
La façon dont les systèmes IA interagissent avec les bases de données est en train de subir un changement fondamental. Pendant des décennies, les bases de données ont servi de backends passifs, attendant que le code applicatif émette des requêtes. Aujourd’hui, les agents IA interrogent activement, modifient et opèrent des bases de données avec une intervention humaine minimale. Cela nécessite un nouveau type d’infrastructure : une infrastructure structurée, sécurisée, auditables et agnostique aux modèles.
CockroachDB a pleinement embrassé ce changement. En mars 2026, Cockroach Labs a annoncé une suite de capacités prêtes pour les agents : un Serveur MCP entièrement géré, un CLI ccloud repensé, et une bibliothèque publique de compétences d’agents CockroachDB. Parallèlement, le Serveur MCP CockroachDB open-source, un projet communautaire, fournit une interface en langage naturel complète permettant aux agents IA de gérer, surveiller et interroger CockroachDB directement.
Cet article couvre les trois dimensions de la stratégie agent-ready de CockroachDB : le serveur MCP open-source, le point de terminaison MCP d’entreprise géré, et le système de compétences d’agents pour l’automatisation du cycle de vie des bases de données.
Qu’est-ce que le Model Context Protocol ?
Le Model Context Protocol (MCP) est un standard ouvert introduit par Anthropic qui permet aux applications IA de communiquer uniformément avec des outils et des sources de données externes, des systèmes de fichiers aux APIs en passant par les bases de données. Pensez-y comme le « USB-C pour l’IA » : un connecteur unique et interopérable qui permet à n’importe quel agent alimenté par LLM de se connecter à n’importe quel outil sans code d’intégration sur mesure.
Avant MCP, faire interroger une base de données par un agent LLM nécessitait de lui fournir manuellement des informations de schéma, d’écrire du code d’intégration personnalisé et de gérer les problèmes de sécurité pour chaque nouveau modèle ou framework d’agent. MCP élimine cette surcharge en fournissant une couche de découverte et d’invocation standardisée.
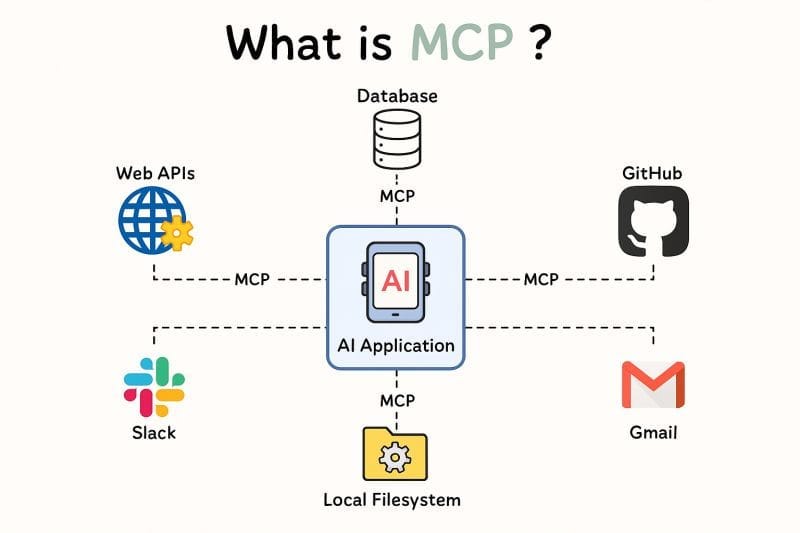
Vue d’ensemble du Model Context Protocol
Le Serveur MCP CockroachDB (Projet communautaire)
Le Serveur MCP CockroachDB est un projet Python open-source qui fait le pont entre les modèles de langage IA et CockroachDB via le Model Context Protocol. Il s’intègre avec les clients compatibles MCP tels que Claude Desktop, Cursor, VS Code avec GitHub Copilot et l’OpenAI Agents SDK.
CockroachDB n’est pas une base de données monolithique typique. C’est une base de données SQL distribuée où les données sont automatiquement fragmentées en « plages » et répliquées sur plusieurs nœuds. Le serveur MCP expose cette complexité à travers 29 outils distincts organisés en quatre catégories, permettant aux agents IA d’interagir avec toute l’étendue des capacités de CockroachDB, de la santé du cluster aux opérations de données transactionnelles, en utilisant le langage naturel.
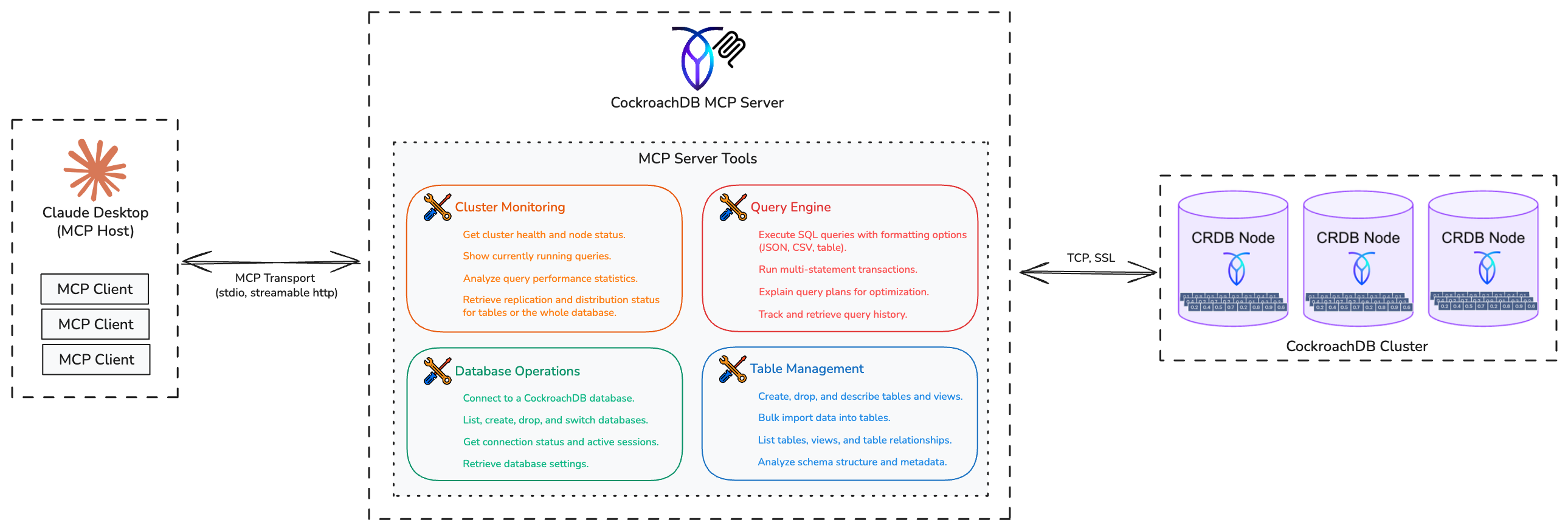
Architecture du Serveur MCP CockroachDB
Catégories d’outils
Surveillance du cluster
| Outil | Description |
|---|---|
get_cluster_status |
Santé du cluster et distribution des nœuds |
show_running_queries |
Requêtes actuellement actives |
analyze_performance |
Statistiques de performance des requêtes |
get_replication_status |
Statut de réplication et de distribution |
Opérations de base de données
| Outil | Description |
|---|---|
connect / connect_database |
Établir des connexions |
list_databases |
Afficher toutes les bases de données |
create_database / drop_database |
Cycle de vie de la base de données |
switch_database |
Changer la base de données active |
get_active_connections |
Sessions utilisateurs actives |
get_database_settings |
Configuration actuelle |
Gestion des tables et du schéma
| Outil | Description |
|---|---|
list_tables / list_views |
Découverte du schéma |
create_table / drop_table |
Gestion des tables |
create_index / drop_index |
Gestion des index |
describe_table |
Informations sur le schéma |
analyze_schema |
Vue d’ensemble complète de la base de données |
get_table_relationships |
Analyse des clés étrangères |
bulk_import |
Chargement de données depuis le stockage cloud (S3, GCS, Azure) |
Exécution de requêtes et de transactions
| Outil | Description |
|---|---|
execute_query |
Exécution de requêtes SQL (sortie JSON, CSV, tableau) |
execute_transaction |
Opérations multi-instructions atomiques |
explain_query |
Analyse du plan d’exécution des requêtes |
get_query_history |
Piste d’audit des requêtes |
Installation
Démarrage rapide avec uvx (sans clonage local) :
uvx --from git+https://github.com/amineelkouhen/mcp-cockroachdb.git@0.1.0 cockroachdb-mcp-server \
--url postgresql://localhost:26257/defaultdb
Paramètres individuels :
uvx --from git+https://github.com/amineelkouhen/mcp-cockroachdb.git cockroachdb-mcp-server \
--host localhost --port 26257 --database defaultdb --user root --password mypassword
Connexion SSL :
uvx --from git+https://github.com/amineelkouhen/mcp-cockroachdb.git cockroachdb-mcp-server \
--url postgresql://user:pass@cockroach.example.com:26257/defaultdb?sslmode=verify-full&sslrootcert=path/to/ca.crt&sslcert=path/to/client.username.crt&sslkey=path/to/client.username.key
Depuis les sources (développement) :
git clone https://github.com/amineelkouhen/mcp-cockroachdb.git
cd mcp-cockroachdb
uv venv
source .venv/bin/activate
uv sync
uv run cockroachdb-mcp-server --help
Docker Compose (développement local) :
docker compose up -d
# MCP server: http://localhost:8000/mcp/
# CockroachDB UI: http://localhost:8080
docker compose logs -f mcp-server
Configuration
Le serveur accepte les arguments CLI, les variables d’environnement et les valeurs par défaut dans cet ordre de priorité.
| Variable | Description | Défaut |
|---|---|---|
CRDB_HOST |
Nom d’hôte/adresse | 127.0.0.1 |
CRDB_PORT |
Port de l’interface SQL | 26257 |
CRDB_DATABASE |
Nom de la base de données | defaultdb |
CRDB_USERNAME |
Utilisateur SQL | root |
CRDB_PWD |
Mot de passe utilisateur | |
CRDB_SSL_MODE |
Mode SSL | disable |
CRDB_SSL_CA_PATH |
Chemin du certificat CA | |
CRDB_SSL_CERTFILE |
Chemin du certificat client | |
CRDB_SSL_KEYFILE |
Chemin de la clé client |
Intégrations clients
Claude Desktop (claude_desktop_config.json) :
{
"mcpServers": {
"cockroach-mcp-server": {
"type": "stdio",
"command": "/opt/homebrew/bin/uvx",
"args": [
"--from", "git+https://github.com/amineelkouhen/mcp-cockroachdb.git",
"cockroachdb-mcp-server",
"--url", "postgresql://localhost:26257/defaultdb"
]
}
}
}
VS Code avec GitHub Copilot (settings.json) :
{
"chat.agent.enabled": true,
"mcp": {
"servers": {
"CockroachDB MCP Server": {
"type": "stdio",
"command": "uvx",
"args": [
"--from", "git+https://github.com/amineelkouhen/mcp-cockroachdb.git",
"cockroachdb-mcp-server",
"--url", "postgresql://root@localhost:26257/defaultdb"
]
}
}
}
}
Cursor (~/.cursor/mcp.json) :
{
"mcpServers": {
"cockroach-mcp-server": {
"type": "stdio",
"command": "uvx",
"args": [
"--from",
"git+https://github.com/amineelkouhen/mcp-cockroachdb",
"--url",
"postgresql://root@localhost:26257/defaultdb?sslmode=disable"
]
}
}
}
Docker (Claude Desktop) :
{
"mcpServers": {
"cockroach": {
"command": "docker",
"args": ["run", "--rm", "--name", "cockroachdb-mcp-server",
"-e", "CRDB_HOST=<host>",
"-e", "CRDB_PORT=<port>",
"-e", "CRDB_DATABASE=<database>",
"-e", "CRDB_USERNAME=<user>",
"mcp-cockroachdb"]
}
}
}
Pour dépanner Claude Desktop sur macOS : tail -f ~/Library/Logs/Claude/mcp-server-cockroach.log
Cas d’utilisation concrets
Cas d’utilisation 1 : Administrateur de base de données alimenté par l’IA
Un exemple de prompt pour diagnostiquer des ralentissements intermittents :
« Hé, pouvez-vous vérifier la santé de mon cluster CockroachDB ? Montrez-moi les requêtes longues en cours d’exécution. Veuillez également analyser le plan de requête pour
SELECT * FROM users WHERE last_active < NOW() - INTERVAL '30 days'et me dire s’il utilise un index. »
En coulisses, l’agent orchestre : get_cluster_status → show_running_queries → explain_query, puis synthétise les résultats avec des suggestions d’optimisation.
Cas d’utilisation 2 : Assistant de prototypage rapide
« Je construis une nouvelle fonctionnalité. Veuillez créer une nouvelle table appelée
feature_flagsavec des colonnes pourid(UUID, clé primaire),name(STRING, unique),is_enabled(BOOL, valeur par défaut true) etcreated_at(TIMESTAMP). Une fois fait, importez en masse les flags initiaux depuis le fichier CSV à l’adresses3://my-company-data/dev/feature_flags.csv. »
L’agent combine l’exécution DDL de create_table avec bulk_import en séquence, puis confirme le nombre d’enregistrements.
CockroachDB est conçu pour les agents IA
Au-delà du serveur MCP communautaire, Cockroach Labs a annoncé un ensemble de capacités d’agent natives de niveau entreprise. Les systèmes IA se comportent différemment des services traditionnels : ils distribuent le travail, relancent agressivement et génèrent des rafales d’écritures concurrentes à travers les régions. CockroachDB gère cette charge élargie grâce à la distribution automatique des données, la scalabilité horizontale et l’isolation sérialisable par défaut.
Comment les agents IA utilisent les bases de données
Il existe deux modèles d’interaction principaux :
-
Backend applicatif : Les systèmes IA nécessitent des bases de données supportant une disponibilité permanente et des déploiements multi-région. CockroachDB gère cela grâce à la distribution des données et la scalabilité horizontale sans partitionnement manuel.
-
Surface d’interaction : Les agents assistent dans tout le cycle de vie de la base de données : provisionnement des clusters, révision des schémas et triage des alertes.
Ce que signifie « agent-ready »
Une base de données agent-ready requiert :
- Interfaces structurées : sorties fiables et interprétables par les machines
- Permissions limitées : régissant ce que les agents peuvent et ne peuvent pas faire
- Auditabilité : journalisation complète des actions pour chaque opération d’agent
- Interfaces agnostiques aux modèles : compatibilité avec les frameworks et les fournisseurs LLM
Le Serveur MCP géré de CockroachDB
Le Serveur MCP géré est un point de terminaison MCP hébergé dans le cloud conçu pour les environnements d’entreprise avec des systèmes d’agents partagés. Contrairement au serveur communautaire, il ne nécessite aucun déploiement local : les développeurs copient un extrait de configuration depuis la Cloud Console et le collent dans leur client MCP en quelques minutes.
Point de terminaison : https://cockroachlabs.cloud/mcp
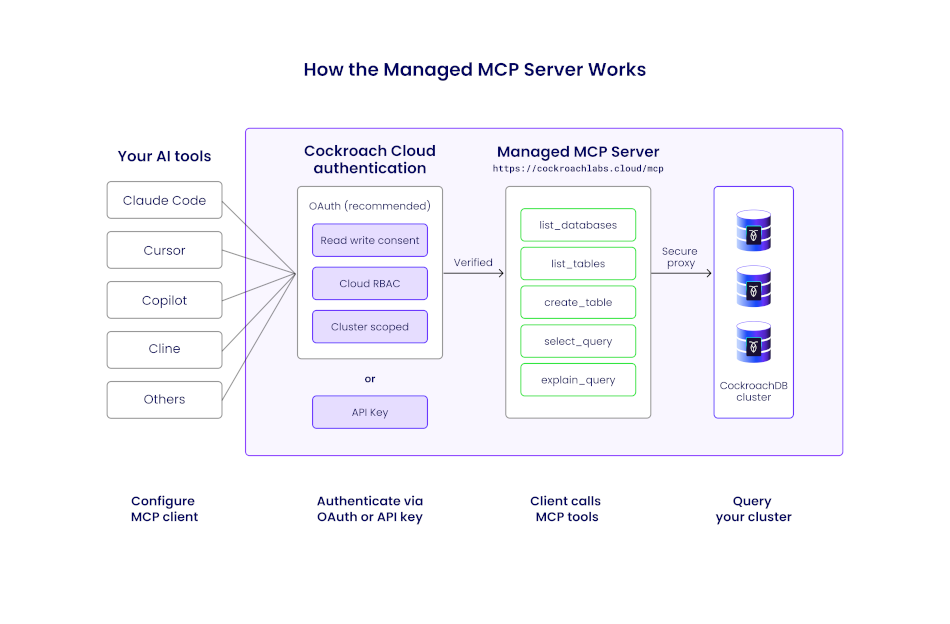
Comment fonctionne le Serveur MCP géré de CockroachDB
Flux de requête
Chaque requête MCP suit ce chemin :
- Le client MCP (par ex., Claude Code) envoie une requête JSON-RPC via HTTPS
- La requête passe par un équilibreur de charge
- Le
mcp-serviceinterne achemine le trafic/mcpvers le gestionnaire MCP - Le pipeline middleware applique l’auth, les limites de débit et la journalisation
- Un gestionnaire d’outil effectue l’autorisation et exécute l’opération demandée
- Les résultats sont retournés sous forme de réponse JSON-RPC conforme MCP
L’implémentation utilise le SDK officiel modelcontextprotocol/go-sdk. Le transport HTTP est supporté et recommandé ; le transport SSE est intentionnellement exclu (déprécié dans MCP).
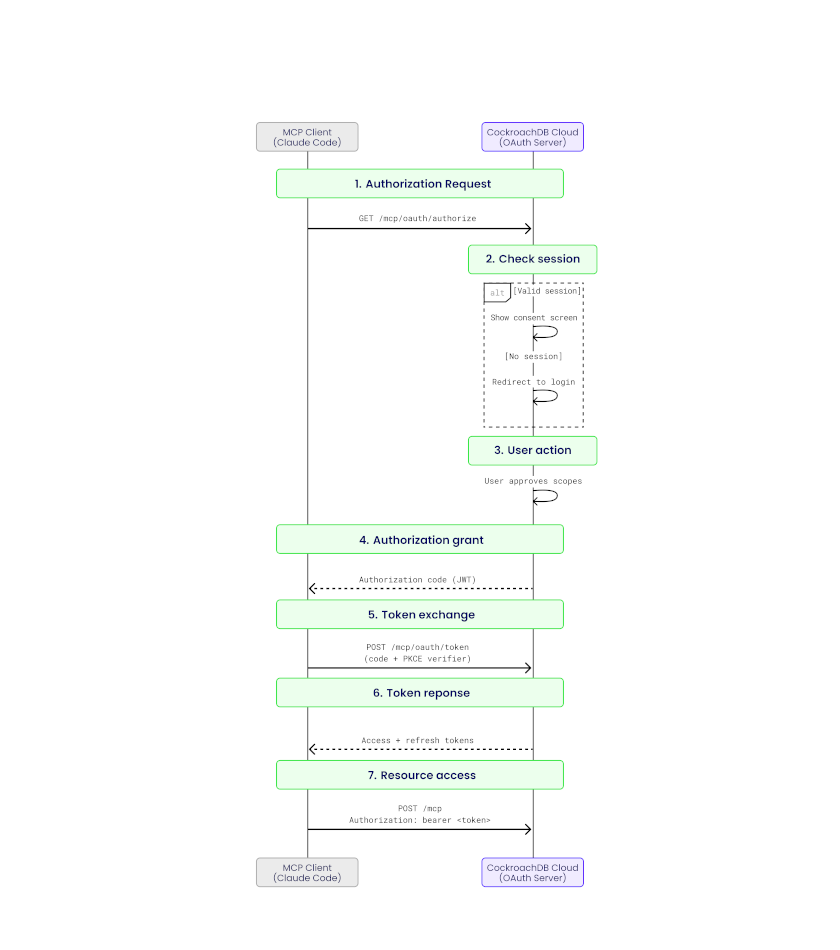
Architecture du Serveur MCP géré
Sécurité : Authentification et autorisation
Deux mécanismes d’authentification sont supportés :
- OAuth 2.1 (Flux de code d’autorisation avec PKCE) : pour les workflows utilisateurs interactifs avec des permissions limitées :
mcp:readpour un accès en lecture seule sécurisémcp:writepour des mutations contrôlées
- Clés API de compte de service : pour les environnements entièrement autonomes avec des rôles Cloud RBAC limités à des clusters spécifiques
Chaque invocation d’outil effectue une vérification Cloud RBAC avant l’exécution. Les requêtes sont rejetées si les permissions dépassent la portée attendue.
Consentement en lecture et en écriture
Le consentement en lecture seule ne permet que des outils sûrs et introspectifs tels que list_databases, select_query et get_table_schema. Les opérations d’écriture sont explicitement bloquées et les tables système sont sur liste de refus pour empêcher les accès sensibles.
Le consentement en écriture active des outils supplémentaires tels que create_database, create_table et insert_rows. Les opérations SQL destructives (DROP, TRUNCATE) restent non supportées.
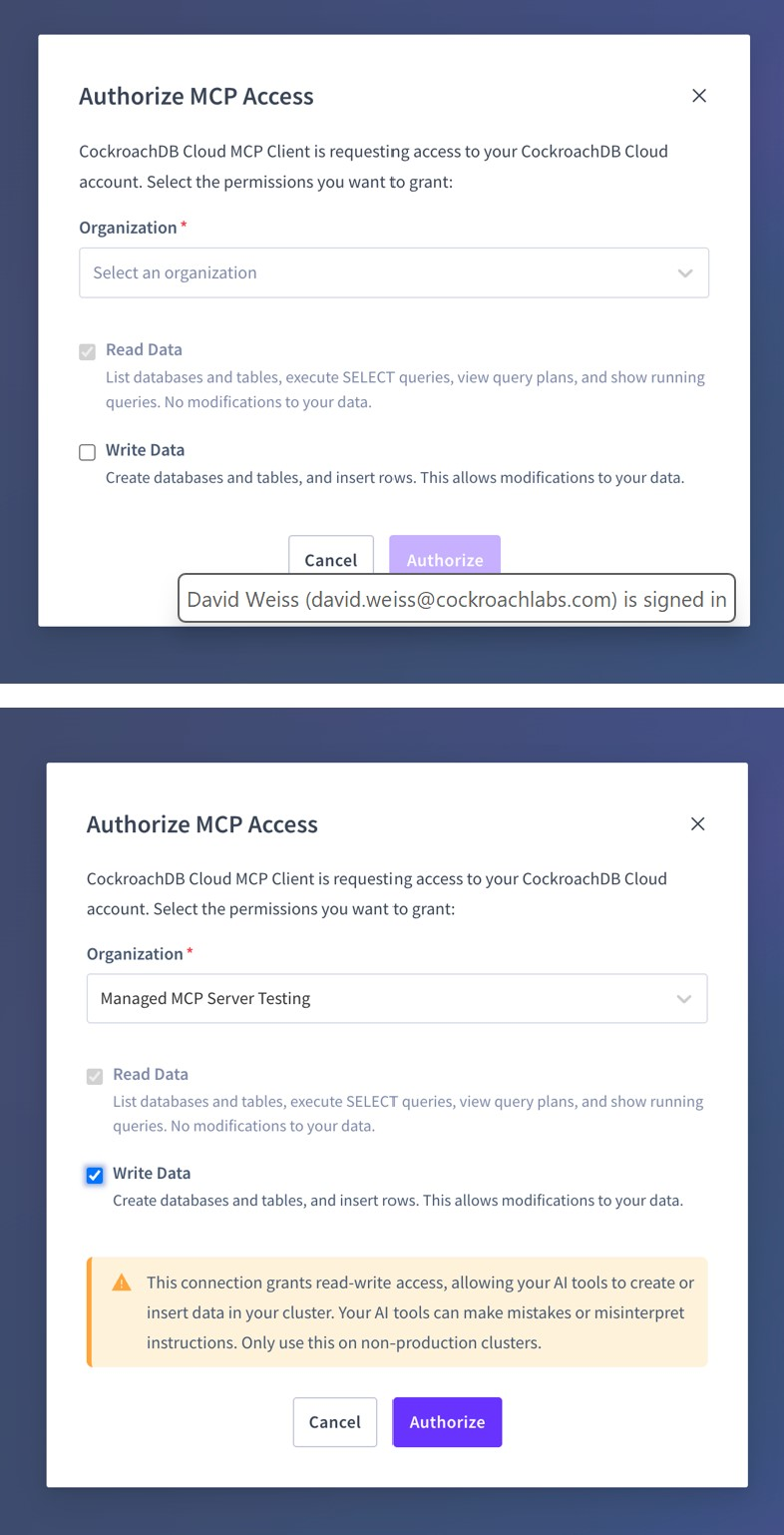
Autorisation de l’accès MCP : Consentement en lecture et en écriture
Observabilité
Toutes les requêtes émettent des journaux structurés tagués avec mcp, incluant :
- Le nom de l’outil
- Le contexte du cluster et de l’organisation
- La forme SQL expurgée
- La latence et la taille de la réponse
- Les codes d’erreur spécifiques MCP
Les traces de bout en bout alimentent le pipeline d’observabilité, avec des spans couvrant les étapes middleware, les appels API et les requêtes de base de données. Les événements d’utilisation des outils sont envoyés au pipeline d’analyse, permettant l’analyse des modèles d’adoption et des workflows réels.
Prise en main
- Connectez-vous à la CockroachDB Cloud Console
- Naviguez vers votre cluster, cliquez sur la modal Connect et sélectionnez l’option d’intégration MCP
- Copiez l’extrait de configuration généré
- Collez l’extrait dans le fichier de configuration de votre client MCP (Claude Code, Cursor ou VS Code)
- Commencez à poser des questions à votre assistant IA sur votre base de données
Serveur MCP communautaire vs. Serveur MCP géré : Une comparaison objective
Pour comprendre pourquoi cette comparaison est importante, il est utile de la situer dans l’évolution plus large du développement assisté par l’IA. Une analyse indépendante identifie trois ères distinctes :
- Ère pré-IA : Les développeurs codaient manuellement chaque interaction, basculant entre des outils séparés pour les requêtes, la surveillance et la gestion des schémas.
- Ère Copilot (2021–2024) : L’IA est entrée en scène comme un assistant passif (complétion de code et suggestions, mais les humains conduisaient toujours chaque action).
- Ère agentique (2025+) : L’IA passe de copilote passif à agent actif, déléguant des tâches entières de manière autonome. MCP est l’infrastructure critique permettant ce changement, une couche de standardisation qui permet à tout agent de découvrir et d’invoquer n’importe quel outil sans code d’intégration sur mesure.
Les deux options couvertes ici se situent clairement dans cette ère agentique, mais elles représentent des philosophies différentes quant à l’emplacement de la sécurité, du contrôle et de la flexibilité.
Déploiement et opérations
Le serveur communautaire est auto-hébergé : vous l’exécutez sur votre propre infrastructure via uvx, Docker ou depuis les sources. Vous contrôlez le binaire, la configuration et le cycle de mise à jour. Chaque ligne de Python est lisible et forkable sur GitHub. L’image Docker officielle est hébergée sous l’espace de noms mcp/ sur Docker Hub, un marqueur de l’importance du projet dans la communauté, même s’il ne s’agit pas d’un produit officiel de Cockroach Labs. La position de l’auteur en tant qu’Architecte Senior de Solutions Partenaires chez Cockroach Labs confère au projet un haut degré d’autorité et de crédibilité.
Le serveur géré est zéro-ops : Cockroach Labs l’héberge à https://cockroachlabs.cloud/mcp. Il n’y a rien à déployer, mettre à jour ou surveiller de votre côté. Les clients reçoivent automatiquement les améliorations du protocole à mesure que MCP évolue, sans suivre les changements de spécification ni redéployer des services. Pour les équipes qui veulent évaluer ou livrer rapidement, cela élimine toute friction d’infrastructure.
Couverture des outils et capacités
Le serveur communautaire expose 29 outils couvrant tout le spectre opérationnel, de get_cluster_status et show_running_queries à create_database, drop_table, create_index, bulk_import et execute_transaction. C’est le choix évident pour les développeurs qui ont besoin d’un outil complet : son inclusion de capacités administratives et de surveillance le rend uniquement puissant pour le développement de bout en bout et les tâches opérationnelles légères. L’outil bulk_import seul , permettant l’ingestion directe de données depuis Amazon S3, Azure Blob Storage et Google Cloud Storage, n’a pas d’équivalent dans l’offre gérée.
Le serveur géré fournit un ensemble d’outils organisé et à portée de sécurité. En mode lecture seule, il autorise les outils introspectifs (list_databases, select_query, get_table_schema). Le consentement en écriture débloque les opérations additives (create_database, create_table, insert_rows). Le SQL destructif (DROP, TRUNCATE) est définitivement non supporté. Cette contrainte délibérée est une fonctionnalité, pas une limitation : elle rend le serveur géré adapté aux environnements de production où une erreur d’agent ne doit jamais entraîner une perte de données.
Modèle de sécurité
| Dimension | Serveur communautaire | Serveur géré |
|---|---|---|
| Authentification | Nom d’utilisateur/mot de passe DB + certificats SSL | OAuth 2.1 (PKCE) ou clés API de compte de service |
| Autorisation | Privilèges de l’utilisateur DB | Cloud RBAC vérifié par invocation d’outil |
| Contrôle de portée | Défini au niveau de l’utilisateur DB | Tokens de consentement mcp:read / mcp:write |
| Journalisation d’audit | Journaux du processus local | Télémétrie structurée dans le pipeline d’observabilité Cloud |
| Opérations destructives | Autorisées (contrôlées par l’utilisateur DB) | Bloquées au niveau de la couche MCP |
Le serveur communautaire est un pont : sa posture de sécurité dépend entièrement de la façon dont vous le configurez, pas de ce que le serveur impose lui-même. Une analyse de sécurité indépendante est explicite sur ce point : soyez extrêmement prudent avant de le connecter à une base de données de production avec des permissions d’écriture. Lorsque vous le déployez, suivez ces pratiques :
- Créez un utilisateur SQL dédié avec les privilèges minimaux requis ; ne vous connectez jamais en tant que
root - Appliquez la segmentation réseau et les règles de pare-feu pour que seul le processus MCP puisse atteindre le port de la base de données
- Examinez régulièrement les journaux du serveur MCP et les journaux d’audit de la base de données pour détecter toute activité inattendue
- Exécutez le serveur dans Docker pour un isolement supplémentaire, en utilisant l’image officielle
mcp/cockroachdb
Le serveur géré applique le principe du moindre privilège par conception : chaque invocation d’outil est indépendamment autorisée par rapport au Cloud RBAC, et les requêtes dépassant la portée sont rejetées avant d’atteindre la base de données. Aucune configuration opérateur n’est requise pour atteindre cette posture ; c’est le comportement par défaut.
Observabilité
Les journaux du serveur communautaire sont locaux au processus et doivent être intégrés dans votre propre stack de surveillance. La boucle de rétroaction itérative (prompt, action IA, validation directe des données) n’est visible que dans vos propres outils. Le serveur géré émet des journaux structurés tagués avec mcp pour chaque requête, incluant le nom de l’outil, le contexte du cluster, forme SQL expurgée, latence et codes d’erreur spécifiques MCP, alimentant directement les pipelines d’observabilité et d’analyse de Cockroach Labs avec des traces de bout en bout.
Personnalisation et extensibilité
Le serveur communautaire est entièrement extensible : forkez le dépôt, ajoutez de nouveaux outils, modifiez le comportement et soumettez des pull requests. Il supporte les transports stdio et http, avec le HTTP streamable planifié comme prochaine addition de transport pour permettre des déploiements plus flexibles dans les environnements web ou serverless. Les éléments futurs de la feuille de route incluent également des contrôles IAM plus approfondis et des outils de réglage de performance plus granulaires. Le projet est sous licence MIT et accueille ouvertement les contributions.
Le serveur géré n’est pas personnalisable au sens traditionnel : vous consommez ce que Cockroach Labs livre. Cependant, comme il est continuellement amélioré sans intervention des opérateurs, vous bénéficiez automatiquement de chaque mise à jour de la spécification MCP et de chaque amélioration de l’API CockroachDB Cloud.
Le serveur communautaire parmi les implémentations MCP CockroachDB
Plusieurs serveurs MCP CockroachDB open-source existent dans l’écosystème. Comprendre où se situe amineelkouhen/mcp-cockroachdb par rapport à eux est important, car c’est précisément sa complétude qui en fait le bon homologue à comparer avec l’offre gérée officielle. Cette évaluation est soutenue par des analyses indépendantes du guide des ingénieurs de Skywork et de la revue approfondie.
| Implémentation | Langage | Nombre d’outils | Surveillance cluster | Gestion schéma | Import en masse | Transactions | Accès |
|---|---|---|---|---|---|---|---|
| amineelkouhen/mcp-cockroachdb | Python | 29 | Complète | Complète | S3/GCS/Azure | Atomiques | Lecture + Écriture |
| Swayingleaves/cockroachdb-mcp-server | Python (psycopg2) | 6 (connect, disconnect, initialize, get_tables, get_table_schema, execute_query) |
Non | Partielle | Non | Non | Lecture + Écriture |
| dhartunian/cockroachdb-mcp-server | Node.js / TypeScript | 1 (query) |
Non | Non | Non | Non | Lecture + Écriture (limité) |
| CData cockroachdb-mcp-server-by-cdata | Java / JDBC | 3 (get_tables, get_columns, run_query) |
Non | Non | Non | Non | Lecture seule |
Les lacunes sont significatives. Swayingleaves se concentre étroitement sur la stabilité des connexions (keep-alive et reconnexion automatique), mais manque de surveillance et de gestion des schémas. Le serveur TypeScript de Hartunian est réduit au minimum absolu : un seul outil query qui exécute du SQL, sans introspection de schéma, pas de surveillance, pas de surface administrative. L’implémentation Java de CData est en lecture seule par conception, n’exposant que 3 outils (get_tables, get_columns, run_query), adaptée aux utilisateurs professionnels interrogeant des données en direct sans SQL, mais inutilisable pour quoi que ce soit d’opérationnel.
amineelkouhen/mcp-cockroachdb est la seule implémentation communautaire qui couvre tout le spectre développeur-ops : surveillance de la santé du cluster et de la réplication, DDL complet (créer, modifier, supprimer), gestion des index, ingestion de données en masse depuis le stockage cloud, transactions multi-instructions atomiques et analyse des plans de requête, le tout dans un seul serveur. C’est également la seule implémentation avec une image Docker officielle hébergée sous l’espace de noms mcp/ sur Docker Hub, un marqueur de maturité et de confiance de la communauté que les autres n’ont pas.
Cette complétude justifie précisément de le placer aux côtés du serveur géré pour comparaison. Les autres implémentations communautaires concourent dans une catégorie différente : ce sont des outils de requête légers. amineelkouhen/mcp-cockroachdb est une interface de gestion complète de base de données exposée aux agents IA, ce qui est la même ambition que le serveur géré, simplement livrée par un modèle opérationnel différent.
CockroachDB dans l’écosystème MCP des bases de données
En prenant encore plus de recul, les serveurs MCP CockroachDB occupent une niche distincte par rapport aux autres implémentations MCP de bases de données :
| Serveur | Idéal pour | Modèle d’accès |
|---|---|---|
| CockroachDB (A. El Kouhen) | Base de données opérationnelle distribuée (workflow développeur + ops) | Admin complet |
| PostgreSQL (Anton O.) | Workflow développeur sur nœud unique, simplicité, accès direct | Lecture + Écriture |
| MongoDB (Officiel) | Exploration de données et inspection sécurisée du schéma | Lecture seule |
| DuckDB (MotherDuck) | Analytics local et cloud, exécution SQL hybride | Analytics |
Le serveur communautaire CockroachDB occupe une position unique : il cible tout le workflow développeur-ops pour une base de données distribuée et opérationnellement complexe. Cela contraste avec les serveurs PostgreSQL qui mettent l’accent sur la simplicité, le serveur MongoDB officiel qui privilégie l’exploration sécurisée en lecture seule, et les serveurs DuckDB focalisés purement sur l’analytics. Aucun autre serveur MCP de base de données dans l’écosystème ne combine la surveillance de la santé du cluster, la gestion DDL, l’import cloud en masse et l’exécution de requêtes transactionnelles dans une seule interface.
Quand utiliser lequel
| Scénario | Recommandé |
|---|---|
| Développement local, exploration de schéma, prototypage | Serveur communautaire |
| Administration complète du cluster via IA (gestion des index, import en masse) | Serveur communautaire |
| Utilisateurs non techniques interrogeant des données en langage naturel | Serveur communautaire |
| Contributeurs open-source et constructeurs d’outils | Serveur communautaire |
| Accès d’agent en production avec exigences de sécurité d’entreprise | Serveur géré |
| Environnements multi-tenant ou d’agents partagés | Serveur géré |
| Industries réglementées nécessitant des pistes d’audit | Serveur géré |
| Équipes sans capacité d’infrastructure pour l’auto-hébergement | Serveur géré |
En pratique, les deux sont complémentaires plutôt que concurrents. De nombreuses équipes utilisent le serveur communautaire pendant le développement, où l’accès administratif complet, la transparence du code et les boucles de rétroaction itératives sont les plus importants, et passent au serveur géré pour les charges de travail de production où la sécurité, l’observabilité et la maintenance zéro-ops prennent le dessus.
Compétences d’agents IA pour l’automatisation du cycle de vie des bases de données
Les compétences d’agents CockroachDB sont des capacités structurées qui définissent comment un système IA interagit avec CockroachDB. Elles suivent des interfaces standard ouvertes, les rendant portables entre différents modèles et outils sans réécrire les intégrations. Les équipes peuvent utiliser les compétences d’agents tout au long de l’intégration, du développement, des opérations et des décisions de scalabilité, tout au long du cycle de vie complet de la base de données.
Pour comprendre où les compétences s’insèrent dans un système agentique, il est utile de penser en trois couches :
-
Les agents sont les orchestrateurs : ils décident quand faire le travail. Un agent reçoit un objectif (par ex., « enquêter sur cette pointe CPU ») et planifie une séquence d’actions pour l’accomplir. Il choisit quels outils appeler et dans quel ordre, relance en cas d’échec et synthétise les résultats en une réponse.
-
Les compétences sont l’expertise : elles enseignent à l’agent comment faire correctement le travail. Une compétence encode les connaissances du domaine : les bons modèles SQL CockroachDB à utiliser, quels index sont appropriés pour une charge de travail donnée, comment interpréter un plan de requête, ou quand recommander une clé primaire à hachage fragmenté plutôt qu’une clé composite. Sans compétences, un agent pourrait produire du SQL syntaxiquement valide mais sémantiquement incorrect.
-
Les outils MCP sont les connecteurs : ils fournissent le quoi : l’interface réelle avec la base de données. Les outils sont les actions concrètes qu’un agent peut effectuer (
execute_query,explain_query,get_cluster_status). Ils ne portent aucun jugement sur quand ou comment les utiliser ; c’est la responsabilité de l’agent et de la compétence.
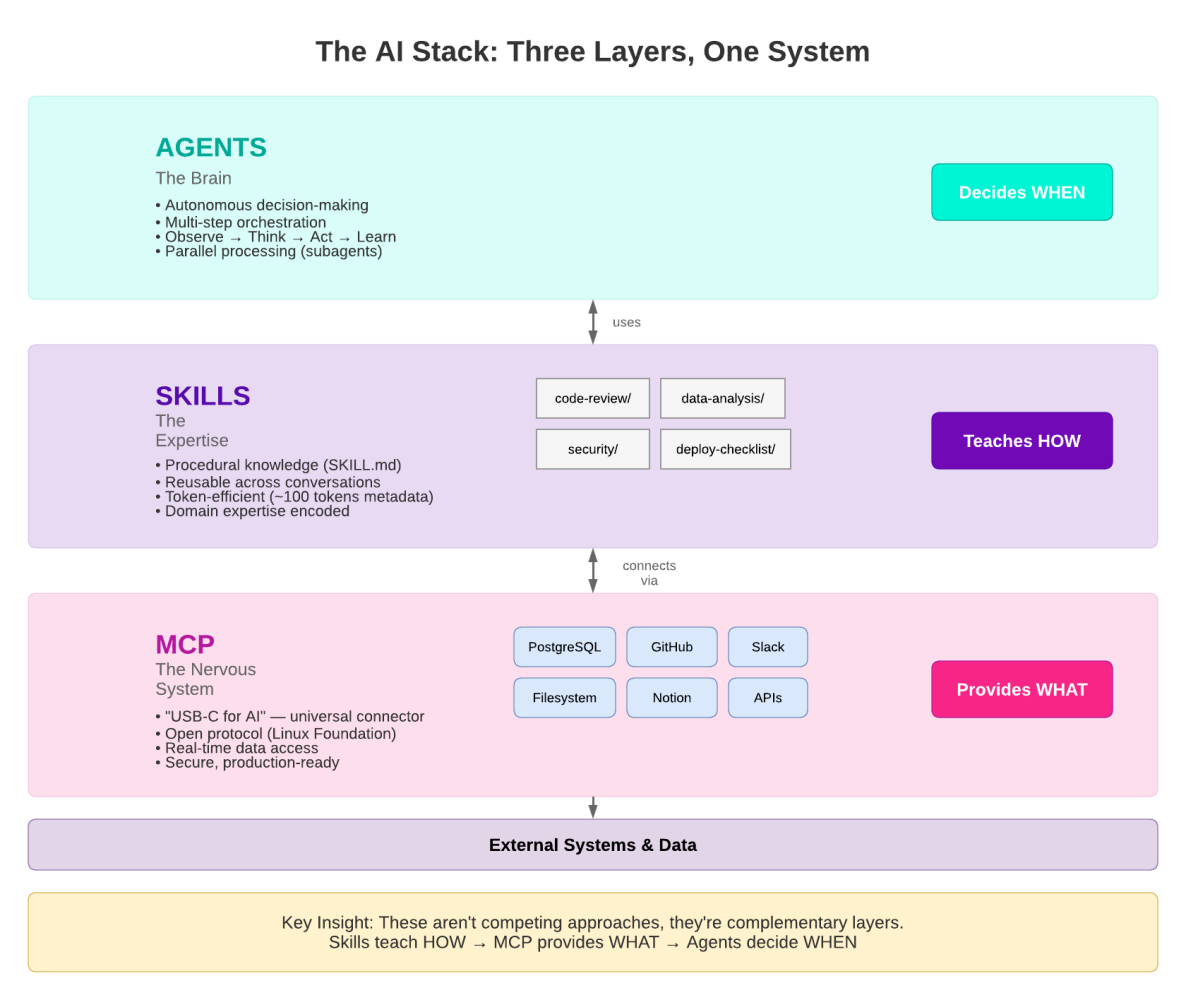
Agents, Compétences et Outils MCP : Les trois couches de l’interaction agentique avec les bases de données
Le dépôt cockroachlabs/cockroachdb-skills est la source officielle de ces compétences. Vous pouvez installer la collection complète dans n’importe quel outil compatible avec les compétences d’agent avec une seule commande :
npx skills add cockroachlabs/cockroachdb-skills
Neuf domaines de compétences
1. Intégration et migrations
Compétences qui guident les équipes dans la prise en main de CockroachDB et le déplacement des charges de travail existantes vers le système. Cela inclut la traduction de schéma depuis PostgreSQL, l’utilisation de MOLT pour le déplacement de données, la validation du trafic fantôme et des stratégies de basculement sécurisées qui minimisent les interruptions.
2. Développement d’applications
Compétences qui aident les développeurs à construire efficacement des applications avec CockroachDB, couvrant les meilleures pratiques de pool de connexions, la logique de relance des transactions, les modèles de compatibilité ORM et les idiomes SQL distribués qui diffèrent des bases de données à nœud unique traditionnelles.
3. Performance et scalabilité
Compétences qui diagnostiquent et résolvent les problèmes de performance des requêtes : analyse des plans d’exécution, identification des index manquants, recommandation de clés primaires à hachage fragmenté pour les charges de travail à écriture intensive, interprétation de la distribution des plages et guidage des décisions de scalabilité horizontale sous charge.
4. Opérations et cycle de vie
Compétences pour les opérations quotidiennes du cluster et la gestion des versions, incluant les mises à niveau progressives, la décommission des nœuds, la planification des sauvegardes et restaurations, et les procédures de finalisation du cluster après les mises à niveau de version majeure.
5. Résilience et reprise après sinistre
Compétences qui assurent la haute disponibilité et préparent les équipes aux scénarios de défaillance : configuration des zones de réplication, validation des objectifs de survie multi-région, conception pour les défaillances de zones et de régions, et test des runbooks de récupération avant les incidents.
6. Observabilité et diagnostics
Compétences qui surveillent, alertent et diagnostiquent les problèmes à travers le cluster, incluant le profilage des instructions SQL, interprétation des événements de contention, diagnostic des plages chaudes, surveillance des tâches d’arrière-plan et corrélation des erreurs applicatives avec les métriques de la base de données.
7. Sécurité et gouvernance
Compétences qui renforcent les déploiements CockroachDB : configuration de RBAC et de la sécurité au niveau des lignes, application de TLS et de la rotation des certificats, audit des modèles d’accès et alignement des configurations avec les frameworks de conformité tels que SOC 2 et PCI-DSS.
8. Intégrations et écosystème
Compétences pour connecter CockroachDB aux outils et plateformes externes, incluant CDC (Change Data Capture) vers Kafka et les systèmes cloud pub/sub, les configurations du connecteur Kafka Connect sink, et les modèles d’intégration avec les entrepôts de données et les plateformes d’analyse.
9. Gestion des coûts et de l’utilisation
Compétences qui aident les équipes à comprendre et optimiser la consommation des ressources : dimensionnement approprié des clusters, interprétation de l’amplification du stockage, analyse des statistiques des instructions pour l’attribution des coûts, et identification des charges de travail qui consomment de manière disproportionnée les ressources du cluster.
Scénario concret : Réponse à une pointe CPU
Considérons un exemple pratique où un agent reçoit une alerte de « haute utilisation CPU » sur un cluster de staging. La séquence ci-dessous montre comment les compétences d’agents CockroachDB guident Claude Code à travers l’investigation et la résolution, étape par étape.
Étape 1 : Recevoir l’alerte et se connecter
L’agent reçoit le contexte de l’alerte et se connecte au cluster via le serveur MCP géré. La compétence Observabilité et Diagnostics le dirige immédiatement à vérifier les tâches d’arrière-plan et les statistiques des instructions actives.
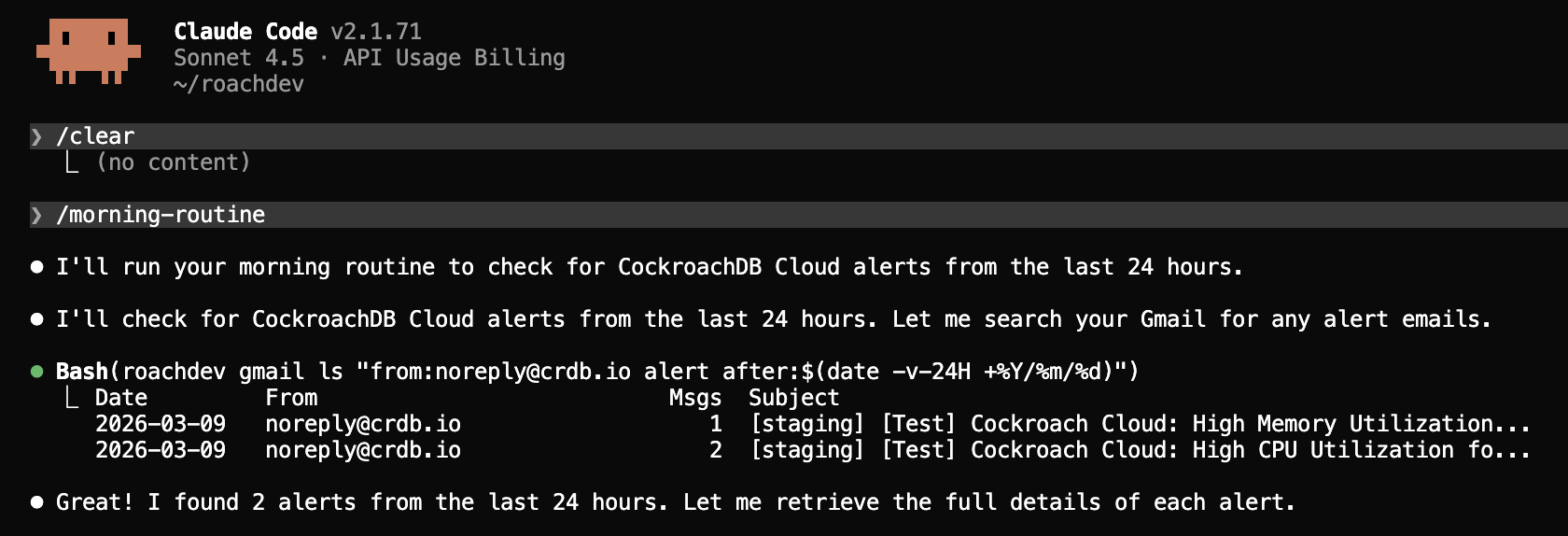
Étape 1 : L’agent reçoit l’alerte CPU et se connecte au cluster
Étape 2 : Surveiller les tâches d’arrière-plan et profiler les instructions SQL
En utilisant la compétence Observabilité et Diagnostics, l’agent appelle show_running_queries et analyze_performance pour faire remonter les requêtes longues et identifier quelles instructions consomment le plus de CPU.
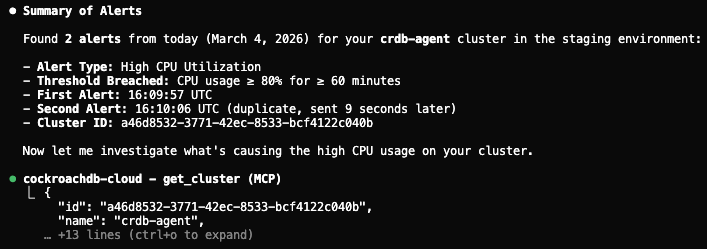
Étape 2 : L’agent surveille les tâches d’arrière-plan et profile les instructions SQL
Étape 3 : Identifier les causes profondes
La compétence Performance et Scalabilité guide l’agent à exécuter explain_query sur les requêtes les plus coûteuses. Elle identifie des scans complets de table coûteux sur la table user_events et une tâche de sauvegarde qui se chevauche avec le pic de trafic.
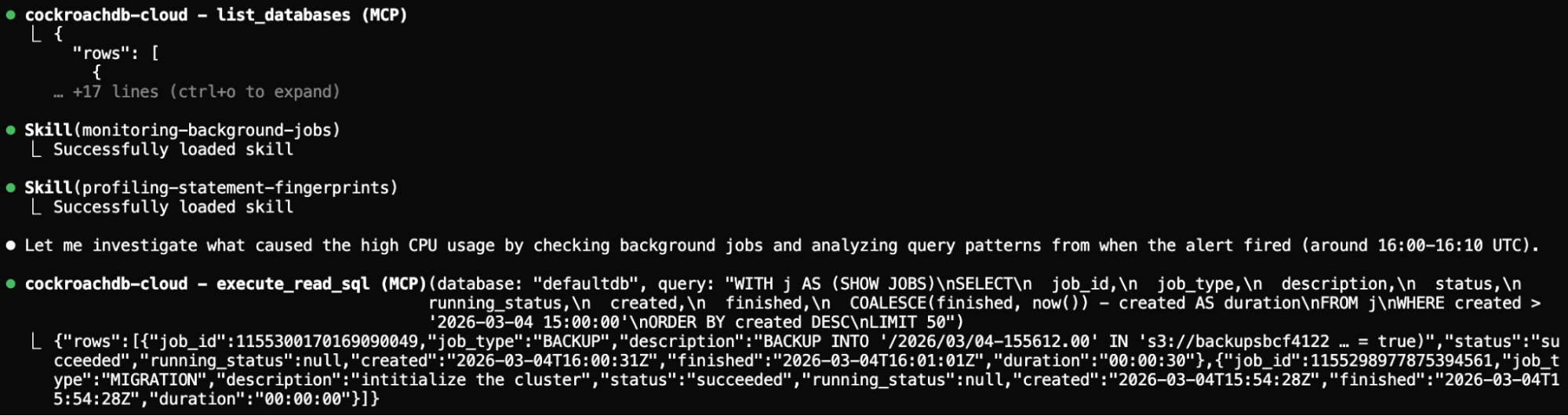
Étape 3 : L’agent identifie les causes profondes : scans complets et chevauchement de sauvegarde
Étape 4 : Diagnostiquer les problèmes de schéma
La compétence Performance et Scalabilité signale en outre un modèle de clé primaire UUID sous-optimal causant des points chauds d’écriture. L’agent propose de le remplacer par une clé primaire à hachage fragmenté et d’ajouter des index de support pour éliminer les scans.
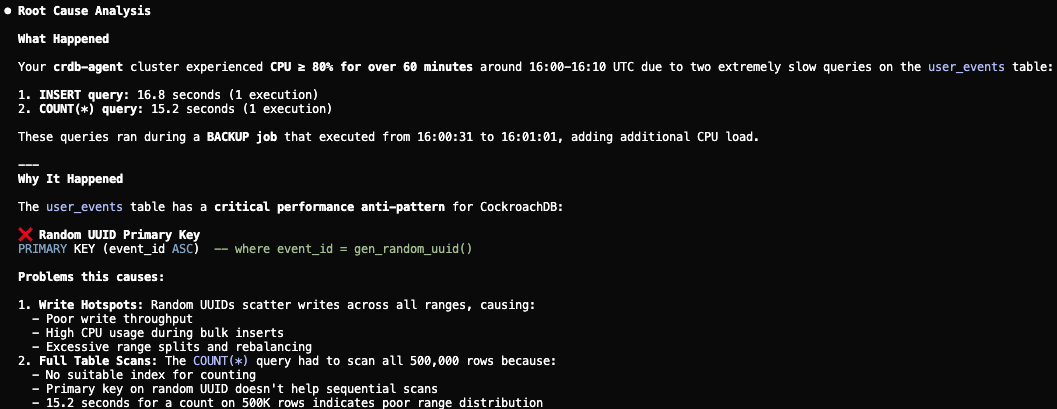
Étape 4 : L’agent diagnostique le point chaud UUID et propose une clé primaire à hachage fragmenté
Étape 5 : Générer des scripts de migration pour révision humaine
La compétence Opérations et Cycle de vie garantit que l’agent n’applique pas directement les changements. Au lieu de cela, il génère des scripts de migration (DDL pour le changement de schéma, un planning de sauvegarde révisé et un plan de rollback) pour qu’un ingénieur les examine et les approuve avant l’exécution.
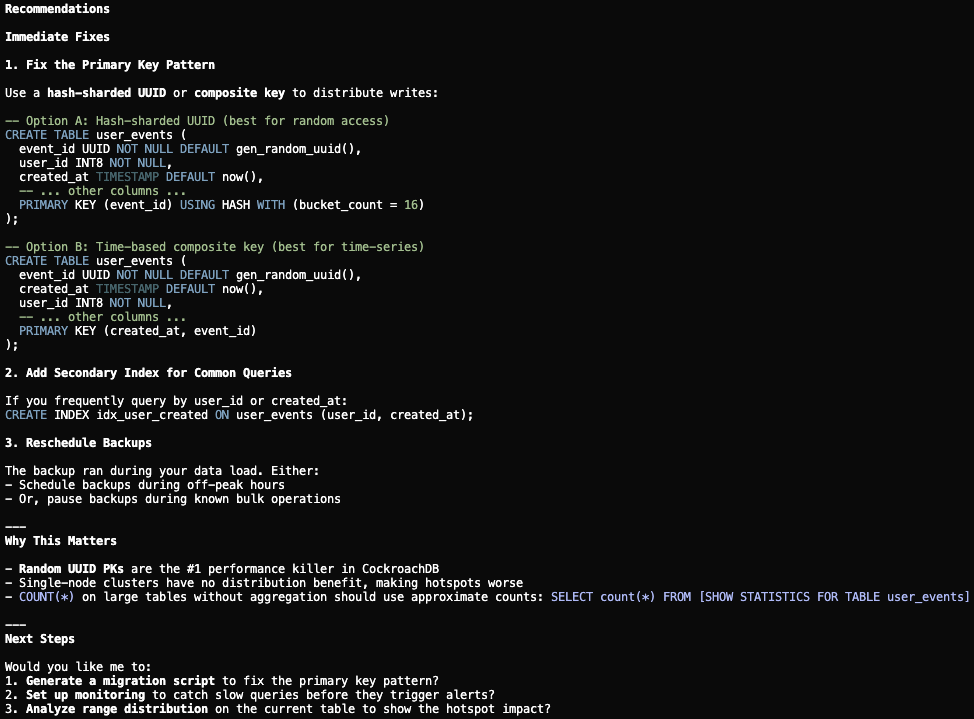
Étape 5 : L’agent génère des scripts de migration pour révision humaine
Ce workflow est conversationnel, structuré, auditable et approuvé par des humains à chaque point de décision, exactement le modèle que les compétences d’agents CockroachDB sont conçues pour imposer.
Trois interfaces, une base de données agent-ready
Les trois composants servent différents scénarios et audiences :
| Interface | Idéal pour |
|---|---|
| Serveur MCP open-source | Développeurs, clusters locaux, contrôle administratif complet |
| Serveur MCP géré | Équipes d’entreprise, systèmes d’agents partagés, sécurité en production |
| Compétences d’agents | Portabilité entre frameworks, raisonnement structuré, automatisation du cycle de vie |
CLI ccloud |
Agents développeurs opérant via des commandes shell, pipelines CI/CD |
Ensemble, ils reflètent une philosophie architecturale délibérée : CockroachDB expose son état interne (statistiques des instructions, plans d’exécution, événements de contention, distribution des plages, statut de réplication) à travers des interfaces structurées que les agents peuvent interpréter et exploiter de manière fiable.
Comme l’a dit Spencer Kimball, PDG de Cockroach Labs : « Toute l’activité que les bases de données ont dû gérer jusqu’à présent a concerné les humains. Désormais, ce seront des agents… Vous pourriez en avoir un trillion. »
L’ère de l’agent IA est arrivée, et CockroachDB est conçu pour elle.
Ressources
- Serveur MCP CockroachDB (open-source)
- Démarrage rapide du Serveur MCP géré CockroachDB
- CockroachDB est conçu pour les agents IA
- Le Serveur MCP géré de CockroachDB : Accès agent IA prêt pour la production
- Compétences d’agents IA pour CockroachDB : Automatisation du cycle de vie des bases de données
- Présentation du Model Context Protocol – Anthropic
- Serveur MCP CockroachDB : Le guide ultime pour les ingénieurs IA – Skywork
- Déverrouiller CockroachDB avec l’IA : Une plongée en profondeur dans le Serveur MCP – Skywork
- Swayingleaves/cockroachdb-mcp-server
- Serveur MCP dhartunian/cockroachdb
- CData cockroachdb-mcp-server-by-cdata
- cockroachlabs/cockroachdb-skills
- Premiers pas avec GenAI et CockroachDB
- Indexation en temps réel pour des milliards de vecteurs avec C-SPANN