défaut. Si vous stockez des données structurées, vous pourriez également envisager les hashes.
2 - Hashes
Les hashes Redis sont des types à structure d’enregistrement sous forme de collections de paires champ-valeur. Vous pouvez utiliser les hashes pour représenter des objets de base et stocker des groupes de compteurs, entre autres choses. La plupart des commandes de hash Redis ont une complexité algorithmique de O(1). Quelques commandes, comme HKEYS, HVALS et HGETALL, sont O(n), où n est le nombre de paires champ-valeur. Chaque hash peut stocker jusqu’à 4 294 967 295 (232 - 1) paires champ-valeur. Notez que chaque nom de champ et valeur est une chaîne Redis limitée à 512 Mo. Par conséquent, la taille maximale d’un hash peut atteindre jusqu’à 4 294 Po (soit (232 -1) x 2 x 512 Mo). En pratique, vos hashes ne sont limités que par la mémoire totale des VM hébergeant votre déploiement Redis.

3 - Ensemble (Set)
Un ensemble Redis est une collection non ordonnée de chaînes uniques (membres). Vous pouvez utiliser les ensembles Redis pour suivre efficacement les éléments uniques (par exemple, suivre toutes les adresses IP uniques accédant à un article de blog donné), représenter des relations (par exemple, l’ensemble de tous les utilisateurs ayant un rôle donné) ou effectuer des opérations inter-ensembles telles que l’intersection, l’union et les différences. La taille maximale d’un ensemble Redis est de 4 294 967 295 (232 - 1) membres uniques, ce qui signifie une taille maximale de 2 147 Po (4 294 967 295 x 512 Mo) par ensemble.
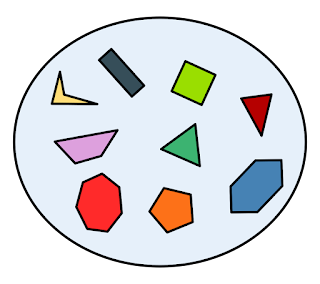 Un ensemble d’éléments uniques.
Un ensemble d’éléments uniques.
La plupart des opérations sur les ensembles, y compris l’ajout, la suppression et la vérification de l’appartenance d’un élément à un ensemble, sont O(1). Cela signifie qu’elles sont très efficaces. Cependant, pour les grands ensembles avec des centaines de milliers de membres ou plus, vous devriez faire preuve de prudence lors de l’exécution de la commande SMEMBERS. Cette commande est O(n) et renvoie l’ensemble entier en une seule réponse. Comme alternative, envisagez SSCAN, qui vous permet de récupérer tous les membres de l’ensemble de manière itérative.
4 - Ensemble trié (SortedSet)
Un ensemble trié Redis est une collection de chaînes uniques (membres) ordonnées par un score associé. Lorsque plus d’une chaîne a le même score, les chaînes sont ordonnées lexicographiquement. La taille maximale d’un ensemble trié Redis est de 4 294 967 295 (232 - 1) membres uniques, ce qui signifie une taille maximale de 2 147 Po (4 294 967 295 x 512 Mo) par ensemble trié.
La plupart des opérations sur les ensembles triés sont O(log(n)), où n est le nombre de membres. Vous devez tenir compte du fait que l’exécution de la commande ZRANGE peut retourner de grandes valeurs (par exemple, des dizaines de milliers ou plus). La complexité temporelle de cette commande est O(log(n) + m), où m est le nombre de résultats retournés.
Les ensembles triés Redis peuvent facilement maintenir des listes ordonnées des meilleurs scores dans un jeu en ligne massivement multijoueur (tableaux de classement), vous pouvez utiliser un ensemble trié pour construire un limiteur de débit à fenêtre glissante pour prévenir des requêtes API excessives, et vous pouvez les utiliser pour stocker des séries temporelles, en utilisant un horodatage comme score.
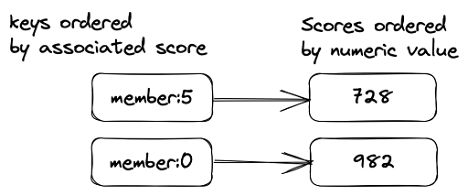 Un ensemble trié Redis (ZSet).
Un ensemble trié Redis (ZSet).
Ils sont également souvent utilisés comme index secondaires pour les requêtes de plage. Par exemple, pour obtenir tous les clients avec un nom spécifique (par exemple, « Amine ») avec des âges entre 30 et 50. Les ensembles triés Redis sont parfois utilisés pour indexer d’autres structures de données Redis. Si vous avez besoin d’indexer et d’interroger vos données, envisagez RediSearch et RedisJSON.
5 - Listes (Lists)
Les listes Redis sont des listes chaînées de valeurs de chaînes. Une liste peut stocker jusqu’à 4 294 967 295 (232 - 1) éléments et conserver les éléments classés. Ce qui signifie une taille maximale de 2 147 Po (4 294 967 295 x 512 Mo) par liste. Les listes Redis sont fréquemment utilisées pour implémenter des piles et des files d’attente. Redis peut ajouter ou supprimer un élément en bas (LPUSH, LPOP) ou en haut d’une liste (RPUSH, RPOP).
Elles prennent également en charge des commandes bloquantes telles que « obtenir l’élément suivant s’il en existe un, ou attendre qu’il y en ait un » (BLPOP, BLMOVE). Redis peut également exécuter des commandes inter-listes pour obtenir et supprimer un élément d’une liste et l’ajouter à une autre liste (BRPOPLPUSH). Les opérations de liste qui accèdent à sa tête ou à sa queue sont O(1), ce qui signifie qu’elles sont très efficaces. Cependant, les commandes qui manipulent des éléments à l’intérieur d’une liste sont généralement O(n). Parmi ces exemples, on trouve LINDEX, LINSERT et LSET. Faites donc preuve de prudence lors de l’exécution de ces commandes, principalement lorsque vous opérez sur de grandes listes.
Envisagez Redis Streams comme alternative aux listes lorsque vous avez besoin de stocker et de traiter une série indéterminée d’événements.
6 - Streams
Un Redis stream est une structure de données qui agit comme un journal en ajout uniquement. Vous pouvez ajouter de nouvelles entrées, elles seront horodatées et stockées, mais vous ne pouvez pas supprimer ou modifier une entrée existante. Redis Streams est souvent utilisé pour enregistrer et diffuser simultanément des événements en temps réel. Par conséquent, Redis Streams peut être pratique pour implémenter la synchronisation de données sur une liaison faible, l’ingestion de données depuis des appareils IoT, la journalisation d’événements ou un canal de discussion multi-utilisateurs.
Vous pouvez ensuite exécuter une requête de plage telle que « obtenir tous les enregistrements entre hier et aujourd’hui ». Redis génère un identifiant unique pour chaque entrée de stream. Vous pouvez utiliser ces identifiants pour récupérer leurs entrées associées ultérieurement ou pour lire et traiter toutes les entrées suivantes dans le stream.
Les streams ont été conçus pour stocker des événements non bornés, donc théoriquement, vos streams ne sont limités que par la mémoire totale des VM hébergeant votre déploiement Redis. Cependant, chaque événement peut contenir jusqu’à 4 294 967 295 (232 - 1) paires champ-valeur. Notez que chaque nom de champ et valeur est une chaîne Redis limitée à 512 Mo.
Ajouter une entrée à un stream est O(1). Accéder à une seule entrée est O(n), où n est la longueur de l’identifiant. Étant donné que les identifiants de stream sont généralement courts et de longueur fixe, cela se réduit effectivement à une recherche en temps constant. Cela n’a été rendu possible que parce que les streams ont été implémentés en utilisant des arbres radix.
Vous pouvez vous abonner à un stream pour recevoir chaque nouvel enregistrement en temps réel, vous abonner à un stream passé pour reprendre une connexion perdue et demander au stream de distribuer les enregistrements à un groupe de consommateurs pour distribuer la charge, avec des accusés de réception. Si toutes les entrées sont identiques, Redis Streams stocke les noms de champs une seule fois, il n’est donc pas nécessaire de les stocker pour les nouvelles entrées.
Redis Streams prend en charge plusieurs stratégies de découpe (pour éviter que les streams ne croissent indéfiniment) et plus d’une stratégie de consommation (voir XREAD, XREADGROUP et XRANGE).
7 - Index géospatiaux (Geospatial Indexes)
Les index géospatiaux Redis vous permettent de stocker des coordonnées et de les rechercher. Cette structure de données est utile pour trouver des points proches dans un rayon ou une boîte de délimitation donnés et calculer des distances.

Cette structure de données n’est pas vraiment une nouvelle structure de données native mais une structure de données dérivée. En interne, cette structure utilise un ensemble trié pour stocker les éléments et utilise un geo-hash calculé à partir des coordonnées comme score. La différence entre deux geo-hashes est proportionnelle à la distance physique entre les coordonnées utilisées pour calculer ces geo-hashes. Elle a également les mêmes propriétés que l’ensemble trié, avec des commandes supplémentaires pour calculer les distances entre les points ou récupérer les éléments par distance.
8 - Bitmap
Une autre structure de données dérivée dans Redis est le Bitmap. Les bitmaps Redis sont une extension du type de données chaîne qui vous permet de traiter une chaîne comme un vecteur de bits. Vous pouvez également effectuer des opérations bit à bit sur une ou plusieurs chaînes, telles que AND, OR et XOR. Par exemple, supposons que vous ayez 100 capteurs de mouvement déployés sur un terrain étiquetés de 0 à 99. Vous voulez déterminer rapidement si un capteur donné a détecté un mouvement au cours de l’heure. Tout ce que vous pouvez faire est de créer un bitmap avec une clé pour chaque heure et laisser les capteurs le définir avec leur identifiant lorsqu’ils capturent un mouvement. Vous pouvez ensuite simplement voir quels capteurs ont émis un signal sur votre terrain en affichant le bitmap.
 Un Bitmap présentant les capteurs activés sur le terrain.
Un Bitmap présentant les capteurs activés sur le terrain.
9 - Bitfield
Les bitfields Redis vous permettent de définir, d’incrémenter et d’obtenir des valeurs entières de longueur de bits arbitraire. Par exemple, vous pouvez opérer sur n’importe quoi, des entiers non signés de 1 bit aux entiers signés de 63 bits. Ces valeurs sont stockées à l’aide de chaînes Redis encodées en binaire. C’est un énorme économiseur de stockage : vous pouvez contenir des valeurs dans la plage 0-8, mais vous n’aurez besoin que de 3 bits par valeur.
Les bitfields prennent en charge les opérations atomiques de lecture, d’écriture et d’incrémentation, ce qui en fait un bon choix pour gérer des compteurs et des valeurs numériques similaires (par exemple, configuration, paramètres…).
10 - HyperLogLog
HyperLogLog est une structure de données qui estime la cardinalité d’un ensemble. Habituellement, lorsque vous avez besoin de compter des milliers ou des millions d’éléments uniques, vous devez également stocker les éléments comptés pour ne les compter qu’une seule fois. D’autre part, HyperLogLog ne conservera que le compteur dans un enregistrement de 12 Ko, et il n’utilisera jamais plus de 12 Ko.
En tant que structure de données probabiliste, HyperLogLog échange la précision parfaite contre une utilisation efficace de l’espace. L’implémentation HyperLogLog utilise jusqu’à 12 Ko et fournit une erreur standard de 0,81 %.
HyperLogLog peut estimer la cardinalité d’ensembles contenant jusqu’à 18 446 744 073 709 551 616 (246) membres. L’écriture (PFADD) vers et la lecture depuis (PFCOUNT) le HyperLogLog se font en temps et en espace constants. La fusion des HLL est O(n), où n est le nombre de sketches.
Si vous voulez compter les visiteurs uniques sur votre site web, vous utiliserez probablement les adresses IP des visiteurs comme critère de comptage. Par exemple, Hyperloglog peut vous dire que vous avez un million d’adresses IP uniques avec une précision de 0,81 %. Il n’utilisera cependant que 12 Ko de mémoire au lieu de 4 Mo pour stocker un million d’adresses IP.
11 - Redis Bloom
Il existe d’autres structures de données probabilistes dans Redis. Elles sont regroupées dans un module appelé RedisBloom qui contient un ensemble de structures de données probabilistes utiles. Les structures de données probabilistes permettent aux développeurs de contrôler la précision des résultats retournés tout en gagnant en performance et en réduisant la mémoire. Ces structures de données sont idéales pour analyser les données en streaming et les grands ensembles de données. En plus du HyperLogLog, vous pouvez utiliser :
- Filtre de Bloom et Filtre Cuckoo : Ces filtres vérifient si un élément apparaît déjà dans un grand ensemble de données. Le filtre de Bloom présente généralement de meilleures performances et une meilleure évolutivité lors de l’insertion d’éléments (donc si vous ajoutez souvent des éléments à votre ensemble de données, un filtre de Bloom peut être idéal). Les filtres Cuckoo sont plus rapides sur les opérations de vérification et permettent également les suppressions.
- Top-K : indique les k valeurs les plus fréquentes dans un ensemble de données.
- t-digest peut indiquer quelle fraction (pourcentage) des valeurs de l’ensemble de données est inférieure à une valeur donnée. Par exemple, vous pouvez utiliser t-digest pour estimer efficacement des percentiles (par exemple, les 50e, 90e et 99e percentiles) lorsque votre entrée est une séquence de mesures (comme la température ou la latence du serveur). Et ce n’est qu’un exemple ; nous en expliquons davantage ci-dessous.
 Redis Bloom (t-digest) calculant les niveaux de confiance.
Redis Bloom (t-digest) calculant les niveaux de confiance.
Ces structures de données peuvent être utiles dans plusieurs scénarios : la maintenance prédictive, la surveillance du trafic réseau ou l’analyse de jeux en ligne sont quelques exemples où vous pouvez utiliser les structures de données RedisBloom.
12 - Structures de données étendues avec les modules Redis
Les modules Redis permettent d’étendre les fonctionnalités de Redis en utilisant des extensions externes, implémentant rapidement de nouvelles commandes et structures de données Redis avec des fonctionnalités similaires à ce qui peut être fait à l’intérieur du cœur lui-même. Les modules peuvent exploiter toutes les fonctionnalités du cœur Redis sous-jacentes, telles que le stockage en mémoire, l’utilisation des structures de données existantes, la persistance, la haute disponibilité, la distribution des données avec le sharding, etc. Les modules les plus courants étendant les structures de données natives de Redis sont RedisJSON, RedisGraph et Redis TimeSeries :
-
Le module RedisJSON fournit la prise en charge JSON pour Redis. RedisJSON vous permet de stocker, mettre à jour et récupérer des valeurs JSON dans une base de données Redis, comme tout autre type de données Redis. RedisJSON fonctionne également parfaitement avec RediSearch pour vous permettre d’indexer et d’interroger des documents JSON.
RedisJSON stocke les valeurs JSON sous forme de données binaires après leur désérialisation. Cette représentation est souvent plus coûteuse, en termes de taille, que la forme sérialisée. Le type de données RedisJSON utilise au moins 24 octets (sur les architectures 64 bits) pour chaque valeur. Comme les chaînes Redis, un objet JSON peut avoir une taille maximale de 512 Mo.
Une valeur JSON passée à une commande peut avoir une profondeur allant jusqu’à 128. Si vous passez une valeur JSON à une commande contenant un objet ou un tableau avec un niveau d’imbrication de plus de 128, la commande renvoie une erreur. La création d’un nouveau document JSON (JSON.SET) est une opération O(M+N) où M est la taille du document original (s’il existe) et N est la taille du nouveau.
-
RedisGraph est une base de données graphe développée de zéro sur Redis, utilisant la nouvelle API des modules Redis pour étendre Redis avec de nouvelles commandes et capacités. En fonction du matériel sous-jacent, les résultats peuvent varier. Cependant, l’insertion d’une nouvelle relation se fait en O(1). RedisGraph peut créer plus d’un million de nœuds en moins d’une demi-seconde et former 500 000 relations en 0,3 seconde.
-
Redis TimeSeries est un module Redis qui ajoute une structure de données de séries temporelles à Redis. Il permet des insertions à haut volume, des lectures à faible latence, des requêtes par heure de début et de fin, des requêtes agrégées (min, max, moyenne, somme, plage, comptage, premier, dernier, écarts-types, variances) pour tout seau temporel, une période de rétention maximale configurable et le sous-échantillonnage/compactage des séries temporelles.
Une série temporelle est une liste chaînée de blocs de mémoire. Chaque bloc a une taille prédéfinie de 128 bits (64 bits pour l’horodatage et 64 bits pour la valeur), et il y a une surcharge de 40 bits lors de la création de votre premier point de données. La plupart des opérations sur les chaînes ont une complexité algorithmique de O(1), ce qui signifie qu’elles sont très efficaces.
Résumé
Dans cet article, nous avons découvert que les décisions de conception fondamentales prises par les développeurs il y a plus d’une décennie étaient à l’origine des performances de Redis, répondant ainsi à la question : Pourquoi Redis est-il si rapide ?
Nous avons découvert quelques-uns des principaux cas d’usage de Redis qui ont été éprouvés en production dans diverses entreprises et à diverses échelles. Ensuite, j’ai présenté les structures de données natives de Redis et celles étendues implémentées avec les modules Redis. J’ai également présenté la complexité algorithmique (notation Big O) des opérations de lecture/écriture de chaque structure de données, les limitations connues et la limite de stockage maximale de chacune. Voici un récapitulatif illustré de cet article :

Redis est très polyvalent : il y a de nombreuses façons différentes de l’utiliser. La seule limite est votre créativité.
Références
- Types de données Redis, Redis.io
- Redis 03 - Structures de données natives (1/2), Blog de François Cerbelle
- Redis 03 - Structures de données natives (2/2), Blog de François Cerbelle
- “Pourquoi Redis est-il si rapide ?”, Blog ByteByteGo
- “Annonce de ScaNN : Recherche efficace par similarité vectorielle”, Blog de recherche Google