
“Data & Snowflake” est une nouvelle série qui présente Snowflake en tant que plateforme de données complète. À travers cette série, vous apprendrez à collecter, stocker, traiter, analyser et exposer des données à l’aide des différents outils de Snowflake.
La plateforme de données Snowflake n’est pas construite sur une technologie de base de données existante ni sur des plateformes logicielles “big data” telles que Hadoop. Au lieu de cela, Snowflake combine un tout nouveau moteur de requêtes SQL avec une architecture innovante conçue nativement pour le cloud. Pour l’utilisateur, Snowflake offre toutes les fonctionnalités d’une base de données analytique d’entreprise, ainsi que de nombreuses fonctionnalités supplémentaires et capacités uniques.
Snowflake est un véritable service auto-géré, ce qui signifie :
- Snowflake fonctionne entièrement sur une infrastructure cloud. Tous les composants du service Snowflake (à l’exception des clients en ligne de commande optionnels, des pilotes et des connecteurs) s’exécutent sur des infrastructures cloud publiques.
- Snowflake utilise des instances de calcul virtuelles pour ses besoins en calcul et un service de stockage pour la persistance des données. Snowflake ne peut pas fonctionner sur des infrastructures cloud privées (sur site ou hébergées).
- Snowflake n’est pas un logiciel packagé qu’un utilisateur peut installer. Snowflake gère tous les aspects de l’installation et des mises à jour logicielles.
Dans les articles précédents, j’ai expliqué que l’architecture de données est un composant essentiel de toute stratégie data. Il n’est donc pas surprenant que le choix de la bonne architecture de données soit une priorité absolue pour de nombreuses organisations. Les architectures de données peuvent être classées selon la vélocité des données, et les plus populaires dans cette catégorie sont Lambda et Kappa.
Dans ce premier article, j’illustrerai comment Snowflake peut mettre en œuvre chacune de ces architectures grâce à la multitude d’outils et de fonctionnalités qu’il propose. Une implémentation détaillée de chaque étape du cycle de vie des données sera publiée dans de futurs articles.
Qu’est-ce qui fait une « bonne » architecture de données ?
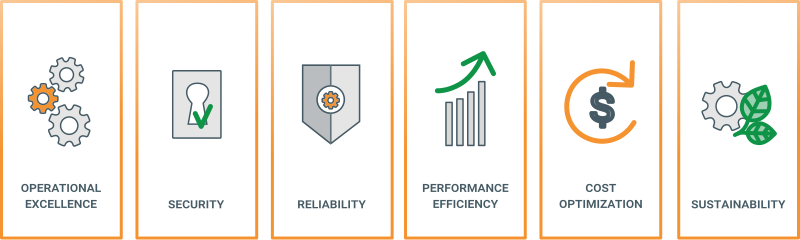
On reconnaît le « bon » en voyant le pire. Les mauvaises architectures de données sont étroitement couplées, rigides, trop centralisées et utilisent les mauvais outils, ce qui freine le développement et la gestion du changement. Une bonne architecture de données doit avant tout répondre aux exigences métier avec un ensemble de blocs de construction largement réutilisables, tout en respectant des bonnes pratiques bien définies (principes) et en effectuant les compromis appropriés. Nous nous inspirons des principes d’une « bonne » architecture de données à partir de plusieurs sources, notamment le AWS Well-Architected Framework. Il comprend six piliers :
- Efficacité des performances : La capacité d’un système à s’adapter aux variations de charge.
- Fiabilité : La capacité d’un système à se remettre de pannes et à continuer à fonctionner.
- Optimisation des coûts : Gérer les coûts pour maximiser la valeur produite.
- Sécurité : Protéger les applications et les données contre les menaces.
- Excellence opérationnelle : Les processus d’exploitation qui maintiennent un système en production.
- Durabilité : Minimiser les impacts environnementaux liés à l’exécution des charges de travail du système.
Dans la deuxième partie de cet article, j’évaluerai les architectures de données implémentées avec Snowflake au regard de cet ensemble de principes.
Parce que l’architecture de données est une discipline abstraite, il est utile de raisonner par catégories d’architecture. La section suivante présente des exemples représentatifs des architectures de données les plus connues aujourd’hui. Bien que cet ensemble d’exemples ne soit pas exhaustif, l’intention est de vous exposer aux patterns d’architecture de données les plus courants et de donner un aperçu de l’analyse des compromis nécessaire lors de la conception d’une bonne architecture pour votre cas d’usage.
Architecture de données Lambda avec Snowflake
Le terme “Lambda” est dérivé du calcul lambda (λ), qui décrit une fonction s’exécutant en calcul distribué sur plusieurs nœuds en parallèle. L’architecture de données Lambda a été conçue pour fournir un système évolutif, tolérant aux pannes et flexible pour traiter de grandes quantités de données, et permet l’accès aux méthodes de traitement par lots et de traitement de flux de manière hybride. Elle a été développée en 2011 par Nathan Marz, le créateur d’Apache Storm, pour résoudre les défis du traitement de données en temps réel à grande échelle.
L’architecture Lambda est une architecture idéale lorsqu’on dispose d’une variété de charges de travail et de vélocités de données. Elle peut gérer de grands volumes de données et fournir des résultats de requêtes à faible latence, ce qui la rend adaptée aux applications d’analytique en temps réel telles que les tableaux de bord et les rapports. De plus, cette architecture est utile pour le traitement par lots (ex. : nettoyage, transformation ou agrégation de données), pour les tâches de traitement de flux (ex. : gestion d’événements, recommandation en temps réel, détection d’anomalies ou prévention de la fraude), et pour la construction de référentiels centralisés appelés “data lakes” pour stocker des informations structurées/non structurées.
La caractéristique fondamentale de l’architecture Lambda est qu’elle utilise deux systèmes de traitement distincts pour gérer différents types de charges de travail. Le premier est un système de traitement par lots, qui traite les données en grands lots et stocke les résultats dans un entrepôt de données centralisé (ex. : un data warehouse ou un data lake). Le second est un système de traitement de flux, qui traite les données en temps réel à leur arrivée et stocke les résultats dans un entrepôt de données distribué.
Architecture Lambda avec Snowflake.
Dans le diagramme ci-dessus, vous pouvez voir les principaux composants de l’architecture Lambda implémentée avec Snowflake. À un niveau élevé, l’architecture se compose des couches suivantes :
- Couche d’ingestion : Dans cette couche, les données brutes sont extraites d’une ou plusieurs sources de données, répliquées, puis ingérées dans un stage Snowflake. En fonction du volume et de la vélocité des données, vous choisirez l’ingestion par lots ou l’ingestion en flux (les différences sont largement discutées ici). Snowflake propose différents outils qui permettent les deux types d’ingestion :
1- Les données brutes (telles quelles) sont copiées depuis la source vers la zone d’atterrissage Snowflake. Pour implémenter cette opération, le Virtual Warehouse Snowflake exécute des commandes COPY Snowflake déclenchées par un orchestrateur tel qu’Apache Airflow.
Données brutes copiées dans les stages.
2- Snowpipe charge les données depuis des fichiers dès qu’ils sont disponibles dans un stage. Les données sont chargées conformément à l’instruction COPY définie dans un pipe référencé. Un pipe est un objet Snowflake nommé de premier ordre contenant l’instruction COPY utilisée par Snowpipe. L’instruction COPY identifie l’emplacement source des fichiers de données (c’est-à-dire un stage) et une table cible. Tous les types de données sont pris en charge, y compris les types de données semi-structurées tels que JSON et Avro.
Ingestion par lots à faible fréquence.
3- L’appel de l’API Snowpipe Streaming déclenche le chargement à faible latence de lignes de données en streaming à l’aide du SDK Snowflake Ingest et de votre propre code d’application géré. L’API d’ingestion en streaming écrit des lignes de données directement dans les tables Snowflake, contrairement aux chargements de données en masse ou à Snowpipe, qui écrivent des données à partir de fichiers stagés. Cette architecture permet des latences de chargement plus faibles avec des coûts correspondants réduits pour le chargement de volumes de données similaires, ce qui en fait un outil puissant pour gérer les flux de données en temps réel.
Ingestion en streaming à fréquence moyenne.
4- Les tables dynamiques sont les blocs de construction des pipelines de transformation de données déclaratifs. Elles simplifient considérablement l’ingénierie des données dans Snowflake et offrent une façon fiable, rentable et automatisée de transformer vos données pour la consommation. Au lieu de définir les étapes de transformation des données comme une série de tâches et de devoir surveiller les dépendances et la planification, vous pouvez déterminer l’état final de la transformation à l’aide de tables dynamiques et laisser Snowflake gérer la complexité du pipeline.
Tables dynamiques.
5- Certaines charges de travail analytiques, comme la détection de fraudes ou le traitement d’événements complexes, nécessitent plus de puissance de calcul. Les limitations actuelles des tables dynamiques pourraient s’atténuer avec le temps, par exemple lorsque les UDFs deviendront disponibles pour les tables dynamiques. En attendant, les analyses complexes pourraient être gérées par un service externe avec un outil analytique dédié comme Apache Flink.
Analytique en streaming à haute fréquence.
-
**Couche batch **: Dans la couche batch, toutes les données entrantes sont sauvegardées sous forme de vues batch pour les préparer à l’indexation. Cette couche remplit deux fonctions importantes. Premièrement, elle gère le jeu de données maître de manière immuable et en ajout uniquement, préservant un enregistrement historique fiable des données entrantes provenant de toutes les sources. Deuxièmement, elle précalcule les vues batch. Cette couche aide à corriger les erreurs, à synchroniser les données avec d’autres systèmes tiers, et à effectuer des contrôles de qualité des données. Les données traitées sont stockées dans Snowflake dans les couches Core DWH et Data Mart, et remplacent les données en ligne du jour précédent.
La commande COPY est très riche en fonctionnalités, vous donnant la flexibilité de décider où dans le pipeline gérer des fonctions ou des transformations spécifiques, comme l’utilisation de l’ELT (Extract/Load/Transform) au lieu de l’ETL traditionnel.
En utilisant la commande COPY, les données peuvent être chargées depuis le stockage de données en parallèle, permettant le chargement de centaines de téraoctets (To) en quelques heures sans compromettre l’accès quasi temps réel aux données chargées. La commande COPY peut être exécutée depuis l’onglet Worksheet dans l’interface utilisateur, tout comme toute autre opération DDL ou DML, ou de manière programmatique en utilisant l’un des langages pris en charge, tels que Python, Node.js, ODBC, JDBC ou Spark.
De plus, la bibliothèque Snowpark fournit une bibliothèque intuitive pour interroger et traiter des données à grande échelle dans Snowflake. En utilisant une bibliothèque pour l’un des trois langages (Java, Python et Scala), vous pouvez créer des applications qui traitent des données dans Snowflake sans déplacer les données vers le système où votre code d’application s’exécute et qui s’exécutent à grande échelle dans le cadre du moteur Snowflake élastique et serverless.
Moteur StreamSets pour Snowpark.
-
Couche Speed : Par conception, la couche batch présente une latence élevée, livrant généralement des vues batch à la couche de service à raison d’une ou deux fois par jour. Le rôle de la couche speed est de réduire l’écart entre le moment où les données sont créées et celui où elles sont disponibles pour les requêtes. La couche speed accomplit cela en indexant toutes les données dans le job d’indexation actuel de la couche de service et toutes les données arrivées depuis le début du job d’indexation le plus récent. Une fois que la couche de service termine un job d’indexation, toutes les données incluses dans ce job ne sont plus nécessaires dans la couche speed et sont supprimées.
En tant que partie de la couche speed, les données passent par les étapes suivantes :
- Le service d’événements asynchrone du système source agit comme un filtre pour capturer le trafic du système source sous forme de messages JSON. Ensuite, il achemine les messages vers des topics Kafka.
- L’outil StreamSets Data Collector (SDC) est utilisé pour consommer les événements des topics Kafka et les traiter :
- Filtre les messages requis,
- Enrichit les données à la volée en utilisant l’API du système source (par exemple, obtient le nom d’une entité en passant son ID),
- Applique d’autres transformations requises aux données (masquage des données, filtrage, etc.),
- Convertit les données au format de fichier CSV et place le fichier dans un data lake (ex. : bucket S3),
- En parallèle, les messages originaux sont placés dans le Data Lake.
- Une table externe Snowflake (Live View dans le diagramme) nous permet d’interroger les informations directement depuis le bucket S3 du Data Lake. Ainsi, les données ne sont pas stockées dans la base de données mais ne font que transiter par un Virtual Warehouse Snowflake lorsqu’elles sont interrogées depuis la couche de service.
-
Couche de service : La couche de service des données reçoit les vues batch de la couche batch selon un calendrier prédéfini, combine les données des couches batch et speed via une vue Snowflake DB, et répond aux requêtes ad hoc des utilisateurs finaux. Cette couche reçoit également des vues quasi temps réel de la couche speed. Ici, les vues batch sont indexées pour les rendre disponibles à l’interrogation. Pendant qu’un job d’indexation s’exécute, la couche de service met en file d’attente les nouvelles données arrivantes pour inclusion dans le prochain cycle d’indexation.
La couche de service est implémentée sous forme d’un ensemble de vues Snowflake DB qui combinent les informations des data marts (préparées dans le dataflow batch) et des tables externes Snowflake (Live View dans le diagramme). En conséquence, les données réelles des applications utilisateur final sont prêtes à être consommées via des tableaux de bord personnalisés et des capacités de découverte de données en libre-service. En utilisant le mode Live Connection, les applications utilisateur final effectuent des requêtes directement contre Snowflake DB.
Bien que les architectures Lambda offrent de nombreux avantages, tels que l’évolutivité, la tolérance aux pannes et la flexibilité pour gérer un large éventail de charges de travail de traitement des données (lots et flux), elles comportent également des inconvénients que les organisations doivent prendre en compte avant de décider de les adopter ou non. L’architecture Lambda est un système complexe qui utilise plusieurs piles technologiques pour traiter et stocker les données. De plus, la logique sous-jacente est dupliquée dans les couches Batch et Speed pour chaque étape. En conséquence, elle peut être difficile à mettre en place et à maintenir, surtout pour les organisations disposant de ressources limitées. Cependant, l’utilisation de Snowflake comme pile unique pour les deux couches peut aider à réduire la complexité rencontrée dans les architectures Lambda.
Architecture de données Kappa avec Snowflake
En 2014, alors qu’il travaillait chez LinkedIn, Jay Kreps a lancé une discussion dans laquelle il soulignait certains inconvénients de l’architecture Lambda. Cette discussion a conduit la communauté big data vers une autre alternative utilisant moins de ressources de code.
L’idée principale derrière cela est qu’une seule pile technologique peut être utilisée à la fois pour le traitement de données en temps réel et par lots. Cette architecture a été appelée Kappa. L’architecture Kappa est nommée d’après la lettre grecque “Kappa” (ϰ), utilisée en mathématiques pour représenter une “boucle” ou un “cycle”. Ce nom reflète l’accent de l’architecture sur le traitement ou le retraitement continu des données plutôt qu’une approche basée sur les lots. En son cœur, elle repose sur une architecture de streaming : les données entrantes sont d’abord stockées dans un journal d’événements en streaming, puis traitées en continu par un moteur de traitement de flux, comme Kafka, soit en temps réel, soit ingérées dans une autre base de données analytique ou application métier en utilisant divers paradigmes de communication tels que le temps réel, le quasi temps réel, le batch, le micro-batch et la requête-réponse.
L’architecture Kappa est conçue pour fournir un système évolutif, tolérant aux pannes et flexible pour traiter de grandes quantités de données en temps réel. L’architecture Kappa est considérée comme une alternative plus simple à l’architecture Lambda car elle utilise une seule pile technologique pour gérer à la fois les charges de travail en temps réel et historiques, traitant tout comme des flux. La motivation principale pour inventer l’architecture Kappa était d’éviter de maintenir deux bases de code distinctes (pipelines) pour les couches batch et speed. Cela lui permet de fournir un pipeline de traitement des données plus rationalisé et simplifié tout en offrant un accès rapide et fiable aux résultats des requêtes.
Architecture Kappa avec Snowflake.
L’exigence la plus importante pour Kappa était le retraitement des données, rendant visibles les effets des changements de données sur les résultats. Par conséquent, l’architecture Kappa avec Snowflake comprend seulement deux couches : la couche stream et la couche de service. La couche de service de Kappa est assez similaire à celle de Lambda.
La couche de traitement de flux collecte, traite et stocke les données en streaming en direct. Cette approche élimine le besoin de systèmes de traitement par lots en utilisant un moteur de traitement de flux avancé tel que Snowpark, Apache Flink, ou Apache Spark Streaming pour gérer des volumes élevés de flux de données et fournir un accès rapide et fiable aux résultats des requêtes. La couche de traitement de flux est divisée en deux composants : le composant d’ingestion, qui collecte les données de diverses sources, et le composant de traitement, qui traite ces données entrantes en temps réel.
- Composant d’ingestion : Cette couche collecte les données entrantes provenant de diverses sources, telles que les journaux, les transactions de base de données, les capteurs et les APIs. Les données sont ingérées en temps réel en utilisant Apache Kafka avec l’API Snowpipe Streaming et stockées dans des stages Snowflake pour traitement.
- Composant de traitement : Le composant de traitement de l’architecture Kappa est responsable de la gestion des flux de données à volume élevé et de la fourniture d’un accès rapide et fiable aux résultats des requêtes. Il utilise des moteurs de traitement d’événements comme Snowpark pour traiter les données entrantes en temps réel. De plus, de nombreuses intégrations Snowflake existent pour d’autres moteurs de traitement d’événements comme Apache Spark Streaming (Spark-Snowflake), Apache Kafka (connecteurs Kafka Snowflake), ou le connecteur dbt pour Snowflake.
Snowpipe streaming.
De nos jours, les données en temps réel surpassent les données lentes. C’est vrai pour presque tous les cas d’usage. Néanmoins, l’architecture Kappa ne peut pas être considérée comme un substitut à l’architecture Lambda. Au contraire, elle doit être vue comme une alternative à utiliser dans les situations où la performance active de la couche batch n’est pas nécessaire pour satisfaire les niveaux de service standard.
L’un des exemples les plus connus tirant parti de l’architecture Kappa avec Snowflake est l’architecture IoT. L’Internet des objets (IoT) est un réseau d’appareils physiques, de véhicules, d’appareils électroménagers et d’autres objets (aussi appelés “choses”) intégrés avec des capteurs, des logiciels et une connectivité leur permettant de collecter et d’échanger des données. Ces appareils peuvent aller des appareils électroménagers intelligents aux machines industrielles en passant par les appareils médicaux, et ils sont tous connectés à Internet.
Architecture IoT avec Snowflake.
Les données collectées par les appareils IoT peuvent être utilisées à diverses fins, telles que la surveillance et le contrôle à distance des appareils, l’optimisation des processus, l’amélioration de l’efficacité et de la productivité, et l’activation de nouveaux services et modèles commerciaux. Les données IoT sont générées par des appareils qui collectent des données périodiquement ou en continu depuis l’environnement environnant et les transmettent vers une destination.
Bien que le concept d’appareils IoT remonte à plusieurs décennies, l’adoption généralisée des smartphones a créé un essaim massif d’appareils IoT presque du jour au lendemain. Depuis lors, diverses nouvelles catégories d’appareils IoT ont émergé, notamment les thermostats intelligents, les systèmes de divertissement automobile, les téléviseurs intelligents et les enceintes connectées. L’IoT peut révolutionner de nombreuses industries, notamment la santé, la fabrication, les transports et l’énergie. Il est passé d’un concept futuriste à un domaine majeur de l’ingénierie des données. On s’attend à ce qu’il devienne l’un des principaux moyens de génération et de consommation des données.
Architecture Data Mesh avec Snowflake
Le Data Mesh a été introduit en 2019 par Zhamak Dehghani. Dans son article de blog, elle a soutenu qu’une architecture décentralisée était nécessaire en raison des lacunes des data warehouses et des data lakes centralisés.
Un data mesh est un cadre qui permet aux domaines métier de posséder et d’exploiter leurs données spécifiques au domaine sans avoir besoin d’un intermédiaire centralisé. Il s’inspire des principes du calcul distribué, où les composants logiciels sont partagés entre plusieurs ordinateurs fonctionnant ensemble comme un système. Ainsi, la propriété des données est répartie entre différents domaines métier, chacun responsable de la création de ses propres produits. De plus, il permet une contextualisation plus aisée des informations collectées pour générer des insights plus profonds tout en facilitant la collaboration entre les propriétaires de domaines pour développer des solutions adaptées à des besoins spécifiques.
Dans un article ultérieur, Zhamak a révisé sa position en proposant quatre principes qui forment ce nouveau paradigme.
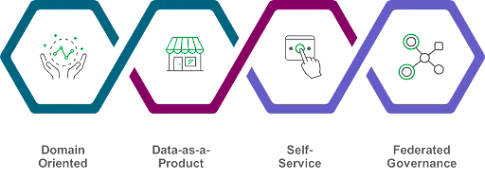 Principes du Data Mesh.
Principes du Data Mesh.
Snowflake propose plusieurs capacités clés pour implémenter des pipelines de transformation de données automatisés et pour créer et gouverner des produits de données. La plateforme Snowflake est conçue pour la facilité d’utilisation, une maintenance quasi nulle et un scaling instantané des ressources pour permettre une véritable expérience en libre-service. Chaque équipe de domaine peut déployer et faire évoluer ses ressources selon ses besoins sans impacter les autres et sans dépendre d’une équipe infrastructure.
La plateforme Snowflake permet aux équipes de domaine de fonctionner de manière indépendante tout en partageant facilement des produits de données entre elles. Chaque domaine peut désigner les objets de données à partager, puis publier des descriptions de produits dans un Snowflake Data Exchange, qui sert d’inventaire de tous les produits de données dans le data mesh. Les autres équipes peuvent parcourir cet inventaire pour découvrir les produits de données répondant à leurs exigences.
Bases de données Snowflake comme domaines.
1- Les données comme produit : Les équipes data appliquent une pensée produit à leurs jeux de données. Dans cette approche, une organisation désigne un product owner pour les données. Cela implique d’appliquer les rigueurs des principes produit aux actifs de données pour apporter une réelle valeur à ses clients finaux (ex. : data scientists et analystes).
Les producteurs de données dans Snowflake peuvent partager des données, des services de données ou des applications avec d’autres comptes en publiant des métadonnées (“listings”). Les producteurs peuvent utiliser des contrôles de découverte des listings pour partager en privé avec d’autres comptes ou groupes de comptes, ou partager publiquement via le Snowflake Marketplace. Les producteurs de données peuvent spécifier des SLAs ou SLOs pour les données qu’ils partagent, tels que la fréquence de mise à jour, la quantité d’historique, la granularité temporelle des données et d’autres propriétés qui aident à décrire les données comme un produit.
2- La propriété par domaine : La propriété des données est fédérée parmi des experts du domaine responsables de la production d’actifs pour l’analyse et l’intelligence d’affaires. Snowflake est une plateforme distribuée mais interconnectée qui évite les silos et permet aux équipes distribuées d’échanger des données de manière gouvernée et sécurisée. Différentes équipes de domaine peuvent travailler de manière autonome en utilisant une puissance de calcul indépendante dans des bases de données ou des comptes séparés tout en utilisant la plateforme Snowflake sous-jacente pour partager des actifs de données entre elles.
Comptes Snowflake comme domaines.
3- Plateformes de données en libre-service : Une plateforme centrale gère les besoins d’infrastructure sous-jacents du traitement des données tout en fournissant les outils nécessaires à l’autonomie spécifique au domaine.
Parmi les raisons les plus courantes de choisir Snowflake, on trouve la facilité d’utilisation et la maintenance quasi nulle. Ce sont des propriétés essentielles pour une plateforme en libre-service. Par exemple, les utilisateurs peuvent facilement instancier et faire évoluer leurs clusters de calcul sans l’aide de l’équipe d’infrastructure IT. Le clonage des environnements de développement et de test est tout aussi simple. Un mécanisme de capture des modifications de données (change data capture) peut être configuré avec une instruction SQL DDL d’une seule ligne. Cet accent sur la facilité d’utilisation a été un principe directeur pour toutes les fonctionnalités de la plateforme Snowflake.
4- Gouvernance computationnelle fédérée : Un ensemble universel de normes définies centralement garantit le respect de la qualité des données, de la sécurité et de la conformité aux politiques à travers les domaines et les propriétaires de données.
La gouvernance fédérée est sans doute l’une des parties les plus difficiles d’un parcours data mesh et nécessite souvent un ou plusieurs outils combinés pour satisfaire toutes les exigences. Snowflake prend en charge le contrôle d’accès basé sur les rôles, les politiques d’accès au niveau des lignes, le masquage des données au niveau des colonnes, la tokenisation externe, la traçabilité des données, les capacités d’audit, et bien plus encore au niveau de la plateforme. Les utilisateurs peuvent également attribuer une ou plusieurs balises de métadonnées (paires clé-valeur) à presque tout type d’objet dans Snowflake, tels que les comptes, les bases de données, les schemas, les tables, les colonnes, les clusters de calcul, les utilisateurs, les rôles, les tâches, les partages et d’autres objets.
Les balises sont héritées à travers la hiérarchie des objets et peuvent être exploitées pour découvrir, suivre, restreindre, surveiller et auditer des objets en fonction de sémantiques définies par l’utilisateur. De plus, les politiques d’accès basées sur les balises permettent aux utilisateurs d’associer une restriction d’accès à une balise, de sorte que la politique d’accès est automatiquement appliquée à tout objet de données correspondant portant la balise concernée.
Implémentation du Data Mesh avec Snowflake.
Architectures de données avec Snowflake : sont-elles de « bonnes » architectures ?
Comme évoqué précédemment, le framework AWS Well-Architected est conçu pour aider les architectes cloud à créer des architectures sécurisées, fiables, performantes, rentables et durables. Ce système comprend six piliers clés : l’excellence opérationnelle, la sécurité, la fiabilité, l’efficacité des performances, l’optimisation des coûts et la durabilité, offrant aux clients une manière cohérente d’évaluer et d’implémenter des architectures évolutives. Je me suis inspiré des principes d’une “bonne” architecture de données du framework AWS Well-Architected pour évaluer si Snowflake peut construire de “bonnes” architectures de données ou non.
1. L’efficacité des performances représente la capacité d’un système à s’adapter aux variations de charge. Le principal défi que l’on observe avec de nombreuses architectures de données est la complexité opérationnelle lors du déploiement et de la gestion de leurs outils et solutions techniques. Il est souvent difficile d’anticiper et de gérer les pics de demande de ces plateformes, ce qui entraîne un gaspillage d’argent sur des ressources sous-utilisées déjà sur-provisionnées en raison de mauvais processus de mise à l’échelle. Dans cette étude, l’auteur a réalisé des benchmarks synthétiques (TPC-DS) pour mesurer les impacts des changements d’application générale sur les performances. En d’autres termes, à quelle vitesse Snowflake s’est-il amélioré au fil du temps en utilisant des blocs de construction stables (data warehouses stables et requêtes récurrentes stables) ?
La durée des requêtes pour les charges de travail récurrentes des clients s’améliore de 15 %.
2. La fiabilité est la condition préalable à la confiance.1 Ce mantra est valable dans l’architecture de données, surtout lorsque les utilisateurs finaux recherchent une prise de décision en temps réel. La fiabilité représente la capacité d’un système à se remettre de pannes et à continuer à fonctionner comme prévu. Le principal défi concernant la fiabilité d’une plateforme de données est de respecter les SLAs requis. Les temps d’arrêt ou les temps de réponse lents peuvent entraîner une perte de revenus, une réputation ternie et un désabonnement des clients. Snowflake fournit des fonctionnalités puissantes pour assurer la maintenance et la disponibilité de vos données historiques (c’est-à-dire les données qui ont été modifiées ou supprimées) : - Interrogation, clonage et restauration des données historiques dans les tables, schemas et bases de données jusqu’à 90 jours via le Time Travel Snowflake. - Récupération après sinistre des données historiques (par Snowflake) via Snowflake Fail-safe.
Ces fonctionnalités sont incluses pour tous les comptes, c’est-à-dire qu’aucune licence supplémentaire n’est requise ; cependant, le Time Travel standard est d’un jour. Le Time Travel étendu (jusqu’à 90 jours) requiert l’édition Enterprise de Snowflake. De plus, le Time Travel et le Fail-safe nécessitent un stockage de données supplémentaire, qui engendre des frais associés.
Snowflake fournit également plusieurs mécanismes pour créer des groupes de réplication afin de répliquer les données vers un ou plusieurs comptes cibles et des groupes de basculement qui fournissent un accès en lecture seule aux objets répliqués en cas de panne.
3. L’optimisation des coûts représente la gestion des coûts pour maximiser la valeur produite. L’architecture Snowflake sépare le stockage du calcul, permettant à diverses charges de travail de s’exécuter à l’intérieur du même warehouse sans aucune conscience les unes des autres et donc isolées pour éviter qu’elles ne s’affectent mutuellement. Le principal avantage de cette multi-location est la capacité de partager les capacités d’infrastructure entre plusieurs bases de données, réduisant ainsi le Coût Total de Possession (TCO) de votre plateforme de données (réduction des coûts de 30 % à 70 %).
Un autre levier qui optimise le coût de votre plateforme de données est la réduction des coûts d’administration et de maintenance (Snowflake est une plateforme entièrement managée). En utilisant les fonctionnalités de performance intégrées, chaque charge de travail dans Snowflake est aussi rapide, stable et efficace que possible. Enfin, Snowflake améliore continuellement le rapport qualité-prix pour les clients grâce à des fonctionnalités natives d’optimisation des coûts et des charges de travail, des améliorations de performance et des ressources d’apprentissage pour la gestion des coûts. Snowflake a réduit le coût moyen des requêtes warehouse de plus de 20 % au cours des trois dernières années.
4. La sécurité représente la protection de la plateforme de données contre les menaces. Bien que la sécurité soit souvent perçue comme un frein au travail des ingénieurs données, ils doivent reconnaître que la sécurité est en réalité un facilitateur vital. En mettant en œuvre des mesures de sécurité robustes (chiffrement, listes blanches réseau, peering réseau, authentification multi-facteurs, Single-Sign-On, OAuth, SCIM, TLS mutuel, CA de confiance…) pour les données au repos et en transit, et un contrôle d’accès aux données à grain fin, une architecture de données utilisant Snowflake peut permettre un partage et une consommation plus larges des données au sein d’une entreprise, conduisant à une augmentation significative de la valeur des données. De plus, le principe du moindre privilège est implémenté via le Contrôle d’Accès Discrétionnaire (DAC) et le Contrôle d’Accès Basé sur les Rôles (RBAC), ce qui signifie que l’accès aux données n’est accordé de manière proportionnelle qu’à ceux qui en ont besoin.
5. L’excellence opérationnelle est la capacité à maintenir un système en production de manière optimale. Premièrement, Snowflake fournit de nombreuses intégrations pour permettre la surveillance opérationnelle de votre plateforme de données, de l’infrastructure sous-jacente et des accès aux données (piste d’audit). Ainsi, vous pouvez obtenir de la visibilité et prendre les mesures appropriées.
6. La durabilité vise à minimiser l’empreinte environnementale de votre plateforme de données. Snowflake prend en charge plusieurs options de déploiement qui vous permettent de choisir la région, les technologies de stockage et les configurations qui soutiennent le mieux la valeur métier de vos données (multi-cloud, cloud hybride). De plus, des fonctionnalités comme la multi-location et le tiering des données peuvent réduire l’infrastructure provisionnée nécessaire pour soutenir votre plateforme de données et les ressources nécessaires pour l’utiliser. Par conséquent, l’utilisation de Snowflake contribue à réduire l’empreinte environnementale de votre plateforme de données.
Résumé
Dans cet article, je présente Snowflake comme une plateforme de données en libre-service qui implémente les architectures de données les plus populaires grâce à la multitude d’outils et de fonctionnalités qu’il propose.
Les types de données se multiplient, les patterns d’utilisation ont considérablement évolué, et un accent renouvelé est mis sur la construction de pipelines avec les architectures Lambda et Kappa sous forme de hubs ou de fabrics de données. Qu’elles soient regroupées par vélocité ou par le type de topologie qu’elles fournissent, les architectures de données ne sont pas orthogonales. Les architectures et paradigmes de données présentés dans cet article peuvent être utilisés côte à côte, alternativement lorsqu’il est nécessaire de passer de l’un à l’autre. De plus, bien sûr, ils peuvent être mélangés dans des architectures comme le data mesh, dans lequel chaque produit de données est un artefact autonome. On peut imaginer qu’une architecture Lambda soit implémentée dans certains produits de données et des architectures Kappa dans d’autres.
Dans l’ensemble, cet article fournit une vue d’ensemble complète de la façon dont Snowflake peut être utilisé comme une plateforme de données moderne et les différentes architectures de données qui peuvent être implémentées. Ensuite, j’ai évalué ces architectures au regard du framework AWS Well-Architected, pour évaluer si ce sont de “bonnes” architectures de données. Le résultat de cette évaluation fournit des insights précieux pour construire des plateformes de données bien architecturées.
Références
- “Three-speed architecture on Snowflake”, Reinout Korbee, Medium 2023.
- “Fundamentals of data engineering: Plan and build robust data systems”, Reis, J. and Housley M., O’Reilly Media (2022).
- “Lambda vs. Kappa Architecture. A Guide to Choosing the Right Data Processing Architecture for Your Needs”, Dorota Owczarek.
- “A brief introduction to two data processing architectures: Lambda and Kappa for Big Data”, Iman Samizadeh, Ph.D.
- “What Is Lambda Architecture?”, Hazelcast Glosary.
- “What Is the Kappa Architecture?”, Hazelcast Glosary.
- “Kappa Architecture is Mainstream Replacing Lambda”, Kai Waehner.
- “Data processing architectures – Lambda and Kappa”, Julien Forgeat.
- “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh”, Zhamak Dehghani (Martin Fowler Blog).
- “Data Mesh Principles and Logical Architecture”, Zhamak Dehghani (Martin Fowler Blog).
- “Benchmarking Real World Customer-Experienced Performance Using the Snowflake Performance Index (SPI)”, Louis Magarshack, Medium 2023.
1. Wolfgang Schäuble - un juriste, homme politique et homme d’État allemand dont la carrière politique s’étend sur plus de cinq décennies.