
Dans la course aux armements contre la fraude financière, les millisecondes comptent. Pour chaque transaction donnée, les systèmes de détection de fraude doivent décider si elle est frauduleuse et agir immédiatement en conséquence. Ne pas traiter définitivement la fraude entraîne des pertes importantes, nuit à l’image de marque des organisations, ternit leur réputation et repousse inévitablement les clients.
L’incidence de la fraude a atteint des niveaux records. Les estimations du coût mondial de la fraude — incluant la cybercriminalité, la fraude financière et les pertes associées — vont de 1 200 à plus de 1 500 milliards de dollars par an d’ici fin 2025.
Pendant ce temps, les fraudeurs évoluent rapidement et progressent en tandem avec les transformations de la banque numérique, imaginant des méthodes astucieuses pour voler ou falsifier les identités des clients et commettre des fraudes à grande vitesse. En conséquence, les systèmes de détection de fraude traditionnels basés sur des règles (hors ligne) ne sont plus efficaces, car ils s’appuient sur des heuristiques statiques et un traitement par lots qui ne peuvent pas suivre le rythme des tactiques de fraude adaptatives en temps réel.
Les systèmes de détection de fraude doivent ingérer des volumes massifs de données transactionnelles, les évaluer par rapport à des ensembles de règles dynamiques et prendre des décisions en temps réel — tout en opérant à travers une infrastructure mondiale. Les bases de données traditionnelles cèdent souvent sous cette pression et offrent de mauvaises performances en matière de prévention de la fraude, en raison de stratégies d’accès aux données inefficaces.
C’est là qu’intervient CockroachDB, une base de données SQL distribuée conçue pour la scalabilité, la résilience et les performances. En ce qui concerne la dernière génération de systèmes de détection de fraude alimentés par l’IA, le cœur de l’avantage de CockroachDB réside dans ses capacités avancées d’indexation vectorielle. En plus des index géo-partitionnés et inversés existants, CockroachDB permet aux développeurs de construire des systèmes de détection de fraude en ligne qui sont à la fois rapides et intelligents.
Cet article explore comment ces nouvelles fonctionnalités d’indexation vectorielle permettent la détection d’anomalies à faible latence, les alertes en temps réel et la prise de décision consciente de la région — sans compromettre l’exactitude ou la scalabilité.
Défis de la détection de fraude
Les systèmes de détection de fraude font face à plusieurs défis qui rendent difficile l’identification précise des activités frauduleuses. Certains de ces défis sont :
-
Techniques de fraude en évolution : Les fraudeurs s’adaptent continuellement et développent de nouvelles techniques pour échapper à la détection. Par conséquent, les systèmes de détection de fraude doivent être mis à jour régulièrement pour suivre l’évolution des schémas.
-
Qualité des données : La précision des systèmes de détection de fraude dépend de la qualité de leurs données. Si les données sont incomplètes, incorrectes ou incohérentes, cela peut conduire à des faux positifs ou des faux négatifs, réduisant l’efficacité du système.
-
Équilibrer la détection de fraude et l’expérience utilisateur : Bien que les systèmes de détection de fraude visent à minimiser la fraude, ils doivent également maintenir une bonne expérience utilisateur. Des règles de détection de fraude trop strictes peuvent entraîner des faux positifs et une friction accrue, conduisant à des clients mécontents.
-
Coût : La mise en œuvre et la maintenance d’un système de détection de fraude peuvent être coûteuses. Le coût comprend l’acquisition et le traitement de grandes quantités de données, le développement et la maintenance des algorithmes et des modèles, et l’embauche de personnel pour gérer le système.
-
Problèmes de confidentialité : Les systèmes de détection de fraude nécessitent l’accès à des données sensibles des clients, ce qui peut soulever des problèmes de confidentialité. Les entreprises doivent s’assurer que leurs systèmes de détection de fraude respectent les réglementations sur la confidentialité et mettent en œuvre des mesures de sécurité appropriées pour protéger les données.
Ensuite, nous nous concentrerons sur les deux principaux défis énumérés ci-dessus : les faux positifs et la latence. Les deux conduisent à des clients mécontents et à des pertes substantielles.
1 - Faux positifs
Qu’est-ce qu’un faux positif ? Lorsqu’une transaction légitime est signalée comme frauduleuse, on parle de « faux positif ». Cette situation est très frustrante pour les clients et peut s’avérer assez coûteuse pour les entreprises. Pour relever ce défi, une approche multicouche est nécessaire pour améliorer la détection et apprendre continuellement des modèles de fraude en évolution.
L’approche multicouche est une technique utilisée dans les systèmes de détection de fraude pour améliorer la précision et l’efficacité de la détection de fraude. Elle implique l’utilisation de plusieurs couches de méthodes et techniques de détection de fraude pour détecter les activités frauduleuses. L’approche multicouche comprend généralement trois couches :
-
Couche basée sur les règles : La première couche est un système basé sur des règles qui utilise des règles prédéfinies pour identifier les activités potentiellement frauduleuses. Ces règles sont basées sur des données de fraude historiques et sont conçues pour détecter les modèles de fraude connus. Voici quelques exemples de ces règles :
- Mise sur liste noire des adresses IP des fraudeurs
- Dérivation et utilisation des données de latitude et longitude à partir des adresses IP des utilisateurs
- Utilisation des données sur le type et la version du navigateur, ainsi que sur le système d’exploitation, les plugins actifs, le fuseau horaire et la langue
- Profil d’achat par utilisateur : Cet utilisateur a-t-il déjà acheté dans ces catégories ?
- Profils d’achat généraux : Ce type d’utilisateur a-t-il déjà acheté dans ces catégories ?
Les règles peuvent être mises en œuvre de sorte qu’elles puissent commencer d’un coût « faible » à un coût « élevé ». Si un utilisateur effectue un achat dans des catégories déjà connues et dans des montants de transaction min/max, l’application peut marquer la transaction comme non frauduleuse et ignorer les étapes de détection ultérieures.
-
Couche de détection d’anomalies : La deuxième couche est un système de détection d’anomalies qui identifie les activités inhabituelles basées sur des analyses statistiques des données transactionnelles. Cette couche utilise des algorithmes d’apprentissage automatique (ML) tels que Random Cut Forest pour identifier des modèles qui ne sont généralement pas observés dans les transactions légitimes. Cette couche implique d’abord la conversion des données en un espace vectoriel de haute dimension à l’aide de techniques d’embedding — ici les embeddings représentent les différents attributs/règles de fraude comme la localisation, le montant de la transaction, le profil utilisateur, les adresses IP… puis l’entraînement d’un modèle de forêt aléatoire sur ces embeddings pour identifier les anomalies comme des points de données qui s’écartent significativement de la norme.
-
Couche de modélisation prédictive : La troisième couche est un système de modélisation prédictive qui utilise des algorithmes avancés d’apprentissage automatique, tels que XGBoost, pour prédire la probabilité de fraude. Cette couche utilise des données historiques pour entraîner les modèles et peut détecter de nouveaux modèles de fraude qui ne sont pas détectés par les couches précédentes. Cette couche peut également être efficacement utilisée pour prédire les anomalies lorsqu’elle est combinée avec des vector embeddings.
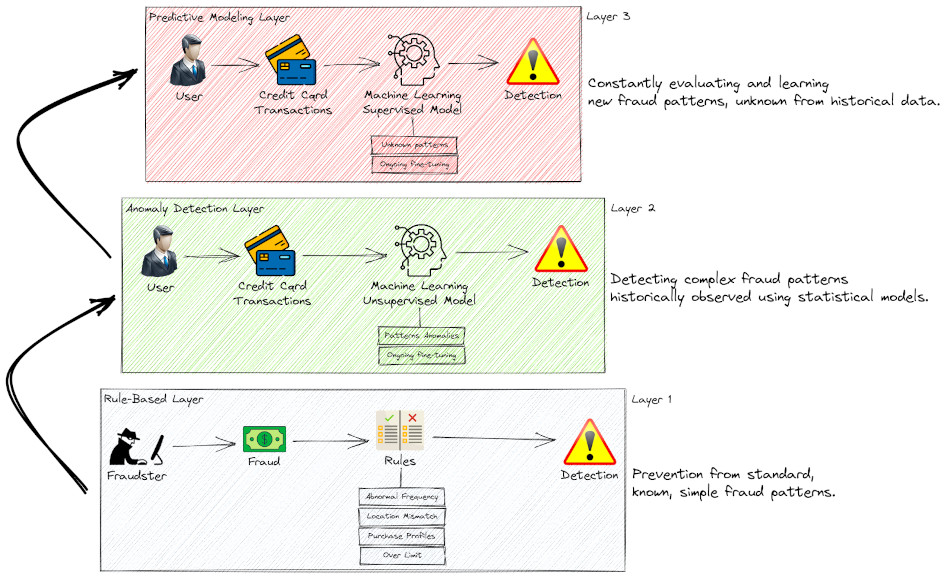
Détection de fraude multicouche
En utilisant une approche multicouche, les systèmes de détection de fraude peuvent minimiser les faux positifs et les faux négatifs, améliorant ainsi la précision de la détection. L’approche multicouche aide également à détecter la fraude avec précision, prévenant l’insatisfaction des clients lorsqu’ils sont faussement signalés comme fraudeurs.
2 - Latence
Comme mentionné précédemment, les fraudeurs évoluent et deviennent plus complexes. Par conséquent, la détection ne doit pas prendre du retard, et une détection améliorée ne doit pas augmenter la latence. Si les entreprises ne peuvent pas détecter si la transaction est frauduleuse ou non en quelques millisecondes, elle est par défaut considérée comme authentique. C’est pourquoi la latence est un défi significatif dans la détection de fraude.
Pour résoudre ce problème, les organisations peuvent tirer parti de la recherche par similarité vectorielle pour conserver et gérer les embeddings utilisés par les systèmes de détection de fraude en ligne (c’est-à-dire en temps réel).
Les embeddings sont les attributs utilisés par les modèles d’apprentissage automatique pour faire des prédictions ou des classifications. Des exemples de vecteur de transaction peuvent inclure les données démographiques des clients, l’historique d’achats, l’activité sur le site web et les préférences de produits. Une base de données vectorielle stocke ces vecteurs dans un emplacement centralisé et les fournit aux modèles d’apprentissage automatique avec une faible latence.
Bien que les bases de données vectorielles natives fournissent une recherche de similarité efficace via des structures d’indexation avancées comme HNSW ou IVF, les bases de données relationnelles traditionnelles avec support vectoriel manquent souvent d’indexation vectorielle sophistiquée. Ces bases de données ont généralement recours à la recherche par force brute pour les opérations de similarité vectorielle. Par conséquent, lorsque le nombre de transactions à évaluer atteint des millions, voire des milliards, les recherches vectorielles deviennent prohibitivement lentes, et le système de détection de fraude perd sa capacité en temps réel.
CockroachDB répond à ce problème de performance fondamental avec la version 25.2, qui inclut un support d’indexation haute performance pour les vecteurs multidimensionnels. L’optimiseur intègre des index vectoriels secondaires dans les plans de requête, et le moteur d’exécution implémente ce nouveau type d’index. Les utilisateurs peuvent écrire des requêtes qui recherchent efficacement à travers des données relationnelles et vectorielles, même dans la même requête.
En utilisant CockroachDB comme base de données vectorielle distribuée, les systèmes de détection de fraude peuvent accéder rapidement et réutiliser des données historiques (vecteurs) pour différents modèles sans les ré-ingénieur ou les retraiter. À mesure que de nouvelles données sont collectées, la base de données peut mettre à jour les embeddings utilisés par les modèles d’apprentissage automatique, résultant en des prédictions de fraude plus précises. Cela améliore l’efficacité et réduit la latence lors de la détection de fraude.
Système de détection de fraude avec CockroachDB & AWS AI
CockroachDB joue deux rôles dans le système de détection de fraude :
-
En tant que base de données de traitement transactionnel en ligne (OLTP) mondiale qui stocke et indexe les transactions financières.
-
En tant que base de données vectorielle exploitée par les services AWS AI Bedrock et Sagemaker. Les deux rôles sont interdépendants et peuvent coexister sur un seul cluster.
En prérequis, les transactions historiques (données d’entraînement) sont fournies à AWS Sagemaker pour entraîner ses modèles ML. Une fois les transactions marquées comme frauduleuses, elles sont stockées dans CockroachDB sous forme de vector embeddings.
Le système de détection de fraude est démarré lorsqu’une fonction AWS Lambda consomme le flux de transactions en temps réel depuis Kinesis, applique les règles, crée les vector embeddings en utilisant les modèles fondamentaux AWS Bedrock, et envoie les données transactionnelles et vectorielles dans CockroachDB.
CockroachDB charge également des données historiques directement depuis un bucket S3 en utilisant l’instruction IMPORT INTO. Ces données peuvent désormais entrer dans le pipeline de détection de fraude, servant d’entrée pour entraîner et améliorer les modèles exécutés sur AWS SageMaker.
Rappelons les deux principaux défis de détection de fraude présentés ci-dessus, les faux positifs et la latence. CockroachDB peut aborder les deux sous différentes perspectives :
Premièrement, il applique des règles prédéfinies pour identifier les activités potentiellement frauduleuses (couche basée sur les règles). Cela garantit une mise sur liste noire cohérente et précise des adresses IP en implémentant la limitation du débit et en utilisant les capacités géospatiales natives, pour calculer et évaluer la localisation de l’utilisateur. Ainsi, nous pouvons éviter les faux positifs en appliquant ces pré-filtres sur le trafic entrant.
Deuxièmement, pour fournir un système de détection de fraude à faible latence, le moteur doit rapidement lire le dernier vecteur inséré dans CockroachDB, chercher parmi des milliards de vecteurs historiques étiquetés comme frauduleux, et calculer la distance entre cette nouvelle transaction et les frauduleuses. Ensuite, basé sur cette distance, le modèle ML classifiera la transaction.
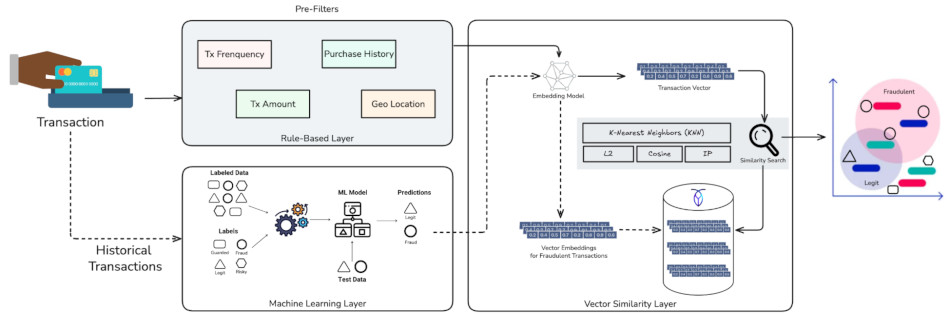
Système de détection de fraude basé sur la GenAI
Cependant, même avec un bon backend de stockage, intégrer le système de détection d’anomalies dans une base de données SQL distribuée comme CockroachDB n’est pas simple. Pour supporter la scalabilité élastique, la tolérance aux pannes et la disponibilité multi-région, CockroachDB a conçu l’indexation vectorielle avec une approche novatrice :
-
Premièrement, elle doit fonctionner sans coordinateur central — chaque nœud du cluster doit pouvoir gérer les lectures et les écritures de manière indépendante, évitant les goulots d’étranglement ou les points de défaillance uniques.
-
L’index doit également éviter de s’appuyer sur de grandes structures en mémoire ; son état doit être stocké de manière persistante pour s’adapter aux environnements serverless et à faible mémoire sans longs temps de démarrage.
-
L’index doit éviter les points chauds en distribuant la charge de travail uniformément à travers le cluster, même sous des insertions ou des requêtes à fort volume.
-
Enfin, il doit supporter les mises à jour incrémentales — gérant les insertions et les suppressions en temps réel sans bloquer les requêtes ni nécessiter de reconstructions complètes. Ces exigences ont écarté de nombreuses stratégies d’indexation conventionnelles, incitant à la conception d’une nouvelle approche adaptée à l’architecture distribuée de CockroachDB.
Cet algorithme d’indexation vectorielle (appelé C-SPANN) est conçu pour organiser les vecteurs en partitions basées sur leur similarité, chaque partition contenant généralement des dizaines à des centaines de vecteurs.
Chacune de ces partitions est représentée par un centroïde — la moyenne de tous les vecteurs qu’elle contient — servant de « centre de masse » pour ce groupe. Ces centroïdes sont ensuite regroupés récursivement en partitions de niveau supérieur, formant une structure d’arbre à plusieurs niveaux (un arbre K-means hiérarchique).
Cette organisation hiérarchique permet à l’index de réduire rapidement l’espace de recherche en traversant des clusters larges vers des sous-ensembles de plus en plus spécifiques. Il en résulte une efficacité et une rapidité considérablement améliorées des recherches vectorielles.
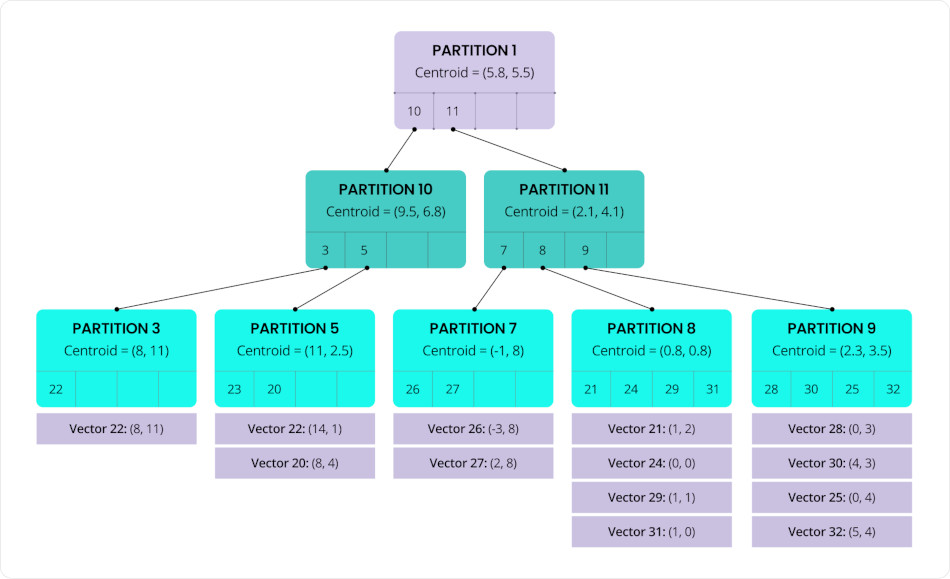
C-SPANN : Arbre K-means hiérarchique
À mesure que de nouveaux vecteurs sont insérés dans l’index, ils sont naturellement distribués à travers plusieurs partitions, qui elles-mêmes sont réparties dans tout le cluster. Cette conception garantit qu’aucun nœud ou plage unique ne devient un goulot d’étranglement, prévenant efficacement les points chauds et permettant au système de faire évoluer le débit d’écriture.
Diviser une partition améliore l’efficacité de la recherche en maintenant un regroupement étroit des vecteurs. Diviser une plage aide à équilibrer le stockage des données et les accès à travers le cluster. Ensemble, ces mécanismes réduisent les points chauds et aident à répartir plus uniformément la charge des requêtes et des insertions.
Lorsque des nœuds sont ajoutés au système, les plages contenant des partitions d’index sont automatiquement distribuées sur les nouveaux nœuds. Cela permet à la charge de travail totale de s’étendre avec le cluster à des taux quasi-linéaires.
Le diagramme ci-dessous illustre l’architecture de la solution de détection de fraude implémentée avec CockroachDB et AWS :
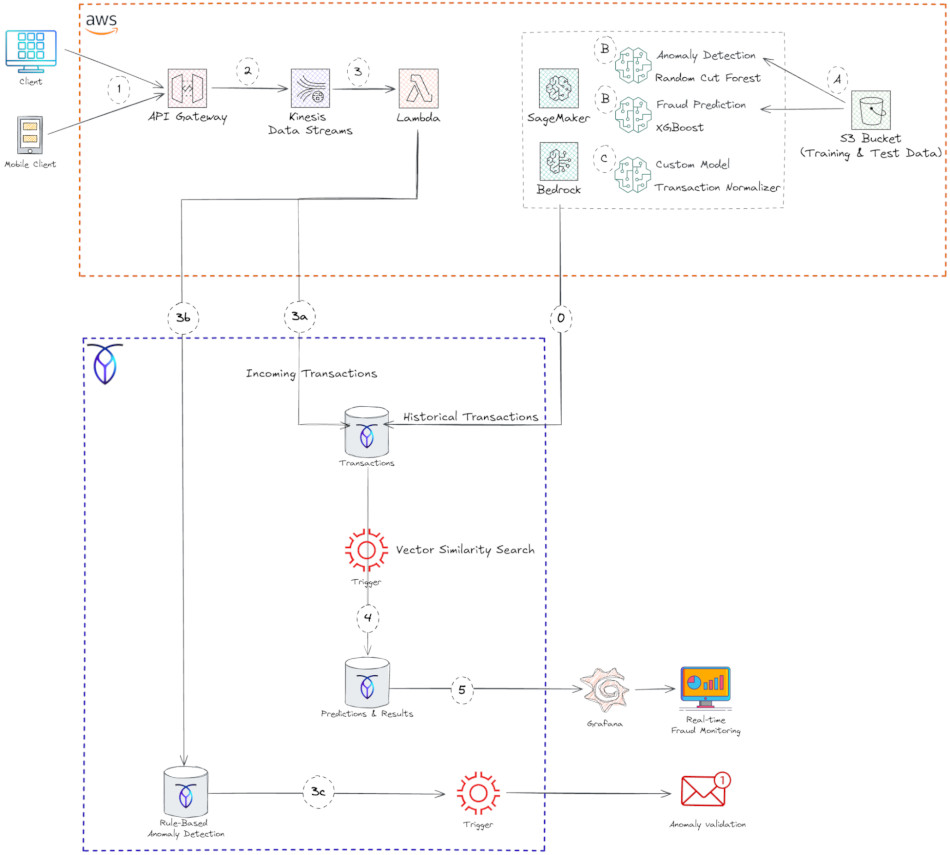
Architecture de référence pour la détection de fraude avec CockroachDB et AWS
A. En prérequis, vous devez mettre des ensembles de données historiques de transactions par carte de crédit dans un bucket Amazon S3. Ces données servent à entraîner et tester les algorithmes d’apprentissage automatique qui détectent la fraude et les anomalies.
B. Amazon SageMaker est un service de workflow d’apprentissage automatique (ML) pour développer, entraîner et déployer des modèles. Il est livré avec de nombreux algorithmes prédéfinis. Vous pouvez également créer vos propres algorithmes en fournissant des images Docker, une image d’entraînement pour entraîner votre modèle, et un modèle d’inférence à déployer sur un point de terminaison REST. Dans CockroachDB, nous avons choisi l’algorithme Random Cut Forest pour la détection d’anomalies et XGBoost pour la prédiction de fraude :
- Random Cut Forest (RCF) est un algorithme non supervisé qui détecte les points de données anormaux dans un jeu de données. Les anomalies sont des observations de données qui s’écartent du modèle ou de la structure attendu. Elles peuvent apparaître comme des pics inattendus dans des données de séries temporelles, des interruptions de périodicité, ou des points de données non classifiables. Ces anomalies sont souvent facilement distinguables des données régulières lorsqu’elles sont visualisées sur un graphique.
RCF attribue un score d’anomalie à chaque point de données. Des scores faibles indiquent que le point de données est normal, tandis que des scores élevés indiquent la présence d’une anomalie. Le seuil de ce qui est considéré comme « faible » ou « élevé » dépend de l’application, mais généralement les scores au-delà de trois écarts-types (3σ) par rapport à la moyenne sont considérés comme anormaux.
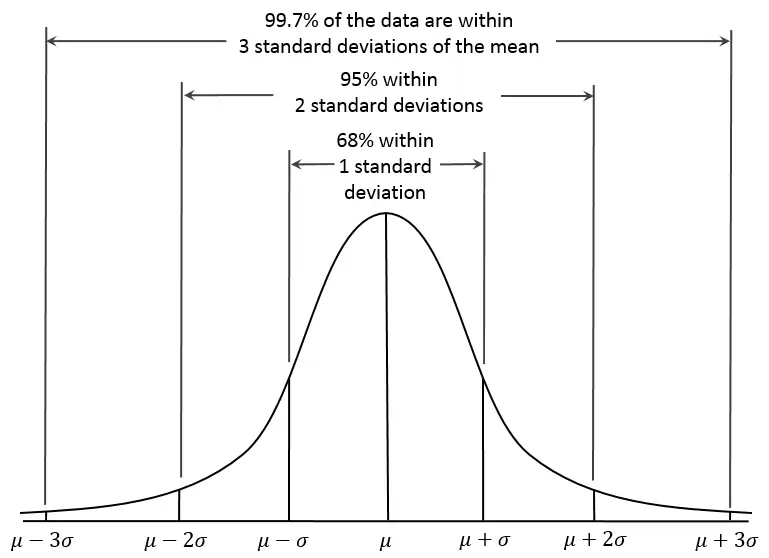
Score d’anomalie
- xGBoost, abréviation d’eXtreme Gradient Boosting, est une implémentation open-source largement utilisée de l’algorithme d’arbres à gradient boosté. Le gradient boosting est une méthode d’apprentissage supervisé qui vise à prédire une variable cible en combinant des estimations d’un ensemble de modèles plus simples et plus faibles.
L’algorithme XGBoost est très efficace dans les compétitions d’apprentissage automatique en raison de sa capacité à gérer divers types de données, distributions et relations, ainsi que la large gamme d’hyperparamètres qui peuvent être ajustés finement.
La fonction Lambda appelle les points de terminaison des modèles AWS SageMaker pour attribuer des scores d’anomalie et des scores de classification aux transactions historiques.
def makeInferences(data_payload):
print("** makeInferences - START")
output = {}
output["anomaly_detector"] = get_anomaly_prediction(data_payload)
output["fraud_classifier"] = get_fraud_prediction(data_payload)
print("** makeInferences - END")
return output
- Détection d’anomalies :
def get_anomaly_prediction(data):
sagemaker_endpoint_name = 'random-cut-forest-endpoint'
sagemaker_runtime = boto3.client('sagemaker-runtime')
response=sagemaker_runtime.invoke_endpoint(EndpointName=sagemaker_endpoint_name, ContentType='text/csv', Body=data)
print("response from get_anomaly_prediction=")
# Extract anomaly score from the endpoint response
anomaly_score=json.loads(response['Body'].read().decode())["scores"][0]["score"]
print("anomaly score: {}".format(anomaly_score))
return {"score": anomaly_score}
- Prédiction de fraude :
def get_fraud_prediction(data, threshold=0.5):
sagemaker_endpoint_name = 'fraud-detection-endpoint'
sagemaker_runtime = boto3.client('sagemaker-runtime')
response=sagemaker_runtime.invoke_endpoint(EndpointName=sagemaker_endpoint_name, ContentType='text/csv', Body=data)
print("response from get_fraud_prediction=")
pred_proba = json.loads(response['Body'].read().decode())
prediction = 0 if pred_proba < threshold else 1
# Note: XGBoost returns a float as a prediction, a linear learner would require different handling.
print("classification pred_proba: {}, prediction: {}".format(pred_proba, prediction))
return {"pred_proba": pred_proba, "prediction": prediction}
C. Une instance de notebook appelle un modèle d’embedding personnalisé d’AWS Bedrock pour vectoriser les jeux de données historiques entraînés et scorés par AWS Sagemaker. Ensuite, elle stocke les transactions frauduleuses sous forme de vecteurs dans CockroachDB (Étape 0 dans le diagramme).
1. Le flux de données commence avec les utilisateurs finaux (clients mobiles et web) invoquant l’API REST Amazon API Gateway.
2. Que sont Amazon Kinesis Data Streams ? Ils sont utilisés pour capturer des données d’événements en temps réel. Amazon Kinesis est un service entièrement géré pour le traitement de données en flux à n’importe quelle échelle. Il fournit une plateforme serverless qui collecte, traite et analyse facilement des données en temps réel pour obtenir des insights opportuns et réagir rapidement aux nouvelles informations. Kinesis peut gérer n’importe quelle quantité de données en streaming et traiter des données provenant de centaines de milliers de sources avec de faibles latences.
3. Qu’est-ce qu’AWS Lambda ? C’est un service de calcul serverless et événementiel qui vous permet d’exécuter du code pour pratiquement n’importe quel type d’application ou service backend sans provisionner ni gérer des serveurs. Dans notre solution, la fonction Lambda est déclenchée par Kinesis pour lire le flux et effectuer les actions suivantes :
3a. Persister les données transactionnelles dans CockroachDB pour permettre une indexation et une interrogation à faible latence des transactions. Pour cela, le schéma suivant a été créé dans la base de données FRAUD_DB :
CREATE TABLE FRAUD_DB.transactions (
transaction_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
account_id UUID NOT NULL,
merchant_id UUID,
transaction_type TEXT NOT NULL CHECK (transaction_type IN ('debit', 'credit', 'refund', 'chargeback')),
amount BIGINT NOT NULL CHECK (amount_cents >= 0),
currency_code CHAR(3) NOT NULL,
status TEXT NOT NULL CHECK (status IN ('pending', 'completed', 'failed', 'reversed')),
transaction_time TIMESTAMPTZ NOT NULL DEFAULT now(),
location_ip INET,
location POINT,
metadata JSONB,
created_at TIMESTAMPTZ DEFAULT now(),
updated_at TIMESTAMPTZ DEFAULT now(),
transaction_vector VECTOR(24)
);
3b. La première couche dans l’approche de détection de fraude est un système basé sur des règles qui applique des règles prédéfinies pour identifier les activités potentiellement frauduleuses. Les règles peuvent être mises en œuvre de sorte qu’elles puissent commencer d’un coût « faible » à un coût « élevé ».
Par exemple, vous pouvez implémenter une fonction de limitation du débit dans CockroachDB qui vérifie les adresses IP et met sur liste noire toute adresse qui se connecte plus d’un certain nombre de fois. Ainsi, vous pouvez appliquer une détection préliminaire d’anomalies sans utiliser l’inférence ML.
3c. Lorsqu’une anomalie basée sur les règles est identifiée, un trigger CockroachDB notifie l’utilisateur final et demande une validation pour la transaction.
4. Pour éviter les faux positifs et les faux négatifs, un autre trigger CockroachDB exécute une fonction qui calcule la distance entre les nouveaux vecteurs de transactions entrantes et les milliards de transactions frauduleuses historiques stockées sous forme de vecteurs. La fonction enregistre ensuite les résultats de la recherche dans CockroachDB.
Lorsque nous effectuons une recherche de similarité sans un index vectoriel approprié, le principal défi est que votre moteur de base de données effectuera un scan complet de toutes vos données et calculera les métriques de similarité pour trouver les vecteurs les plus proches de votre requête.
Pour vérifier cela, vous pouvez utiliser l’instruction EXPLAIN qui retourne le plan de requête de CockroachDB. Vous pouvez utiliser ces informations pour optimiser la requête et éviter de scanner toute la table, qui est la façon la plus lente d’accéder aux données.
Appliquons cette instruction à la requête de recherche de similarité :
EXPLAIN SELECT transaction_id, transaction_vector <-> new_trancation_vector AS l2_distance FROM fraudulent_transactions ORDER BY l2_distance DESC;
La sortie montre la structure arborescente du plan d’instruction, dans ce cas un tri et un scan :
info -----------------------------------------------------------------------
distribution: full
vectorized: true
• sort
│ estimated row count: 3.000.000
│ order: -l2_distance
│ └── • render
│ └── • scan
estimated row count: 3.000.000 (100% of the table; stats collected 2 minutes ago)
table: fraudulent_transactions@transaction_id
spans: FULL SCAN
Créons maintenant un index vectoriel sur le vecteur de transaction :
CREATE VECTOR INDEX trx_vector_idx ON transactions (transaction_vector);
Une fois l’index vectoriel affiné, l’appel suivant à EXPLAIN démontre que la portée du scan est maintenant LIMITED SCAN. Cela indique que la table sera scannée sur un sous-ensemble des plages de clés d’index.
info -----------------------------------------------------------------------
distribution: local
vectorized: true
• sort
│ estimated row count: 294.547
│ order: -l2_distance
│ └── • render
│ └── • vector search
table: fraudulent_transactions@trx_vector_idx
target count: 294.547
spans: LIMITED SCAN
Comme vous pouvez l’observer, le nombre estimé de lignes est d’environ 10 % du nombre de lignes de la table. Cela améliore considérablement le temps d’exécution de la recherche vectorielle, et la latence globale du système de détection de fraude.
Notez que la précision de la recherche dépend fortement de facteurs de charge de travail tels que :
- la taille de la partition
- le nombre de dimensions
VECTOR - dans quelle mesure les embeddings reflètent la similarité sémantique
- comment les vecteurs sont distribués dans le jeu de données.
5. Optionnellement, les résultats de la recherche de similarité, ainsi que les détails transactionnels, peuvent également être stockés dans une base de données de séries temporelles pour des visualisations de données supplémentaires en utilisant la plateforme d’observabilité Grafana.
Ci-dessous se trouve le tableau de bord Grafana qui montre les scores de fraude en temps réel pour les transactions entrantes. Sur une échelle de 0 à 1 et pour toute transaction donnée, si le score de fraude dépasse 0,8, elle est considérée comme frauduleuse et affichée en rouge. De plus, d’autres graphiques sont utilisés pour visualiser l’activité de fraude dans le temps ou pour comparer les transactions frauduleuses et non frauduleuses (côté inférieur).
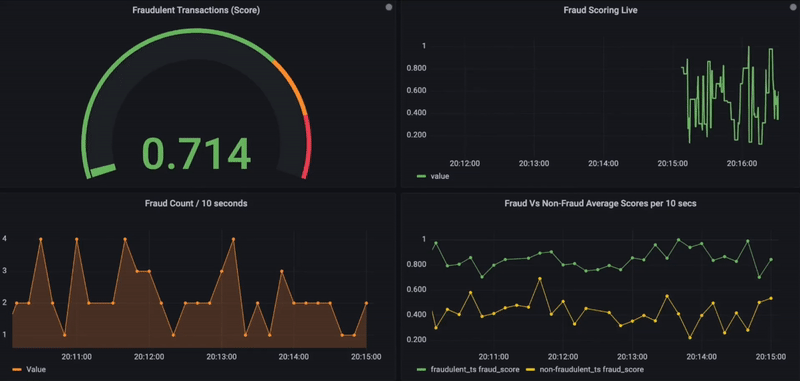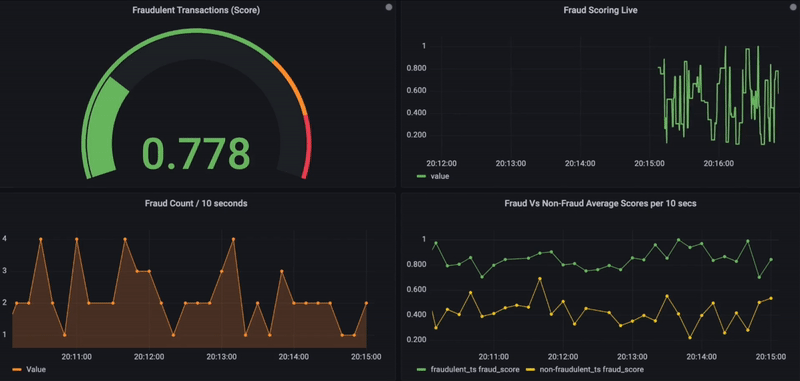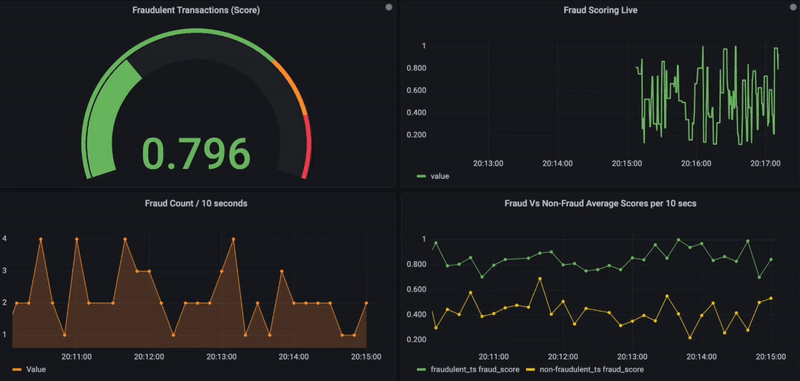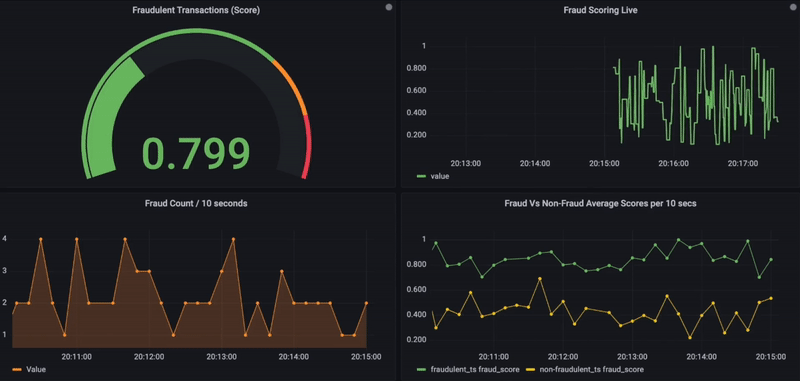
Surveillance de fraude en temps réel avec Grafana
Comment vaincre la fraude
L’architecture distribuée et les capacités d’indexation vectorielle de CockroachDB débloquent quelque chose de puissant : un nouveau niveau de vitesse et d’intelligence pour la détection de fraude en temps réel.
Associé aux services AWS AI comme Bedrock, SageMaker et Lambda, vous pouvez construire un pipeline robuste et scalable qui détecte les anomalies tôt, les classifie précisément et répond en quelques secondes. Ce système réduit non seulement le risque de fraude, mais évite également de bloquer les utilisateurs légitimes — maintenant la sécurité et la confiance des utilisateurs, afin que les entreprises puissent croître.
Ressources
- Documentation de la recherche vectorielle CockroachDB
- C-SPANN : Indexation en temps réel pour des milliards de vecteurs
- Article original : Détection de fraude à grande échelle avec CockroachDB & AWS AI
- Le vrai coût de la cybercriminalité
- La recherche vectorielle rencontre le SQL distribué
- Amazon Kinesis Data Streams
- AWS Lambda
- Amazon SageMaker
- Amazon Bedrock