
Le traitement de données consiste à transformer des données brutes en informations exploitables grâce à des techniques d’analyse telles que des algorithmes d’apprentissage automatique ou des modèles statistiques, selon le type de problème à résoudre dans le contexte d’une organisation.
Le traitement de données est au cœur de toute architecture de données. L’objectif ici n’est pas seulement la précision, mais aussi l’efficacité, car cette étape nécessite une puissance de calcul importante qui pourrait devenir coûteuse avec le temps sans stratégies d’optimisation appropriées.
Dans cette étape, les données brutes, déjà extraites des sources de données, sont préparées et transformées dans le format spécifique requis par les systèmes en aval. Nous verrons que plus les données progressent dans cette étape, plus elles gagnent en valeur et peuvent offrir de meilleures perspectives pour la prise de décision.
Dans cet article, nous aborderons le traitement de données à l’aide des outils Redis. Redis est un datastore open-source en mémoire utilisé comme base de données, cache, moteur de streaming et courtier de messages. Il prend en charge diverses structures de données telles que les chaînes, les hashes, les listes, les ensembles, les ensembles triés avec requêtes de plage, les bitmaps, les hyperloglogs, les index géospatiaux et les streams. De plus, Redis offre une latence inférieure à la milliseconde avec un débit très élevé : jusqu’à 200 millions d’opérations par seconde à l’échelle de la sous-milliseconde, ce qui en fait le choix évident pour les cas d’utilisation en temps réel.
Pré-requis
1 - Créer une base de données Redis
Vous devez installer et configurer quelques éléments pour cet article. Tout d’abord, vous devez préparer un cluster Redis Enterprise comme support de stockage. Ce support de stockage sera l’infrastructure cible pour les données transformées à cette étape. Vous pouvez utiliser ce projet pour créer un cluster Redis Enterprise chez le fournisseur cloud de votre choix.
Une fois le cluster Redis Enterprise créé, vous devez créer une base de données cible qui contiendra les données transformées. Redis Enterprise Software vous permet de créer et distribuer des bases de données sur un cluster de nœuds. Pour créer une nouvelle base de données, suivez les instructions ici. Nous supposons que pour cet article, vous utiliserez une base de données avec le point d’accès : redis-12000.cluster.redis-process.demo.redislabs.com:12000
2 - Installer RedisGears
Installons maintenant RedisGears sur le cluster. S’il est absent, suivez ce guide pour l’installer.
mkdir ~/tmp
curl -s https://redismodules.s3.amazonaws.com/redisgears/redisgears.Linux-ubuntu18.04-x86_64.1.2.5.zip -o ~/tmp/redis-gears.zip
cd ~/tmp
curl -v -k -s -u "<REDIS_CLUSTER_USER>:<REDIS_CLUSTER_PASSWORD>" -F "module=@./redis-gears.zip" https://<REDIS_CLUSTER_HOST>:9443/v2/modules
Traitement de données avec RedisGears
1 - RedisGears : Introduction
RedisGears est un moteur de traitement de données dans Redis. Il prend en charge les traitements transactionnels, par lots (batch) et événementiels (event-driven). RedisGears s’exécute en tant que module à l’intérieur d’un serveur Redis et est piloté via un ensemble de commandes Redis. Pour l’utiliser, vous aurez besoin d’un serveur Redis (v6 ou supérieur) et de la bibliothèque partagée du module, puis vous écrivez des fonctions qui décrivent comment vos données doivent être traitées. Vous soumettez ensuite ce code à votre déploiement Redis pour une exécution distante.
Lorsque le module Redis Gears est chargé sur les moteurs Redis, l’ensemble de commandes du moteur Redis est étendu avec de nouvelles commandes pour enregistrer, distribuer, gérer et exécuter des Gear Functions, écrites en Python, sur les shards de la base de données Redis.
Les applications clientes peuvent définir et soumettre ces fonctions Python Gear, soit pour s’exécuter immédiatement comme des traitements par lots, soit pour être enregistrées afin d’être déclenchées par des événements, tels que des modifications de keyspace Redis, des écritures dans des streams ou des déclencheurs externes. Le module Redis Gears gère toutes les complexités de distribution, coordination, planification, exécution, collecte et agrégation des résultats des Gear Functions.
Le moteur peut exécuter des fonctions de manière ad hoc, comme des traitements par lots, ou déclenchées par différents événements pour un traitement événementiel. De plus, les données stockées dans la base de données peuvent être lues et écrites par les fonctions, et un coordinateur intégré facilite le traitement des données distribuées dans un cluster.
La première étape de toute Gear Function est toujours l’un des six « Readers » disponibles qui opèrent sur différents types de données d’entrée :
- KeysReader : clés et valeurs Redis.
- KeysOnlyReader : clés Redis uniquement.
- StreamReader : messages de Redis Stream.
- PythonReader : générateur Python arbitraire.
- ShardsIDReader : identifiant de shard.
- CommandReader : arguments de commande provenant du client applicatif.
Les Readers peuvent être paramétrés pour restreindre le sous-ensemble de données sur lequel ils doivent opérer, par exemple en spécifiant un motif pour les clés ou les streams à lire.
Selon le type de Reader, les Gear Functions peuvent être exécutées immédiatement à la demande, comme des traitements par lots, ou de manière événementielle en les enregistrant pour se déclencher automatiquement sur divers types d’événements.
Les Gear Functions sont composées d’une séquence d’étapes ou d’opérations, telles que Map, Filter, Aggregate, GroupBy, et plus encore. Ces opérations sont paramétrées avec des fonctions Python que vous définissez selon vos besoins.
Une opération est l’élément de base des Gears Functions. Différents types d’opérations peuvent être utilisés pour obtenir une variété de résultats répondant à divers besoins de traitement de données. Les opérations peuvent avoir zéro ou plusieurs arguments qui contrôlent leur fonctionnement.
Les étapes/opérations sont enchaînées les unes aux autres par le runtime Redis Gears, de sorte que la sortie d’une étape devient l’entrée de l’étape suivante.
Une action est un type d’opération particulier qui constitue toujours la dernière étape d’une fonction. Il existe deux types d’actions :
- Run : exécute la fonction immédiatement en mode batch
- Register : enregistre l’exécution de la fonction pour être déclenchée par un événement
Chaque shard du cluster Redis exécute sa propre « instance » de la Gear Function en parallèle sur les données locales du shard concerné, sauf si les données sont explicitement collectées ou implicitement réduites à leur résultat global final à la fin de la fonction.

2 - RedisGears : premiers pas
La façon la plus simple d’écrire et d’exécuter une Gears Function peut être réalisée via l’interface client Redis (redis-cli).
Une fois à l’invite redis-cli, tapez ce qui suit puis appuyez sur <ENTRÉE> pour l’exécuter :
$ redis-cli -h cluster.redis-process.demo.redislabs.com -p 12000
cluster.redis-process.demo.redislabs.com:12000> RG.PYEXECUTE "GearsBuilder().run()"
1) (empty array)
2) (empty array)
La fonction RedisGears que vous venez d’exécuter a répondu avec un tableau de résultats vide parce qu’elle n’avait pas de données à traiter (la base de données est vide). L’entrée initiale de toute fonction RedisGears peut être zéro, un ou plusieurs enregistrements générés par un Reader.
Un Record est l’abstraction de base de RedisGears représentant les données dans le flux de la fonction. Les enregistrements de données d’entrée sont transmis d’une étape à l’autre et sont finalement retournés comme résultat.
Un Reader est la première étape obligatoire de toute fonction, et chaque fonction possède exactement un Reader. D’abord, un Reader lit des données et génère des enregistrements d’entrée à partir de celles-ci. Ensuite, les enregistrements d’entrée sont consommés par la fonction.
Il existe plusieurs types de Readers que le moteur propose. Le type de Reader d’une fonction est toujours déclaré lors de l’initialisation de son contexte GearsBuilder(). Sauf déclaration explicite, le Reader d’une fonction utilise par défaut le KeysReader, ce qui signifie que les lignes suivantes sont interchangeables :
GearsBuilder() # The context builder's default is
GearsBuilder('KeysReader') # the same as using the string 'KeysReader'
GearsBuilder(reader='KeysReader') # and as providing the 'reader' argument
GB() # GB() is an alias for GearsBuilder()
Ajoutons une paire de Hashes représentant des personnages fictifs et un hash représentant un pays. Exécutez ces commandes Redis :
HSET person:1 name "Rick Sanchez" age 70
HSET person:2 name "Morty Smith" age 14
HSET country:FR name "France" continent "Europe"
Maintenant que la base de données contient trois clés, la fonction retourne trois enregistrements de résultats, un pour chacun.
cluster.redis-process.demo.redislabs.com:12000> RG.PYEXECUTE "GearsBuilder().run()"
1) 1) "{'event': None, 'key': 'person:1', 'type': 'hash', 'value': {'age': '70', 'name': 'Rick Sanchez'}}"
2) "{'event': None, 'key': 'person:2', 'type': 'hash', 'value': {'age': '14', 'name': 'Morty Smith'}}"
3) "{'event': None, 'key': 'country:FR', 'type': 'hash', 'value': {'continent': 'Europe', 'name': 'France'}}"
2) (empty array)
Par défaut, le KeysReader lit toutes les clés de la base de données. Ce comportement peut être contrôlé en fournissant au Reader un motif de type glob qui, lors de l’exécution de la fonction, est comparé à chaque nom de clé. Le Reader génère des enregistrements d’entrée uniquement pour les clés dont les noms correspondent au motif.
Le motif de nom de clés du Reader est défini sur « * » par défaut, de sorte que tout nom de clé y correspond. Une façon de remplacer le motif par défaut est via la méthode run() du contexte. Pour obtenir des enregistrements d’entrée composés uniquement de personnes, nous pouvons utiliser le motif person:* pour écarter les clés qui ne correspondent pas :
cluster.redis-process.demo.redislabs.com:12000> RG.PYEXECUTE "GearsBuilder().run('person:*')"
1) 1) "{'event': None, 'key': 'person:1', 'type': 'hash', 'value': {'age': '70', 'name': 'Rick Sanchez'}}"
2) "{'event': None, 'key': 'person:2', 'type': 'hash', 'value': {'age': '14', 'name': 'Morty Smith'}}"
2) (empty array)
Le Reader peut générer n’importe quel nombre d’enregistrements d’entrée. Ces enregistrements sont utilisés comme entrée pour l’étape suivante du flux, dans laquelle les enregistrements peuvent être traités d’une certaine manière, puis transmis. Plusieurs étapes peuvent être ajoutées au flux, transformant de manière significative ses enregistrements d’entrée en un ou plusieurs enregistrements de sortie.
Pour voir comment cela fonctionne en pratique, nous allons refactoriser notre fonction pour utiliser une opération filter() comme étape plutôt que le motif de clés du Reader :
cluster.redis-process.demo.redislabs.com:12000> RG.PYEXECUTE "GearsBuilder().filter(lambda x: x['key'].startswith('person:')).run()"
1) 1) "{'event': None, 'key': 'person:1', 'type': 'hash', 'value': {'age': '70', 'name': 'Rick Sanchez'}}"
2) "{'event': None, 'key': 'person:2', 'type': 'hash', 'value': {'age': '14', 'name': 'Morty Smith'}}"
2) (empty array)
L’opération filter() invoque la fonction de filtrage une fois pour chaque enregistrement d’entrée reçu. L’enregistrement d’entrée désigné par x dans les exemples est un dictionnaire dans notre cas, et la fonction vérifie si la valeur de sa clé correspond au motif demandé.
La principale différence entre la fonction qui utilise le motif de clés du Reader et celle qui utilise l’étape réside dans le moment où le filtrage se produit. Dans le cas du motif de clés, le filtrage est effectué par le Reader lui-même, après l’obtention des noms de clés mais avant la lecture de leurs valeurs. En revanche, avec l’opération filter() dans le flux, le Reader lit toutes les clés (et leurs valeurs) qui ne sont filtrées par l’étape que par la suite.
Les fonctions peuvent être aussi complexes que nécessaire et peuvent comprendre n’importe quel nombre d’étapes exécutées séquentiellement. De plus, l’API Python de RedisGears permet l’utilisation de toutes les fonctionnalités du langage, y compris l’importation et l’utilisation de packages externes.
Taper des fonctions à l’invite (redis-cli) devient vite fastidieux. Vous pouvez imaginer la complexité lorsque vous avez une logique de traitement de données complexe à implémenter. Pour cette raison, au lieu d’utiliser le mode interactif, vous pouvez stocker le code de vos fonctions dans un fichier texte ordinaire et demander à redis-cli d’en envoyer le contenu pour exécution.
cat myFunction.py | redis-cli -h redis-12000.cluster.redis-process.demo.redislabs.com -p 12000 -x RG.PYEXECUTE
3 - RedisGears : Traitement batch
Une fois les données collectées dans Redis, elles peuvent entrer dans l’étape de préparation des données. La préparation des données, souvent appelée « pré-traitement », est l’étape à laquelle les données brutes sont nettoyées et organisées pour les étapes suivantes du traitement. Pour cela, RedisGears propose plusieurs opérations permettant de filtrer les erreurs et les valeurs invalides, puis de préparer les données pour les étapes suivantes. Cette étape vise à éliminer les mauvaises données (redondantes, incomplètes ou incorrectes) et à créer des données de haute qualité pour une prise de décision optimale basée sur les données.
Rappelons ce fichier CSV que nous avons ingéré dans Redis (voir Data & Redis partie 1)
| AirportID | Name | City | Country | IATA | ICAO | Latitude | Longitude | Altitude | Timezone | DST | Tz | Type | Source |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Goroka Airport | Goroka | Papua New Guinea | GKA | AYGA | -6.081689834590001 | 145.391998291 | 5282 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 2 | Madang Airport | Madang | Papua New Guinea | MAG | AYMD | -5.20707988739 | 145.789001465 | 20 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 3 | Mount Hagen Kagamuga Airport | Mount Hagen | Papua New Guinea | HGU | AYMH | -5.826789855957031 | 144.29600524902344 | 5388 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 4 | Nadzab Airport | Nadzab | Papua New Guinea | LAE | AYNZ | -6.569803 | 146.725977 | 239 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 5 | Port Moresby Jacksons International Airport | Port Moresby | Papua New Guinea | POM | AYPY | -9.443380355834961 | 147.22000122070312 | 146 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 6 | Wewak International Airport | Wewak | Papua New Guinea | WWK | AYWK | -3.58383011818 | 143.669006348 | 19 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
Nous avons utilisé RIOT-File pour ingérer en masse ce fichier CSV dans Redis sous forme d’objets JSON. Les objets étaient préfixés par airport, et AirportID était la clé primaire.
Imaginons que seuls les aéroports dans un rayon de 2 000 km de Paris soient pertinents à conserver dans le jeu de données. RedisGears peut traiter le jeu de données brut comme un bloc batch airport:* et créer un geo set Redis avec la fonction create_geo_set. Cette structure de données est utile pour trouver des points à proximité dans un rayon ou une zone donnée. Nous l’utilisons pour filtrer les aéroports et ne conserver que ceux dans un rayon de 2 000 km des coordonnées de Paris (Longitude : 2.3488, Latitude : 48.85341) comme détaillé dans la fonction paris_nearest_airports. Finalement, RedisGears supprime tous les aéroports hors de ce rayon spécifique et retourne le nombre d’aéroports supprimés du jeu de données.
import json
def create_geo_set(key):
airport = json.loads(execute("JSON.GET", key))
execute("GEOADD", "geoAirport", airport["Longitude"], airport["Latitude"], key)
return key
def paris_nearest_airports(dist):
paris_long = 2.3488
paris_lat = 48.85341
return execute("GEORADIUS", "geoAirport", paris_long, paris_lat, dist, "km")
GearsBuilder()\
.map(lambda x: x['key'])\
.map(lambda y: create_geo_set(y))\
.filter(lambda z: (z not in paris_nearest_airports(2000)))\
.map(lambda e: execute('JSON.DEL', e))\
.count()\
.run("airport:*")
## Expected result: [289]
De plus, vous pouvez utiliser RedisGears pour éliminer les informations inexactes et combler les lacunes. Cela inclut la suppression des détails inutiles, la déduplication, la correction des données corrompues ou mal formatées, le traitement des valeurs aberrantes, le remplissage des champs vides avec des valeurs appropriées et la masquage des entrées confidentielles.
Créons les hashes représentant quelques personnages :
HSET person:1 name "Rick Sanchez" age 70
HSET person:2 name "Morty Smith" age 14
HSET person:3 name "Summer Smith" age 17
HSET person:4 name "Beth Smith" age 35
HSET person:5 name "Shrimply Pibbles" age 87
Vous pouvez utiliser la fonction RedisGears suivante pour formater le jeu de données et obtenir les prénoms et noms séparés dans différents champs.
def split_name(key):
person_name = execute("HGET", key, "name")
first_name = person_name.split(' ')[0]
last_name = person_name.split(' ')[1]
execute("HMSET", key, "fname", first_name, "lname", last_name)
execute("HDEL", key, "name")
return execute("HGETALL", key)
GearsBuilder()\
.map(lambda x: x['key'])\
.map(split_name)\
.collect()\
.run("person:*")
## Expected result:
# 1) "['age', '35', 'fname', 'Beth', 'lname', 'Smith']"
# 2) "['age', '70', 'fname', 'Rick', 'lname', 'Sanchez']"
# 3) "['age', '87', 'fname', 'Shrimply', 'lname', 'Pibbles']"
# 4) "['age', '14', 'fname', 'Morty', 'lname', 'Smith']"
# 5) "['age', '17', 'fname', 'Summer', 'lname', 'Smith']"
Le temps d’exécution d’une fonction dépend de ses entrées et de sa complexité. C’est pourquoi RedisGears exécute les fonctions batch de manière asynchrone dans un thread s’exécutant en arrière-plan, permettant ainsi au processus Redis principal de continuer à traiter les requêtes pendant que le moteur traite les données.
Le comportement par défaut de RG.PYEXECUTE est de bloquer le client appelant. Un client bloqué attend la réponse du serveur avant de continuer, et dans le cas d’une fonction RedisGears, cela signifie attendre que le traitement soit terminé. Ensuite, les résultats générés sont retournés au client qui est débloqué.
Le blocage simplifie grandement la logique du client, mais pour les tâches longues, il est parfois souhaitable que le client continue son travail pendant l’exécution de la fonction. Les fonctions batch RedisGears peuvent être exécutées dans ce mode non-bloquant pour le client en ajoutant l’argument UNBLOCKING à la commande RG.PYEXECUTE. Par exemple, nous pouvons exécuter la première version de notre fonction simple de manière non bloquante :
$ cat myFunction.py | redis-cli -h redis-12000.cluster.redis-process.demo.redislabs.com -p 12000 -x RG.PYEXECUTE UNBLOCKING
"0000000000000000000000000000000000000000-0"
Lors de l’exécution en mode UNBLOCKING, le moteur répond avec un identifiant d’exécution (Execution ID) qui représente l’exécution de la fonction en interne. Les identifiants d’exécution sont uniques. Ils sont composés de deux parties, un identifiant de shard et une séquence, délimités par un tiret (‘-‘). L’identifiant de shard est unique pour chaque shard dans un cluster Redis, tandis que la séquence est incrémentée à chaque exécution d’une fonction par le moteur.
En appelant la commande RG.DUMPEXECUTIONS, nous pouvons récupérer la liste des exécutions du moteur, qui ne contient actuellement qu’une seule entrée représentant la fonction que nous venons d’exécuter :
$ redis-cli -h redis-12000.cluster.redis-process.demo.redislabs.com -p 12000 -c RG.DUMPEXECUTIONS
1) 1) "executionId"
2) "0000000000000000000000000000000000000000-0"
3) "status"
4) "done"
Comme l’exécution de la fonction est terminée, indiquée par la valeur done dans le champ status, nous pouvons maintenant obtenir ses résultats avec la commande RG.GETRESULTS. Comme son nom l’indique, la commande retourne les résultats de l’exécution spécifiée par son identifiant :
$ redis-cli -h redis-12000.cluster.redis-process.demo.redislabs.com -p 12000 -c RG.GETRESULTS 0000000000000000000000000000000000000000-0
1) 1)"['age', '35', 'fname', 'Beth', 'lname', 'Smith']"
2)"['age', '70', 'fname', 'Rick', 'lname', 'Sanchez']"
3)"['age', '87', 'fname', 'Shrimply', 'lname', 'Pibbles']"
4)"['age', '14', 'fname', 'Morty', 'lname', 'Smith']"
5)"['age', '17', 'fname', 'Summer', 'lname', 'Smith']"
Avant le statut done, le moteur aurait répondu avec une erreur.
Notez que nous obtenons les résultats collectés (les personnes) dans un ordre différent de celui dans lequel ils ont été créés. C’est parce que le shard d’origine a distribué (mappé) la fonction à tous les autres shards et a ensuite collecté les résultats locaux intermédiaires avant de retourner une réponse fusionnée.
Avant de retourner les résultats, le coordinateur du shard d’origine collecte les résultats locaux de chaque shard. C’est le comportement par défaut, et son utilisation ajoute implicitement une opération collect() à la fonction comme dernière étape.
Bien que les données soient distribuées sur les shards du cluster, la fonction retourne des résultats identiques (à l’ordre près) à ce qu’une instance unique aurait retourné. C’est parce que le shard d’origine a distribué (mappé) la fonction aux shards du cluster et a ensuite collecté les résultats locaux intermédiaires de tous les autres shards avant de retourner une réponse fusionnée. Ce concept est connu sous le nom de MapReduce.

4 - RedisGears : Traitement de stream
Jusqu’à présent, nous avons exécuté des fonctions batch, ce qui signifie que nous avons utilisé l’action run() pour que la fonction s’exécute immédiatement. Exécutée de cette façon, le Reader de la fonction récupère les données existantes puis s’arrête. Une fois le Reader arrêté, la fonction est terminée et ses résultats sont retournés.
Dans de nombreux cas, les données changent continuellement et doivent être traitées de manière événementielle. À cette fin, les fonctions RedisGears peuvent être enregistrées comme des déclencheurs qui « se déclenchent » sur des événements spécifiques pour implémenter ce que l’on appelle des flux de traitement de stream. Le Reader d’une fonction enregistrée ne lit pas les données existantes mais attend de nouvelles entrées pour déclencher les étapes.
La fonction est exécutée une fois pour chaque nouvel enregistrement d’entrée par défaut lorsqu’elle est enregistrée pour traiter des données en streaming. Cependant, alors que les fonctions batch sont exécutées exactement une fois, l’exécution d’une fonction enregistrée peut être déclenchée un nombre quelconque de fois en réponse aux événements qui la pilotent.
Pour essayer ceci, nous allons retourner les hashes de personnes avec les noms séparés en deux champs, comme vu précédemment. Mais au lieu de l’exécuter en mode batch, nous l’enregistrons (register()) pour les personnes entrantes :
def split_name(key):
person_name = execute("HGET", key, "name")
first_name = person_name.split(' ')[0]
last_name = person_name.split(' ')[1]
execute("HMSET", key, "fname", first_name, "lname", last_name)
execute("HDEL", key, "name")
return execute("HGETALL", key)
GearsBuilder()\
.map(lambda x: x['key'])\
.map(split_name)\
.collect()\
.register("person:*")
## Expected result: ['OK']
Ajoutons une nouvelle personne :
HSET person:6 name "Amine El-Kouhen" age 36
Dès qu’une nouvelle personne est définie dans Redis, la fonction sera exécutée, et les résultats peuvent être obtenus lorsque le statut d’exécution indique done.
$ redis-cli -h redis-12000.cluster.redis-process.demo.redislabs.com -p 12000 -c RG.DUMPEXECUTIONS
1) 1) "executionId"
2) "0000000000000000000000000000000000000000-119"
3) "status"
4) "done"
5) "registered"
6) (integer) 1
Vous pouvez ensuite obtenir les résultats de l’exécution spécifiée par son identifiant avec la commande RG.GETRESULTS :
$ redis-cli -h redis-12000.cluster.redis-process.demo.redislabs.com -p 12000 -c RG.GETRESULTS 0000000000000000000000000000000000000000-119
1) 1) "['age', '36', 'fname', 'Amine', 'lname', 'El-Kouhen']"
2) (empty array)
Nous pouvons utiliser le traitement de stream avec Gears pour effectuer des fonctions d’agrégation qui évoluent au fur et à mesure que les données sont ingérées dans Redis. Par exemple, supposons que les données financières d’Apple soient stockées dans Redis. Les parties prenantes pourraient avoir besoin de voir le compte de résultat (Profit and Loss statement) en temps réel.

Le Compte de Résultat (P&L) est un état financier qui commence par les revenus et déduit les coûts et dépenses pour obtenir le bénéfice net d’une entreprise, la rentabilité d’une période déterminée. Implémentons d’abord la logique que nous souhaitons exposer à nos utilisateurs :
def grouping_by_account(x):
return x['value']['account']
def summer(k, a, r):
''' Accumulates the amounts '''
a = execute("GET", k)
a = float(a if a else 0) + float(r['value']['amount'])
execute("SET", k, a)
return a
def create_pnl(a):
if a['key'] == "Revenue":
execute("HSET", "pnl", "total_net_sales", execute("GET", a['key']))
elif a['key'] == "Cost":
execute("HSET", "pnl", "total_cost_sales", execute("GET", a['key']))
elif a['key'] == "Operating Expenses":
execute("HSET", "pnl", "operating_expenses", execute("GET", a['key']))
elif a['key'] == "Provision":
execute("HSET", "pnl", "provision", execute("GET", a['key']))
def get_value_or_zero(field):
r = execute("HGET", "pnl", field)
return float(r) if r else 0
def consolidate_pnl(a):
gross_margin = get_value_or_zero("total_net_sales") - get_value_or_zero("total_cost_sales")
operating_income = get_value_or_zero("gross_margin") - get_value_or_zero("operating_expenses")
net_income = get_value_or_zero("operating_income") - get_value_or_zero("provision")
execute("HSET", "pnl", "gross_margin", gross_margin)
execute("HSET", "pnl", "operating_income", operating_income)
execute("HSET", "pnl", "net_income", net_income)
gb = GearsBuilder()
gb.groupby(grouping_by_account, summer)
gb.map(create_pnl)
gb.map(consolidate_pnl)
gb.register('record:*')
Dans cette fonction Gears, nous avons introduit l’opération groupby(). Elle effectue le regroupement des enregistrements selon des critères de regroupement et peut réaliser une agrégation par les éléments de regroupement. Ici, la fonction effectue une somme de tous les enregistrements groupés par nature comptable (par exemple, Revenus, Coûts, etc.)
Une fois le regroupement effectué, la fonction crée un hash pnl qui contient le calcul des lignes composant le compte de résultat et les consolide pour calculer le bénéfice net.
Comme vous pouvez l’observer, cette fonction est une procédure déclenchée par événement (autrement dit, enregistrée). Cela signifie qu’elle sera exécutée dès qu’un enregistrement financier est défini dans Redis. Ainsi, les utilisateurs finaux peuvent obtenir des informations en temps réel sur la situation financière de l’entreprise avec moins d’effort.
Exécutons ces commandes pour créer de nouveaux enregistrements financiers. Pour simplifier l’exemple, chaque transaction financière ne consiste qu’en une nature comptable et un montant de transaction :
HSET record:1 account "Revenue" amount 316199
HSET record:2 account "Revenue" amount 78129
HSET record:3 account "Cost" amount 201471
HSET record:4 account "Cost" amount 22075
HSET record:5 account "Operating Expenses" amount 26251
HSET record:6 account "Operating Expenses" amount 25094
HSET record:7 account "Provision" amount 19300
En supposant que tous les enregistrements sont des transactions réelles, les parties prenantes peuvent obtenir la situation financière de l’entreprise en temps réel, et les différents revenus et dépenses sont mis à jour en continu.
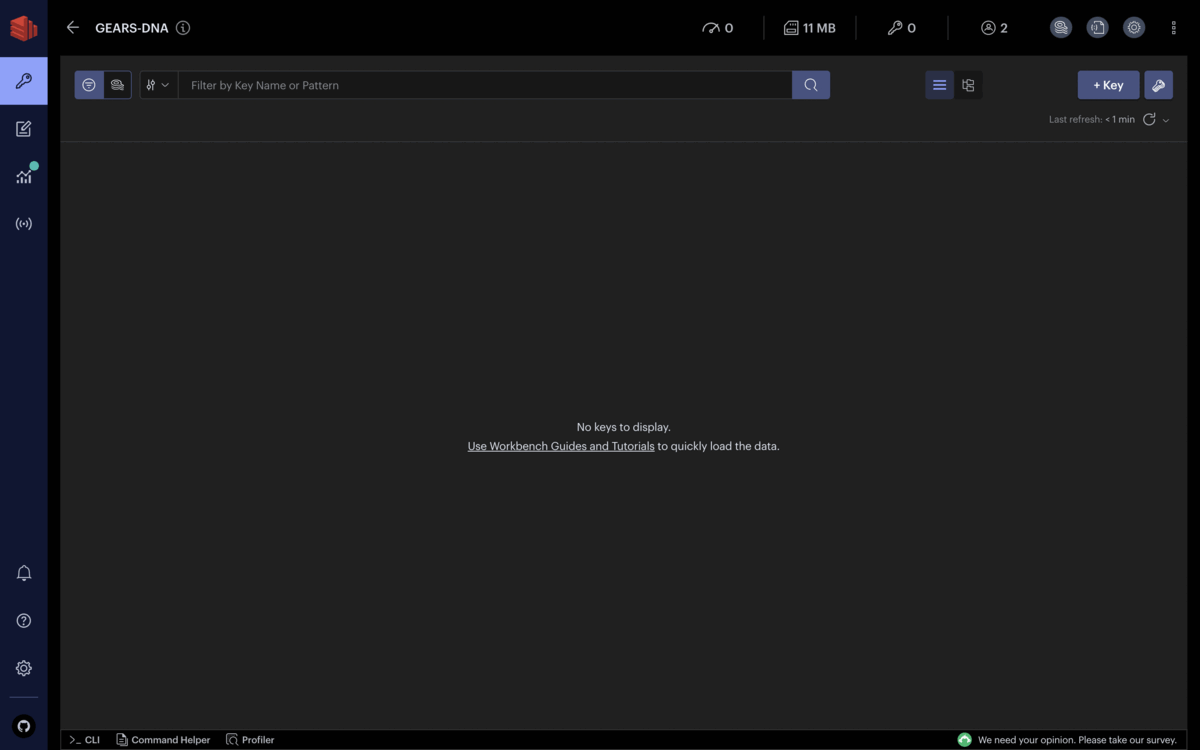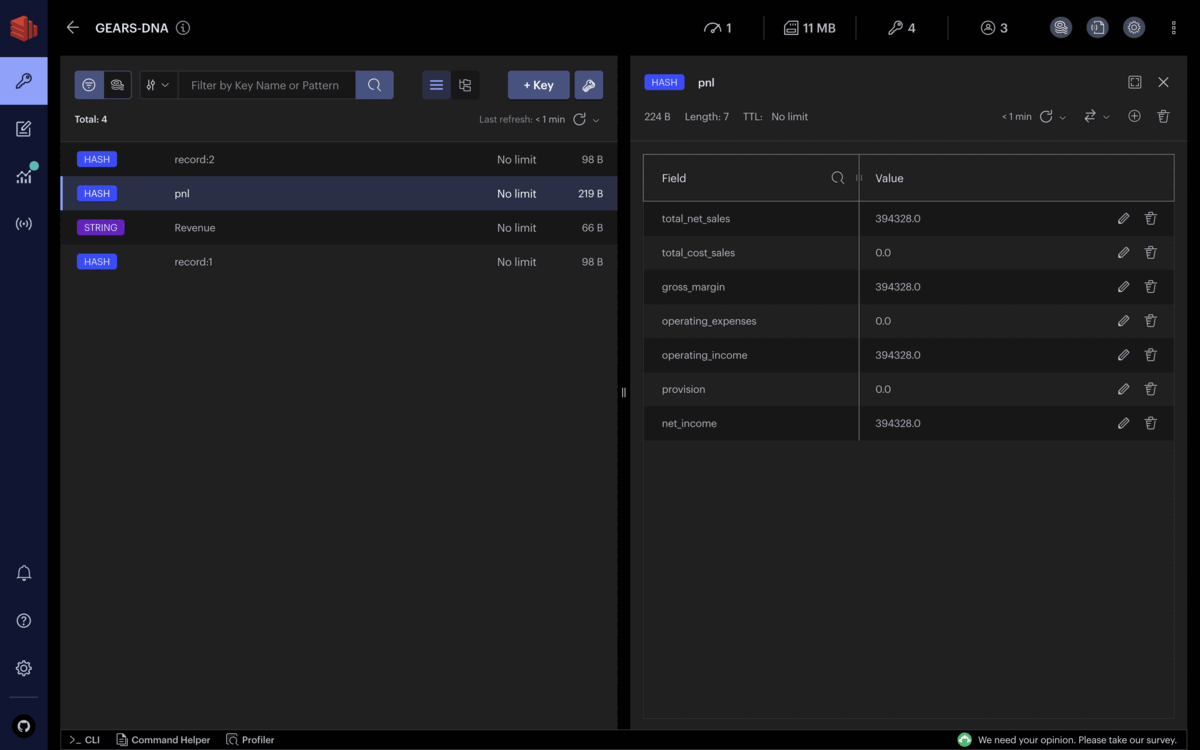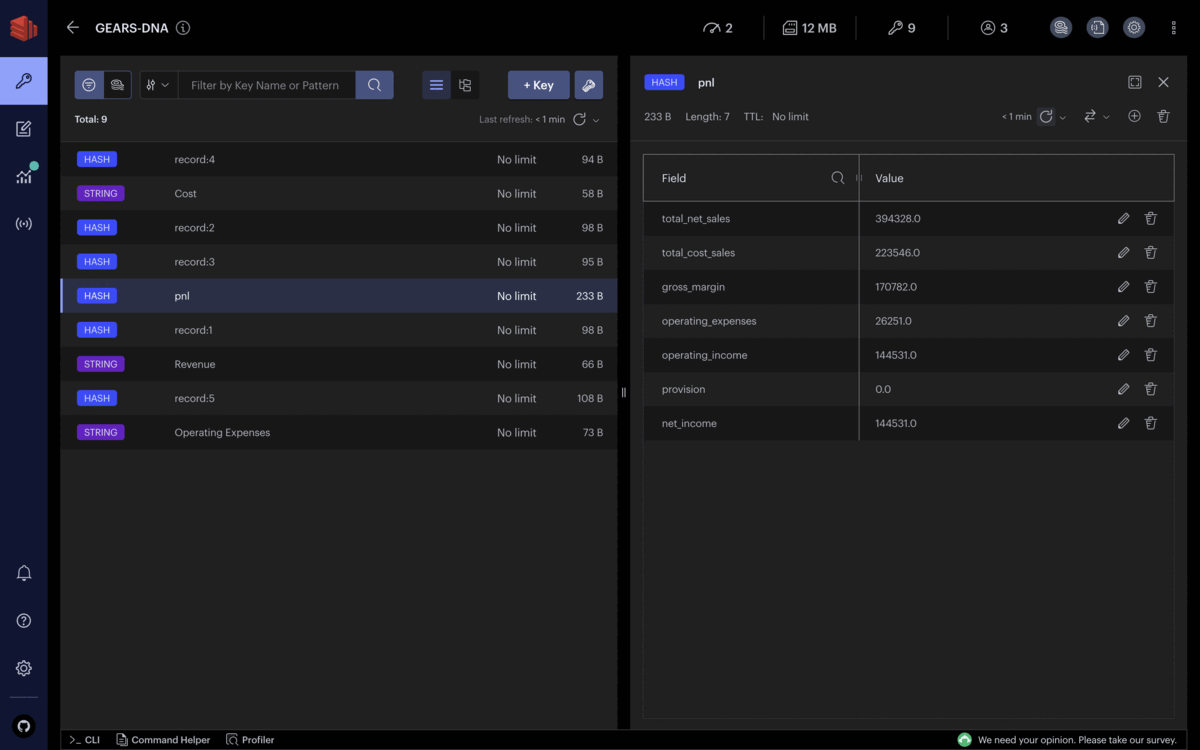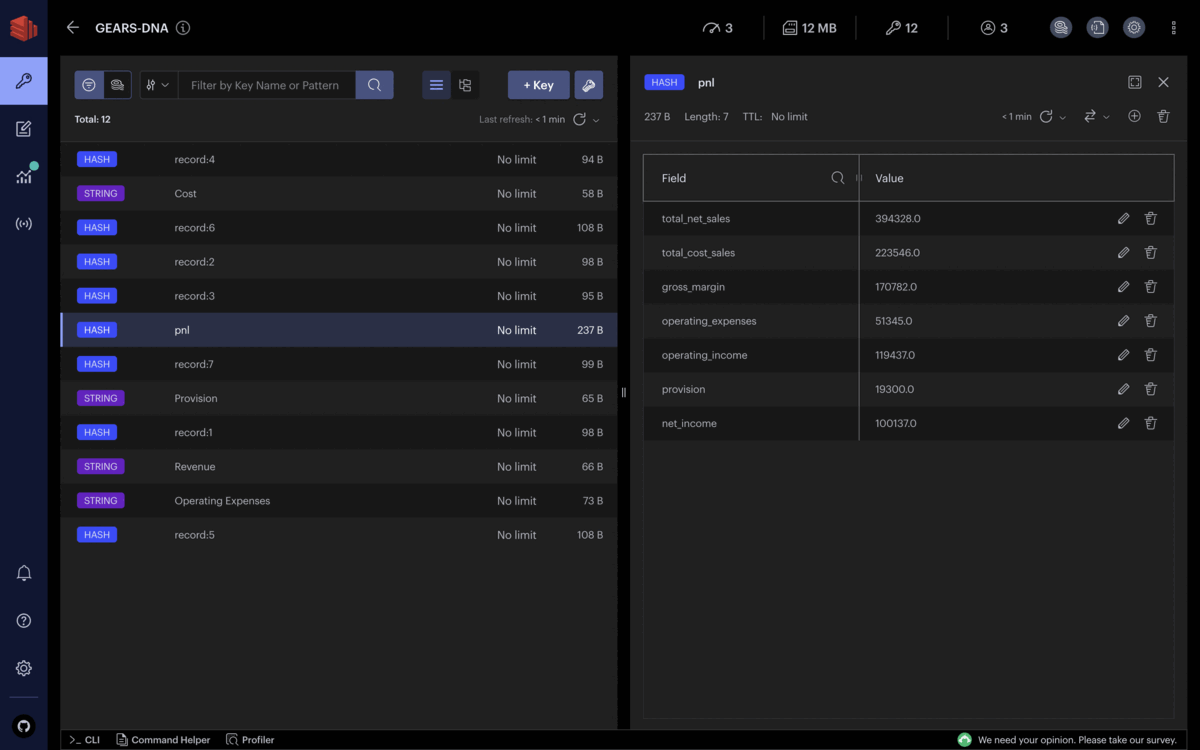
Chaque enregistrement financier ajouté à Redis est immédiatement capturé, groupé par nature comptable et intégré dans le calcul des principales lignes du compte de résultat. Vous pouvez observer que le bénéfice net évolue aussi souvent que des enregistrements financiers continuent d’entrer dans Redis.
Résumé
Dans cet article, nous avons testé le moteur de traitement de données de Redis appelé RedisGears. Il prend en charge le traitement transactionnel, batch et événementiel des données Redis grâce à des fonctions qui décrivent comment les données doivent être traitées.
Nous avons vu comment RedisGears traite les données en mode batch à l’aide du bloc run et comment les fonctions RedisGears peuvent être déclenchées pour traiter un flux de données en enregistrant des fonctions au préalable. Dans la version 2.0 (encore en développement), RedisGears permet d’exécuter des fonctions JavaScript via des appels API, des déclenchements temporels et des déclenchements par keyspace, que nous avons testés dans la section de traitement de stream, offrant ainsi une meilleure expérience utilisateur que la version actuelle.
De plus, dans la future version de RedisGears, les fonctions seront considérées comme une partie intégrante de la base de données (artefacts de première classe de la base de données). Ainsi, Redis garantit leur disponibilité via la persistance et la réplication des données.
Références
- Redis Gears, Guide du développeur