
Les Grands Modèles de Langage (LLMs) transforment la façon dont nous construisons des applications intelligentes, mais ils portent une limitation fondamentale : leur connaissance est figée au moment de l’entraînement. Interrogez un modèle sur votre documentation interne, votre catalogue de produits ou le rapport d’incident de la semaine dernière et il refusera soit de répondre, soit halluciner une réponse plausible.
La Génération Augmentée par Récupération (RAG) résout ce problème en ancrant chaque réponse LLM dans vos propres données actualisées et spécifiques à votre domaine. Plutôt que de s’appuyer uniquement sur des connaissances pré-entraînées, un système RAG récupère les documents les plus pertinents depuis une base de connaissances privée, les injecte comme contexte dans le prompt, et seulement alors demande au LLM de générer une réponse précise, fiable et ancrée dans des données vérifiées.
Mais RAG n’est pas une technique unique. Au cours des deux dernières années, le domaine a rapidement évolué des simples recherches vectorielles aux pipelines sophistiqués pilotés par des agents. Cet article couvre :
- L’état de l’art : RAG naïf, Graph RAG et RAG agentique : comment ils fonctionnent, quand les utiliser et où ils échouent.
- Pourquoi CockroachDB est une fondation idéale pour n’importe lequel de ces paradigmes.
- Un tutoriel complet et fonctionnel implémentant un pipeline RAG sur CockroachDB en utilisant Google Cloud (Vertex AI) et AWS (Bedrock).
L’état de l’art du RAG
RAG a évolué à travers trois générations distinctes, chacune répondant aux limitations de la précédente. Le RAG naïf a établi le modèle fondamental de récupération-puis-génération, simple, rapide et efficace pour des recherches simples, mais fragile lorsque les requêtes nécessitent de connecter des faits à travers plusieurs documents. Le Graph RAG a remplacé les segments vectoriels plats par un graphe de connaissances structuré, permettant une compréhension globale à travers de grands corpus au prix d’une latence plus élevée et de coûts d’indexation plus importants. Le RAG agentique est allé encore plus loin, intégrant des agents autonomes qui planifient, récupèrent de manière itérative, invoquent des outils externes et se corrigent, échangeant la prévisibilité contre la capacité à traiter des tâches de raisonnement multi-étapes véritablement ouvertes.
Choisir entre eux n’est pas une question de « plus récent est meilleur » : c’est une question d’adapter le paradigme à la complexité de la requête, au budget de latence et à l’enveloppe de coût de votre cas d’utilisation spécifique. Les sections ci-dessous décomposent chaque approche pour que vous puissiez faire ce choix en toute confiance.
RAG naïf
Le RAG naïf est le paradigme fondateur de récupération-puis-génération. Il se déroule en deux phases distinctes , un pipeline d’ingestion hors ligne (étapes 1–3) et un pipeline de récupération et de génération en ligne (étapes 4–7), connectées via un vector store partagé.
- Découpage : les documents bruts (PDF, CSV, HTML) sont divisés en segments de texte chevauchants de taille fixe par un découpeur.
- Encodage : chaque segment est converti en un vecteur de haute dimension par un modèle d’embedding qui capture son sens sémantique.
- Indexation : les vecteurs résultants sont stockés et indexés dans le Vector Store CockroachDB, prêts pour la recherche de similarité.
- Encodage de la requête : la question de l’utilisateur est passée à travers le même modèle d’embedding pour produire un vecteur de requête.
- Recherche de similarité : CockroachDB compare le vecteur de requête à tous les vecteurs de segments indexés en utilisant la distance cosinus et retourne les k correspondances les plus proches.
- Assemblage du contexte : les segments récupérés sont combinés avec la requête originale en un seul bloc de contexte.
- Génération : le LLM reçoit contexte + requête comme prompt et produit une réponse ancrée.
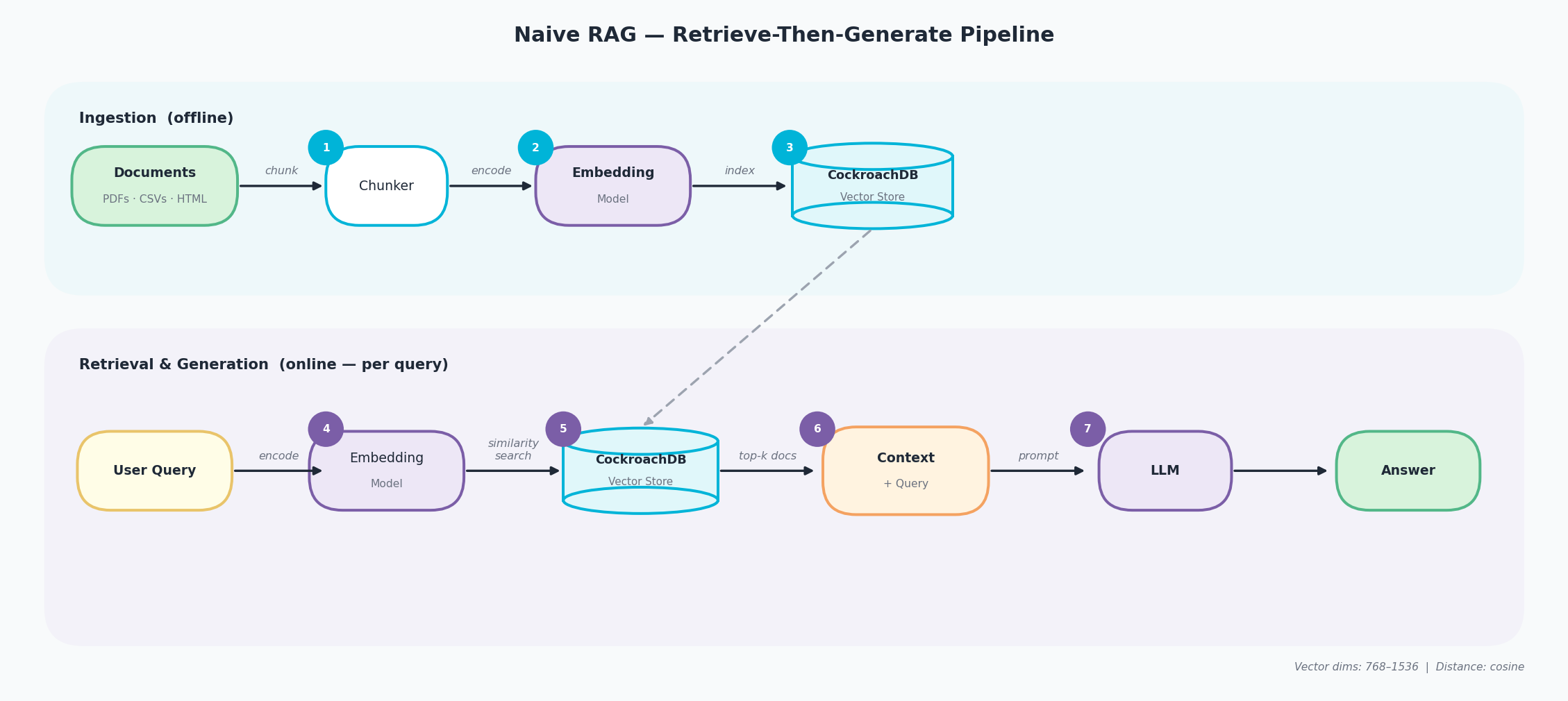
Pipeline RAG naïf : Ingestion (documents, découpeur, modèle d’embedding, vector store CockroachDB) et Récupération & Génération (requête utilisateur, embedding, recherche de similarité, contexte + LLM)
-
Points forts : complexité minimale, déploiement rapide, faible latence (< 2 s), faible coût. Prouvé efficace pour les recherches factuelles simples. La précision de GPT-4 sur les QCM médicaux a été améliorée de 73 % à 80 % avec un RAG de base seul.
-
Faiblesses : difficultés avec le raisonnement multi-sauts, incapacité à synthétiser à travers de nombreux documents, susceptible aux hallucinations dues à des segments de contexte bruités ou contradictoires, pas de prise en compte des relations entre entités.
-
Utilisez-le quand : vous construisez un prototype, les requêtes sont simples (recherches à concept unique), le coût et la latence sont les contraintes principales, ou le corpus de documents est petit et bien structuré.
-
Évitez-le quand : les requêtes nécessitent de connecter des informations de plusieurs sources, un raisonnement multi-étapes est nécessaire, ou le niveau d’exigence en précision est élevé pour des questions complexes et ouvertes.
Graph RAG
Le Graph RAG, pionnier par Microsoft Research dans leur article d’avril 2024 « From Local to Global: A Graph RAG Approach to Query-Focused Summarization », remplace les segments vectoriels plats par un graphe de connaissances structuré et des résumés de communautés hiérarchiques. Le pipeline se déroule en deux phases : indexation hors ligne (étapes 1–5) et récupération & génération en ligne (étapes 6–10).
- Découpage : les documents sources sont divisés en segments de texte, tout comme dans le RAG naïf.
- Extraction d’entités : un LLM lit chaque segment et identifie les entités nommées (personnes, lieux, concepts) et les relations entre elles.
- Graphe de connaissances : les entités et relations extraites sont assemblées dans un graphe stocké dans une base de données dédiée Graph DB.
- Clustering de communautés : un algorithme de détection de communautés regroupe les entités étroitement liées en clusters.
- Résumés de communautés : le LLM pré-génère un résumé en langage naturel pour chaque cluster ; les résumés sont stockés à la fois dans la Graph DB et une Vector DB pour une recherche rapide.
- Encodage de la requête : la requête utilisateur est convertie en un vecteur.
- Recherche vectorielle : la Vector DB est interrogée pour trouver les résumés de communautés sémantiquement les plus pertinents.
- Traversée du graphe : pour chaque communauté correspondante, la Graph DB est traversée pour récupérer les relations d’entités soutenant et les preuves détaillées.
- Synthèse LLM : tous les résumés récupérés et le contexte du graphe sont passés au LLM pour composer une réponse complète.
- Réponse : la réponse finale est ancrée à la fois dans des preuves au niveau de la communauté et des entités de l’ensemble du corpus.
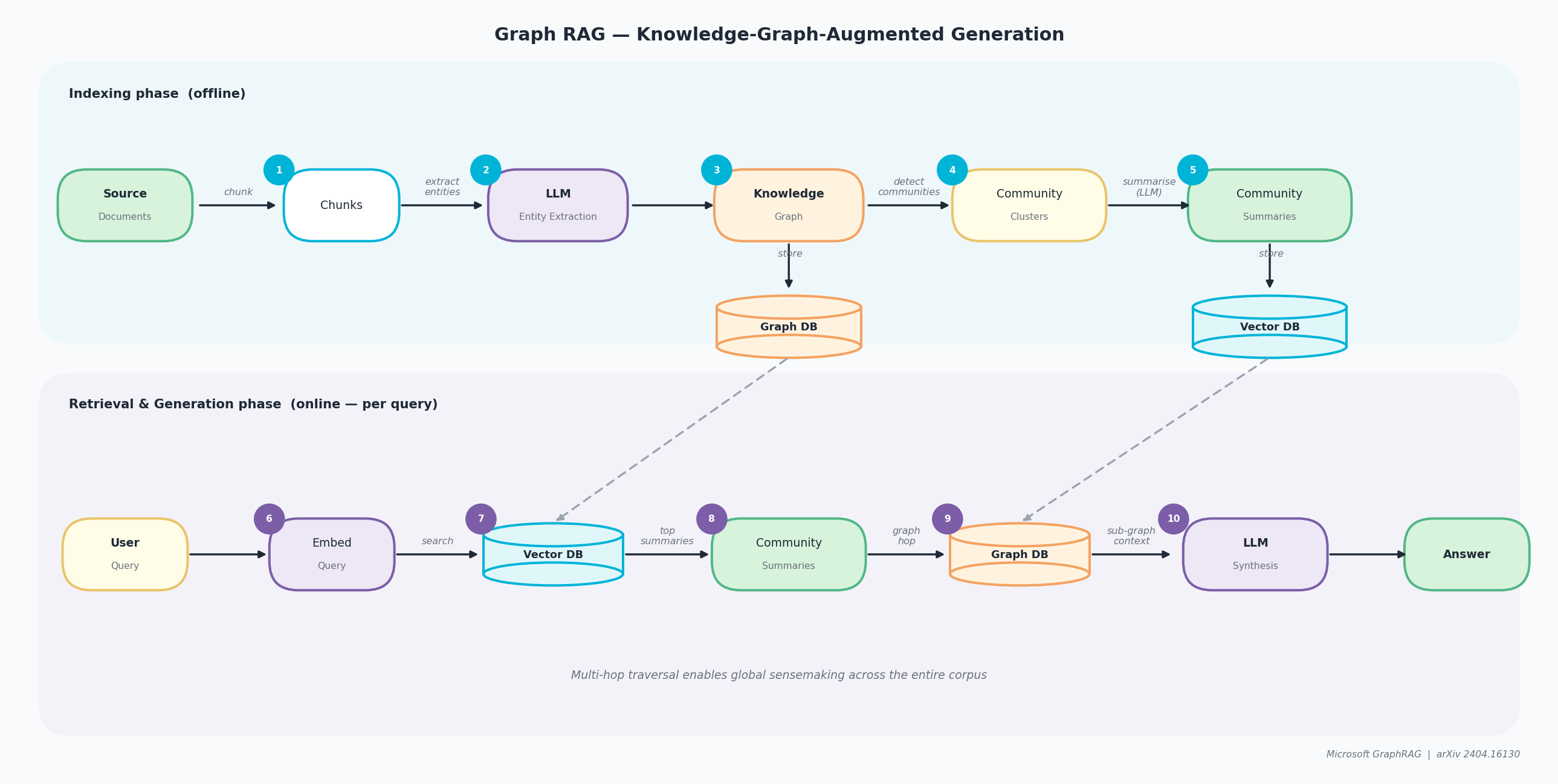
Pipeline Graph RAG : Phase d’indexation (docs sources, extraction d’entités LLM, graphe de connaissances, clusters et résumés de communautés) et phase de Récupération & Génération (Vector DB, résumés de communautés, traversée Graph DB, synthèse LLM)
-
Points forts : excelle dans la compréhension globale et la synthèse à travers de grands corpus (1M+ tokens). Les tests de Microsoft ont montré 72–83 % de complétude par rapport au RAG de base. Le raisonnement multi-sauts et le traçage des relations sont des capacités de premier ordre.
-
Faiblesses : haute latence (20–24 s en moyenne), coût d’indexation élevé (20–500 $ par corpus), coûteux en calcul pour reconstruire quand les données sources changent fréquemment.
-
Utilisez-le quand : la complétude compte plus que la vitesse, le corpus a des relations riches et interconnectées (juridique, médical, littérature de recherche), ou la découverte de connaissances d’entreprise à travers de nombreux documents est l’objectif.
-
Évitez-le quand : des réponses en temps réel sont nécessaires, le budget est serré, le corpus est petit, ou les données sources changent fréquemment.
RAG agentique
Le RAG agentique intègre des agents IA autonomes dans le pipeline. Le LLM agit comme un orchestrateur intelligent qui planifie, raisonne de manière itérative, invoque des outils et adapte sa stratégie de récupération en temps réel en fonction des résultats intermédiaires. Le pipeline s’exécute sur trois voies : Planification (étapes 1–3), Récupération multi-sources (étapes 4–5) et Raisonnement itératif & auto-correction (étapes 6–9).
- La Requête de l’utilisateur arrive au Planificateur d’agent, qui analyse l’intention et la portée.
- Le planificateur décompose la requête en Sous-questions, chacune adressable par une source de récupération ou un outil spécifique.
- Le Sélecteur d’outils achemine chaque sous-question vers le backend approprié.
- La récupération s’exécute en parallèle sur quatre sources : Vector DB (CockroachDB pour la recherche sémantique), Recherche Web (temps réel), APIs & Outils (données structurées) et Exécuteur de code (calculs programmatiques).
- Tous les résultats sont agrégés dans un package de Contexte récupéré passé à la voie de raisonnement.
- Le Raisonneur LLM traite le contexte et produit une Réponse préliminaire.
- Une porte de décision demande : « Besoin de plus d’informations ? » : si OUI, l’agent retourne à l’étape 3 avec une sous-question affinée et relance la récupération.
- Si NON, l’Agent évaluateur évalue la qualité : « Pertinent & complet ? » : si NON, la réponse est affinée et réévaluée.
- Si OUI, la Réponse finale est retournée à l’utilisateur.
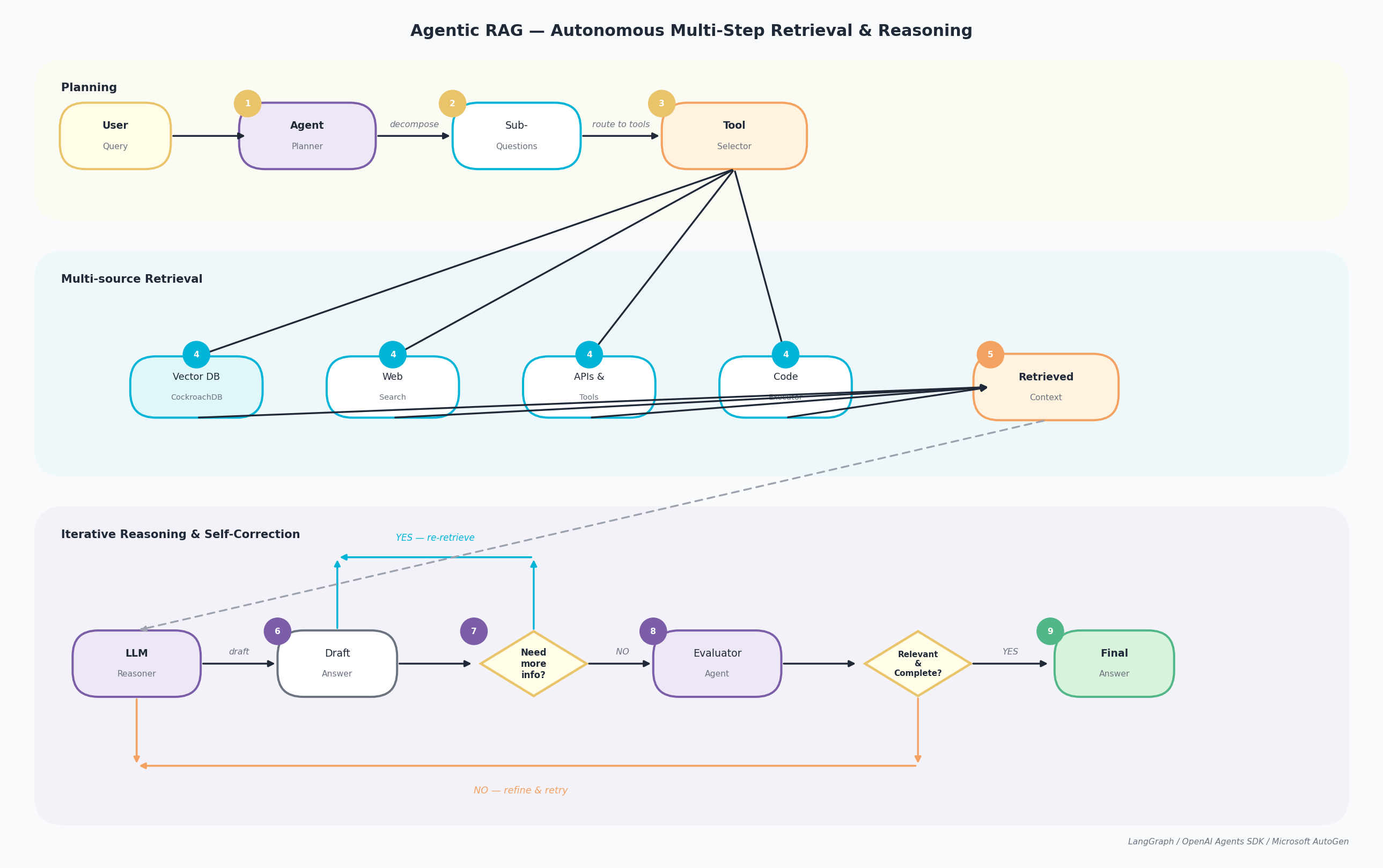
Pipeline RAG agentique : Planification (planificateur d’agent, sous-questions, sélecteur d’outils), Récupération multi-sources (Vector DB, recherche web, APIs, exécuteur de code) et Raisonnement itératif (raisonneur LLM, réponse préliminaire, boucle d’auto-correction, évaluateur, réponse finale)
-
Points forts : gère le raisonnement multi-étapes complexe, intègre des données en temps réel via la recherche web et les APIs, auto-correctif, idéal pour les tâches exploratoires et de découverte. Précision de 75–90 %+ sur les requêtes complexes.
-
Faiblesses : haute latence (10–30+ s), coût élevé (plusieurs appels LLM par requête), difficile à déboguer, comportement non déterministe, surdimensionné pour des tâches simples.
-
Utilisez-le quand : le raisonnement multi-étapes est essentiel, l’accès aux données en temps réel est requis, la tâche est exploratoire, ou la validation humaine dans la boucle est acceptable.
-
Évitez-le quand : le temps de réponse doit être < 2 s, le volume de requêtes est élevé avec un budget serré, le comportement doit être déterministe, ou les requêtes sont de simples recherches.
Comparaison : Choisir le bon paradigme RAG
| RAG naïf | Graph RAG | RAG agentique | |
|---|---|---|---|
| Complexité | Faible | Élevée | Très élevée |
| Latence | < 2 s | 20–24 s | 10–30 s |
| Coût par requête | Faible | Élevé | Très élevé |
| Profondeur de raisonnement | Mono-saut | Multi-sauts (structuré) | Multi-sauts + ramification |
| Précision sur Q complexe | 60–80 % | 72–83 % | 75–90 %+ |
| Données temps réel | Non | Non | Oui |
| Idéal pour | Prototypes, recherche simple | Synthèse d’entreprise | Tâches de recherche complexes |
| Inadapté pour | Requêtes multi-documents complexes | Applications sensibles à la vitesse | Volume élevé, faible latence |
| Mode de défaillance | Contexte manquant | Lent, coûteux | Erreurs de raisonnement en cascade |
Pourquoi construire RAG sur CockroachDB ?
Stockage unifié
CockroachDB stocke les documents sources, les métadonnées, les vector embeddings, les caches LLM et l’historique des conversations dans une seule base de données. Il n’y a pas de délai de synchronisation entre un vector store séparé et vos données opérationnelles.
Scalabilité et résilience
L’architecture SQL distribuée de CockroachDB fournit une auto-guérison automatique des pannes de nœuds, une scalabilité horizontale et une disponibilité continue, conçue pour les charges de travail critiques pour l’entreprise à grande échelle.
Vector Store natif : pas d’infrastructure supplémentaire
CockroachDB embarque un type VECTOR natif soutenu par l’index distribué C-SPANN, conçu pour les systèmes distribués, pas simplement un wrapper pgvector. Capacités clés importantes pour les charges de travail RAG :
- Index C-SPANN : un arbre K-means hiérarchique stocké dans la couche clé-valeur de CockroachDB ; pas de goulot d’étranglement sur un nœud unique, pas de coût de démarrage, auto-division à mesure que les données croissent (voir Indexation en temps réel pour des milliards de vecteurs).
- Filtrage avancé des métadonnées : filtrez par n’importe quelle colonne aux côtés de la similarité vectorielle dans une seule requête SQL.
- Multi-tenant avec colonnes de préfixe : chaque utilisateur ou tenant obtient sa propre partition d’index ; les performances sont proportionnelles aux données de ce tenant, pas au corpus total.
Intégration dédiée LangChain
Le package langchain-cockroachdb fournit une intégration asynchrone de première classe avec AsyncCockroachDBVectorStore, supportant l’ingestion de documents, la recherche de similarité et le filtrage de métadonnées, entièrement compatible avec n’importe quelle chaîne ou agent LangChain. Installez-le avec :
pip install langchain-cockroachdb
Dès qu’une application a besoin de récupérer des données, maintenir un contexte conversationnel ou raisonner sur plusieurs étapes, la quantité de code de liaison personnalisé croît rapidement. LangChain fournit une façon structurée d’orchestrer ces workflows, et langchain-cockroachdb fait de CockroachDB une source vectorielle plug-and-play pour n’importe quel pipeline LangChain.
Sécurité et gouvernance des données
RBAC, Row-Level Security et placement natif des données géographiques appliquent des permissions granulaires sur votre base de connaissances sans modifier le code de l’application.
Les outils
LangChain
LangChain est un framework open-source pour construire des applications alimentées par des grands modèles de langage. Plutôt que d’écrire des appels API bruts et d’assembler des pipelines personnalisés, LangChain vous donne un ensemble d’abstractions composables (chargeurs de documents, découpeurs de texte, modèles d’embedding, vector stores, récupérateurs, chaînes et agents) qui couvrent tout le cycle de vie d’une application LLM.
Sa force clé pour RAG est le pipeline de récupération :
- Les Chargeurs de documents ingèrent du contenu depuis des PDFs, CSV, bases de données, Notion, Google Drive, Slack et des dizaines d’autres sources dans un objet
Documentstandardisé. - Les Découpeurs de texte divisent les grands documents en segments plus petits et indépendamment récupérables, une étape cruciale car les modèles d’embedding ont des limites de longueur de contexte et les segments plus petits donnent des correspondances de similarité plus précises.
- Les Modèles d’embedding convertissent chaque segment en un vecteur de haute dimension. LangChain supporte plus de 30 fournisseurs d’embedding incluant Google Vertex AI, Amazon Bedrock, OpenAI, Cohere et Ollama, tous derrière la même interface, donc changer de fournisseur nécessite de modifier une seule ligne.
- Les Vector Stores stockent et indexent ces embeddings pour une recherche sémantique rapide. LangChain s’intègre avec plus de 40 backends, incluant le
AsyncCockroachDBVectorStorenatif fourni par le packagelangchain-cockroachdb. - Les Récupérateurs se posent au-dessus des vector stores et exposent une interface unique
.invoke(query), que la recherche sous-jacente soit basée sur la similarité, MMR ou hybride avec des seuils de score. - Les Chaînes et agents connectent les récupérateurs, les prompts et les LLMs en workflows de bout en bout. Les chaînes suivent un chemin d’exécution fixe ; les agents laissent le LLM décider dynamiquement quels outils appeler et dans quel ordre, la colonne vertébrale du RAG agentique.
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_cockroachdb import AsyncCockroachDBVectorStore
# Load → Split → Embed → Store
docs = PyPDFLoader("report.pdf").load()
chunks = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200).split_documents(docs)
store = AsyncCockroachDBVectorStore(engine=engine, embeddings=VertexAIEmbeddings(model="gemini-embedding-001"), collection_name="kb")
await store.aadd_documents(chunks)
# Retrieve
results = await store.asimilarity_search_with_score("What is the Q3 revenue?", k=3)
Cette composabilité est la raison pour laquelle LangChain est le standard de facto pour RAG : vous pouvez échanger n’importe quel composant, fournisseur d’embedding, backend vectoriel ou LLM, sans réécrire le pipeline.
Memori
Memori est une couche mémoire SQL-native et agnostique aux LLM pour les agents IA en production. Là où LangChain gère le pipeline de récupération et de génération, Memori gère ce que l’agent se rappelle entre les sessions, transformant les conversations brutes en connaissances structurées et interrogeables qui persistent dans votre propre base de données.
À chaque appel LLM, Memori capture automatiquement l’échange et le classe en quatre types de mémoire :
| Type de mémoire | Ce qu’il stocke | Exemple |
|---|---|---|
| Faits | Déclarations vérifiées sur le monde ou l’utilisateur | « Le plan de compte de l’utilisateur est Enterprise » |
| Préférences | Préférences exprimées ou déduites | « Préfère des réponses concises » |
| Règles | Contraintes et instructions | « Ne jamais recommander les produits concurrents » |
| Résumés | Historique de conversation compressé | « Discussion sur les étapes d’intégration lors de la session #4 » |
Lors des appels suivants, Memori injecte uniquement les mémoires pertinentes comme contexte, pas tout l’historique, en utilisant son propre moteur de rappel sans token. C’est le mécanisme derrière sa réduction revendiquée de 98 % des dépenses LLM : au lieu de rejouer des journaux de conversation entiers dans la fenêtre de contexte à chaque tour, seuls les extraits sémantiquement pertinents sont récupérés en millisecondes depuis CockroachDB.
L’intégration est un seul appel SDK :
from memori import Memori
with sql_engine.raw_connection() as conn:
mem = Memori(conn=conn).llm.register(vertexai)
mem.attribution(entity_id="user-123", process_id="my-app")
mem.config.storage.build()
Après mem.llm.register(client), Memori intercepte tous les appels LLM automatiquement, sans décorateur, sans recherche manuelle dans le cache, sans code d’injection de conversation. Il fournit également un Graphe de mémoire interactif qui visualise comment les faits, les préférences et les relations évoluent entre les sessions, plus un Tableau de bord d’analyse qui suit les taux de création de mémoire, les taux de correspondance du cache et l’utilisation du rappel.
Pour les déploiements d’entreprise, Memori est conforme PCI et SOC 2, supporte RBAC avec SSO/OAuth, une rétention de données configurable et une purge automatique, et des pistes d’audit complètes, avec toutes les données restant dans votre propre base de données par défaut.
Tutoriel : Construire le pipeline RAG
Le tutoriel est structuré en deux parties. La Partie 1 utilise Vertex AI de Google Cloud (Embeddings Gemini + génération Gemini 2.5 Flash). La Partie 2 utilise Bedrock d’Amazon Web Services (Titan Embed Text v2 + Claude Sonnet 4.6). La couche CockroachDB et le pipeline LangChain sont identiques entre les deux ; seuls les clients d’embedding et de LLM changent.
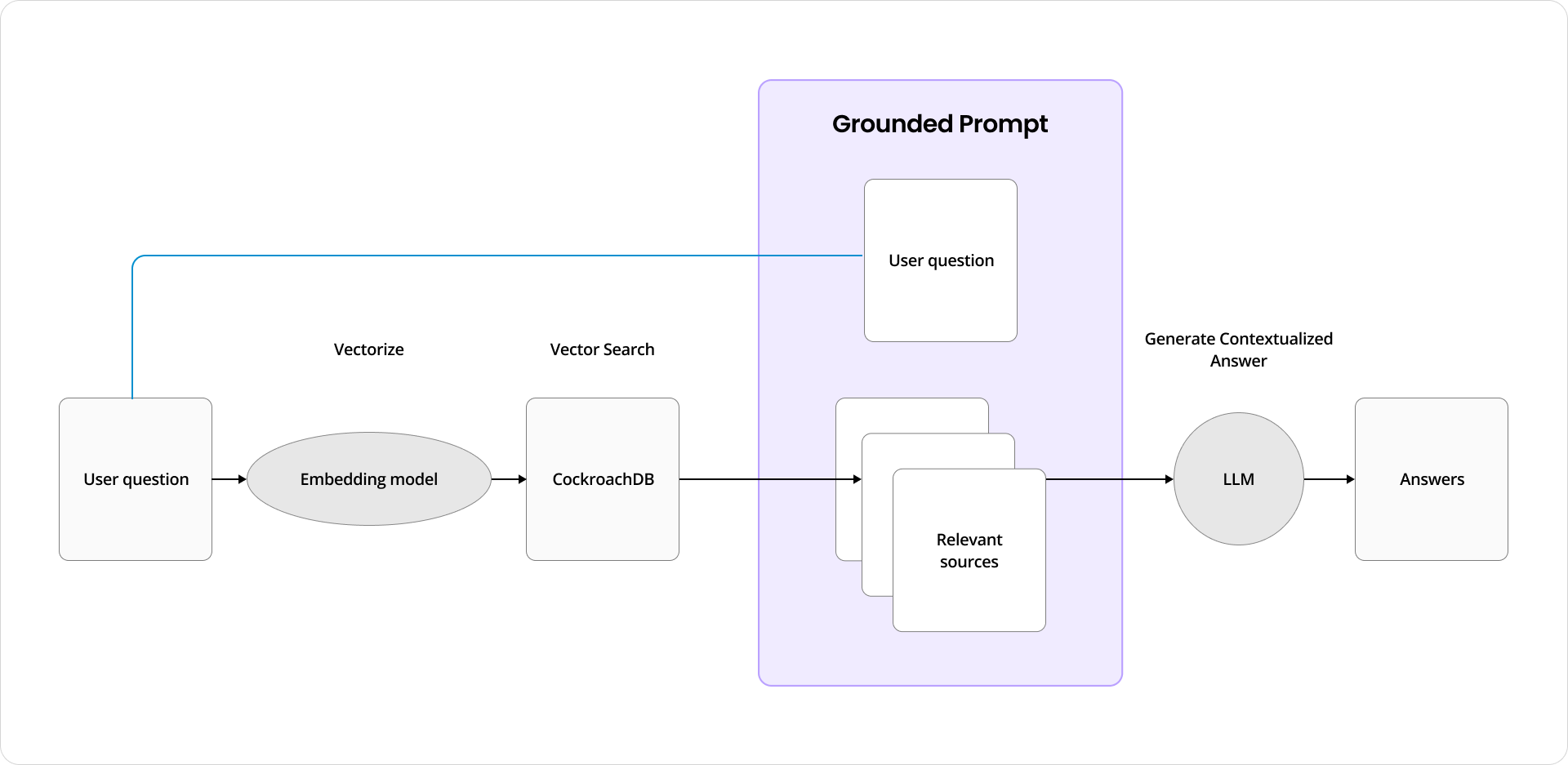
Flux de données RAG avec CockroachDB : question de l’utilisateur, vectorisation, recherche de similarité, injection de contexte, réponse LLM
Le flux de données : l’utilisateur soumet une question → elle est vectorisée → CockroachDB effectue une recherche de similarité → les documents top-k pertinents sont récupérés → le contexte est injecté dans le prompt → le LLM génère une réponse ancrée.
Partie 1 : CockroachDB + GCP Vertex AI + Memori
Installer les dépendances
pip install langchain langchain-community langchain-cockroachdb langchain-google-vertexai \
pypdf tenacity psycopg2-binary sqlalchemy memori "google-cloud-aiplatform>=1.60.0" --upgrade
Imports
from glob import glob
from memori import Memori
from langchain.document_loaders import PyPDFLoader, DataFrameLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_cockroachdb import AsyncCockroachDBVectorStore, CockroachDBEngine
from langchain_google_vertexai import VertexAIEmbeddings
from vertexai.generative_models import GenerativeModel
from sqlalchemy import create_engine, text
import vertexai, hashlib, pandas as pd
Configurer GCP Vertex AI, Memori et CockroachDB
from getpass import getpass
PROJECT_ID = getpass("GCP Project ID: ")
REGION = input("GCP Region (e.g. us-central1): ")
vertexai.init(project=PROJECT_ID, location=REGION)
# Connection string from the CockroachDB Cloud Console
# Format: cockroachdb://user:pass@host:26257/db?sslmode=verify-full
COCKROACHDB_URL = getpass("CockroachDB connection string: ")
engine = CockroachDBEngine.from_connection_string(COCKROACHDB_URL)
sql_engine = create_engine(COCKROACHDB_URL.replace("cockroachdb://", "postgresql://"))
with sql_engine.raw_connection() as conn:
cursor = conn.cursor()
mem = Memori(conn=conn).llm.register(vertexai)
mem.config.storage.build()
Charger et découper les documents
pages = []
loaders = [PyPDFLoader(f) for f in glob("docs/pdf/*.pdf")]
for loader in loaders:
pages.extend(loader.load())
df = pd.read_csv("docs/csv/blogs.csv")
pages.extend(DataFrameLoader(df, page_content_column="text").load())
splitter = RecursiveCharacterTextSplitter(
chunk_size=5000,
chunk_overlap=100,
separators=["\n\n", "\n", "(?<=\\. )", " ", ""],
)
docs = splitter.split_documents(pages)
print(f"{len(docs)} chunks ready for indexing")
Créer le Vector Store CockroachDB
AsyncCockroachDBVectorStore gère automatiquement l’initialisation de la table, le stockage des embeddings et la gestion des index C-SPANN via l’intégration langchain-cockroachdb.
embeddings = VertexAIEmbeddings(model="gemini-embedding-001")
# gemini-embedding-001 produces up to 3072-dimensional vectors
await engine.ainit_vectorstore_table(
table_name="knowledge_base",
vector_dimension=3072,
)
vector_store = AsyncCockroachDBVectorStore(
engine=engine,
embeddings=embeddings,
collection_name="knowledge_base",
)
await vector_store.aadd_documents(docs)
print(f"{len(docs)} chunks indexed in CockroachDB")
Pipeline de génération RAG
generation_model = GenerativeModel("gemini-2.5-flash")
PROMPT = """You are a helpful virtual assistant. Use the sources below as context \
to answer the question. If you don't know the answer, say so.
SOURCES:
{sources}
QUESTION: {query}
ANSWER:"""
async def rag(query: str) -> str:
relevant = await vector_store.asimilarity_search_with_score(query, k=3)
sources = "\n---\n".join(doc.page_content for doc, _ in relevant)
return generation_model.generate_content(
PROMPT.format(sources=sources, query=query)
).text
Cache LLM standard (SQLAlchemyCache)
L’approche la plus simple pour utiliser un cache LLM au-dessus de CockroachDB est le SQLAlchemyCache intégré de LangChain, qui s’intègre de manière transparente avec tous les appels LLM, sans code hash/UPSERT manuel. Utilisez le sql_engine que vous avez déjà :
from langchain.globals import set_llm_cache from langchain.cache import SQLAlchemyCache
set_llm_cache(SQLAlchemyCache(sql_engine))
C’est tout ! LangChain intercepte chaque appel LLM, vérifie la table de cache (llm_cache) dans CockroachDB automatiquement, et retourne la réponse stockée en cas de correspondance.
Cache par correspondance exacte : si la même requête a été posée avant, SQLAlchemyCache retourne en interne la réponse stockée sans appeler le LLM.
Cela remplace tout le bloc de cache manuel (cache_get, cache_put, le décorateur @standard_llmcache, etc.). Une fois set_llm_cache appelé, il s’applique globalement à tous les appels LLM ultérieurs, y compris à l’intérieur des chaînes et des agents.
Cache LLM sémantique et historique des conversations (Memori)
Une fois que mem.llm.register(client) est appelé, Memori intercepte automatiquement tous les appels LLM sans décorateur ni recherche manuelle dans le cache. Il capture les faits, les préférences et les résumés dans CockroachDB et injecte le contexte pertinent à chaque appel suivant.
Cela remplace à la fois le cache standard et les blocs d’historique de conversation dans le tutoriel. Memori gère la mémoire structurée, le rappel et la mise en cache dans une seule couche.
Le cache sémantique de Memori est intégré : ce n’est pas un composant séparé à configurer. Il fonctionne à deux niveaux :
- Rappel sans token (remplace votre cache sémantique) : Lorsqu’une requête est sémantiquement similaire à une précédente, Memori récupère uniquement les extraits de contexte mis en cache pertinents depuis CockroachDB, sans appel LLM ni dépense de tokens. C’est la revendication de « réduction des coûts de 98 % ». Cela se produit automatiquement une fois que
mem.llm.register(client)est appelé. - Augmentation avancée (s’exécute en arrière-plan) : Il convertit les conversations en triplets sémantiques structurés (faits, préférences, règles, relations) stockés dans CockroachDB. Les futures requêtes sont associées à ce store structuré sémantiquement, plus précis que la similarité d’embedding brute.
Comparé à l’approche manuelle dans le tutoriel :
| Configuration manuelle | Memori | |
|---|---|---|
| Cache exact | Hash SHA-256 → SQL UPSERT | Intégré |
| Cache sémantique | asimilarity_search_with_score + seuil |
Rappel sans token intégré |
| Historique de conversation | Table chat_history + injection manuelle |
Mémoire de session intégrée |
| Configuration requise | Similarity Threshold, décorateur, wrapper |
Aucune - intercepté automatiquement |
Tout le bloc de cache + historique manuel dans le tutoriel se résume à :
mem = Memori(conn=get_conn).llm.register(client)
mem.attribution(entity_id="user-123", process_id="my-app")
mem.config.storage.build()
NOTE: Vous ne pouvez pas régler directement le seuil de similarité, cela est abstrait dans le moteur de rappel de Memori.
Partie 2 : CockroachDB + Amazon Bedrock
Installer les dépendances
pip install langchain langchain-community langchain-cockroachdb langchain-aws \
pypdf tenacity psycopg2-binary sqlalchemy boto3 botocore --upgrade
Imports
from langchain.document_loaders import PyPDFLoader, DataFrameLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_cockroachdb import AsyncCockroachDBVectorStore, CockroachDBEngine
from langchain_aws import BedrockEmbeddings, ChatBedrock
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from sqlalchemy import create_engine, text
import boto3, hashlib, pandas as pd
Configurer AWS et CockroachDB
from getpass import getpass
ACCESS_ID = getpass("AWS Access Key ID: ")
ACCESS_KEY = getpass("AWS Secret Access Key: ")
REGION = "us-west-2"
bedrock_runtime = boto3.client(
"bedrock-runtime",
region_name=REGION,
aws_access_key_id=ACCESS_ID,
aws_secret_access_key=ACCESS_KEY
)
# Format: cockroachdb://user:pass@host:26257/db?sslmode=verify-full
COCKROACHDB_URL = getpass("CockroachDB connection string: ")
engine = CockroachDBEngine.from_connection_string(COCKROACHDB_URL)
sql_engine = create_engine(COCKROACHDB_URL.replace("cockroachdb://", "postgresql://"))
Créer le Vector Store CockroachDB
bedrock_embeddings = BedrockEmbeddings(
model_id="amazon.titan-embed-text-v2:0",
client=bedrock_runtime
)
# amazon.titan-embed-text-v2:0 produces 1024-dimensional vectors
await engine.ainit_vectorstore_table(
table_name="knowledge_base",
vector_dimension=1024,
)
vector_store = AsyncCockroachDBVectorStore(
engine=engine,
embeddings=bedrock_embeddings,
collection_name="knowledge_base",
)
await vector_store.aadd_documents(docs)
Pipeline de génération RAG
PROMPT = """You are a helpful virtual assistant. Use the sources below as context \
to answer the question. If you don't know the answer, say so.
SOURCES:
{sources}
QUESTION: {query}
Answer:"""
async def rag(query: str) -> str:
relevant = await vector_store.asimilarity_search_with_score(query, k=3)
sources = "\n---\n".join(doc.page_content for doc, _ in relevant)
llm = ChatBedrock(model_id="anthropic.claude-sonnet-4-6", client=bedrock_runtime)
chain = ConversationChain(llm=llm, verbose=False, memory=ConversationBufferMemory())
return chain.predict(input=PROMPT.format(sources=sources, query=query))
Mise en cache et historique
Les implémentations du cache standard et de l’historique sont identiques à la Partie 1 (en utilisant sql_engine). Seul le client d’embedding du vector store change, utilisez bedrock_embeddings (1024 dims) au lieu des embeddings Vertex AI :
await engine.ainit_vectorstore_table(
table_name="llm_semantic_cache",
vector_dimension=1024,
)
semantic_cache = AsyncCockroachDBVectorStore(
engine=engine,
embeddings=bedrock_embeddings, # Titan v2 instead of Gemini
collection_name="llm_semantic_cache",
)
@standard_llmcache
async def ask_claude(query): return await rag(query)
@semantic_llmcache
async def ask_claude_semantic(query): return await rag(query)
GCP Vertex AI vs AWS Bedrock : Choisir votre stack IA cloud
Les deux intégrations produisent des résultats identiques du point de vue de CockroachDB : les couches de vector store, de mise en cache et d’historique sont inchangées. La décision dépend de votre stratégie cloud, de vos préférences de modèles et de vos exigences de conformité.
| GCP Vertex AI | AWS Bedrock | |
|---|---|---|
| Modèle d’embedding | gemini-embedding-001 (3072 dims) |
amazon.titan-embed-text-v2:0 (1024 dims) |
| Modèle de génération | gemini-2.5-flash |
anthropic.claude-sonnet-4-6 |
| Dimensionnalité vectorielle | 3072 | 1024 |
| Classe LangChain | VertexAIEmbeddings (langchain-google-vertexai) |
BedrockEmbeddings / ChatBedrock (langchain-aws) |
| Mécanisme d’auth | Compte de service GCP / ADC | Clés d’accès AWS IAM / rôle |
| Idéal pour | Stacks natifs GCP, intégration BigQuery | Stacks natifs AWS, choix multi-modèles |
| Variété de modèles | Gemini 2.0, Gemma, Imagen | Anthropic, Cohere, Meta, Amazon, Mistral |
| Modèle de tarification | Par caractère entrée/sortie | Par token entrée/sortie |
| Conformité | RGPD, HIPAA, SOC 2 | RGPD, HIPAA, SOC 2, FedRAMP |
| Latence | ~200–400 ms (embedding) | ~300–600 ms (embedding) |
Choisissez Vertex AI si vous êtes déjà sur GCP, utilisez BigQuery comme source de données, ou avez besoin d’une intégration étroite avec Gemini 2.5. Choisissez Bedrock si vous êtes sur AWS, souhaitez accéder à plusieurs modèles de fondation tiers (Anthropic Claude Sonnet 4.6, Cohere, Meta Llama) depuis une seule API, ou avez besoin de la conformité FedRAMP.
Les deux sont également bien adaptés à n’importe lequel des trois paradigmes RAG décrits ci-dessus (naïf, graph ou agentique), avec CockroachDB servant de couche de données unifiée pour tous.
Ce que RAG débloque : Cas d’utilisation concrets
Les patterns RAG et l’infrastructure décrits ci-dessus ne sont pas des exercices académiques : ils permettent directement une classe d’applications qui seraient impossibles ou peu fiables sans une récupération ancrée. Voici deux exemples concrets qui illustrent la portée de ce qui devient possible une fois que vous avez un pipeline RAG fonctionnel sur CockroachDB.
Assistants conversationnels spécialisés
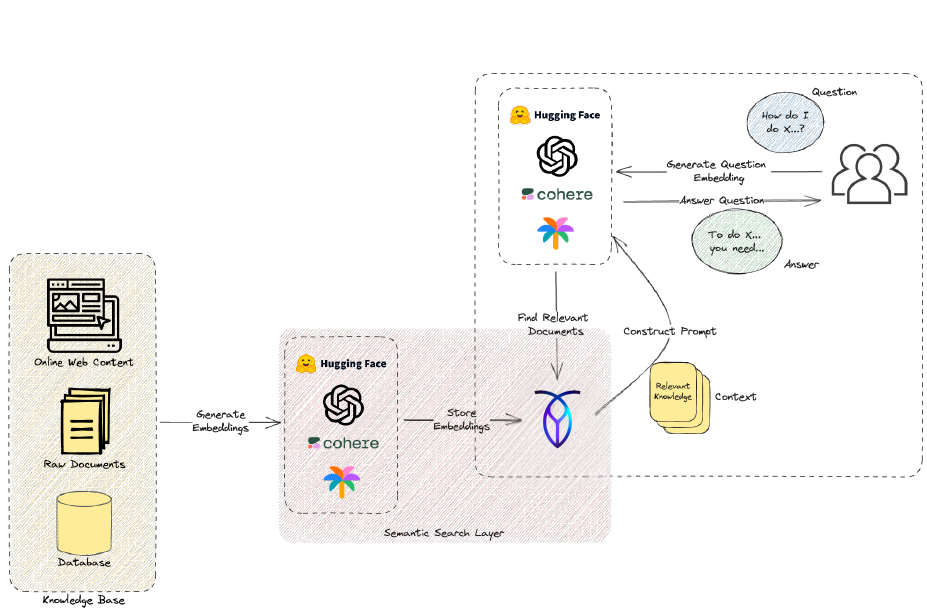
Pipeline RAG pour un assistant conversationnel spécialisé : base de connaissances (contenu web, documents, base de données), couche de recherche sémantique, récupération de contexte, LLM répondant aux questions des utilisateurs
L’application la plus directe est un assistant conversationnel ancré dans une base de connaissances privée. La base de connaissances peut être n’importe quoi : documentation interne, FAQ de support, dépôts réglementaires, articles de recherche, ou une combinaison de contenu web, de documents bruts et d’enregistrements de base de données structurés. Les utilisateurs posent des questions en langage naturel, telles que « Comment configurer l’authentification à deux facteurs ? », « Que dit la clause 4.3 de notre SLA ? », « Résumez les trois rapports d’incidents les plus récents », et le pipeline RAG récupère uniquement le contexte pertinent avant de demander au LLM de composer une réponse.
L’avantage critique par rapport à un modèle affiné est la fraîcheur : la base de connaissances se met à jour en temps réel à mesure que des documents sont ajoutés ou révisés, sans réentraînement. Avec CockroachDB comme vector store, un seul upsert indexe immédiatement le nouveau contenu, et la prochaine requête en bénéficiera déjà. Associez cela à la mémoire de session de Memori et l’assistant se souvient également du contexte de l’utilisateur entre les conversations, le rendant véritablement adaptatif plutôt que sans état.
Les déploiements courants dans ce pattern comprennent :
- Bots de support client qui répondent aux questions sur les produits ou les politiques depuis un corpus de documentation en direct
- Assistants juridiques et de conformité qui font remonter les clauses contractuelles pertinentes ou les exigences réglementaires
- Bases de connaissances internes où les employés interrogent les politiques RH, les runbooks d’ingénierie ou les guides d’intégration
- Assistants de recherche qui synthétisent les résultats de centaines d’articles sans nécessiter de révision manuelle
Recommandations e-commerce personnalisées
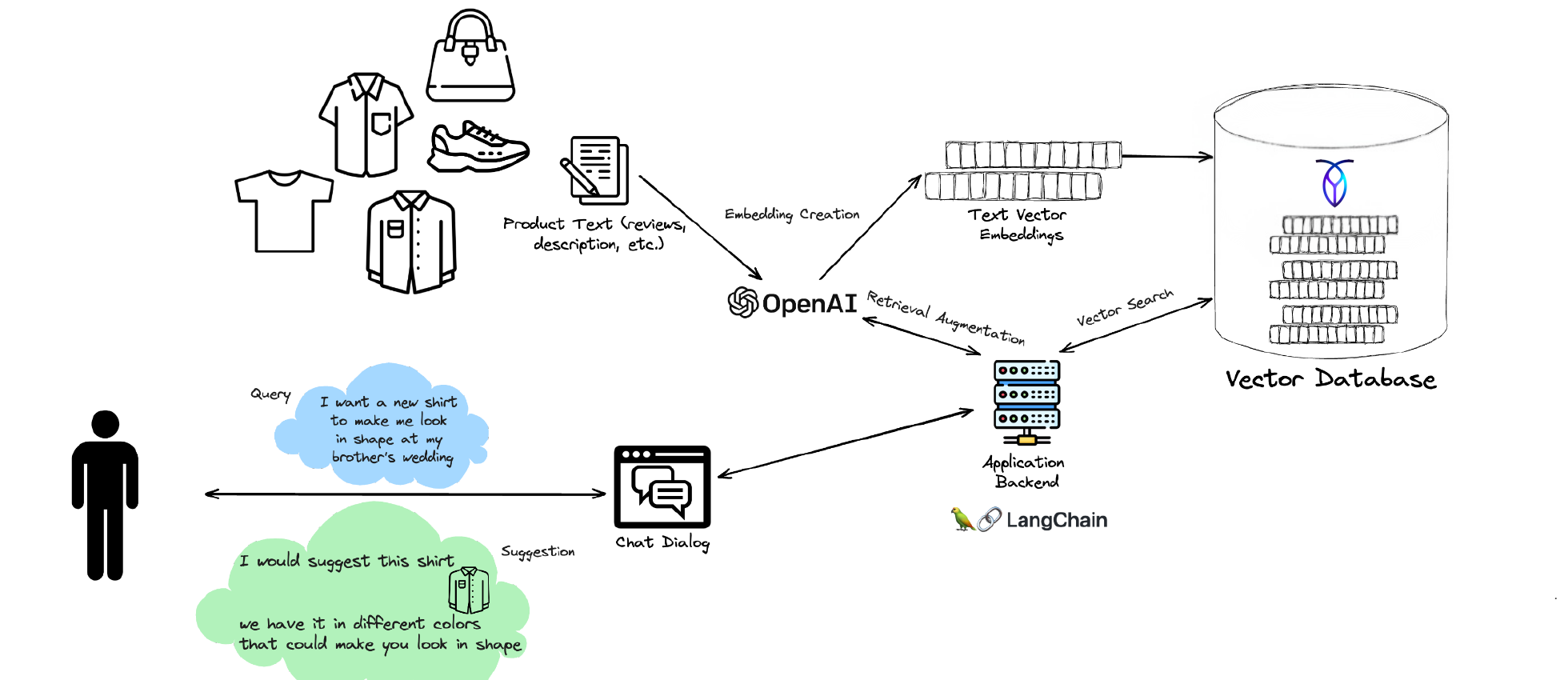
RAG pour chatbot e-commerce : embeddings du catalogue produits dans la base de données vectorielle, requête en langage naturel de l’utilisateur, backend applicatif LangChain, recommandation de produit personnalisée via dialogue de chat
Le e-commerce est un cadre naturel pour RAG car les catalogues de produits sont vastes, changent fréquemment et portent un contenu sémantique riche (descriptions, avis, attributs) que la recherche par mots-clés gère mal. Plutôt que de s’appuyer sur des menus de filtres fragiles ou des moteurs de recommandation précalculés, un assistant shopping alimenté par RAG permet aux utilisateurs de décrire ce dont ils ont besoin en langage naturel et retourne des produits qui correspondent véritablement à l’intention.
Dans l’architecture ci-dessus, les descriptions de produits, les avis et les attributs sont intégrés et indexés dans le vector store CockroachDB. La requête d’un utilisateur, comme « Je veux une nouvelle chemise pour avoir l’air en forme au mariage de mon frère », est intégrée au moment de la requête, associée au catalogue de produits via la recherche de similarité sémantique, et les meilleurs candidats sont passés au LLM avec l’historique de chat de l’utilisateur. Le résultat est une recommandation personnalisée avec une explication : « Je vous suggèrerais cette chemise, nous l’avons en différentes couleurs qui pourraient bien convenir. »
Ce qui rend cela viable à grande échelle est précisément le modèle de multi-tenancy de CockroachDB : l’historique des préférences de chaque client, les interactions passées et les embeddings personnalisés vivent dans leur propre partition d’index, donc les performances sont proportionnelles aux données de cet utilisateur plutôt qu’à la taille du catalogue complet. À mesure que le catalogue croît, l’index C-SPANN se divise et se rééquilibre automatiquement sans aucune intervention opérationnelle.
Au-delà du commerce de mode, cette même architecture alimente :
- Recherche de produits B2B à travers de grands catalogues techniques où les numéros de pièces et les spécifications nécessitent une correspondance sémantique
- Découverte de médias et de contenu qui fait remonter des articles, des vidéos ou des podcasts basés sur les intérêts nuancés des utilisateurs
- Recherche immobilière où des requêtes en langage naturel comme « quartier calme, bonnes écoles, accessible à pied » correspondent à des annonces structurées
- Moteurs de recommandation pour voyages et hôtellerie qui personnalisent les offres depuis un inventaire en direct
Le fil conducteur commun
Les deux cas d’utilisation partagent la même infrastructure : CockroachDB stocke le corpus de connaissances ou de produits, sert d’index vectoriel, met en cache les réponses LLM pour réduire les coûts, et persiste la mémoire de session via Memori. LangChain fournit la couche d’orchestration qui connecte les embeddings, la récupération et la génération en un pipeline cohérent. La stack IA cloud, Vertex AI ou Bedrock, fournit les modèles d’embedding et de génération.
Ce qui change entre un bot de support et un assistant shopping n’est que les données de domaine et le prompt. L’architecture, les propriétés de scalabilité et les garanties opérationnelles restent les mêmes, ce qui est précisément la valeur de construire sur une base de données distribuée à usage général plutôt que sur un vector store dédié.
Ressources
- Documentation de la recherche vectorielle CockroachDB
- langchain-cockroachdb : Intégration LangChain pour CockroachDB
- Développement d’agents avec CockroachDB et LangChain
- De local à global : article Microsoft GraphRAG (arXiv 2404.16130)
- Enquête sur le RAG agentique (arXiv 2501.09136)
- Catalogue de modèles Amazon Bedrock
- Google Vertex AI : IA générative
- Notebook RAG original : GCP
- Notebook RAG original : AWS
- Memori Labs
- Dépôt GitHub Memori Labs